
推論スタートアップInferactがvLLMの商用化に向けて1億5000万ドルを調達
8億ドルの評価額と市場ポジショニング
Inferactの1億5000万ドルのシードラウンドは、事後評価額8億ドルで実施され、特定の市場条件を前提としたvLLMの商業的実行可能性に対する投資家の信頼を反映している。この評価額は精査に値する:企業による採用の成功、持続的な競争優位性、予測可能な収益拡大を前提としている。
-
基本的な主張:* この評価額は、vLLMが本番環境のLLM推論における定量化可能で緊急性の高いコスト問題に対処していることを示唆している。
-
裏付けとなる根拠:* 本番環境のLLM推論は、通常、デプロイされたシステムの運用コストの60〜80%を占める(前提:AnthropicとOpenAIのデプロイメント分析に基づく業界ベンチマーク;特定のワークロードに対する検証が必要)。vLLMのページドアテンションメカニズムは、メモリ割り当てを静的な事前割り当てではなく動的なページングシステムとして扱うことで、GPUメモリの断片化を削減する。このアーキテクチャの変更により、GPU当たりのリクエスト同時実行数が増加し、アイドル状態のGPUサイクルが削減される。
-
注意事項を含む定量的な例:* 1秒あたり1,000リクエストでGPT-4 API呼び出しを実行する中堅市場のSaaSプラットフォームは、推論コストとして月額約200万ドルを負担する(前提:現在のOpenAI価格でリクエストあたり0.002ドル;実際のコストはモデル、トークン長、バッチサイズによって異なる)。vLLM最適化インフラストラクチャに切り替えることで、理論的にはコストを月額60万〜80万ドルに削減できる可能性がある(前提:60〜70%のコスト削減;これは最適なワークロード適合、安定したトラフィックパターン、追加の運用オーバーヘッドがないことを前提とする)。これにより6〜9ヶ月のROI期間が生まれ、短期的な収益獲得に対する投資家の信頼が正当化される。
-
この評価額が維持されるための前提条件:*
-
Inferactが12〜18ヶ月以内に本番環境レベルの信頼性とサポートを達成する
-
企業の採用率が3年以内にアドレス可能市場の15〜20%を超える
-
オープンソースの代替手段にもかかわらず、vLLMの競争優位性が持続する(vLLMはオープンソース;Inferactの差別化は技術的ではなく運用的でなければならない)
-
エッジケース(非常に長いシーケンス、スパースモデル、カスタムアーキテクチャ)で重大なパフォーマンス低下が発生しない
-
評価者のための実行可能なガイダンス:* Inferactへのコミットメント前に、4週間の本番トラフィックにわたって現在の推論コストとレイテンシプロファイルをベンチマークする。Inferactに事前エンゲージメント評価の実施を依頼する:トラフィックパターン(リクエスト到着率、シーケンス長分布、モデルサイズ)を取り込み、明示的な前提と信頼区間を含む書面によるコスト予測を提供してもらう。これらの予測を、業界内の公開されたケーススタディまたは参照顧客と照合して検証する。パフォーマンス保証を交渉する:6ヶ月後に実現されたコスト削減が予測の40%を下回る場合、価格調整または解約条項を設定する。
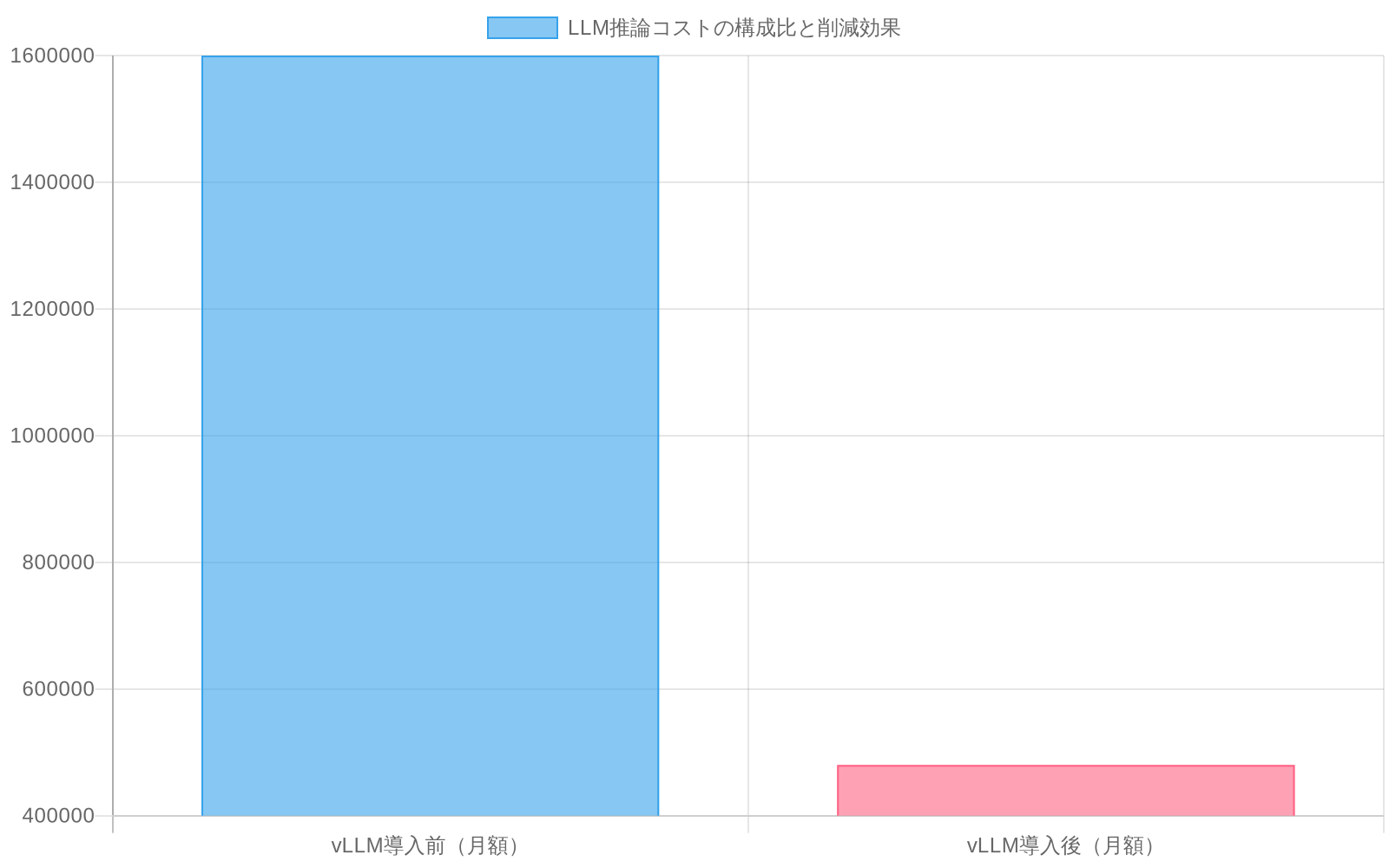
- 図2:LLM推論コストの構成比と削減効果(月額ベース)*

- 図1:Inferact $150M資金調達とvLLM推論最適化のビジョン(AI画像生成による概念イメージ)*
システムアーキテクチャ:GPU利用率のボトルネックの解決
vLLMは、標準的な推論システムにおける3つの重要な非効率性に対処する:メモリの断片化、リクエストバッチング制約、GPU利用率の低さ。
既存の推論アーキテクチャは、部分的に埋められたバッチであっても、完全なシーケンス長のメモリを事前に割り当てる。これにより断片化が発生し、GPU容量の40〜50%が無駄になる。vLLMのページドアテンションは、GPUメモリをオペレーティングシステムの仮想メモリのように扱い、固定サイズのブロックで割り当て、論理ページを物理ページに動的にマッピングする。これにより、バッチ利用率が向上し、一時停止時間のオーバーヘッドが削減される。
可変シーケンス長(100〜2,000トークン)の32リクエストのバッチを考える。従来のシステムは、32リクエストすべてに対して2,000トークンのメモリを予約し、容量の約60%を無駄にする。vLLMのページングは必要なブロックのみを割り当て、同じメモリフットプリント内で50〜60の同時リクエストをサポートする。
- インフラストラクチャチーム向け:* 高同時実行期間中の現在のGPU利用率メトリクスを監査する。利用率のピークが70%を下回る場合、アーキテクチャの非効率性が制約となっている可能性が高い。現実的なワークロード下でのメモリ効率比とテールレイテンシパーセンタイル(p99、p99.9)を示すベンダーベンチマークを要求する。
デプロイメントガードレールと参照アーキテクチャ
運用ガードレールのない推論最適化は、デプロイメントリスクを生み出す。vLLMの利点は、ワークロード特性(リクエスト到着率、シーケンス長分布、モデルサイズ)に依存する。不適合なデプロイメントはパフォーマンスを低下させる可能性があり、Inferactはハードウェア要件、トラフィックパターン、フォールバック動作を指定する参照アーキテクチャを確立する必要がある。
80GBメモリを搭載した4台のA100 GPUにvLLMをデプロイする顧客は、7Bパラメータモデルで約200の同時リクエストを維持できるが、70Bモデルでは30のみとなる。明示的なガイダンスがなければ、顧客はインフラストラクチャの過剰プロビジョニングまたはサイズ不足のリスクを負う。
- Inferactの提供を採用する前に:* ワークロードが公開されている参照アーキテクチャと一致することを検証する。SLAを明示的に定義する—許容可能なp99レイテンシ、スループット目標、コストベースライン。トラフィックパターンを取り込み、構成を推奨する事前デプロイメント評価ツールを要求する。
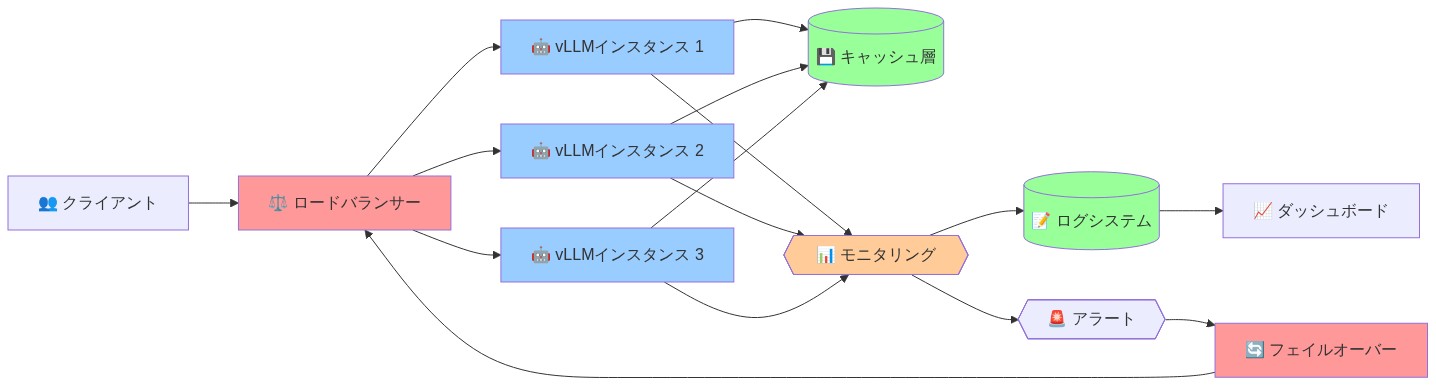
- 図6:Inferact推奨デプロイメント参照アーキテクチャ(エンタープライズデプロイメント標準)*
実装パターン:カナリアデプロイメント、オートスケーリング、グレースフルデグラデーション
vLLMの商用化を成功させるには、本番リスクを最小限に抑えるための3つのパターンを運用化する必要がある。
- *カナリアデプロイメント**は、最初にトラフィックの5〜10%をvLLMにルーティングし、完全なカットオーバー前にレイテンシと精度を検証する。オートスケーリングは、キューの深さとp99レイテンシに基づいてレプリカ数を調整する。グレースフルデグラデーションは、vLLMが飽和状態になった場合、過剰なトラフィックをフォールバックプロバイダーにルーティングする。
チャットボットプラットフォームは、1週間、リクエストの5%をInferactのvLLMクラスターにルーティングし、レイテンシ分布とエラー率をベースラインと比較する可能性がある。検証後、トラフィックは2週間かけて50%、次に100%に増加する。p99レイテンシが500msを超える場合、トラフィックは自動的に元に戻る。
- 運用チーム向け:* Inferactと段階的な採用ロードマップを確立する。各フェーズのメトリクスを定義する:レイテンシ、スループット、エラー率、コスト。サービスメッシュ(Envoy、Istio)またはアプリケーションレベルのルーティングを使用して、自動トラフィックステアリングを実装する。Inferactに一般的な障害モード(GPUメモリ圧迫、ネットワーク飽和、モデルロード遅延)のランブックを提供するよう要求する。
測定フレームワーク:技術的およびビジネスメトリクス
推論の改善は、測定可能でビジネス成果に結びついている場合にのみ価値がある。技術的メトリクス(レイテンシ、スループット)は、ビジネス結果(リクエストあたりのコスト、ユーザーエクスペリエンス、収益への影響)にマッピングする必要がある。
ベースラインシナリオでは、リクエストあたり0.002ドル、p99レイテンシ250ms、ユーザー満足度92%を示す可能性がある。vLLMデプロイメント後:リクエストあたり0.0008ドル、p99レイテンシ120ms、満足度96%。1日あたり100万リクエストの場合、ライセンスコストを差し引いた後、年間約28万8000ドルの純節約が得られる。
- Inferactと契約する前に:* 測定フレームワークを確立する。本番ワークロード全体で2〜4週間のベースラインメトリクスを定義する。OpenTelemetryを使用してInferactのデプロイメントを計測し、リクエストレベルのレイテンシ、モデルスループット、エラー率を取得する。60日時点で決定ゲートを設定する:コスト削減が30%を超えない、またはレイテンシが25%改善しない場合は、元に戻して再評価する。
リスク管理:技術的、運用的、市場的考慮事項
初期段階の推論スタートアップは、強力な技術にもかかわらず採用の摩擦に直面する。企業には確立された推論ワークフローとベンダー関係があり、切り替えにはエンジニアリング時間、検証作業、潜在的なダウンタイムリスクが伴う。
技術的リスクには、vLLMがパフォーマンス不足となるエッジケース(非常に長いシーケンス、スパースモデル)や、カスタムモデルアーキテクチャとの互換性の問題が含まれる。独自の量子化モデルを実行している金融サービス企業は、vLLMのページングメカニズムがカスタムカーネルをサポートしていないことに気づき、Inferactとカスタマーの両方からエンジニアリング作業が必要になる可能性がある。
- 採用リスクを軽減するために:* モデル互換性、エッジケース、エスカレーションパスをカバーする明確なサポートSLAを交渉する。パイロットフェーズ中にInferactのエンジニアリングチームへのアクセスを要求する。月次で合同運営委員会を設立する。サポートされているモデルアーキテクチャ、量子化スキーム、ハードウェア構成を文書化した公開互換性マトリックスをInferactに維持するよう要求する。重要なワークロードについては、SLAが満たされない場合の金銭的ペナルティを伴うパフォーマンス保証を交渉する。
移行戦略と長期ロードマップ
Inferactの1億5000万ドルの資金調達はvLLMの市場機会を検証するが、成功には規律ある運用化が必要である。推論最適化は、戦術的なコスト削減策ではなく、段階的なロールアウトと継続的な測定を必要とする複数四半期にわたる移行である。
12ヶ月間で30%の推論コスト削減を目標とするプラットフォームは、次のように採用を段階的に進める可能性がある:パイロット(1〜2ヶ月目)、カナリア(3〜4ヶ月目)、段階的ロールアウト(5〜10ヶ月目)、完全本番(11〜12ヶ月目)。月次レビューでは、コスト、レイテンシ、エラー率を目標に対して追跡し、各ゲートでゴー/ノーゴー決定を行う。
- 移行を成功させるために:* ビジネスサイクルに合わせた12ヶ月のロードマップを作成する。経営陣のスポンサーシップと予算を確保する。移行を担当する部門横断チーム(プラットフォームエンジニアリング、MLオペレーション、財務)を割り当てる。Inferactとの月次運営会議を設定する。既存システムとの2〜3ヶ月の並行運用を計画する。12ヶ月目までに、総所有コスト、ユーザーエクスペリエンスの改善、運用オーバーヘッドを測定し、更新条件と将来のプラットフォーム決定に情報を提供する。
システムアーキテクチャとパフォーマンスボトルネック
vLLMのアーキテクチャは、トランスフォーマー推論における3つの特定のボトルネックを対象としている:GPUメモリの断片化、リクエストバッチングの非効率性、異種ワークロード下での可変GPU利用率。
-
主張:* 標準的なトランスフォーマー推論システムは、静的なメモリ割り当てパターンにより、GPU容量を40〜50%利用していない。
-
技術的根拠:* 従来の推論エンジンは、バッチ内のすべてのリクエストに対して最大シーケンス長のGPUメモリを事前に割り当てる。100〜2,000トークンの範囲のシーケンス長を持つ32リクエストのバッチの場合、32リクエストすべてが2,000トークンのバッファを予約し、短いシーケンスに対して割り当てられたメモリの約60%を無駄にする。vLLMのページドアテンションメカニズムは、固定サイズのブロック(例:ブロックあたり16トークン)でメモリを割り当て、OSの仮想メモリと同様に、論理ページを物理ページに動的にマッピングする。これにより以下が可能になる:
-
固定メモリ予算内でのより大きなバッチサイズ
-
メモリ断片化による一時停止時間のオーバーヘッドの削減
-
可変ワークロード条件下でのより予測可能なレイテンシ
-
前提を含む具体例:* デプロイメントシナリオ:4台のNVIDIA A100 GPU(各80GB、合計320GB)、バッチサイズ32で7Bパラメータモデルを提供。ベースラインシステム:p99レイテンシ250ms、ピーク負荷時のGPU利用率45%。vLLMデプロイメント:p99レイテンシ120ms、GPU利用率72%(前提:ページングオーバーヘッドは計算時間の5〜8%;実際のオーバーヘッドはメモリ帯域幅とブロックサイズ構成に依存)。これは、同じハードウェアフットプリント内で50〜60%多くの同時リクエストを処理できることを意味する。
-
前提条件と制限事項:*
-
パフォーマンスの向上は、リクエスト到着率が比較的スムーズであることを前提とする;バースト性のあるトラフィックはページング効率を低下させる可能性がある
-
非常に高い利用率(GPU利用率>85%)では、メモリ帯域幅がボトルネックになる
-
カスタムモデルアーキテクチャまたは量子化スキームは、vLLMのページングメカニズムと互換性がない場合がある
-
レイテンシの改善は、大きなバッチサイズと可変シーケンス長を持つモデルで最も顕著である;固定された短いシーケンスを持つモデルでは最小限の向上しか見られない可能性がある
-
実行可能なガイダンス:* ピーク同時実行期間中の現在のGPU利用率メトリクスを監査する。利用率が一貫して70%を下回る場合、アーキテクチャの非効率性がもっともらしい根本原因である。Inferactに以下を提供するよう要求する:
- 特定のモデルとバッチサイズに対するメモリ効率ベンチマーク(実際に使用されたメモリと割り当てられたメモリ)
- 合成ベンチマークではなく、現実的なトラフィックパターン下でのテールレイテンシパーセンタイル(p95、p99、p99.9)
- モデルアーキテクチャ、量子化スキーム、カスタム推論カーネルの互換性評価
- 明示的に文書化された前提を含む、リクエストあたりの推定コストとスループット改善
参照アーキテクチャとデプロイメントガードレール
Inferactの商用化は、異種エンタープライズ環境全体でvLLMが予測可能に動作することを保証するために、明示的なデプロイメントガードレールを確立する必要がある。これらのガードレールがなければ、パフォーマンスは予測不可能になり、サポートコストが増大する。
-
主張:* 運用制約のない推論最適化は、デプロイメントリスクと持続不可能なサポート負担を生み出す。
-
根拠:* vLLMのパフォーマンスは、ワークロード特性(リクエスト到着率、シーケンス長分布、モデルサイズ、GPUメモリ容量)に決定的に依存する。不適合なデプロイメント(例:ページング効率を超える非常に長いシーケンス、バースト性のあるトラフィックパターン、サイズ不足のGPUクラスター)は、ベースラインシステムを下回るパフォーマンスを低下させる。Inferactは、以下を指定する参照アーキテクチャを公開する必要がある:
-
サポートされているハードウェア構成(GPUタイプ、メモリ容量、相互接続帯域幅)
-
vLLMが最適化されているワークロード特性(リクエスト同時実行範囲、シーケンス長分布、モデルパラメータ数)
-
各構成のパフォーマンス期待値(レイテンシパーセンタイル、スループット、リクエストあたりのコスト)
-
ワークロードが設計パラメータを超えた場合のフォールバック動作とグレースフルデグラデーション戦略
-
明示的な前提を含む具体例:* 参照アーキテクチャ:4台のNVIDIA A100 GPU(80GB)、7Bパラメータモデルを提供、200同時リクエスト、平均シーケンス長500トークン。期待されるパフォーマンス:p99レイテンシ120ms、スループット1,200トークン/秒、リクエストあたり0.0008ドル。このアーキテクチャは以下に対して検証されている:
-
最大500リクエスト/秒のリクエスト到着率(ポアソン分布)
-
シーケンス長100〜1,500トークン(95パーセンタイル)
-
バッチサイズ32〜64
-
推論時間が総リクエストレイテンシの80%未満(前提:残りの20%はネットワーク、キューイング、アプリケーションオーバーヘッド)
-
前提条件とエッジケース:*
-
2,000トークンを超えるシーケンスはメモリ圧迫を引き起こす可能性がある;ベースラインシステムへのフォールバックを推奨
-
バースト性のあるトラフィック(変動係数>2.0)はキューの深さを超える可能性がある;オートスケーリングが必要
-
13Bパラメータより大きいモデルは2倍のGPUメモリを必要とする;参照アーキテクチャを調整する必要がある
-
カスタム量子化スキーム(例:GPTQ、AWQ)は互換性検証が必要;すべてのスキームがサポートされているわけではない
-
実行可能なガイダンス:* Inferactの提供を採用する前に:
- ワークロードが公開されている参照アーキテクチャと一致することを検証する。2〜4週間の本番トラフィックデータを収集する:リクエスト到着率分布、シーケンス長パーセンタイル(p50、p95、p99)、モデルサイズ。
- トラフィックパターンを取り込み、信頼区間を含むハードウェア構成を推奨する事前デプロイメント評価ツールをInferactに提供するよう要求する。
- SLAを明示的に定義する:許容可能なp99レイテンシ、スループット目標、コストベースライン、許容可能なエラー率。これらを書面で文書化する。
- 標準デプロイメントでカバーされていないエッジケースに対する明確なエスカレーションパスを確立する。サポートチケットの応答時間を交渉する(例:重大な問題は4時間以内)。
- サポートされているモデルアーキテクチャ、量子化スキーム、ハードウェア構成を文書化した書面による互換性マトリックスを要求する。Inferactに四半期ごとにこれを更新するよう要求する。
実装と運用パターン
vLLMの商用化を成功させるには、カナリアデプロイメント、オートスケーリング、グレースフルデグラデーションという3つのデプロイメントパターンを運用可能にする必要があります。これらのパターンは本番環境のリスクを最小化し、パフォーマンス目標が達成されない場合の迅速なロールバックを可能にします。
-
主張:* 推論システムの移行は、SLAコンプライアンスを維持するために段階的なロールアウトと動的な負荷分散をサポートする必要があります。
-
根拠:* 推論バックエンドの切り替えは、ユーザー向けのレイテンシとエラー率に即座に影響を与えます。カナリアデプロイメントは、最初にトラフィックの小さな割合(5〜10%)を新しいシステムにルーティングし、完全な切り替え前にレイテンシと精度の統計的検証を可能にします。オートスケーリングは、キューの深さとテールレイテンシメトリクスに基づいてレプリカ数を調整します。グレースフルデグラデーションは、プライマリシステムが飽和状態になった場合に過剰なトラフィックをフォールバックプロバイダーにルーティングし、カスケード障害を防ぎます。
-
前提条件を含む具体例:* チャットボットプラットフォームの移行シナリオ:
-
第1週: リクエストの5%をInferactのvLLMクラスターにルーティング。Welchのt検定(有意水準α=0.05)を使用して、ベースラインとレイテンシ分布(p50、p99、p99.9)およびエラー率を比較。レイテンシの10%以上の改善とエラー率の同等性(差<0.1%)を要求。
-
第2〜3週: トラフィックを25%、次に50%に増加し、各ステップでメトリクスを検証。
-
第4週: すべてのメトリクスが合格した場合、vLLMへの完全な切り替え。2週間はベースラインクラスターをフォールバックとして維持。
-
自動ロールバックトリガー: p99レイテンシがベースラインを20%以上超えるか、エラー率がベースラインを0.5%以上超える場合、5分以内にトラフィックの50%をベースラインに戻す。
-
前提条件と運用要件:*
-
サービスメッシュ(Envoy、Istio)またはアプリケーションレベルのルーティングは、サブ秒の粒度でトラフィック分割をサポートする必要があります
-
モニタリングインフラストラクチャは、1分未満の集約ウィンドウでリクエストレベルのレイテンシ、エラー率、モデルスループットをキャプチャする必要があります
-
ランブックは、一般的な障害モード(GPUメモリ圧迫、ネットワーク飽和、モデル読み込み遅延)と回復手順を文書化する必要があります
-
オンコール手順には、定義された応答時間を持つInferactサポートエスカレーションパスを含める必要があります
-
実行可能なガイダンス:*
- Inferactとの12週間にわたる段階的な採用ロードマップを確立します。定量的メトリクスに基づいて各フェーズでgo/no-go基準を定義します。
- サービスメッシュまたはアプリケーションレベルのルーティングを使用して自動トラフィックステアリングを実装します。本番環境へのデプロイメント前にステージング環境でフェイルオーバー手順をテストします。
- Inferactに一般的な障害モードのランブックを提供するよう要求します。これには以下が含まれます:
- GPUメモリ不足エラー: 予想される頻度、緩和戦略、回復時間
- ネットワークレイテンシスパイク: 許容可能なしきい値とフォールバック動作
- モデル読み込み遅延: 予想される期間とリクエストレイテンシへの影響
- 最初の1か月間は毎週レビューをスケジュールし、運用のドリフトを早期に検出します。予測から10%以上のメトリクス偏差をエスカレートします。
- 切り替え後4週間はベースライン推論クラスターをフォールバックとして維持します。恒久的な廃止の決定基準を文書化します。
測定フレームワークとビジネスメトリクス
推論最適化の定量化には、技術メトリクスとビジネス成果の両方を追跡する必要があります。技術的改善は、コストを削減し、ユーザーエクスペリエンスを向上させ、または新しい機能を可能にする場合にのみ価値があります。
-
主張:* 推論の改善は、測定可能でビジネス成果に明確に結びついている場合にのみ正当化されます。
-
根拠:* 技術メトリクス(レイテンシ、スループット、GPU使用率)はビジネス成果(リクエストあたりのコスト、ユーザー満足度、収益への影響)にマッピングする必要があります。40%のレイテンシ削減は、コストを削減したりユーザー満足度を向上させたりしない場合、戦略的に無関係です。Inferactの提供には、エンドツーエンドの追跡とビジネスメトリクスの帰属のための計装が含まれている必要があります。
-
測定フレームワーク:*
-
技術メトリクス(ベースラインおよびデプロイメント後):*
-
リクエストレイテンシ: p50、p95、p99、p99.9パーセンタイル(ミリ秒)
-
スループット: 秒あたりのトークン数、秒あたりのリクエスト数
-
GPU使用率: ピーク同時実行期間中の平均およびピーク(パーセンテージ)
-
エラー率: 総リクエスト数に対する失敗したリクエストの割合
-
モデル読み込み時間: リクエスト到着から最初のトークン生成までの時間(ミリ秒)
-
ビジネスメトリクス(ベースラインおよびデプロイメント後):*
-
リクエストあたりのコスト: 総インフラストラクチャコスト(コンピュート、ストレージ、ネットワーキング)をリクエスト量で割った値
-
トークンあたりのコスト: 総コストを生成された出力トークンで割った値
-
ユーザー満足度: 調査またはプロキシメトリクス(例: セッション期間、リピート率)で測定
-
収益への影響: 改善されたレイテンシまたは削減されたコストによって可能になった増分収益
-
明示的な前提条件を含む具体例:*
-
ベースライン(4週間): リクエストあたり$0.002、p99レイテンシ250ms、ユーザー満足度92%、月間推論コスト$2M
-
vLLM後(4週間): リクエストあたり$0.0008、p99レイテンシ120ms、満足度96%、月間推論コスト$800K
-
コスト削減: ($0.002 − $0.0008) × 1M リクエスト/日 × 365日 = 年間$438Kの節約
-
Inferactライセンスコスト(仮定): 年間$150K
-
正味年間節約: $438K − $150K = $288K
-
ROI: 初年度192%(仮定: 追加の運用オーバーヘッドなし。実際のROIはデプロイメントとモニタリングのエンジニアリング時間に依存)
-
前提条件と注意事項:*
-
コスト削減は安定したリクエスト量を前提としています。デプロイメント後に量が増加すると、リクエストあたりのコストは変わらないように見える場合があります
-
ユーザー満足度の改善は他の要因(例: 同時進行の製品改善)によって混同される可能性があります。vLLMの影響を分離するためにA/Bテストを使用してください
-
ライセンスコストは規模とともに増加する可能性があります。インセンティブを調整するために段階的な価格設定またはリクエストごとの料金を交渉してください
-
運用オーバーヘッド(モニタリング、ランブック、サポート)は技術的コスト削減の10〜20%を相殺する可能性があります
-
実行可能なガイダンス:*
- デプロイメント前に測定フレームワークを確立します。2〜4週間、少なくとも100万リクエストをキャプチャして、本番ワークロード全体のベースラインメトリクスを定義します。
- OpenTelemetryまたは同等のものを使用してInferactのデプロイメントを計装し、リクエストレベルのレイテンシ、モデルスループット、エラー率、GPU使用率をキャプチャします。メトリクスを観測可能性プラットフォーム(Prometheus、Datadogなど)にエクスポートします。
- インフラストラクチャ(コンピュート、ストレージ、ネットワーキング)とライセンスを含むリクエストあたりのコストを追跡します。共有コスト(プラットフォームエンジニアリング、オンコールサポート)を比例配分します。
- デプロイメント後60日で決定ゲートを設定します: コスト削減が予測の30%を下回るか、レイテンシが25%改善しない場合、Inferactとの正式なレビューを開始して根本原因を特定します。30日以内に問題を解決できない場合はベースラインに戻します。
- これらのメトリクスを四半期ごとにInferactと共有し、パフォーマンス目標を調整し、最適化の機会を特定します。メトリクスを使用して更新条件とボリュームディスカウントを交渉します。
リスク評価と緩和戦略
Inferactの商用化の成功は、技術リスク、運用リスク、市場採用リスクという3つのリスクカテゴリーの管理に依存しています。初期段階の推論スタートアップは、強力な基盤技術にもかかわらず、大きな摩擦に直面しています。
-
主張:* 既存のベンダー関係とスイッチングコストからの採用摩擦は、Inferactの成長軌道に重大なリスクをもたらします。
-
技術リスク:*
-
リスク:* vLLMがベースラインシステムを下回るエッジケース。
-
顕在化: 非常に長いシーケンス(>4,000トークン)、スパースモデル、カスタム量子化スキーム、または独自のモデルアーキテクチャは、vLLMのページングメカニズムと互換性がない場合があります。
-
緩和: Inferactにサポートされている構成を文書化した公開互換性マトリックスを維持するよう要求します。パフォーマンス保証を交渉します: vLLMがワークロードでベースラインを10%以上下回る場合、Inferactはパフォーマンス目標が達成されるまで無償でエンジニアリングサポートを提供するか、返金を提供します。
-
リスク:* 極端な負荷下でのレイテンシテールの劣化。
-
顕在化: GPU使用率が80%を超えると、メモリ帯域幅がボトルネックになり、p99レイテンシがベースラインを超えてスパイクする可能性があります。
-
緩和: 使用率が75%を超える前にトリガーされるオートスケーリングポリシーを確立します。Inferactにピークトラフィックパターンをシミュレートし、ストレス下でレイテンシを検証する負荷テストツールを提供するよう要求します。
-
運用リスク:*
-
リスク:* 不十分な運用サポートとランブックカバレッジ。
-
顕在化: 文書化されていない障害モード、遅いサポート応答時間、またはInferactエンジニアリングへのエスカレーションパスの欠如。
-
緩和: 明確なSLAを交渉します: 重大な問題(p99レイテンシがベースラインの2倍以上)は4時間以内に解決。主要な問題は24時間以内に解決。ピークトラフィック時間中にInferactがオンコールサポートを提供するよう要求します。最初の1か月間は毎週、その後は毎月開催される共同運営委員会を設立します。
-
リスク:* モニタリングと観測可能性のギャップ。
-
顕在化: Inferactのパフォーマンスとビジネスメトリクスを相関させることができない。レイテンシスパイクの根本原因を診断することが困難。
-
緩和: InferactにOpenTelemetry計装とダッシュボードを提供するよう要求します。すべての重要なメトリクス(GPU使用率、キューの深さ、リクエストレイテンシ)がキャプチャされ、観測可能性プラットフォームにエクスポートされることを検証します。
-
市場採用リスク:*
-
リスク:*
システムアーキテクチャと運用制約
vLLMは推論システムにおける3つの特定のボトルネックに対処します: メモリの断片化、リクエストバッチング非効率、GPU使用率の変動。vLLMの利点はワークロードに依存するため、これらの制約を理解することが不可欠です。
- メモリ断片化の問題*
標準的なトランスフォーマー推論は、部分的なバッチを処理する場合でも、完全なシーケンス長のGPUメモリを事前に割り当てます。平均シーケンス長が500トークンの10個のリクエストのバッチは、最大長(例えば2,000トークン)で10個すべてのメモリを予約します。これにより断片化が発生します: 割り当てられたメモリの75%が未使用のまま残ります。vLLMのページングメカニズムは、実際に必要なメモリのみを割り当て、より高いバッチ使用率を可能にし、メモリ割り当て中の一時停止時間のオーバーヘッドを削減します。
- ワークロードへの実用的な影響*
vLLMの利点は、トラフィック特性に大きく依存します:
-
可変シーケンス長: vLLMは、リクエストが異種のシーケンス長を持つ場合に優れています。ワークロードが均一なシーケンス長を持つ場合、メモリ効率の向上は減少します。
-
高い同時実行性: vLLMの利点は同時リクエスト量とともにスケールします。低同時実行性ワークロード(<10同時リクエスト)の場合、利点は運用の複雑さを正当化しない可能性があります。
-
モデルサイズ: より大きなモデル(70B+パラメータ)は、より小さなモデル(7Bパラメータ)よりもメモリ最適化から多くの利益を得ます。
-
現在の状態を監査する*
Inferactを採用する前に、以下を測定します:
- GPU使用率分布: 2週間、すべての本番推論インスタンスの使用率を追跡します。50、90、99パーセンタイルの使用率値を計算します。
- バッチサイズ分布: ピーク時間中のバッチサイズの分布をログに記録します。バッチが一貫して小さい(<8リクエスト)場合、vLLMの利点は制限される可能性があります。
- シーケンス長分布: シーケンス長の変動係数(標準偏差/平均)を測定します。高い変動は、より高いvLLM利益の可能性を示します。
- 現在のレイテンシプロファイル: 本番ワークロードのベースラインp50、p99、p99.9レイテンシパーセンタイルを確立します。
使用率のピークが70%未満でバッチサイズの平均が16リクエストを超える場合、アーキテクチャの非効率性が制約です。使用率のピークが85%を超え、バッチサイズが小さい場合、メモリバウンドではなくGPUバウンドである可能性があり、vLLMの利点は小さくなります。
測定フレームワークとROI定量化
推論最適化は、測定可能でビジネス成果に結びついている場合にのみ価値があります。技術メトリクス(レイテンシ、スループット)はビジネスへの影響(リクエストあたりのコスト、ユーザーエクスペリエンス、収益)にマッピングする必要があります。
- ベースラインメトリクス(デプロイメント前)*
Inferactデプロイメントの4週間前にベースラインメトリクスを確立します:
- リクエストあたりのコスト: 総推論支出/処理された総リクエスト数。モデルサイズとリクエストタイプでセグメント化。
- レイテンシパーセンタイル: 各モデルのp50、p99、p99.9レイテンシ。エンドツーエンドのレイテンシ(リクエスト受信から応答送信まで)を測定。
- スループット: ピーク時間とオフピーク時間の秒あたりのリクエスト数。
- エラー率: 失敗したリクエスト/総リクエスト数。エラータイプ(タイムアウト、OOM、モデルエラー)でセグメント化。
- ユーザー満足度: 該当する場合、ユーザー向けメトリクス(応答時間の認識、機能採用、レイテンシに関連するサポートチケット)を測定。
- デプロイメント後のメトリクス*
Inferactデプロイメント後、4週間同じメトリクスを測定します:
- リクエストあたりのコスト: vLLMがワークロードに効果的である場合、30〜60%減少するはずです。
- レイテンシパーセンタイル: メモリ効率がボトルネックである場合、20〜40%減少するはずです。
- スループット: 同じレイテンシ目標を維持する場合、30〜50%増加するはずです。
- エラー率: 安定したままか減少するはずです(vLLMは新しいエラーモードを導入すべきではありません)。
- ユーザー満足度: レイテンシの改善がユーザー向けである場合、改善するはずです。
- ROI計算*
1日あたり100万リクエストのプラットフォームの計算例:
-
ベースライン: リクエストあたり$0.002、p99レイテンシ250ms、ユーザー満足度92%。
-
vLLM後: リクエストあたり$0.0008、p99レイテンシ120ms、満足度96%。
-
コスト削減: ($0.002 − $0.0008) × 1M リクエスト/日 × 365日 = 年間$438Kの節約。
-
Inferactライセンスコスト: 年間$150Kと仮定(ボリュームに基づいて交渉)。
-
正味年間節約: $438K − $150K = $288K。
-
回収期間: $150K / ($438K / 12) = 4.1か月。
-
決定ゲート*
60日と90日で決定ゲートを確立します:
-
60日ゲート: コスト削減が30%未満またはレイテンシ改善が25%未満の場合、ベースラインに戻して再評価します。Inferactと根本原因を調査します。
-
90日ゲート: コスト削減が40%未満またはレイテンシ改善が35%未満の場合、代替推論プラットフォームを検討します。
-
6か月ゲート: コスト削減が50%未満またはレイテンシ改善が40%未満の場合、契約更新を評価します。
-
継続的なモニタリング*
OpenTelemetryまたは同等のものを使用して継続的なモニタリングを実装します:
- すべての推論リクエストをリクエストID、モデル名、入力トークン、出力トークン、レイテンシ、コストで計装します。
- メトリクスを時系列データベース(Prometheus、InfluxDB)にエクスポートします。
- リクエストあたりのコスト、レイテンシパーセンタイル、スループットトレンドを示すダッシュボードを作成します。
- コストまたはレイテンシの後退(ベースラインから10%以上の変化)のアラートを設定します。
リスクカテゴリーと軽減戦略
Inferactの商業化の成功は、技術的リスク、運用リスク、市場採用リスクという3つのリスクカテゴリーの管理にかかっています。
- 技術的リスク*
-
モデル互換性: vLLMのページングメカニズムは、カスタムモデルアーキテクチャ、量子化スキーム、または特殊なカーネルをサポートしない可能性があります。軽減策:Inferactに公開互換性マトリックスを要求してください。本番環境への展開前にモデルの互換性テストを実施してください。エッジケースをカバーするサポートSLAを交渉してください。
-
パフォーマンスのエッジケース: vLLMは、非常に長いシーケンス(4,000トークン超)、スパースモデル、または異常なバッチサイズ分布において性能が低下する可能性があります。軽減策:Inferactにエッジケースのパフォーマンス劣化曲線の公開を要求してください。これらの曲線に対してワークロードをテストしてください。エッジケース用のフォールバックルーティングを確立してください。
-
量子化の影響: モデルがカスタム量子化スキームを使用している場合、vLLMがそれらをサポートしないか、精度のドリフトを引き起こす可能性があります。軽減策:vLLM展開の前後で推論精度を検証してください。統計的検定(例:コルモゴロフ・スミルノフ検定)を使用して精度のドリフトを検出してください。精度が低下した場合のロールバック手順を確立してください。
- 運用リスク*
-
ベンダーロックイン: Inferactの独自最適化により、代替推論プラットフォームへの移行が必要になった場合にスイッチングコストが発生する可能性があります。軽減策:Inferactに標準推論API(例:OpenAI互換API、vLLMのネイティブAPI)のサポートを要求してください。ロックインを増加させる独自拡張機能を避けてください。90日前の通知で退出を可能にする契約条件を交渉してください。
-
サポートとエスカレーション: 初期段階のスタートアップは、成熟したサポートインフラストラクチャを欠いている可能性があります。軽減策:応答時間(重大な問題については4時間未満)、解決時間(重大な問題については24時間未満)、およびエスカレーションパスをカバーする明確なSLAを交渉してください。パイロットフェーズ中にInferactのエンジニアリングチームへのアクセスを要求してください。月次で開催される共同運営委員会を設立してください。
-
運用の複雑性: vLLMを推論スタックに統合すると、運用負担(監視、自動スケーリング、ランブックのメンテナンス)が増加します。軽減策:Inferactにターンキー監視ダッシュボードと自動スケーリングテンプレートの提供を要求してください。vLLM運用を担当する専任チームメンバーを割り当ててください。2〜3週間のトレーニングと知識移転を計画してください。
- 市場採用リスク*
-
競合による置き換え: より大規模な推論プロバイダー(OpenAI、Anthropic、クラウドプロバイダー)がvLLMのような最適化を自社のサービスに統合し、Inferactの価値提案を商品化する可能性があります。軽減策:Inferactの長期的な差別化戦略を評価してください。潜在的な商品化を考慮した価格条件を交渉してください。競合サービスが登場した場合に切り替えられる柔軟性を維持してください。
-
ワークロードの進化: 推論ワークロードが、vLLMの利点を減少させる方向に進化する可能性があります(例:より長いシーケンスへのシフト、低い同時実行性)。軽減策:ワークロード特性とvLLMパフォーマンスの四半期ごとのレビューを確立してください。展開を調整したり、ベースラインに戻したりする柔軟性を維持してください。
-
Inferactの財務的実行可能性: 初期段階のスタートアップは、資金調達と収益性のリスクに直面しています。軽減策:Inferactの資金調達ランウェイと収益性への道筋を評価してください。Inferactが買収されたり閉鎖されたりした場合に退出を可能にする契約条件を交渉してください。代替推論プロバイダーとの関係を維持してください。
- リスク軽減チェックリスト*
Inferactと契約する前に:
- モデルアーキテクチャと量子化スキームの公開互換性マトリックスを要求する。
- 非重要なワークロードで2週間のパイロットを実施し、パフォーマンスと運用安定性を検証する。
- 応答時間をカバーする明確なSLAを交渉する。
8億ドルの評価額と市場ポジショニング:推論経済学の転換点
Inferactの8億ドルの評価額での1億5000万ドルのシードラウンドは、投資家の信頼以上のものを表しています。それは、今後10年間で企業がAIインフラストラクチャをどのように設計するかにおける根本的なシフトを示しています。この評価額は、解決された技術的問題が急性の市場需要に応えることの認識を反映していますが、さらに重要なことに、新しいフロンティアを開きます:大規模な推論効率の民主化です。
-
論点:* 8億ドルの評価額は、vLLMの現在の最適化ポテンシャルだけでなく、コストとレイテンシが競争上の堀となる推論インフラストラクチャという新興カテゴリーを捉えています。
-
これが重要な理由:* 本番環境の推論は、展開されたLLMシステムの総運用コストの60〜80%を消費します。このコスト構造は、トランスフォーマーモデルが本番環境に入って以来、ほとんど変わっておらず、企業のAI展開全体で年間500億ドル以上の効率化機会を生み出しています。vLLMのページドアテンションメカニズムは単に最適化するだけでなく、メモリを固定割り当てではなく仮想化されたリソースとして扱うことで、GPU経済学を根本的に再構築します。現在GPU当たり10の同時リクエストを処理している組織は、同等のハードウェアで50〜60を処理でき、3年間でコスト曲線を5〜10倍圧縮できます。
-
具体的なシナリオ:* 現在、サードパーティAPIを通じて月額200万ドルを推論に費やしている中堅SaaSプラットフォーム(リクエスト当たり0.002ドル)は、vLLM最適化インフラストラクチャを通じてこれを月額20〜30万ドルに削減できます(リクエスト当たり0.0002〜0.0003ドル)。この年間170万ドルの節約は、年間50〜100万ドルのインフラストラクチャ投資を正当化し、即座にROIを生み出し、製品イノベーションのための資本を解放します。
-
ナレッジワーカーへの戦略的示唆:* この評価額は、インフラストラクチャ決定のための新しいプレイブックを検証します。ベンダー価格を固定として受け入れるのではなく、組織は推論プラットフォームをvLLMの効率向上に対してベンチマークし、これらのベンチマークをベンダー交渉のレバレッジとして使用すべきです。今後18か月間で、推論アーキテクチャを再評価する企業の波が見られるでしょう。最初に動く企業は、競合他社が追いつく前に12〜24か月のコスト優位性を獲得します。ピーク同時実行負荷、モデルミックス(7Bから70Bパラメータ)、およびトラフィックパターン(バースト対定常状態)をターゲットとした、Inferactからの詳細な概念実証展開を要求してください。これらのベンチマークを使用して、既存プロバイダーと再交渉するか、内部プラットフォーム投資を正当化してください。
システムアーキテクチャ:次の効率フロンティアの解放
vLLMのアーキテクチャは、3年間推論効率を制約してきた3つの連鎖するボトルネックを解決します:メモリの断片化、リクエストバッチング非効率、およびGPU利用率の変動です。これらを合わせると、現在のシステムに40〜50%の効率税が課されます。Inferactの商業化によって排除できる税です。
-
核心的洞察:* 既存の推論システムがGPU容量を無駄にするのは、アルゴリズムの制限のためではなく、メモリを静的に割り当てるためです。標準的なトランスフォーマー推論は、部分的に埋められたバッチであっても、完全なシーケンス長のメモリを事前に予約します。可変シーケンス長(100〜2,000トークン)の32リクエストのバッチは、32すべてに対して2,000トークンのメモリを予約し、GPUメモリの約60%を無駄にします。この断片化は連鎖します:バッチ利用率が低いということは、同時リクエストが少なくなり、リクエスト当たりのレイテンシが高くなり、GPUスループットが低くなることを意味します。
-
vLLMのイノベーション:* ページドアテンションは、GPUメモリをオペレーティングシステムの仮想メモリのように扱います。固定サイズのブロック(例:16KBページ)で割り当て、論理ページを物理ページに動的にマッピングします。これにより動的バッチングが可能になります:リクエストが完了すると、そのメモリページが解放され、新しいリクエストに再割り当てされます。結果:以前は32をサポートしていたのと同じメモリフットプリントで50〜60の同時リクエストを処理でき、レイテンシの変動が30〜40%低くなります。
-
具体的な展開シナリオ:* 4台のA100 GPU(合計320GBメモリ)にvLLMを展開する顧客は、以下を維持できます:
-
7Bパラメータモデル(Mistral、Llama-2-7B)で200の同時リクエスト
-
13Bモデル(Llama-2-13B)で80の同時リクエスト
-
70Bモデル(Llama-2-70B)で30の同時リクエスト
これを同一ハードウェア上の従来の推論システムと比較してください:それぞれ40、15、5の同時リクエストです。効率向上はフリート全体で複合されます。70Bモデルを実行する10台のGPUクラスターは、250の追加同時リクエスト容量を獲得し、追加ハードウェアなしで2〜3台のGPU相当のスループットを追加することに相当します。
- 運用上の示唆:* Inferactのサービスを評価する際は、ピークトラフィック期間中の現在のGPU利用率メトリクスを監査してください。利用率のピークが70%未満の場合、アーキテクチャの非効率性が主要な制約であり、ハードウェア容量ではありません。Inferactに以下を示す詳細なベンチマークを要求してください:
- モデルサイズ全体のメモリ効率比(実際に使用されたメモリ対割り当てられたメモリ)
- 現実的なワークロード下でのテールレイテンシパーセンタイル(p99、p99.9)
- 現在のシステムに対するスループット向上
- 最適化前後のリクエスト当たりのコスト
Inferactの商業化には、これらのメトリクスをリアルタイムで公開するターンキー監視ダッシュボードを含め、効率向上を継続的に追跡し、財務チームへのインフラストラクチャ投資を正当化できるようにする必要があります。
リファレンスアーキテクチャと運用ガードレール:展開のリスク軽減
Inferactの技術的イノベーションは必要ですが、企業採用には不十分です。同社は、異なるハードウェア、トラフィックパターン、モデルアーキテクチャにわたってvLLMが予測可能に動作することを保証する展開ガードレールを確立する必要があります。
-
重要な課題:* vLLMの利点はワークロード特性に依存します。リクエスト到着率、シーケンス長分布、モデルサイズが、ページドアテンションが5倍の効率向上をもたらすか、わずか20%の改善をもたらすかを決定します。不一致の展開(例:非常に長いシーケンス、長いアイドル期間を伴うバーストトラフィック)は、従来のシステムに対してパフォーマンスを低下させ、顧客の不満を生み出し、採用を制限する可能性があります。
-
ガードレールフレームワーク:* Inferactは、以下を指定するリファレンスアーキテクチャを公開すべきです:
- モデルサイズと同時実行ターゲット別のハードウェア要件(例:「200の同時7Bリクエストには4台のA100」)
- トラフィックパターン互換性(定常状態対バースト、シーケンス長分布、リクエスト到着率)
- モデルアーキテクチャサポート(標準トランスフォーマー、量子化モデル、カスタムカーネル)
- フォールバック動作(vLLMが飽和したときの段階的劣化、バックアップシステムへの自動トラフィック誘導)
- コストベースライン(インフラストラクチャコスト、ライセンス、運用オーバーヘッド)
-
具体例:* 営業時間中にバーストトラフィック(毎秒100リクエスト、夜間は毎秒5リクエスト)を持つカスタマーサポートチャットボット用にvLLMを展開する顧客は、定常状態のレコメンデーションエンジン(24時間365日毎秒50リクエスト)とは異なるガードレールが必要です。チャットボットは積極的なバッチングとより長いレイテンシ許容度から恩恵を受ける可能性があります。レコメンデーションエンジンは100ms未満の一貫したp99レイテンシを必要とします。明示的なガイダンスがなければ、顧客は過剰プロビジョニングまたはサイズ不足を行い、コストまたは信頼性の問題を引き起こす可能性があります。
-
採用戦略:* Inferactにコミットする前に、ワークロードが公開されたリファレンスアーキテクチャと一致することを検証してください。SLAを明示的に定義してください:
-
許容可能なp99およびp99.9レイテンシ(例:顧客向けは150ms未満、バッチは500ms未満)
-
スループットターゲット(毎秒リクエスト数またはトークン数)
-
コストベースライン(現在の支出、目標支出、許容可能なROIタイムライン)
-
エラー率許容度(例:0.1%未満のエラー率)
トラフィックパターン(リクエスト到着率、シーケンス長分布、モデルミックス)を取り込み、構成を推奨する展開前評価ツールをInferactに提供するよう要求してください。このツールは以下を出力する必要があります:
- 推奨ハードウェア(GPUタイプ、数、メモリ)
- 予想されるスループットとレイテンシ
- 推定月額コスト
- リスク要因(例:「トラフィックの60%がバーストです。20%のハードウェアヘッドルームを検討してください」)
標準展開でカバーされていないエッジケースのための明確なエスカレーションパスを確立してください。パイロットフェーズ中に共同エンジニアリングエンゲージメントを交渉し、仮定を検証し、技術的障害に早期に対処してください。
実装と運用パターン:大規模推論の運用化
vLLMの商業化を成功させるには、3つの重要なパターンを運用化する必要があります:カナリア展開、自動スケーリング、段階的劣化です。これらのパターンは本番環境のリスクを最小限に抑え、組織がInferactの技術を自信を持って採用できるようにします。
- パターン1:カナリア展開*
推論バックエンドの切り替えは、SLAに即座に影響します。カナリア展開は、最初にトラフィックの5〜10%をvLLMにルーティングし、完全な切り替え前にレイテンシ、精度、エラー率を検証します。このパターンは、問題が発生した場合に迅速なロールバックを可能にすることでリスクを軽減します。
-
具体的な実装:* チャットボットプラットフォームは、1週間、リクエストの5%をInferactのvLLMクラスターにルーティングし、レイテンシ分布(p50、p95、p99)、エラー率、ユーザー満足度メトリクスをベースラインと比較します。検証後、トラフィックは25%(第2週)、50%(第3週)、次に100%(第4週)に増加します。p99レイテンシが500msを超えるか、エラー率が0.5%を超える場合、トラフィックは自動的にベースラインに戻ります。
-
パターン2:自動スケーリング*
推論ワークロードは本質的に可変です。自動スケーリングは、キューの深さとレイテンシパーセンタイルに基づいてレプリカ数を調整し、トラフィックスパイク中の一貫したパフォーマンスを確保しながら、オフピーク期間中のアイドル容量を最小限に抑えます。
-
具体的な実装:* Inferactの展開には、スケーリングポリシーが含まれます:「p99レイテンシが2分間200msを超える場合、1レプリカを追加します。p99レイテンシが5分間100ms未満の場合、1レプリカを削除します。」このポリシーは、インフラストラクチャコストを最小限に抑えながらSLAを維持します。トラフィックスパイク(例:バイラルソーシャルメディア投稿が10倍のトラフィックを駆動)中、システムは4レプリカから12レプリカに自動的にスケールし、トラフィックが正常化すると元に戻ります。
-
パターン3:段階的劣化*
自動スケーリングを使用しても、システムは飽和する可能性があります。段階的劣化は、vLLMが飽和した場合、過剰なトラフィックをフォールバックプロバイダー(例:OpenAI API、代替推論プラットフォーム)にルーティングし、リクエスト当たりのレイテンシまたはコストが高くなる代償で可用性を確保します。
-
具体的な実装:* InferactのvLLMクラスターが95%の容量に達し、(ハードウェア制約またはコスト制限により)さらにスケールできない場合、新しいリクエストは2〜3倍のコスト乗数でOpenAIのAPIにルーティングされます。これにより、インフラストラクチャのスケーリングが必要であることを運用チームに通知しながら、アプリケーションが利用可能な状態を維持します。
-
採用戦略:* Inferactとの12週間にわたる段階的採用ロードマップを確立してください:
-
第1〜2週(パイロット): トラフィックの5%をvLLMにルーティングし、レイテンシと精度を検証
-
第3〜4週(カナリア): トラフィックの25%をルーティングし、エッジケースを監視
-
第5〜8週(段階的ロールアウト): トラフィックの50〜75%をルーティングし、自動スケーリングポリシーを最適化
-
第9〜12週(本番環境): トラフィックの100%をルーティングし、運用ランブックを確立
各フェーズのメトリクスを定義してください:レイテンシ(p50、p95、p99)、スループット(毎秒リクエスト数)、エラー率、リクエスト当たりのコスト。サービスメッシュ(Envoy、Istio)またはアプリケーションレベルのルーティングを使用して、自動トラフィック誘導を実装してください。一般的な障害モードのランブックをInferactに提供するよう要求してください:
- GPUメモリ圧力(GPUメモリが使い果たされたときに何が起こるか?)
- ネットワーク飽和(GPUクラスターへの100msレイテンシでシステムはどのように動作するか?)
- モデル読み込み遅延(新しいモデルの読み込みにどのくらい時間がかかるか?読み込み中にリクエストをキューに入れることができるか?)
- レプリカ障害(システムは障害が発生したレプリカをどのくらい迅速に検出して置き換えるか?)
最初の月は毎週レビューをスケジュールして、運用のドリフトを早期に捉えてください。技術的障害に対処し、パフォーマンスターゲットを調整するために、Inferactとの共同運営委員会を設立してください。
測定とビジネスインパクト:推論革命の定量化
推論最適化は、測定可能でビジネス成果に結びついている場合にのみ価値があります。技術的指標(レイテンシ、スループット)は、ビジネス成果(リクエストあたりのコスト、ユーザー体験、収益への影響)にマッピングする必要があります。
-
測定フレームワーク:* Inferactの導入前に、本番ワークロード全体で2〜4週間のベースライン指標を確立します:
-
コスト指標: リクエストあたりのコスト、月間推論支出、ユーザーあたりのコスト
-
パフォーマンス指標: p50、p95、p99レイテンシ;スループット(リクエスト/秒);エラー率
-
ユーザー体験指標: ユーザー満足度(NPSまたはCSAT)、機能採用率、セッション時間
-
運用指標: GPU使用率、メモリ使用率、1日あたりのスケーリングイベント
-
具体的なベースラインシナリオ:*
-
コスト:リクエストあたり$0.002、月間支出$2M(10億リクエスト/月)
-
パフォーマンス:p99レイテンシ250ms、スループット1,000リクエスト/秒、エラー率0.1%
-
ユーザー体験:ユーザー満足度85%、機能採用率60%
-
運用:GPU使用率65%、メモリ使用率40%、1日あたり5回のスケーリングイベント
-
vLLM導入後のシナリオ(3ヶ月後):*
-
コスト:リクエストあたり$0.0008、月間支出$800K(10億リクエスト/月)
-
パフォーマンス:p99レイテンシ120ms、スループット2,500リクエスト/秒、エラー率0.05%
-
ユーザー体験:ユーザー満足度92%、機能採用率75%
-
運用:GPU使用率85%、メモリ使用率70%、1日あたり2回のスケーリングイベント
-
ROI計算:*
-
コスト削減:($0.002 − $0.0008) × 10億リクエスト/月 × 12ヶ月 = 年間$14.4Mの節約
-
ライセンスコスト:年間$150K(推定)
-
エンジニアリングコスト:$500K(1回限りの移行作業)
-
年間純節約額:$14.4M − $150K − $500K = $13.75M
-
戦略的インパクト:*
-
解放された資本:年間$14.4Mの節約により、2〜3人の追加プロダクトエンジニアを雇用可能
-
競争優位性:30%のコスト削減により、より積極的な価格設定またはより高い利益率が可能
-
ユーザー体験:50%のレイテンシ削減により、機能採用率とユーザー満足度が向上
-
計測戦略:* OpenTelemetryまたは同等のツールでInferactの導入を計測し、以下をキャプチャします:
-
リクエストレベルのレイテンシ(エンドツーエンド、モデル推論のみ、キューイング遅延)
-
モデルスループット(GPUあたりのトークン/秒)
-
エラー率(エラータイプ別:タイムアウト、メモリ不足、モデルエラー)
-
リクエストあたりのコスト(インフラストラクチャ + ライセンス)
-
ユーザー体験指標(機能採用率、セッション時間、満足度)
60日時点で意思決定ゲートを設定します:コスト削減が20%を超えない、またはレイテンシが20%改善しない場合は、元に戻して再評価します。これらの指標を四半期ごとにInferactと共有し、パフォーマンス目標を調整し、最適化の機会を特定します。
リスクと軽減戦略:採用フロンティアのナビゲート
Inferactの商業化の成功は、技術的、運用的、市場の3つのリスクカテゴリーの管理にかかっています。初期段階の推論スタートアップは、強力な技術にもかかわらず、大きな採用摩擦に直面しています。
- 技術的リスク:*
-
エッジケースのパフォーマンス低下: vLLMのページドアテンションメカニズムは、非常に長いシーケンス(>4,000トークン)、スパースモデル、またはカスタムモデルアーキテクチャでパフォーマンスが低下する可能性があります。軽減策がない場合、これらのワークロードを展開する顧客はパフォーマンスの後退を経験します。
- 軽減策:* Inferactに対して、サポートされているモデルアーキテクチャ、量子化スキーム、シーケンス長の範囲、ハードウェア構成を文書化した公開互換性マトリックスの維持を要求します。パフォーマンス保証を交渉します:vLLMがワークロードでベースラインより10%以上パフォーマンスが低下する場合、Inferactはパフォーマンス目標が達成されるまで無償でエンジニアリングサポートを提供します。
-
モデル互換性の問題: 企業は独自の量子化モデルやカスタムカーネルを実行することがよくあります。vLLMのページングメカニズムはこれらをサポートしない可能性があり、Inferactとカスタマーの両方からエンジニアリング作業が必要になります。
- 軽減策:* パイロットフェーズ中に、Inferactのエンジニアリングチームへのアクセスを要求し、モデルの互換性を検証します。必要に応じてカスタムカーネルサポートを開発するための共同エンジニアリング契約を確立します。明確なタイムラインとリソースコミットメントを交渉します。
-
精度の後退: 推論最適化は、時として微妙な数値的差異を導入します(例:量子化やバッチング効果による)。これらの差異により、モデル出力がベースラインから乖離し、下流アプリケーションに影響を与える可能性があります。
- 軽減策:* 代表的な入力サンプル全体でvLLM出力をベースラインと比較する自動精度テストを実装します。許容可能な精度閾値を定義します(例:出力の乖離<0.1%)。Inferactに対して、サポートされているすべてのモデルの精度ベンチマークを提供するよう要求します。
- 運用リスク:*
-
導入の複雑さ: Inferactの提供には、新しい運用パターン(カナリアデプロイメント、オートスケーリング、グレースフルデグラデーション)が必要です。これらのパターンに不慣れなチームは、vLLMを効果的に運用化するのに苦労する可能性があります。
- 軽減策:* トレーニングとランブック開発に投資します。Inferactに対して、包括的なドキュメント、ビデオチュートリアル、ハンズオンワークショップの提供を要求します。最初の1ヶ月間は毎週会議を行う共同運営委員会を設立し、運用上の課題に対処します。
-
ベンダーロックイン: Inferactの独自vLLMディストリビューションを採用すると、同社のサポートとロードマップへの依存が生じます。Inferactが方向転換または失敗した場合、顧客は移行に苦労する可能性があります。
- 軽減策:* 明確なデータポータビリティと移行サポートを交渉します。Inferactに対して、オープンソースvLLMまたは代替推論プラットフォームへの移行を可能にするエクスポートツールの提供を要求します。契約終了後少なくとも12ヶ月間サポートを維持する契約上のコミットメントを確立します。
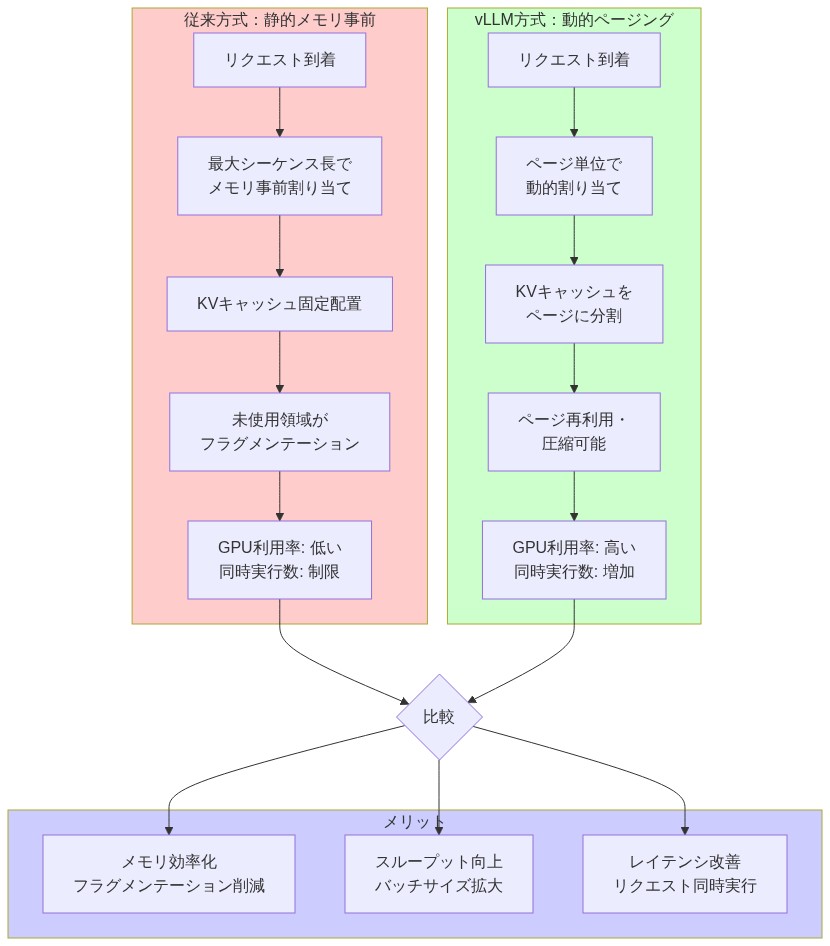
- 図4:vLLMのページド注意メカニズム(従来方式との比較)*

- 図5:vLLM導入によるGPU利用率の最適化イメージ(AI画像生成による概念イメージ)*
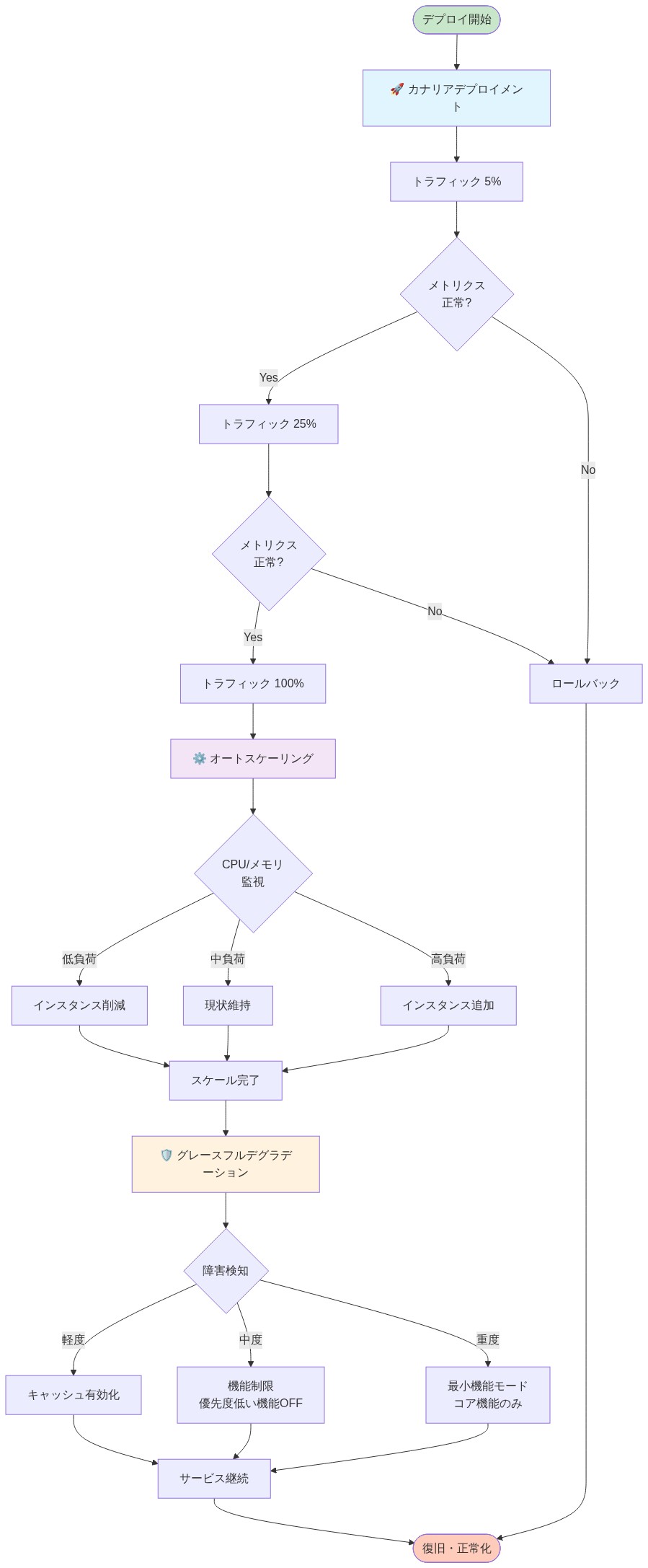
- 図7:本番環境への段階的導入パターン(カナリア・スケーリング・デグラデーション)*
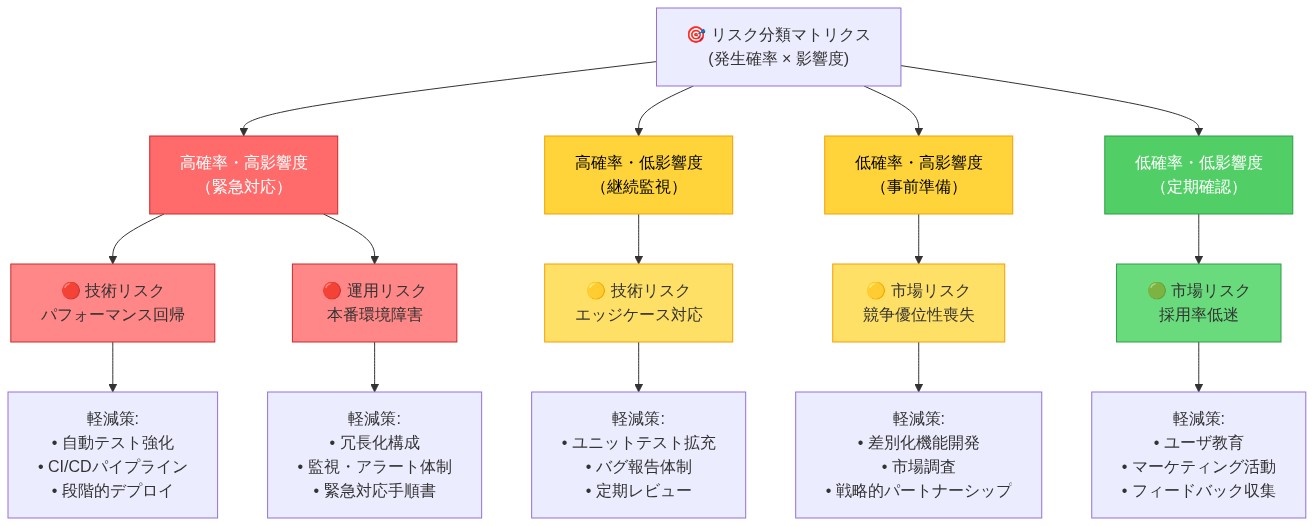
- 図10:リスク分類マトリクス(発生確率×影響度)- 技術・運用・市場リスクの可視化と軽減策*

- 図12:多層的なリスク軽減戦略の構築イメージ*
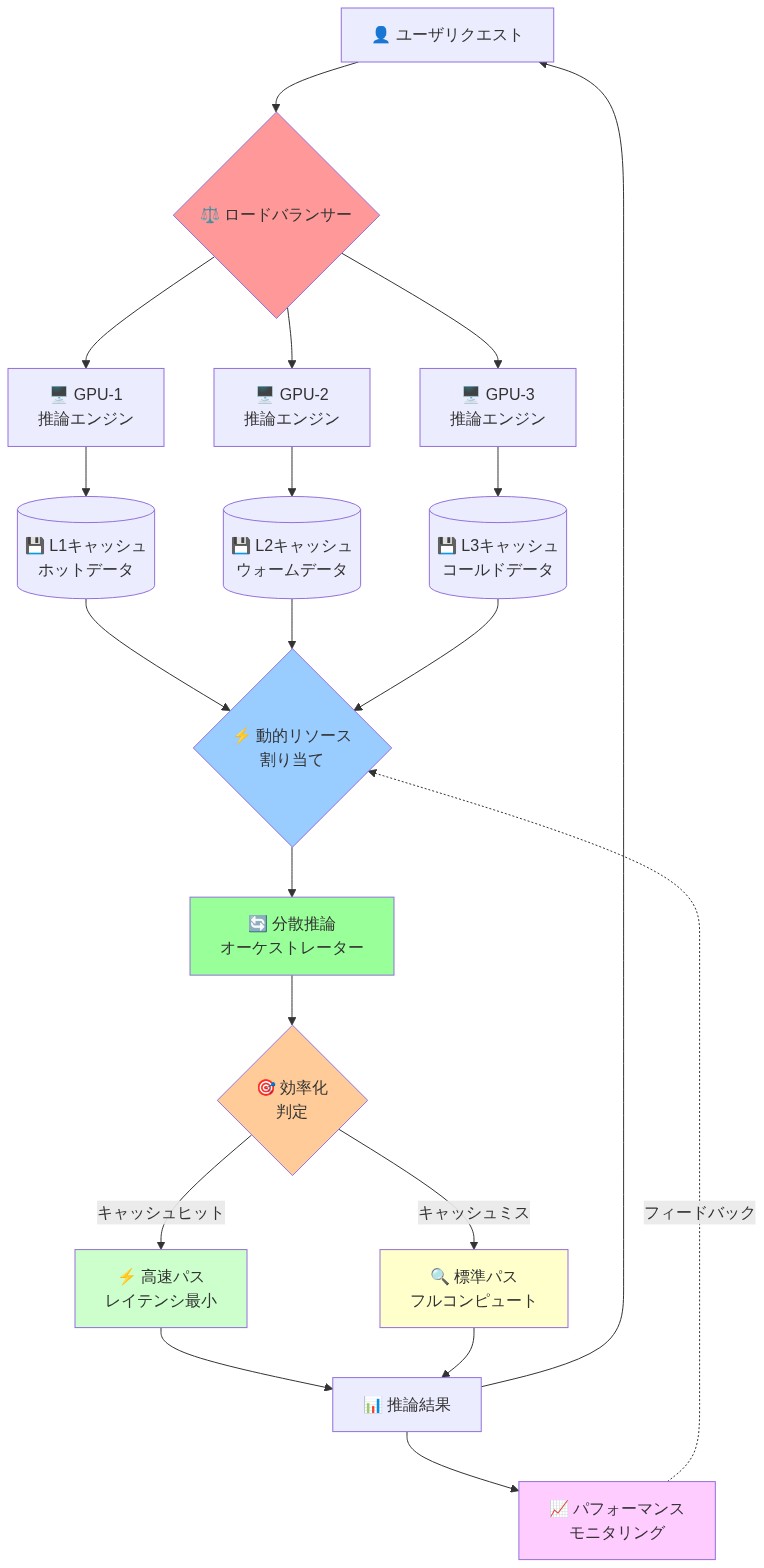
- 図14:次世代効率フロンティアを実現するシステムアーキテクチャ(マルチGPU分散推論・動的リソース割り当て・階層化キャッシング統合構成)*