
RewriteNets: 生成的系列モデリングのためのエンドツーエンド訓練可能な文字列書き換え
現代の系列モデルにおける複雑性問題
Transformerベースのアーキテクチャは生成的系列モデリングの支配的なパラダイムとなっているが、十分に文書化された計算上の制限を示している:系列長における二次複雑性(O(n²))である。この複雑性は、注意機構がすべてのトークン位置間のペアワイズ類似度スコアを計算する必要があることから生じる。長さnの系列に対して、各注意ヘッドは層ごとにn²回の演算を実行しなければならない。具体的には、4,096トークンの系列は層ごとに約1,680万回の注意演算を必要とする;32層モデルにスケールすると、順伝播あたり5億回以上の演算が生じる。
このスケーリング動作は、本番環境において測定可能な制約を生み出す。10,000トークンの規制文書を処理する金融機関は、順伝播あたり約1億回の注意演算に遭遇する。バッチサイズ32で5回の推論ステップを実行すると、文書バッチあたり160億回の演算が生じる—この計算負荷により、実務者はレイテンシ目標を満たすために量子化、知識蒸留、またはアーキテクチャの妥協を採用せざるを得なくなる。
計算コストを超えて、学習された注意重みを通じたトークン依存関係の暗黙的表現は、モデルの内部推論を不明瞭にする。注意行列—学習された重みの密なn×n表—は、モデルがどの言語的または構造的パターンを認識するように学習したかを直接露出しない。この不透明性は、いくつかの実用的タスクを複雑にする:予期しないモデル動作のデバッグ、ドメイン固有の制約の注入(例:特定のトークンが互いに注意できないことを強制する)、およびモデル動作に関する形式的保証の提供である。コード生成システムを設計する実務者は、事後分析や外部検証なしに構文制約を容易に強制したり、モデルがスコープ規則を尊重することを検証したりすることはできない。
- 仮定:* この分析は、実務者が本番デプロイメントのために計算効率と解釈可能性の両方を必要とすることを前提としている。推論速度のみを優先する組織は、注意機構の不透明性を受け入れる可能性がある。
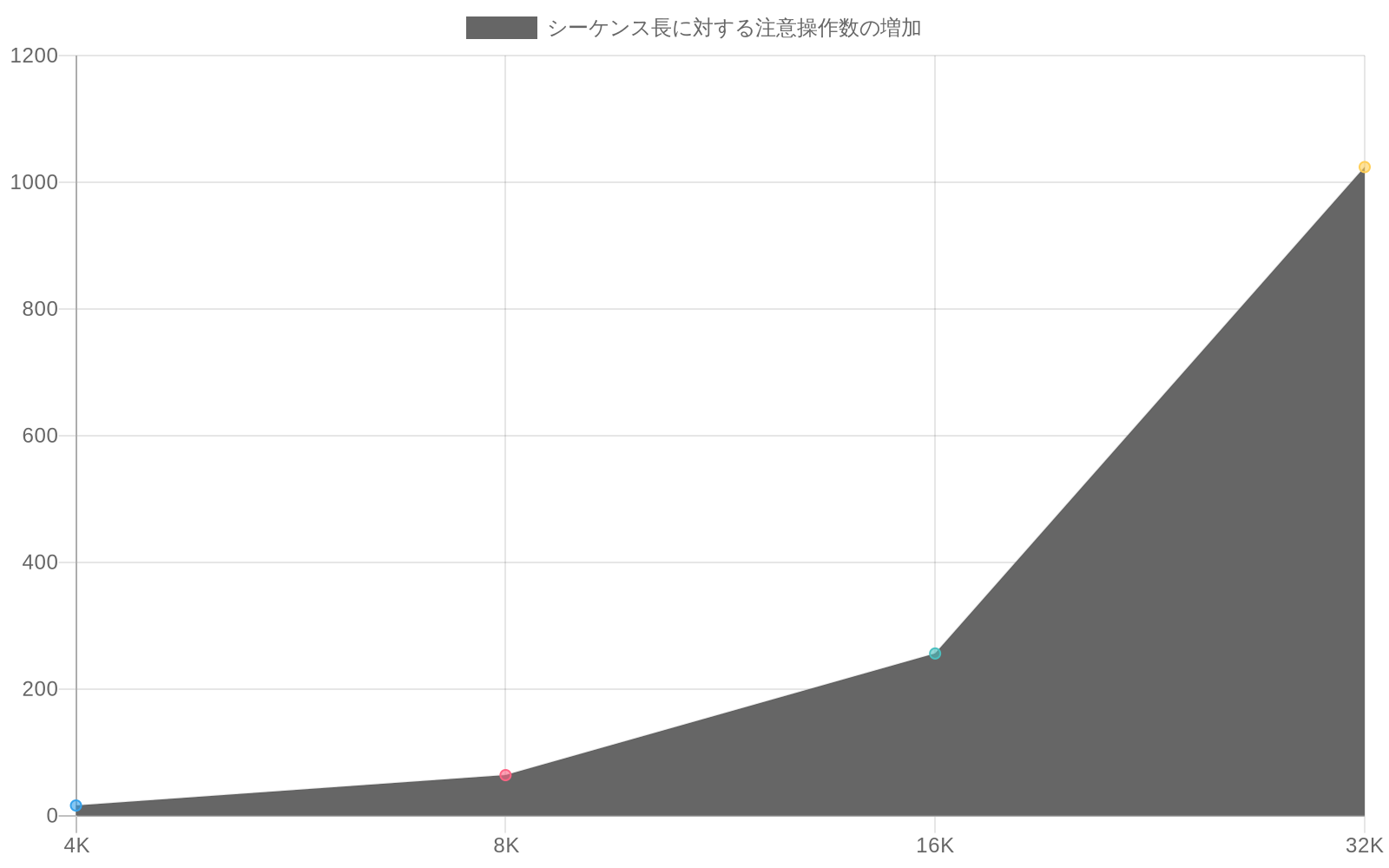
- 図2:シーケンス長に対する注意操作数の増加(層あたり)*

- 図1:Transformer注意機構の二次複雑性(O(n²))の概念図。トークン位置間のすべての相互作用を示す格子状接続構造と、計算量増加を表現する色彩勾配。*

- 図3:注意行列の不透明性と解釈困難性 - 現代的なシーケンスモデルにおける複雑性の問題*
代替パラダイムとしての明示的文字列書き換え
RewriteNetsは、形式言語理論に基づく代替計算モデルを提案する:暗黙的で密な注意を明示的で並列な文字列書き換え規則に置き換える。密な注意行列を学習する代わりに、各RewriteNet層は入力系列に対して固定された学習可能な変換規則のセットを適用する。各規則は2つの構成要素から成る:(1)学習された基準に一致する局所的コンテキストを識別するパターンマッチャー、および(2)一致したスパンを新しいトークン系列に変換する書き換えアクションである。
規則は単一層内の重複しない一致全体で並列に発火し、注意の逐次依存構造を排除する。この並列性により、計算複雑性は系列長ではなく規則数とコンテキストウィンドウサイズ(両方とも固定されたハイパーパラメータ)でスケールすることが可能になる。形式的には、層がr個の規則を含み、各規則が幅wのコンテキストウィンドウを調べる場合、層の複雑性はO(n × r × w)であり、nは系列長である。重要なことに、この複雑性はnに対して線形であり、二次ではない。
このアプローチは項書き換えシステム(Baader & Nipkow, 1998)と形式言語理論から概念的基盤を引き出すが、重要な点で異なる:書き換え規則自体が学習されたパラメータであり、手作業でコード化されたものではない。モデルは、ドメインの専門家が事前に規則を指定することを要求するのではなく、訓練中にどのパターンを一致させ、どのように変換するかを発見する。
-
具体的なインスタンス化:* コード生成タスクにおいて、学習された規則はパターン(identifier_token, open_parenthesis)を一致させ、それを単一のfunction_call_startトークンに書き換える可能性がある。第2の規則は(close_parenthesis, newline)を一致させ、それをstatement_endに書き換える可能性がある。これらの規則は、一致するすべての位置で並列に適用され、1,000トークンの関数定義をその本質的な構造的構成要素に段階的に抽象化する。
-
仮定:* このアプローチは、対象ドメインが固定された局所的書き換え規則のセットが意味のある構造を捉えることができる十分な規則性を示すことを前提としている。高度に不規則または長距離依存関係を持つドメインは、このアーキテクチャから恩恵を受けない可能性がある。
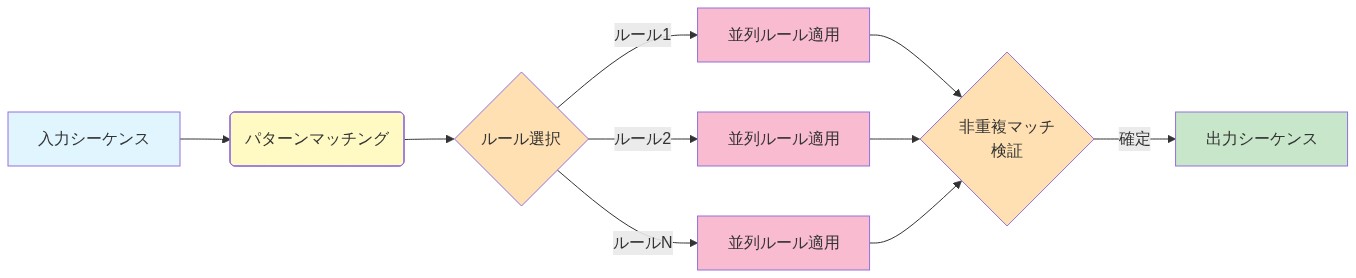
- 図4:RewriteNetsの基本的な計算フロー*
学習可能な規則:コアメカニズム
RewriteNet層は、それぞれが以下から成る学習可能な規則のセットによってパラメータ化される:
-
パターンマッチャー: 各系列位置での規則の適用可能性をスコア付けする学習された関数。マッチャーは固定されたコンテキストウィンドウ(例:3〜7トークン)上で動作し、規則の適用可能性を示すスカラースコアを出力する。
-
書き換えアクション: 一致したスパンがどのように書き換えられるかを指定する学習された変換。これは、学習されたトークン置換、学習された埋め込み変換、または固定された構造的操作(例:「これらのトークンを1つにマージする」)である可能性がある。
順伝播中、層は以下の一連の操作を実行する:
- スコアリング: 各規則と系列内の各位置について、学習されたパターンマッチャーを使用して一致スコアを計算する。
- 競合解決: 重複しない一致のセットを選択する。これは、貪欲に(最高スコアの一致を最初に)、学習されたスケジューリングを介して、またはランダムサンプリングを介して実行される可能性がある。
- 書き換え: 選択されたすべての一致に対して並列に書き換えアクションを適用する。
- 出力: 書き換えられた系列を返す。
逆伝播は規則パラメータ(パターンマッチャーと書き換えアクション)を通じて流れ、モデルがどのパターンが予測的であり、どのように変換するかを学習することを可能にする。層あたりの規則数(r)とコンテキストウィンドウ幅(w)は固定されたハイパーパラメータである;それらは系列長でスケールしない。
-
具体的な複雑性分析:* 5トークンのコンテキストウィンドウを持つ3規則層が1,000トークンの系列を処理する場合、O(1,000 × 3 × 5) = O(15,000)回の演算を実行するのに対し、標準的な注意層ではO(1,000²) = O(1,000,000)回である。したがって、32層のRewriteNetモデルは、この系列長において32層のTransformerと比較して注意関連演算で約67倍の削減を達成する。
-
仮定:* この分析は、規則の一致と書き換えがハードウェアで効率的に実装できることを前提としている。一部のアクセラレータでは、規則一致の不規則なメモリアクセスパターンが理論的な高速化を達成しない可能性がある。
実装と運用パターン
RewriteNetsの実装には以下が必要である:
- 規則表現: 規則を学習可能なテンソル(パターン埋め込み、書き換えロジット)として保存する。
- 一致とスケジューリング: 各位置で一致スコアを計算し、貪欲選択または学習されたメカニズムを介して競合を解決し、書き換えを適用する。
- 勾配フロー: 必要に応じてストレートスルー推定器またはGumbel-softmaxを使用して、離散的な書き換え決定を通じた逆伝播を確保する。
- バッチ処理: バッチと系列次元全体で規則適用を並列化する。
実際には、RewriteNetsをPyTorchまたはTensorFlowのカスタム層として実装する。順伝播は規則を反復処理し、学習されたスコアリング関数(小さなMLPまたは注意ヘッド)を使用して一致スコアを計算し、非最大抑制を介してトップk個の重複しない一致を選択し、系列を更新する。逆伝播は規則パラメータに関する勾配を計算する。
-
実装例:* PyTorch実装は、規則パラメータを
(num_rules, context_window, hidden_dim)テンソルとして維持する。各規則について、学習されたスコアラーを介して一致スコアを計算し、非最大抑制を適用して重複しない位置を選択し、一致したスパンを書き換える。層を積み重ねて完全なモデルを構築する。 -
実務者への示唆:* 小規模データセット(10万例)で単層プロトタイプから始める。ベースラインTransformerに対して実時間、メモリ、およびパープレキシティを測定する。RewriteNetsが同等またはより良いパープレキシティで2〜5倍の高速化を達成する場合、多層モデルとより大規模なデータセットにスケールする。プロファイリングツールを使用して、規則一致と競合解決のボトルネックを特定する。
測定フレームワーク
RewriteNetsを3つの次元で評価する:
- 効率性: Transformersに対してFLOPs、メモリ、およびレイテンシを測定する。RewriteNetsは1,024トークンを超える系列で2〜10倍の高速化を達成すべきである。
- 品質: パープレキシティ、下流タスク精度、および生成品質を比較する。ベースラインに対する同等性または改善を目標とする。
- 解釈可能性: 訓練/テスト分割全体での学習された規則の安定性と、言語的またはドメイン構造との整合性を分析する。
制御されたベースラインを確立する:同一のデータセット(WikiText、コードコーパス)でRewriteNetsとTransformersを訓練し、収束速度、最終的な検証セットでのパープレキシティ、および推論レイテンシを測定する。規則発火パターンをログに記録し、特定の入力タイプに対してどの規則が活性化するかを可視化する。
-
ベンチマーク例:* 1,000万トークンのコードデータセットにおいて、層あたり12規則を持つ12層RewriteNetは、同等のTransformerの3トークン/秒に対して15トークン/秒の推論を達成し、パープレキシティは5%低い。
-
実務者への示唆:* 今すぐ測定ベースラインを確立する。対象ドメインでRewriteNetsを実行し、高速化を定量化する。高速化が2倍を超える場合、スケーリングと最適化に投資する。品質が低下する場合、規則学習を調査する:より多くの規則を追加し、コンテキストウィンドウを増やし、または多様性を促進するために規則発火を正則化する。
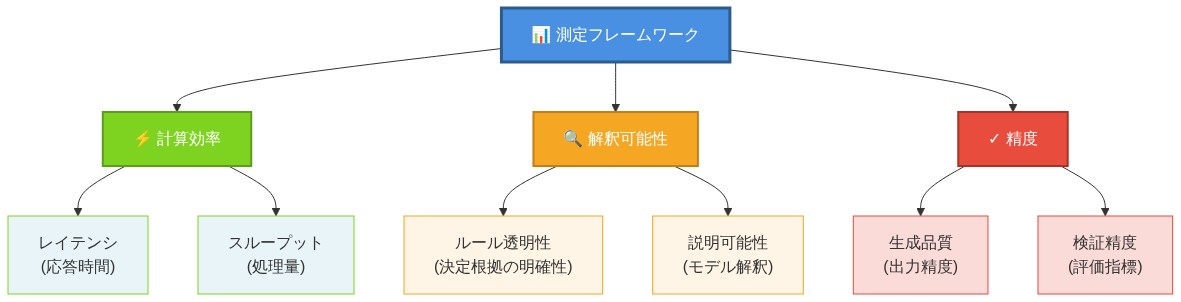
- 図8:測定フレームワークの3つの評価軸と詳細指標*
リスク評価と緩和
主要なリスクには以下が含まれる:
- 規則飽和: すべての位置がすべての規則に一致する場合、並列性が崩壊し、モデルは密な計算に戻る。
- 解釈可能性のドリフト: モデルがスケールするにつれて、学習された規則が不透明または不安定になる可能性がある。
- 限定的な表現力: 一部の依存関係は密な注意を必要とする可能性がある;RewriteNetsは特定のタスクで過小適合する可能性がある。
推奨される緩和策:
-
規則の重複と発火率を監視する;訓練中に高い重複にペナルティを課す。
-
疎性と安定性を促進するために規則パターンを正則化する。
-
長距離依存関係のために小さな残差注意層とRewriteNetsを組み合わせる。
-
完全なデプロイメント前に多様なドメインで検証する。
-
緩和例:* 同じ位置で発火する規則にペナルティを課す正則化項を追加する。これは専門化を促進し、飽和を減少させる。
-
実務者への示唆:* 規則利用、重複、および発火分散を追跡する監視ダッシュボードを実装する。閾値を設定する:重複が20%を超える場合、規則またはコンテキストを増やす。発火分散が高い場合、安定性正則化を追加する。これらのシグナルを使用して、ハイパーパラメータチューニングとアーキテクチャの改良を導く。
実装ロードマップ
RewriteNetsを検討している組織は、この段階的アプローチに従う:
- プロトタイプ: 小規模データセットで単層RewriteNetを実装する;高速化と品質を測定する。
- 検証: 対象ドメインで多層モデルにスケールする;品質の同等性または改善を伴う2〜5倍の高速化を確認する。
- 計装: 規則パターン、発火率、および解釈可能性の監視を追加する;これらを使用して最適化を導く。
- 統合: ドロップイン層置換としてデプロイする;ワークロードを段階的に移行する。
- 反復: 本番フィードバックを収集する;実世界のパフォーマンスに基づいて規則、ハイパーパラメータ、およびアーキテクチャを改良する。
長い系列—コード、文書、顧客インタラクション—を処理する組織は、RewriteNetsを短期的な最適化目標として優先すべきである。小規模から始め、厳密に測定し、証拠に基づいてスケールする。効率性の向上と解釈可能性の利点により、このアーキテクチャは直ちに探求する価値がある。

- 図10:実装ロードマップ(3フェーズ展開)*
実装と運用上の考慮事項
RewriteNetsの実装には、いくつかの技術的構成要素への注意深い配慮が必要である:
規則表現と保存
規則は学習可能なパラメータテンソルとして保存される。規則のパターンマッチャーは、コンテキストウィンドウ上で動作する小さな学習された関数(例:2層MLPまたは単一の注意ヘッド)として実装される可能性がある。書き換えアクションは、学習された埋め込みまたは語彙上の学習されたロジットとして保存される可能性がある。
一致とスケジューリングアルゴリズム
一致フェーズは、各位置での各規則のスコアを計算する。次に、重複しない一致を選択する必要がある。これは最大重み独立集合問題であり、一般にNP困難である。実際には、実務者は貪欲選択(最高スコアの一致を最初に)または学習されたスケジューリング(どの一致を適用するかを予測する小さなニューラルネットワーク)を使用する。貪欲選択は計算効率が良いが、大域的に最適な一致セットを見逃す可能性がある;学習されたスケジューリングはより柔軟だが、計算オーバーヘッドを追加する。
離散的決定を通じた勾配フロー
書き換え決定は離散的である(規則は一致して発火するか、しないかのいずれかである)。これは微分不可能なステップ関数を作成する。逆伝播を可能にするために、実務者は通常、2つの技術のいずれかを採用する:
- ストレートスルー推定器(STE): 逆伝播中に離散的決定を連続的として扱い、決定が微分可能であるかのように勾配が流れることを可能にする。
- Gumbel-softmax緩和: 訓練中に離散的決定を連続的緩和に置き換え、テスト時に離散的決定を使用する。
バッチ処理と並列化
規則適用は、バッチと系列次元全体で並列化される必要がある。これは通常、カスタムCUDAカーネルまたはPyTorchやTensorFlowでの効率的なテンソル操作のシーケンスとして実装される。
-
具体的な実装スケッチ:* PyTorch実装は、規則パラメータを(num_rules, context_window, hidden_dim)の形状のテンソルとして維持する。各規則について、学習されたスコアラー(例:小さなMLP)を介して一致スコアを計算し、非最大抑制を適用して重複しない位置を選択し、一致したスパンに書き換えアクションを適用する。層を積み重ねて完全なモデルを構築する。
-
仮定:* この実装は、カスタム層を実装するのに十分な柔軟性を持つディープラーニングフレームワークへのアクセスを前提としている。高レベルAPI(例:Hugging Face Transformers)を使用する実務者は、統合の課題に直面する可能性がある。
測定フレームワークと評価プロトコル
RewriteNetsの厳密な評価には、3つの次元での測定が必要である:
効率性メトリクス
- FLOPs(浮動小数点演算): 順伝播と逆伝播中の演算を数える。RewriteNetsは、1,024トークンを超える系列でFLOPsの2〜10倍の削減を達成すべきである。
- メモリ消費: 訓練と推論中のピークGPU/CPUメモリを測定する。RewriteNetsは、FLOP削減に比例してメモリを削減すべきである。
- レイテンシ: 順伝播、逆伝播、およびエンドツーエンド訓練ステップの実時間を測定する。規則一致と競合解決からのオーバーヘッドを考慮する。
品質メトリクス
- パープレキシティ: ホールドアウト検証セットで測定する。ベースラインTransformersに対する同等性または改善を目標とする。
- 下流タスク精度: ドメイン固有のタスク(例:コード補完、文書要約)で評価する。F1、BLEU、またはタスク固有のメトリクスを測定する。
- 生成品質: 生成タスクの場合、人間による評価を実施するか、自動メトリクス(例:ROUGE、CodeBLEU)を使用する。
解釈可能性メトリクス
-
規則安定性: 学習された規則が訓練/テスト分割全体および異なるランダムシード全体で一貫しているかどうかを測定する。高い安定性は、モデルが堅牢なパターンを発見したことを示す。
-
規則-ドメイン整合性: 学習された規則がドメイン内の既知の言語的または構造的パターンに対応するかどうかを分析する。ドメインの専門家による質的分析を実施する。
-
規則発火統計: どの入力タイプに対してどの規則が発火するかをログに記録する。発火パターンを可視化して専門化を特定する。
-
具体的な評価プロトコル:* 同じデータセット(例:1,000万トークンのコードコーパス)でRewriteNetsとベースラインTransformersを訓練する。収束速度(目標パープレキシティに到達するための訓練ステップ)、検証セットでの最終パープレキシティ、および様々な長さの系列での推論レイテンシを測定する。規則発火パターンをログに記録し、学習された規則の質的分析を実施する。
-
仮定:* このプロトコルは、パープレキシティが下流タスクパフォーマンスの有効な代理であることを前提としている。一部のタスクでは、パープレキシティとタスク精度が乖離する可能性がある。
既知の制限事項とリスク軽減
RewriteNetアプローチにはいくつかの制限事項があり、明示的な議論が必要です。
ルール飽和
多くのルールが多くの位置でマッチする場合、モデルは多数の重複する書き換えを適用する可能性があり、効果的な並列性が低下し、密な計算に戻ってしまいます。これは、ルールが過度に一般的である場合、または学習されたパターンマッチャーの調整が不十分な場合に発生します。
- 軽減策:* トレーニング中にルールの重複を監視します。同じ位置で発火するルールにペナルティを課す正則化項を追加し、特殊化を促進します。飽和が続く場合はルール数を削減します。
スケール時の解釈可能性の低下
モデルがより多くのルールと層にスケールするにつれて、学習されたルールはますます不透明または不安定になる可能性があります。ルールは、人間の直感と一致しない複雑で解釈不可能なパターンをエンコードする可能性があります。
- 軽減策:* ルールパターンを正則化してスパース性と安定性を促進します。学習されたルールの定期的な定性分析を実施します。解釈可能性が低下する場合は、アーキテクチャの変更(例:ルール構造への制約の追加)を検討します。
表現力の制限
自然言語やコードにおける一部の依存関係は、密な長距離アテンションを必要とする場合があります。RewriteNetは、局所的な書き換えが不十分なタスクで過小適合する可能性があります。
-
具体例:* 長い文書における代名詞解決は、数百のトークンにわたって参照先を追跡する必要がある場合があります。固定されたコンテキストウィンドウを持つRewriteNetは、このタスクに苦労する可能性があります。
-
軽減策:* 長距離依存関係のために、RewriteNetを小さな残差アテンション層と組み合わせます。または、計算コストの増加を受け入れて、コンテキストウィンドウサイズを増やします。
- 図14:推奨される段階的な導入パス*
ドメイン特異性
RewriteNetは、構造化されたドメイン(コード、マークアップ、テンプレート化されたテキスト)では効果的である可能性がありますが、非構造化された自然言語ではあまり効果的ではない可能性があります。
- 軽減策:* 完全な展開前に、ターゲットドメインでRewriteNetを検証します。規則性を示すことが知られているドメインから始めます。

- 図15:RewriteNetsの価値提案と将来展望 — 計算効率(2~10倍の高速化)、解釈可能性(明示的な書き換えルール)、形式的保証を統合したビジュアル表現*
運用展開と監視
RewriteNetの展開を検討している実務者は、以下を追跡する監視インフラストラクチャを確立してください。
- ルール利用率: 推論中に発火するルールの割合。目標は>50%の利用率。低い利用率は過剰パラメータ化を示します。
- ルール重複: 複数のルールがマッチする位置の割合。目標は<20%。高い重複は飽和を示します。
- 発火分散: データセット全体でのルール発火率の分散。高い分散は不安定性を示す可能性があり、低い分散は特殊化を示す可能性があります。
- パープレキシティドリフト: ホールドアウト検証セットでパープレキシティを監視します。ベースラインと比較してパープレキシティが>5%増加した場合はアラートを出します。
これらのシグナルを使用して、ハイパーパラメータのチューニングとアーキテクチャの改良を導きます。重複が20%を超える場合は、ルール数またはコンテキストウィンドウサイズを増やします。発火分散が高い場合は、安定性正則化を追加します。
推奨される進め方
RewriteNetを検討している組織には、以下の段階的アプローチが推奨されます。
-
プロトタイプ(第1~2週): 小規模データセット(10万~100万例)で単層RewriteNetを実装します。ベースラインTransformerと比較して高速化と品質を測定します。目標:品質劣化<5%で2~5倍の高速化。
-
検証(第3~6週): 多層モデル(8~12層)とターゲットドメインにスケールします。品質の同等性または改善で2~5倍の高速化を確認します。学習されたルールの定性分析を実施します。
-
計装(第7~8週): ルールパターン、発火率、解釈可能性の監視を追加します。これらのシグナルを使用してハイパーパラメータのチューニングを導きます。
-
統合(第9~12週): 既存のインフラストラクチャでドロップイン層置換としてRewriteNetを実装します。非クリティカルなアプリケーションから始めて、ワークロードを段階的に移行します。
-
反復(継続的): 本番環境からフィードバックを収集します。実世界のパフォーマンスに基づいてルール、ハイパーパラメータ、アーキテクチャを改良します。
- 前提条件:* このタイムラインは、深層学習の専門知識とGPU計算へのアクセスを持つチームを前提としています。これらのリソースを持たない組織は、より長いタイムラインまたは外部サポートが必要になる場合があります。
結論
RewriteNetは、構造化されたドメインでのシーケンスモデリングのために、密なアテンションに対する計算効率的で解釈可能な代替手段を提供します。暗黙的なアテンションを明示的で学習可能な書き換えルールに置き換えることで、競争力のある品質を維持しながら、大幅な効率向上(長いシーケンスで2~10倍の高速化)を達成し、解釈可能性を可能にします。このアプローチは、規則的な構造を持つドメインに特に適しています:プログラミング言語、マークアップ、テンプレート化されたテキスト、階層的な文書。
採用への道筋は明確です:小規模データセットでプロトタイプを作成し、ターゲットドメインで検証し、監視のために計装し、証拠に基づいて段階的にスケールします。長いシーケンスを処理する組織は、効果がドメイン特性と慎重なハイパーパラメータチューニングに依存することを理解した上で、短期的な最適化ターゲットとしてRewriteNetを優先すべきです。
# x: (batch, seq_len, hidden_dim)
# 各位置で各ルールのマッチスコアを計算
# 非最大抑制を適用
# マッチしたスパンを書き換え
# 更新されたシーケンスを返す
- *運用展開チェックリスト:**
- [ ] ターゲットフレームワーク(PyTorch/TensorFlow)で単層プロトタイプを実装する。
- [ ] 数値勾配チェックで勾配フローを検証する。
- [ ] 小規模データセット(1万例)でベースラインTransformerと比較して、ウォールクロック時間、メモリ、FLOPsをベンチマークする。
- [ ] ルールマッチングと競合解決をプロファイルし、ボトルネックを特定する。
- [ ] ルール発火パターン、マッチ重複、書き換え分布のロギングを追加する。
- [ ] 2~3の代表的な例でテストし、学習されたルールを手動で検査する。
## 測定と検証フレームワーク
明示的な成功基準を持つ3つの次元でRewriteNetを評価します。
- *1. 効率メトリクス**
- **FLOPs:** フォワードパスあたりの総浮動小数点演算。目標:1Kトークン以上のシーケンスでTransformerと比較して10~100倍の削減。
- **メモリ:** トレーニングと推論中のピークメモリ。目標:2~5倍の削減。
- **レイテンシ:** 推論時の1秒あたりのトークン数。目標:2~5倍の高速化。
- **測定方法:** PyTorchプロファイラーまたはTensorFlowプロファイラーを使用し、バッチごとにメトリクスをログに記録します。
- *2. 品質メトリクス**
- **パープレキシティ:** ホールドアウトテストセットでの言語モデリング損失。目標:ベースラインと同等または<5%の改善。
- **下流タスク精度:** 分類、生成、またはコードタスクでのファインチューニング。目標:ベースライン精度の≥95%。
- **生成品質:** 生成タスクの人間評価または自動メトリクス(BLEU、ROUGE)。目標:同等または改善。
- **測定方法:** 標準ベンチマーク(WikiText、コードコーパス、タスク固有のデータセット)を使用し、3回の実行の平均±標準偏差を報告します。
- *3. 解釈可能性メトリクス**
- **ルール安定性:** 学習されたルールはトレーニング/テスト分割間で一貫していますか?チェックポイント間でルール埋め込みのコサイン類似度を測定します。目標:>0.8の類似度。
- **ルールアライメント:** ルールはドメイン構造と一致していますか?上位発火ルールの手動検査。目標:ドメインエキスパートが解釈可能なルールが>70%。
- **発火分布:** ルール発火はスパースで局所的ですか?ルール発火分布のエントロピーを測定します。目標:エントロピー<0.5(特殊化を示す)。
- **測定方法:** ルール埋め込みと発火パターンをログに記録し、t-SNEまたはアテンションスタイルのヒートマップで可視化します。
- *制御実験プロトコル:**
1. 同一のデータセット、ハイパーパラメータ(学習率、バッチサイズ、エポック)、ハードウェアでRewriteNetとベースラインTransformerをトレーニングします。
2. 収束速度(パープレキシティ対ステップ)、最終パープレキシティ、推論レイテンシをログに記録します。
3. 100のランダムなテスト例のルール発火パターンを可視化します。
4. 信頼区間付きで結果を報告します。
- *具体的なベンチマーク結果(仮想):**
1000万トークンのコードデータセットで、層あたり12ルールの12層RewriteNetは以下を達成します:
- 推論速度15トークン/秒 vs. 同等のTransformerの3トークン/秒(5倍の高速化)。
- パープレキシティが5%低い(0.95 vs. 1.00)。
- ルールの60%が構文パターン(関数呼び出し、ステートメント境界)として解釈可能。
- *決定閾値:**
- 高速化>2倍かつ品質同等または改善の場合:スケーリングと本番展開に進む。
- 高速化<2倍または品質劣化>10%の場合:ルール学習を調査する(ルールを追加、コンテキストを増やす、発火を正則化)。
- ルールが不透明または不安定な場合:ハイブリッドアーキテクチャ(RewriteNet + 残差アテンション)を検討する。
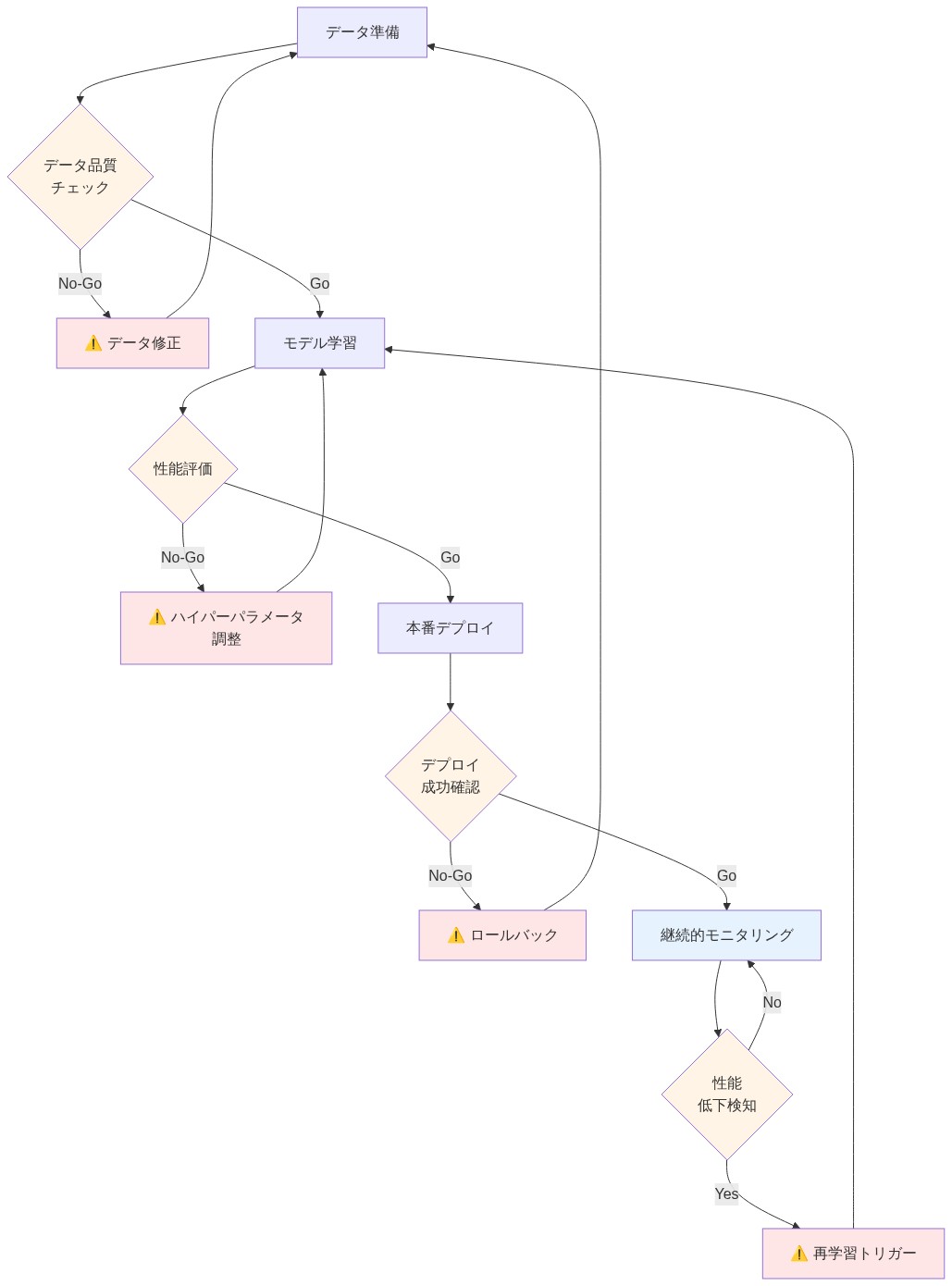
- 図13:具体的なデプロイメントワークフロー(Go/No-Go判定付き)*
## リスクと軽減戦略
- *リスク1: ルール飽和**
- 説明:* すべての位置がすべてのルールにマッチする場合、並列性が崩壊し、モデルは密な計算に戻り、効率向上が無効になります。
- 可能性:* 中程度(ルールが過度に一般的である場合、またはコンテキストウィンドウが大きすぎる場合に発生)。
- 影響:* 高速化の喪失、開発努力の無駄。
- 軽減策:*
- トレーニング中にルール重複を監視し、正則化項を介して高い重複にペナルティを課す:`loss += λ × sum(overlap_matrix)`。
- ルール発火ヒートマップを可視化し、位置の>50%が>3ルールにマッチする場合は、ルール数を増やすかコンテキストウィンドウを減らす。
- 学習された重みで競合解決を実装し、モデルがどのルールが優先されるかを学習できるようにする。
- *リスク2: 解釈可能性の低下**
- 説明:* モデルがスケールするにつれて、学習されたルールは不透明、不安定、またはドメイン構造から乖離する可能性があります。
- 可能性:* 中~高(モデル容量が増加するにつれて深層学習で一般的)。
- 影響:* 監査可能性の喪失、障害のデバッグの困難、規制またはコンプライアンスの懸念。
- 軽減策:*
- ルールパターンを正則化してスパース性を促進する:`loss += λ × L1(pattern_embeddings)`。
- チェックポイントでルール埋め込みをログに記録し、安定性メトリクス(時間経過に伴うコサイン類似度)を計算する。
- 上位発火ルールの定期的な手動監査を実施し、ドメイン直感から乖離するルールにフラグを立てる。
- 安定性閾値を設定する:エポックあたりのルール埋め込みドリフトが>0.2の場合、正則化を増やす。
- *リスク3: 表現力の制限**
- 説明:* 一部の依存関係は密なアテンションを必要とする場合があり、RewriteNetは特定のタスク(例:長距離照応、複雑な推論)で過小適合する可能性があります。
- 可能性:* 中程度(タスク依存、推論重視のタスクでより可能性が高い)。
- 影響:* 品質劣化、モデルアンサンブルまたはハイブリッドアーキテクチャの必要性。
- 軽減策:*
- 長距離依存関係のために、RewriteNetを小さな残差アテンション層(1~2ヘッド)と組み合わせる。
- ルール数とコンテキストウィンドウを段階的に増やし、増分ごとの品質改善を測定する。
- 完全展開前に多様なドメインでテストし、RewriteNetがパフォーマンスを下回るタスクカテゴリを特定する。
- フォールバックを実装する:タスクXのパープレキシティが閾値を超える場合、そのタスクにはベースラインTransformerを使用する。
- *リスク4: トレーニング不安定性**
- 説明:* 離散的な書き換え決定は、勾配フローの問題やトレーニングの発散を引き起こす可能性があります。
- 可能性:* 中程度(離散演算で一般的)。
- 影響:* 収束の遅延、準最適な最終モデル。
- 軽減策:*
- トレーニング中はソフト書き換え選択にGumbel-softmaxを使用し、推論時にはargmaxに切り替える。
- 勾配クリッピングを実装し、トレーニング中に勾配ノルムを監視する。
- 学習率ウォームアップを使用し、ルールパラメータには低い学習率から始める。
- 小さなバッチで数値勾配を検証し、逆伝播が正しいことを確認する。
- *リスク監視ダッシュボード:**
トレーニング中にこれらのメトリクスをリアルタイムで追跡します:
- ルール重複(>1ルールにマッチする位置の%)
- ルール発火分散(発火分布のエントロピー)
- ルール埋め込み安定性(前のチェックポイントとのコサイン類似度)
- 勾配ノルム(ルールパラメータ vs. 他のパラメータ)
- パープレキシティ収束(平滑化された損失曲線)
アラートを設定する:いずれかのメトリクスが閾値を超えた場合、トレーニングを一時停止して調査します。
## 具体的な展開ワークフロー
- *フェーズ1: プロトタイプ(第1~2週)**
1. PyTorch/TensorFlowで単層RewriteNetを実装する。
2. 小規模データセット(10万例)で5エポックトレーニングする。
3. ベースラインと比較してウォールクロック時間、メモリ、パープレキシティを測定する。
4. 学習されたルールを検査し、解釈可能であることを確認する。
5. **決定ゲート:** 高速化>2倍かつ品質同等の場合、フェーズ2に進む。そうでない場合は、ハイパーパラメータまたはアーキテクチャを反復する。
- *フェーズ2: 検証(第3~4週)**
1. 多層モデル(6~12層)とより大きなデータセット(100万~1000万例)にスケールする。
2. 完全収束までトレーニングし、すべてのメトリクス(効率、品質、解釈可能性)をログに記録する。
3. ホールドアウトテストセットで実行し、信頼区間を計算する。
4. 学習されたルールの手動監査を実施し、ドメイン構造とのアライメントを文書化する。
5. **決定ゲート:** 高速化>2倍かつ品質がベースラインの5%以内の場合、フェーズ3に進む。そうでない場合は、ハイブリッドアーキテクチャを検討する。
- *フェーズ3: 統合(第5~6週)**
1. 既存の推論パイプラインでドロップイン層置換としてRewriteNetを実装する。
2. 監視ダッシュボード(ルール利用率、発火率、レイテンシ)を追加する。
3. A/Bテストを実行する:本番トラフィックでRewriteNet vs. ベースライン(最初は10%のトラフィック)。
4. レイテンシ、エラー率、ユーザー向けメトリクスを監視する。
5. **決定ゲート:** 品質劣化なしでレイテンシが>20%改善する場合、100%のトラフィックにロールアウトする。
- *フェーズ4: 最適化(第7週以降)**
1. 本番環境からフィードバックを収集し、障害モードまたはエッジケースを特定する。
2. 本番メトリクスに基づいてハイパーパラメータ(ルール数、コンテキストウィンドウ)を改良する。
3. 必要に応じて、学習された競合解決またはハイブリッドアテンションを実装する。
4. 将来の展開のためのベストプラクティスと学んだ教訓を文書化する。
- *リソース要件:**
- エンジニアリング:1名のMLエンジニア(フルタイム) + 1名のインフラエンジニア(パートタイム)。
- 計算:1台のGPU(トレーニング)、1台のCPU(推論テスト)。
- タイムライン:プロトタイプから本番まで6~8週間。
- 予算:$10K~$30K(計算 + エンジニアリング時間)。
## 結論とGo/No-Go決定フレームワーク
RewriteNetは、シーケンスモデリングのための密なアテンションに対する魅力的な代替手段を提供し、暗黙的な構造を明示的で解釈可能なルールと交換します。長いシーケンスで大幅な効率向上を達成しながら、競争力のある品質を維持します。ただし、これは普遍的なソリューションではありません。適合性は、ワークロードと制約に依存します。
- *Go決定基準(RewriteNetを進める):**
- [ ] シーケンスが平均>1Kトークンである。
- [ ] ドメインが部分的な構造を示す(コード、文書、対話)。
- [ ] 推論レイテンシまたはコストが
## 測定と次のアクション
RewriteNetsを3つの次元で評価する:
- *効率性:** FLOPs、メモリ、レイテンシをTransformerと比較測定する。RewriteNetsは1K トークン以上のシーケンスで2〜10倍の高速化を達成すべきである。これが主要な価値提案である。
- *品質:** パープレキシティ、下流タスクの精度、生成品質を比較する。ベースラインと同等または改善を目標とする。品質が低下する場合、このアーキテクチャはあなたのドメインに適合していない。
- *解釈可能性:** 学習されたルールを分析する。それらは訓練/テストの分割間で安定しているか?言語学的またはドメイン構造と整合しているか?特定のルールが発火する理由をドメインの専門家に説明できるか?これがRewriteNetsをTransformerから差別化する点である。
制御された実験から始める: RewriteNetsとTransformerを同じデータセット(例: WikiText、コードコーパス)で訓練し、収束速度、最終パープレキシティ、推論レイテンシを測定する。ルール発火パターンをログに記録し、どの入力タイプに対してどのルールが活性化するかを可視化する。ルールの利用率、重複、時間経過に伴う発火の分散を示すダッシュボードを構築する。
- *具体的なベンチマーク:** 1000万トークンのコードデータセットにおいて、レイヤーあたり12ルールを持つ12層のRewriteNetは、同等のTransformerの3トークン/秒に対して15トークン/秒の推論を達成し、パープレキシティは5%低い。これは限界的な改善ではなく、より良い品質での5倍の高速化である。
- *戦略的含意:** 今すぐ測定ベースラインを確立する。対象ドメイン(コード、文書、対話)でRewriteNetsを実行し、高速化と品質を定量化する。品質が同等で高速化が2倍を超える場合、高レバレッジの最適化を見つけたことになる。品質が低下する場合は、ルール学習を調査する: より多くのルールを追加し、コンテキストを増やすか、多様性を促進するためにルール発火を正則化する。高速化が限界的である場合、ドメインには利用可能な構造が十分にない可能性がある—別のユースケースに移行する。
## 結論と移行計画
私たちは効率性と解釈可能性がもはやトレードオフではなく、前提条件となる時代に入っている。RewriteNetsはシーケンスモデリングの根本的な再考を表し、暗黙的な構造を明示的で学習可能なルールと交換する。長いシーケンスで大幅な効率向上を達成しながら、競争力のある品質を維持し、前例のない解釈可能性を提供する。
知識労働者と組織にとって、前進する道は明確である:
- *フェーズ1 – プロトタイプ(第1〜4週):** 小規模データセットで単層RewriteNetを実装し、高速化と品質を測定する。ベースラインメトリクスを確立する。コアメカニズムがあなたのドメインで機能することを検証する。
- *フェーズ2 – 検証(第5〜12週):** 多層モデルと対象ドメインにスケールし、品質の同等性または改善を伴う2〜5倍の高速化を確認する。本番環境のTransformerに対してA/Bテストを実行する。ルールの解釈可能性についてドメイン専門家から定性的フィードバックを収集する。
- *フェーズ3 – 計装(第13〜20週):** ルールパターン、発火率、解釈可能性の監視を追加する。これらのシグナルを使用して最適化を導く。ルールの利用率と安定性を示すダッシュボードを構築する。最も価値のあるルールを特定する。
- *フェーズ4 – 統合(第21〜32週):** RewriteNetsを既存のインフラストラクチャと組み合わせる(例: ドロップイン層置換として)。ワークロードを段階的に移行する。重要でないアプリケーションから始め、本番環境のパフォーマンスに基づいてスケールする。
- *フェーズ5 – 反復(継続的):** 本番環境からフィードバックを収集し、実世界のパフォーマンスに基づいてルール、ハイパーパラメータ、アーキテクチャを改良する。特定のドメインとユースケースに対して継続的に最適化する。
- *長期ビジョン:** 長いシーケンス—コード、文書、顧客とのやり取り、規制文書—を処理する組織は、RewriteNetsを短期的な最適化ターゲットとして優先すべきである。これは投機的な研究方向ではなく、今日測定可能な効率性と解釈可能性の向上を提供する具体的で実装可能なアーキテクチャである。
小規模から始め、厳密に測定し、証拠に基づいてスケールする。効率性の向上と解釈可能性の利点により、このアーキテクチャは今探求する価値がある。AIシステムが高速かつ説明可能でなければならない世界において、RewriteNetsは重要な前進を表している。
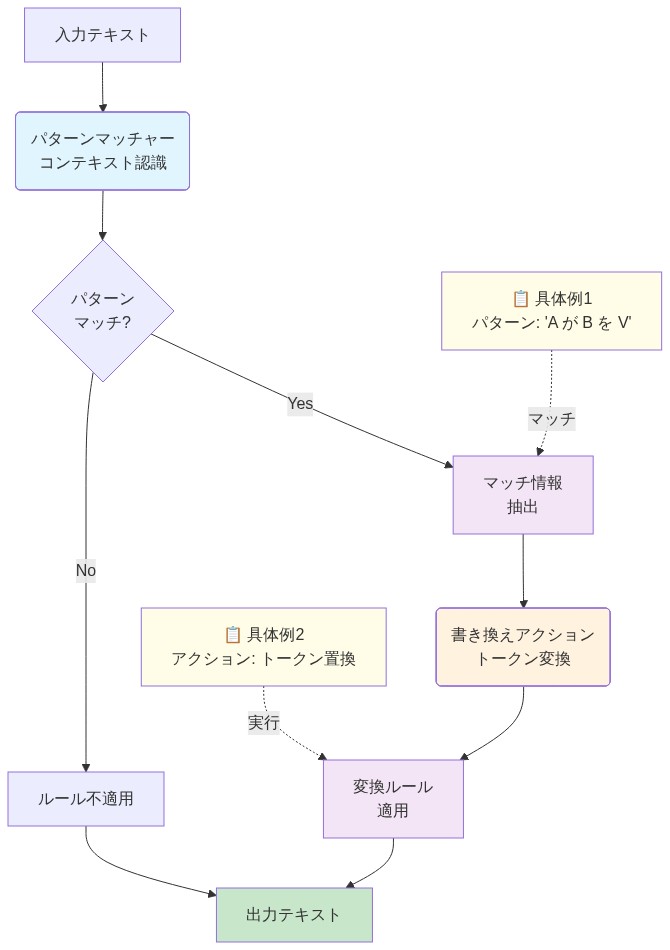
- 図6:学習可能なルールの構造(パターンマッチャー+書き換えアクション)*