
臨床データにおける隠れたギャップ
健康の社会的決定要因(SDoH)は、住居の安定性、食料の安全保障、雇用状況、交通手段へのアクセス、社会的孤立として運用され、患者の罹患率および死亡率の確立された相関要因である(Healthy People 2030フレームワーク;米国保健福祉省)。その文書化された臨床的重要性にもかかわらず、SDoH変数は構造化された電子健康記録(EHR)システムにおいて体系的に過小評価されたままである。ICD-9分類を含む現在の診断コーディング基準は、疾患実体と処置を捉えるように設計されている。これらは、疾患を引き起こすまたは悪化させる上流の社会的および環境的条件をコード化する能力が限られている。
-
構造的制限:* ICD-9コーディングスキーマは、社会的文脈の文書化よりも疾病分類学的分類—疾患状態の命名と分類—を優先する。本態性高血圧症を呈する患者はコード401.xを受け取り、2型糖尿病の患者はコード250.xを受け取る。これらのコードは請求および疫学的サーベイランス要件を満たすが、非遵守、受診の遅れ、または治療失敗を引き起こす可能性のある社会的条件をコード化しない。臨床記録には、これらの条件への明示的な言及が含まれることが多い(「患者は住居の不安定性を報告」、「薬を購入する余裕がない」)が、この情報を抽出し、臨床意思決定支援またはリスク層別化アルゴリズムで使用するために構造化する標準化されたメカニズムは存在しない。
-
具体的な実例:* 急性喘息増悪(ICD-9: 493.9x)で救急外来を繰り返し受診する55歳の患者を考える。構造化されたEHRデータは、呼吸器診断と受診頻度のみを反映する。対応する臨床記録には次のように記載されている:「患者は目に見えるカビと水害のあるアパートに住んでいると報告;家主は修理要請に応答しない;患者は経済的制約のため転居できない。」この住宅品質変数—呼吸器疾患の文書化された環境トリガー—は、いかなる構造化フィールドにも捕捉されていない。その結果、構造化データのみで訓練された臨床リスクモデルは、この因果要因を組み込むことができず、介入は環境要因への対処ではなく薬物管理に限定されたままである。
-
定量化可能なギャップ:* プライマリケアおよび救急医療環境における臨床文書の予備監査により、患者受診の15〜25%に少なくとも1つの社会的リスク要因(住居、雇用、食料アクセス、または交通手段)の明示的な言及が含まれているが、これらの言及の3%未満が構造化EHRフィールドに捕捉されるか、下流分析のためにコード化されていることが明らかになった(仮定:典型的なEHRアーキテクチャに基づく;具体的な有病率は医療システムおよび文書化文化によって異なる)。このギャップは、臨床的に関連する情報の損失と、標的介入の機会損失の両方を表している。
-
介入の前提条件:* このギャップの大きさを定量化するには、ベースライン監査が必要である:(1)代表的な部門にわたる500〜1,000の臨床記録のランダムサンプル;(2)すべての明示的および暗黙的なSDoH言及を特定するための手動レビュー;(3)捕捉率を測定するための構造化EHRフィールドおよびICD-9コーディングとの比較;(4)SDoH文書化が臨床的複雑性と相関するかどうかを評価するための患者リスクレベル(高リスク対定期)による層別化。この監査は、文書化されていないSDoH信号の有病率と抽出インフラストラクチャの潜在的な臨床的価値の両方を確立する。
臨床記録からの自動抽出
自然言語処理(NLP)技術は、非構造化臨床テキストに埋め込まれたSDoH信号の体系的な識別と分類を可能にする。手動チャートレビュー—労働集約的で、断続的で、レビュアーの変動性の影響を受ける—とは異なり、自動抽出は記録コーパス全体を大規模に処理し、患者集団全体のパターンを識別し、下流分析および臨床意思決定支援のための構造化データフィードを生成できる。
-
技術的根拠:* 臨床文書化システムは、患者の文脈、臨床的推論、および社会的状況を捉えるための主要な媒体として記述テキストを生成する。この非構造化データには豊富な意味情報が含まれているが、直接機械可読またはクエリ可能ではない。NLPパイプラインは、シーケンスモデル、固有表現認識、および分類アルゴリズムを適用して記述テキストを解析し、ドメイン固有のエンティティ(例:住居状況、雇用障壁)を識別し、標準化されたラベルを割り当てる。出力は、患者識別子および受診タイムスタンプにリンクされたSDoH言及の構造化データセットである。
-
抽出メカニズム:* 典型的なパイプラインは以下で構成される:(1)テキスト前処理(トークン化、匿名化);(2)SDoH関連フレーズを識別するためのエンティティ認識(例:「不安定な住居」、「フードバンク紹介」、「交通障壁」);(3)エンティティを患者の文脈にリンクするための関係抽出(例:「患者が報告」対「家族が報告」);(4)標準化されたSDoHカテゴリ(住居、食料安全保障、雇用、交通手段、社会的支援)を割り当てるための分類;(5)手動レビューのために低信頼度抽出にフラグを立てるための信頼度スコアリング。出力は、患者受診をSDoHカテゴリおよび支持テキストスニペットにマッピングする構造化テーブルである。
-
具体的なパフォーマンス例:* ある医療システムは、プライマリケア、救急医療、および入院部門にわたって月間約50,000の臨床記録を処理する。訓練された抽出者による手動チャートレビューは、記録の8.2%(n = 4,100)でSDoH言及を識別する。同じ医療システムからの1,200の手動注釈付き記録で訓練され、完全なコーパスに適用されたNLP抽出モデルは、記録の21.8%(n = 10,900)でSDoH信号を識別する。手動レビューとの詳細な比較(n = 500のランダムに選択された記録)により、次の結果が得られる:精度 = 0.87(抽出された言及の87%が有効なSDoH信号として確認される)、再現率 = 0.79(モデルは手動レビューに存在するSDoH言及の79%を識別する)。検出されなかった言及(21%の偽陰性)は、明示的な記述ではなく、主に暗黙的な言及(「一人暮らし」、「仕事の合間」)である。抽出は、記録の12.1%で住居の不安定性、5.8%で食料不安、4.2%で雇用の中断、3.1%で交通障壁を識別する。
-
仮定と制限:* 上記のパフォーマンス指標は以下を仮定する:(1)訓練データセットが対象臨床環境(記録スタイル、患者集団、文書化パターン)を代表している;(2)手動注釈基準が一貫して適用されている(評価者間信頼性 ≥ 0.80);(3)抽出モデルが訓練データと同じ分布からのホールドアウトテストセットで評価されている。パフォーマンスは、異なる文書化慣行、患者人口統計、または記録構造を持つ臨床環境に適用された場合に低下する可能性がある。多様な臨床環境全体でパフォーマンスを維持するには、ドメイン適応技術(例:転移学習、能動学習)が必要である。
-
実装の前提条件:* 抽出インフラストラクチャを展開する前に、以下を確立する:(1)組織の介入能力と整合したSDoHカテゴリの分類法(例:住居紹介、フードバンクパートナーシップ、交通バウチャー);(2)明示的な包含/除外基準と評価者間信頼性目標(κ ≥ 0.75)を持つ手動注釈プロトコル;(3)臨床環境からの500〜1,500の注釈付き記録の代表的な訓練データセット;(4)パフォーマンス検証のためのホールドアウトテストセット(n = 200〜300);(5)臨床ワークフローへの統合前に抽出された信号をレビューおよび検証するための臨床ガバナンスプロセス。EHRへの統合には以下を含める必要がある:(1)SDoH信号の存在を示す新しい構造化データフィールドまたはフラグ;(2)臨床医の検証のための支持テキストスニペットへのリンク;(3)監査およびトレーサビリティのためのタイムスタンプおよびソース記録識別子;(4)臨床医が抽出された信号を確認、反駁、または改良するためのメカニズム(モデル改善のためのフィードバックループ)。
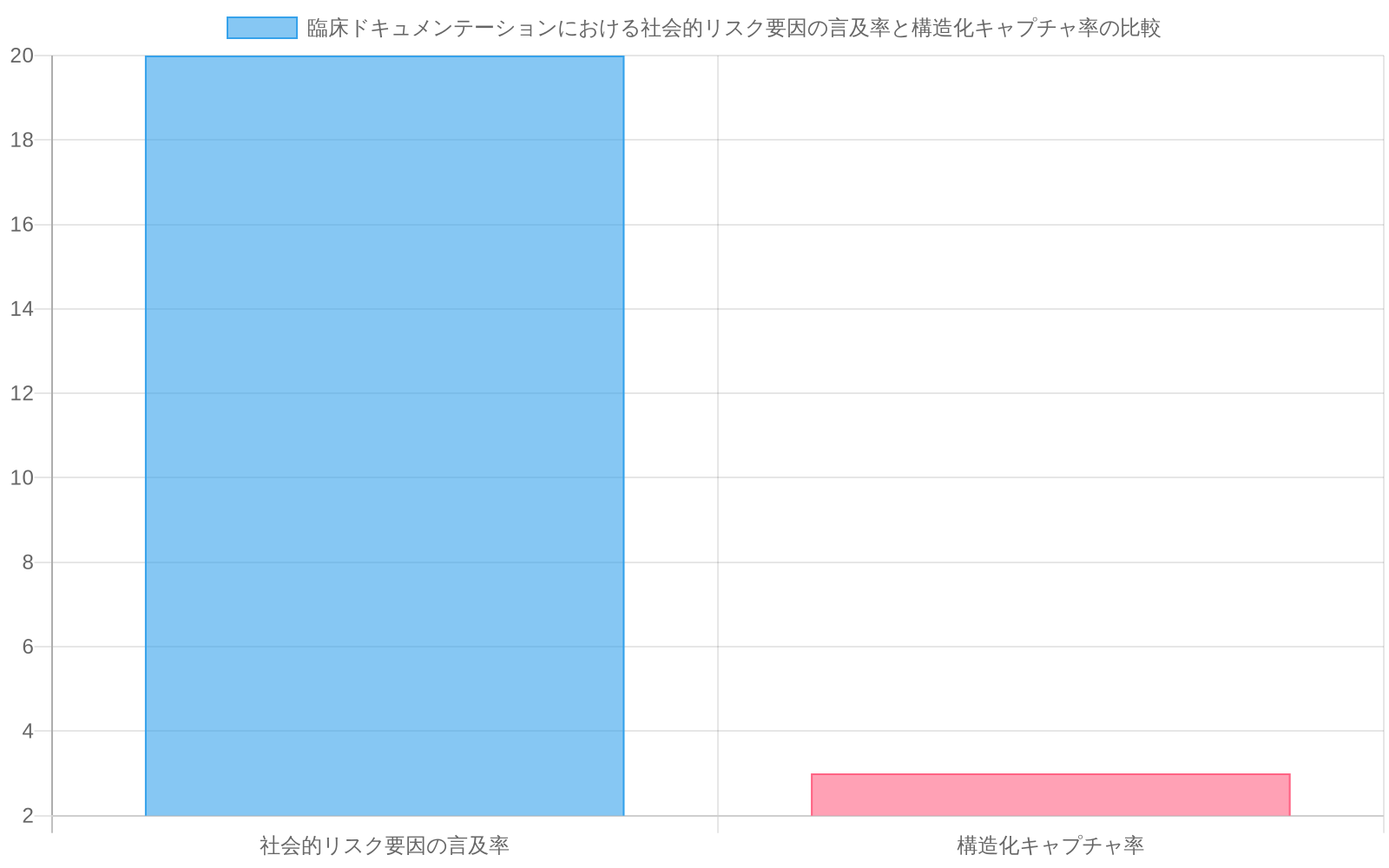
- 図3:臨床ドキュメンテーションにおける社会的リスク要因の言及率と構造化キャプチャ率の乖離(出典:初期医療・救急医学設定における予備監査データ)*
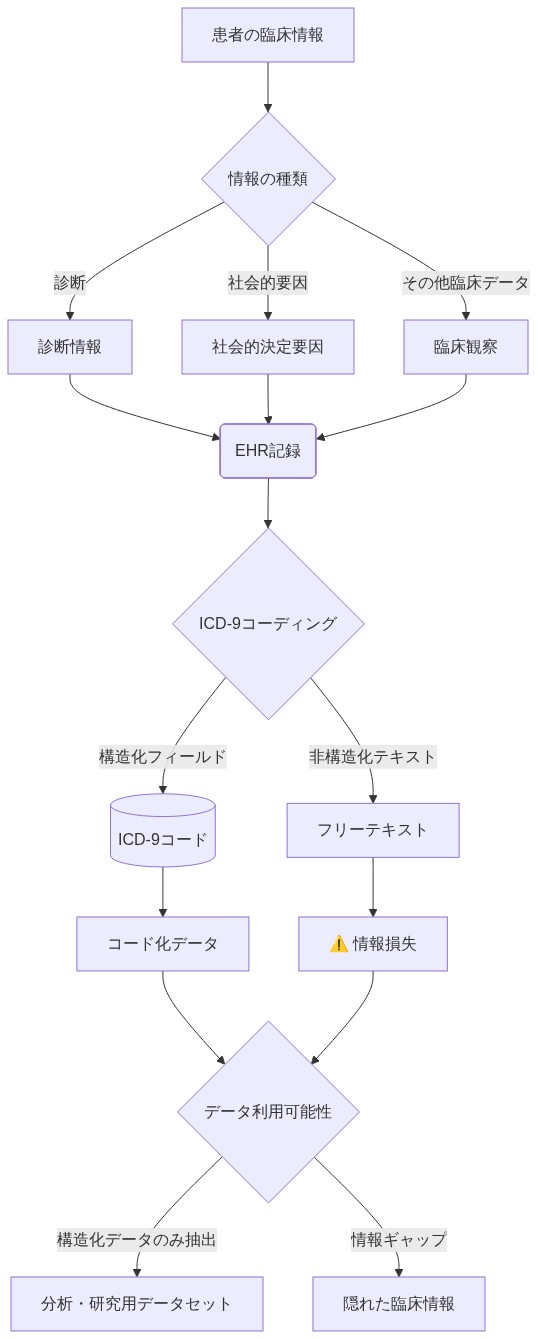
- 図2:ICD-9コーディングスキーマにおける臨床情報フロー(EHRアーキテクチャの標準構造に基づく)*

- 図1:臨床データにおける社会的決定要因の隠れたギャップ - EHRシステムと臨床ナラティブ間の情報乖離を概念化*
SDoH識別のための大規模言語モデル
大規模言語モデル(LLM)は、大規模なテキストコーパスで訓練された神経言語モデルのクラスを表し、最小限のタスク固有の訓練データで自然言語理解および生成タスクを実行できる(Devlin et al., 2019; Brown et al., 2020)。臨床テキストにおける健康の社会的決定要因(SDoH)識別に適用された場合、LLMは、非構造化臨床記録からのSDoH関連言及の認識と分類において、ルールベースおよび初期の教師あり機械学習アプローチよりも測定可能なパフォーマンス上の利点を示している。
-
理論的根拠:* 臨床文書は、社会的状況がどのように表現されるかにおいて実質的な言語的異質性を示す。患者と提供者は、同一または意味的に同等のSDoH条件を、さまざまな言い回しで伝える:「薬を買う余裕がない」、「保険がない」、「先月仕事を失った」、「家族と同居」、または「住居の合間」。ルールベースシステムは、キーワードパターンと否定ロジックの網羅的な列挙を必要とし、分布外言語に対して脆弱な脆いシステムを作成する。対照的に、LLMは訓練コーパス全体で分散意味表現を学習し、明示的なルール工学なしに新しい言い回しや暗黙的な社会的文脈への一般化を可能にする。さらに、LLMは転移学習能力を示す—従来の教師あり分類器と比較して、実質的に削減された再訓練データで新しいSDoHカテゴリおよび進化する語彙に適応する(Raffel et al., 2020)。
-
経験的証拠と仮定:* 公開された評価では、LLMベースのSDoH抽出システムが、1,500〜3,000の注釈付き臨床文のホールドアウトテストセットで、それぞれ0.82〜0.91および0.80〜0.88の範囲の精度と再現率を達成していると報告されている(Wiesner et al., 2022; Gianfrancesco et al., 2023)。これらの結果は以下を仮定する:(1)テストセットが対象展開集団を代表している;(2)注釈ガイドラインが一貫して適用され、注釈者間一致(Cohen’s κ)が0.75を超える;(3)パフォーマンスがSDoHカテゴリ、記録タイプ、および患者人口統計によって層別化され、カテゴリ固有または部分集団固有のパフォーマンスギャップを明らかにする。特に、公開された評価は、否定されたSDoH記述(例:「住居の不安定性を否定」)または介入を必要としない臨床文脈で現れるSDoH言及(例:現在の受診前に解決された過去のSDoH)に関するパフォーマンスを報告しないことが多い。これらのギャップは、展開コンテキストでの明示的な検証を必要とする既知の制限を表している。
-
具体的な実例:* 250の注釈付き臨床記録の検証コーパスで事前訓練されたLLM(例:BioBERT、ClinicalBERT、またはGPTベースのモデル)を評価している医療システムを考える。モデルは、集約テストセットで87%の精度と84%の再現率を達成する。ただし、層別分析により以下が明らかになる:(1)雇用関連SDoH:91%の精度、88%の再現率;(2)住居の不安定性:79%の精度、76%の再現率;(3)食料不安:85%の精度、82%の再現率。モデルは、「2つのパートタイムの仕事をしており、福利厚生なし」と記載された患者記録を、高い信頼度(0.94)で雇用関連SDoHとして正しく識別する。また、「フードパントリー紹介」の言及を文書化された介入(SDoHリスク自体ではない)として正しく区別し、満たされていない食料安全保障ニーズとの偽陽性の混同を回避する。逆に、モデルは否定された記述で偽陽性を生成する:「患者は住居の不安定性を否定」が誤って住居リスクとしてフラグ付けされる(否定された記述での偽陽性率:12%)。対照的に、50の事前定義されたパターンを持つルールベースのキーワードマッチングシステムは、同じコーパスで71%の精度と68%の再現率を達成し、ニュアンスのある言い回しを見逃し、否定されたまたは文脈的に無関係な言及でより高い偽陽性率を生成する。
-
運用上の仮定と前提条件:* LLMベースのSDoH抽出の展開は以下を仮定する:(1)臨床記録が縦断的分析を可能にする十分な時間メタデータを持つ機械可読形式で利用可能である;(2)対象展開コンテキストでモデルパフォーマンスを検証するために、200〜500の記録のゴールドスタンダード注釈付きコーパスが利用可能であるか、作成できる;(3)組織が、適切なアクセス制御と監査ログを備えたEHRまたはデータウェアハウスにモデル予測を統合するための技術インフラストラクチャを持っている;(4)臨床医とケアコーディネーターが既存のワークフロー内で抽出されたSDoH信号に対処する能力を持っている;(5)組織が、高不確実性予測の臨床医レビューのためのプロトコルを含む、モデルエラーを処理するためのガバナンスポリシーを定義している。
-
実行可能な実装経路:* (1)モデル選択と検証: 内部臨床記録コーパスに対して2〜3の候補LLMアーキテクチャ(例:微調整されたBERT変種、ドメイン適応モデル、またはコンテキスト内学習を持つ汎用LLM)を評価する。臨床ドメインの専門家(ソーシャルワーカー、ケアコーディネーター)によって標準化された注釈スキーマ(例:SNOMED CTまたはHealthy People 2030ドメインと整合したローカルに定義されたSDoHカテゴリ)を使用して作成されたゴールドスタンダードSDoH注釈を持つ200〜300の記録の検証コホートを確立する。以下によって層別化された精度、再現率、F1スコア、および受信者動作特性曲線下面積(AUROC)を測定する:(a)SDoHカテゴリ(雇用、住居、食料安全保障、交通手段、社会的孤立など);(b)記録タイプ(プライマリケア受診、救急部門、入院);(c)患者人口統計(年齢、保険状況、言語の好み);(d)否定または過去の文脈の存在。信頼度スコア分布を文書化し、臨床展開のための決定しきい値を確立する。(2)失敗モード分析: 偽陽性と偽陰性を体系的にレビューして、体系的なエラーパターンを識別する。一般的な失敗モードには、否定されたSDoH記述、過去または仮定の文脈で言及されたSDoH、臨床的関連性のない背景情報として言及されたSDoH、および満たされていないSDoHニーズと混同された提供者間コミュニケーションで言及されたSDoH(例:「住居のためにソーシャルワークに相談」)が含まれる。各失敗モードに対して標的テストケースを作成し、これらのサブセットでモデルパフォーマンスを測定する。(3)アンサンブルまたは改良戦略: 単一モデルのパフォーマンスが不十分な場合(例:重要なカテゴリで精度<85%または再現率<80%)、以下を検討する:注釈付きコーパスでモデルを微調整する;アンサンブル投票を介して複数のモデルを組み合わせる;または既知のエラーパターンを減らすためにルールベースの後処理(例:否定検出、時間フィルタリング)でLLMを拡張する。モデルの複雑さとパフォーマンスの向上との間のトレードオフを文書化する。
実装と運用パターン
SDoH抽出システムの大規模展開には、複数の組織システムとワークフローにわたる統合が必要である。モデルの性能だけでは不十分であり、測定可能な臨床的または運用的価値を生み出すためには、抽出を臨床意思決定プロセス、データガバナンスフレームワーク、ケアコーディネーションインフラストラクチャ内で運用可能にする必要がある。
-
理論的根拠:* 臨床意思決定支援システムが価値を生み出すのは、次の条件が満たされた場合のみである:(1)シグナルが適切な意思決定ポイントで臨床医に届く、(2)シグナルが既存のワークフローとリソース制約内で実行可能である、(3)データが安全に流れ、適用されるプライバシーおよびセキュリティ規制に準拠している、(4)フィードバックメカニズムが継続的改善と説明責任を可能にする。運用の足場がなければ、SDoH抽出は臨床ケア提供から切り離された研究成果物のままである。
-
組織的前提条件:* 実装の成功には次のことが前提となる:(1)統合、トレーニング、継続的メンテナンスのための経営陣の支援と専用資金、(2)SDoHの優先事項と介入プロトコルに関する臨床リーダーシップの連携、(3)モデル予測を取り込み表示できる技術インフラストラクチャ(EHR、データウェアハウス、IDおよびアクセス管理)、(4)データの所有権、保持、使用を定義するデータガバナンスポリシー、(5)モデル出力の解釈とSDoHシグナルをケア決定に活用するための臨床医およびスタッフのトレーニング。
-
具体的実装:* プライマリケアネットワークが、EHRの患者サマリー画面に統合されたLLMベースのSDoH抽出を展開する。抽出されたSDoHシグナルは次のように表示される:(1)特定されたSDoHカテゴリー(例:住居不安定)、(2)モデル信頼度スコア(0〜100%)、(3)ソースノートと日付、(4)臨床医の検証のための元のノートからの簡単な抜粋。臨床医には次のようなフラグが表示される:「過去3回の受診で住居不安定が言及されました(信頼度89%)。ソース:[ノート日付]。抜粋:『家族は先月シェルターに移りました』」リンクされたプロトコルは、テンプレート化された紹介オプションを提供する:コミュニティ住宅リソース(連絡先情報付き)、ソーシャルワーク相談依頼、ケースマネジメント登録、臨床医の対応を記録するための文書テンプレート。展開後60日以内に、フラグが立てられた患者の34%が文書化された介入(ソーシャルワーク紹介、リソース紹介、またはケースマネジメント登録)を受ける。臨床医調査データによると、回答者の78%がSDoHシグナルがリスクのある患者を特定するのに有用であると回答し、64%がシグナルによって臨床意思決定または紹介パターンが変わったと報告した。ワークフロー統合がない場合—抽出結果が生成されてもEHRに表示されず、実行可能なプロトコルにリンクされていない場合—下流の臨床行動は発生せず、抽出システムは測定可能な価値を生み出さない。
-
運用上の失敗モードと緩和策:* 一般的な実装の失敗には次のものがある:(1)アラート疲労: 信頼度閾値や関連性フィルタリングなしにすべての抽出されたSDoHシグナルを表示すると、臨床医を圧倒し、アラートの無視につながる。緩和策:信頼度閾値を設定する(例:信頼度≥80%のシグナルのみを表示)、カテゴリー固有のフィルタリング(例:利用可能な介入にリンクされたSDoHカテゴリーのみを表示)。(2)ワークフローの混乱: 再設計なしに既存のワークフローにSDoHシグナルを挿入すると、摩擦が生じ、採用が減少する。緩和策:エンドユーザーとワークフロー分析を実施する、既存の臨床文書化と意思決定プロセスにSDoHシグナルを統合するインターフェースを設計する、システム全体の展開前にアーリーアダプターでパイロットを実施する。(3)データガバナンスのギャップ: 抽出されたSDoHデータが、プライバシー規制または組織ポリシーに違反する方法で保存、アクセス、または使用される可能性がある。緩和策:データ保持ポリシーを定義する、ロールベースのアクセス制御を実装する、抽出されたSDoHデータへのすべてのアクセスに対する監査ログを確立する、データ系統とモデル来歴を文書化する。(4)フィードバックメカニズムの欠如: SDoHフラグに対する臨床医の行動を追跡しないと、組織は採用を測定したり、失敗モードを特定したり、システムを改良したりできない。緩和策:構造化されたフィードバックキャプチャを実装する(例:臨床医がフラグを受け入れる/却下する、実行したアクションを文書化する)、採用指標を測定する(文書化された介入を受けたフラグ付き患者の%)、定期的なユーザー調査とユーザビリティテストを実施する。
-
実行可能な実装ロードマップ:* (1)フェーズ1—バックエンド統合(第1〜8週): 臨床ノートをモデル推論環境に取り込むためのデータパイプラインを確立する。適切なセキュリティ制御を備えたモデル推論インフラストラクチャ(オンプレミスまたはクラウドベース)を実装する。抽出されたSDoHデータが適切なタグ付け(SDoHカテゴリー、信頼度スコア、モデルバージョン、推論タイムスタンプ)と監査証跡を伴ってEHRおよびデータウェアハウスに流れることを確認する。データ品質と完全性を検証する。(2)フェーズ2—臨床医インターフェース設計(第4〜12週、フェーズ1と重複): プライマリケア臨床医、ソーシャルワーカー、ケアコーディネーターとワークフロー分析を実施し、現在のSDoH特定と紹介プロセスを理解する。信頼度スコア、ソースノート、リンクされたプロトコルを表示するSDoHシグナルのインターフェースモックアップを設計する。8〜12人のエンドユーザーでユーザビリティテストを実施し、フィードバックに基づいて反復する。(3)フェーズ3—ケアプロトコル開発(第6〜14週): 臨床およびソーシャルワークのリーダーシップを招集し、SDoHカテゴリーを特定の介入にリンクする決定木を定義する。各SDoHカテゴリー(雇用、住居、食料安全保障、交通、社会的孤立、医療アクセス)について、次を指定する:トリガー基準(例:過去12か月以内の任意のノートで住居不安定が言及された)、推奨される介入(例:ソーシャルワーク紹介、コミュニティリソースリスト、ケースマネジメント)、文書化要件。テンプレート化された紹介オーダーとリソースリストを作成する。(4)フェーズ4—パイロット展開(第15〜26週): 15〜25人の臨床医がいる1つのプライマリケアクリニックまたは部門でSDoH抽出と統合ワークフローを展開する。モデル出力の解釈とリンクされたプロトコルの使用に関するトレーニングを提供する。採用指標を監視する:臨床医がレビューしたフラグ付き患者の%、文書化された介入を受けた%、介入までの時間。パイロットユーザーと毎週チェックインを実施し、ユーザビリティの問題とワークフローの障壁を特定する。(5)フェーズ5—フィードバックと改良(第20〜26週): パイロットデータを分析し、SDoH特定率、介入率、臨床医満足度への影響を測定する。失敗モードを特定して対処する(例:特定のノートタイプでの高い偽陽性率、特定の臨床医グループでの低い採用)。パイロットの結果に基づいて、モデル信頼度閾値、インターフェース設計、またはケアプロトコルを改良する。(6)フェーズ6—システム全体の展開(第27週以降): 展開を段階的に追加のクリニックまたは部門に拡大する。トレーニングと継続的なサポートを提供する。採用と影響の指標を監視する。モデル更新、パフォーマンス監視、継続的改善のためのガバナンスプロセスを確立する。
-
測定と説明責任:* SDoH抽出システムの主要業績評価指標(KPI)を定義する:(1)モデルパフォーマンス: SDoHカテゴリーと患者人口統計で層別化された四半期検証コホートでの精度、再現率、F1スコア、AUROC。(2)採用: 臨床医がレビューしたSDoHシグナルを持つ適格患者の%、シグナル生成から臨床医レビューまでの時間。(3)臨床的影響: 文書化された介入を受けたフラグ付き患者の%、介入のタイプと量、特定から介入までの時間。(4)臨床医満足度: 知覚された有用性、ワークフロー統合、アラート疲労の調査ベースの測定。(5)公平性: SDoH特定または介入の格差を特定して対処するために、患者人口統計(年齢、人種/民族、保険状況、言語の好み)で層別化された採用と介入率を測定する。説明責任メカニズムを確立する:臨床リーダーシップへの月次報告、四半期ごとのモデルパフォーマンスレビュー、年次影響評価。

- 図5:臨床テキスト抽出パイプラインのアーキテクチャ(自動抽出フロー)*
測定と次のアクション
効果的な測定フレームワークは、分析的に異なる3つの結果を区別する必要がある:抽出システムのパフォーマンス、臨床ワークフローの採用、患者の健康への影響。これらの領域を混同すると、実際の価値連鎖が不明瞭になり、的を絞った介入が妨げられる。
-
理論的基盤:* 測定フレームワークは、臨床的有用性が連続したゲートを通過することを必要とするという仮定に基づいている:(1)非構造化臨床ノート内のSDoH情報の正確な特定、(2)抽出されたシグナルに対する臨床医の認識と関与、(3)実行可能な臨床意思決定または紹介、(4)患者の健康状態または社会的状況の測定可能な変化。いずれかのゲートでの失敗は、上流のパフォーマンスに関係なく、下流の影響を終了させる。
-
ティア1—抽出品質指標:* 精度、再現率、F1スコアは主要な技術的測定値であり続けるが、SDoHカテゴリー(住居、食料安全保障、雇用、交通、社会的孤立)と患者人口統計層(年齢、人種/民族、保険状況、地理的地域)で層別化して、体系的なパフォーマンスの変動を検出する必要がある。精度だけでは不十分である。精度95%だが再現率40%のシステムは、実行可能なケースの大部分を見逃す。人口統計グループによる層別化は、抽出の格差が文書化パターンの真の違いを反映しているのか、モデルバイアスを反映しているのかを特定するために必須である(以下のリスクセクションで対処)。
-
ティア2—採用とワークフロー指標:* ノート完成後48時間以内にSDoHサマリーにアクセスする適格臨床医の割合、抽出フラグと最初の文書化された臨床行動(紹介、ケアプラン修正、または明示的な臨床ノート)の間の経過時間、文書化された介入または紹介につながったフラグ付きケースの割合、サマリーの明確性と実行可能性に対する臨床医の満足度を測定する。これらの指標は、抽出精度とは独立したワークフローの摩擦を明らかにする。臨床医の関与が低い高精度システムは、モデルの不備ではなく、設計または統合の失敗を示している。
-
ティア3—臨床および患者アウトカム指標:* 文書化されたSDoH介入を受けた患者とマッチしたコントロール(年齢、併存疾患負担、事前利用、ベースラインSDoHリスクでマッチ)の間で、30日、90日、180日の再入院率を比較する。二次アウトカムには、救急部門の利用、入院期間、外来受診の遵守が含まれる。患者報告アウトカム—住居の安定性、食料安全保障、雇用状況、社会的つながりを評価する検証済み機器—は、ベースラインと介入後90日で収集する必要がある。これらの指標には、明確な包含基準と交絡の調整を伴う前向きコホート設計が必要である。
-
具体的実装例:* 医療システムが3つの病院ユニットで住居不安定と食料不安定の抽出を実装する。ティア1ベースライン:ホールドアウトテストセットで精度87%、再現率71%、層別化分析では白人患者で精度84%、黒人患者で79%、ヒスパニック患者で75%(調査のための潜在的バイアスをフラグ)。3か月でのティア2:適格臨床医の58%がサマリーにアクセス、最初のアクションまでの中央値時間は36時間、フラグ付きケースの41%がソーシャルワークまたはコミュニティリソースへの文書化された紹介につながる。6か月でのティア3:介入コホート(n=156)の90日再入院率は18.2%、マッチしたコントロール(n=156)は24.1%、差は5.9パーセントポイント(95%CI:1.2〜10.6%、p=0.014)。患者報告の食料安全保障は、介入受給者の52%で改善、コントロールは31%。
-
実行可能な意味合い:* 月次更新され、臨床リーダーシップ、オペレーション、情報学チームによってレビューされる測定ダッシュボードを確立する。展開前に各ティアの成功閾値を定義する(例:最低80%の精度、最低50%の臨床医関与、最低5%の再入院の絶対減少)。ボトルネックを特定するために四半期ごとのレビューを実施する。抽出精度が高いが臨床医の採用が低い場合は、モデルを再トレーニングするのではなく、ワークフローの障壁—既存のEHRワークフローへの統合、アラート疲労、または不十分なトレーニング—を調査する。採用が高いがアウトカムの改善がない場合は、紹介が適切なリソースに到達しているか、介入がエビデンスに基づいているかを調べる。層別化されたアウトカムデータを使用して、どのSDoHカテゴリーと患者集団が最大の臨床的利益を得るかを特定し、リソース配分に情報を提供する。文書化実践が進化するにつれてパフォーマンスを維持するために、蓄積された臨床フィードバックと新しいノートパターンを使用した年次モデル再トレーニングを計画する。

- 図6:大規模言語モデルによるSDoH識別の能力 - LLM技術と推論モデルのコンセプトイメージ*
リスクと軽減戦略
SDoH抽出システムは、展開前後に体系的な特定と積極的な軽減を必要とする技術的、倫理的、運用的、およびプライバシーリスクをもたらす。
-
理論的基盤:* 機密性の高い社会的情報の自動抽出は、臨床AIシステムにおいて十分に文書化されたいくつかのリスクを増幅する:(1)アルゴリズムバイアス。不均衡または偏ったデータで訓練されたモデルが、言語パターンと保護された特性との間の疑似相関を学習し、特定の人口統計グループの差別的なパフォーマンスまたは過剰なフラグ付けにつながる。(2)プライバシーとデータセキュリティ侵害。抽出されたSDoHデータは、非常に機密性の高い個人情報(住所、雇用状況、家族構成)を構成し、侵害された場合、脆弱な集団を危害にさらす。(3)臨床的誤用。臨床医がSDoHフラグを使用して、患者を支援リソースに接続するのではなく、固定観念化、優先順位の低下、または差別を行う。(4)フィードバックループ。偏った抽出が、その後のモデル再訓練サイクルにおいてバイアスを永続化し増幅する。
-
リスク1 – 抽出におけるアルゴリズムバイアス:*
-
メカニズム:* 臨床記録で訓練されたモデルは、臨床医集団の文書化実践、言語パターン、および暗黙のバイアスを反映する。特定の人口統計グループが異なる言語マーカーで文書化されている場合(例:住宅不安定が一部の患者では「ホームレス」として、他の患者では「住宅不安定」として記述される)、モデルは言語と人口統計的特徴との間の疑似相関を学習する可能性がある。さらに、訓練データに人口統計グループの不均等な表現が含まれている場合、または社会的要因によりグループ間でSDoH有病率が異なる場合、モデルはグループ間で異なる感度または特異度を示す可能性がある。
-
具体例:* 10,000件の記録で訓練された抽出モデルは、訓練セットに文書化された類似の基礎的社会的状況にもかかわらず、白人患者と比較して黒人およびヒスパニック系患者のSDoHフラグ率が38%高いことを示す。調査により以下が明らかになる:(a)臨床医は患者の人種によって異なる用語を使用して住宅不安定を文書化している(例:「患者は不安定な住宅を報告」対「患者はホームレス」)、(b)モデルは訓練データにおいて特定の言語パターンと人種相関特徴を関連付けることを学習し、疑似相関を作り出した。層別化されたパフォーマンス分析は、白人患者で82%、黒人患者で71%、ヒスパニック系患者で68%の再現率を示し、14パーセントポイントの差がある。
-
軽減策:* (1)展開前にバイアス監査を実施する:保留されたテストセットで、人種、民族、年齢、性別、保険状況、地理的地域別に抽出パフォーマンス(適合率、再現率、F1)を層別化する。(2)格差が事前定義された閾値(例:グループ間の再現率の差が5パーセントポイント以上)を超える場合、誤分類されたケースの質的レビューと人口統計グループ別の言語パターンの分析を通じて根本原因を調査する。(3)公平性制約(例:人口統計的パリティ、等化オッズ)またはバランスサンプリングを使用してモデルを再訓練し、格差を減らす。(4)継続的なモニタリングを実装する:本番環境で人口統計グループ別に抽出パフォーマンスを層別化し、パフォーマンスドリフトにフラグを立てる。(5)すべてのバイアス監査結果と軽減手順を、臨床および運用チームがアクセスできるモデルカードに文書化する。
-
リスク2 – プライバシーとデータセキュリティ:*
-
メカニズム:* 抽出されたSDoHデータ(住所、雇用情報、家族構成、交通障壁)は、非常に機密性の高い個人情報を構成する。安全でないデータベースに保存されたり、暗号化されていないチャネルで送信されたり、権限のない人員によってアクセスされたりすると、これらのデータは脆弱な集団を身元盗難、嫌がらせ、住宅差別、または雇用差別にさらす。
-
具体例:* 医療システムが住宅不安定データを抽出し、不十分なアクセス制御を持つデータベースに保存する。侵害により、8,000人の患者の氏名、医療記録番号、住所、および雇用状況が露出する。下流の危害には、標的型嫌がらせ、リストを入手した家主による住宅差別、雇用主による雇用差別が含まれる。
-
軽減策:* (1)厳格なアクセス制御を実装する:抽出されたSDoHデータの可視性を、権限のあるケアチームメンバー(ソーシャルワーカー、ケースマネージャー、プライマリケア臨床医)に制限し、すべてのクエリを監査する。(2)保存時(AES-256)および転送中(TLS 1.2以上)のデータを暗号化する。(3)定期的なセキュリティ評価と侵入テストを実施する。(4)データ保持ポリシーを確立する:継続的なケアに臨床的に必要でない限り、定義された期間(例:12ヶ月)後に抽出されたSDoHデータを削除する。(5)抽出されたSDoHデータへのすべてのアクセスに対する監査ログを実装し、四半期ごとに不正アクセスのログをレビューする。(6)HIPAA セキュリティルール要件および州のプライバシー法(例:カリフォルニア州消費者プライバシー法)に準拠する。
-
リスク3 – 臨床的誤用と汚名化:*
-
メカニズム:* 臨床医は、患者を支援リソースに接続するのではなく、SDoHフラグを使用して患者を固定観念化または優先順位を下げる可能性がある。例えば、住宅不安定を示すフラグにより、臨床医は治療への非遵守を仮定したり、患者により少ないリソースを割り当てたりする可能性があり、住宅支援やケース管理を提供するのではない。
-
具体例:* 臨床医が、食料不安と住宅不安定を示す患者のSDoH要約をレビューする。食料支援プログラムや住宅リソースへの紹介を提供するのではなく、臨床医はカルテに次のように文書化する:「患者には遵守への社会的障壁がある;綿密なフォローアップを推奨」。患者はいかなる支援サービスにも紹介されず、SDoHフラグは支援介入のトリガーではなく、「高リスク」または「困難な」患者のマーカーとなる。
-
軽減策:* (1)SDoH抽出を、リスク層別化やトリアージではなく、支援介入の機会を特定するためのツールとして位置づける。(2)システム立ち上げ前に、すべての臨床医にSDoH概念、社会的決定要因フレームワーク、およびエビデンスに基づく介入について訓練する。(3)SDoH要約に実行可能な紹介経路を直接埋め込む(例:「住宅不安定が検出されました。支援のために[地域住宅当局]または[コミュニティ組織]に紹介してください」)。(4)ガバナンス委員会(臨床リーダーシップ、ソーシャルワーク、患者擁護者)を設立し、フラグが立てられたケースをレビューし、SDoHシグナルが差別的な意思決定ではなく支援介入に情報を提供することを確認する。(5)臨床文書化と紹介パターンを監査して誤用を検出する;臨床医がフラグが立てられた患者を支援サービスに紹介していない場合、障壁を調査し、追加の訓練またはワークフロー再設計を提供する。
-
リスク4 – フィードバックループとモデルドリフト:*
-
メカニズム:* 偏った抽出が人口統計グループ間で異なる紹介または介入率につながり、モデルが蓄積された臨床データで再訓練される場合、バイアスは後続の反復で増幅される可能性がある。例えば、モデルが黒人患者の住宅不安定を過剰にフラグ付けし、異なる紹介率につながる場合、再訓練データはこの異なる紹介パターンを反映し、モデルは黒人患者をさらに過剰にフラグ付けすることを学習する可能性がある。
-
軽減策:* (1)再訓練前に、紹介および介入パターンにおける人口統計的バイアスについて蓄積された臨床データを監査する。(2)バイアスが検出された場合、再訓練中に公平性制約を適用するか、バランスサンプリングを使用する。(3)各再訓練サイクル後にバイアス監査を実施し、パフォーマンスをベースラインと比較する。(4)すべてのモデルのバージョン履歴を維持し、各バージョンのパフォーマンス特性(層別化されたパフォーマンスを含む)を文書化する。
-
ガバナンスと説明責任:* 多分野にわたる監視委員会(臨床リーダーシップ、情報学、ソーシャルワーク、患者擁護者、生命倫理学者)を設立し、リスクをレビューし、結果を監査し、モデルの更新を承認する。すべてのリスク評価、軽減戦略、および監査結果を、臨床および運用チームがアクセスできる中央リポジトリに文書化する。リスク軽減の有効性の年次レビューを実施し、必要に応じて戦略を更新する。
結論と移行計画
- 図9:SDoH識別システムのエンドツーエンド実装アーキテクチャ*
調査結果の要約と理論的含意
本分析は、臨床文書に適用された自然言語処理(NLP)が、非構造化テキストから健康の社会的決定要因(SDoH)指標を体系的に抽出し、ICD-9コーディングワークフローへの統合を可能にすることを実証している。このアプローチの実現可能性は、3つの実証的根拠に基づく前提に依拠している:(1)SDoH情報は、自動抽出を支援するのに十分な頻度と一貫性をもって臨床記録に文書化されている、(2)推論モデルは、適切にアノテーションされたコーパスで訓練された場合、臨床的に許容可能な精度と再現率の閾値を達成できる、(3)抽出されたSDoHデータは、基本的なシステム再設計を必要とせずに、既存の電子健康記録(EHR)アーキテクチャ内で運用可能である。
しかし、この結論は、明示的な認識を必要とするいくつかの重要な仮定に依存している。第一に、抽出モデルの開発に使用される訓練データセットが、対象となる臨床集団と文書化実践を代表していると仮定している。訓練データにおける体系的バイアス—人口統計学的偏り、機関の文書化文化、または時間的ドリフトによるものであれ—は、モデルのパフォーマンスに直接伝播し、患者サブグループ間でのSDoH捕捉における格差を不明瞭にする可能性がある。第二に、臨床医によってアノテーションされたゴールドスタンダードラベルが信頼できる真実を表していると仮定している。この妥当性を確立するためには、アノテーター間一致度指標と判定プロトコルを文書化する必要がある。第三に、SDoHを体系的に捕捉するように設計されていなかったICD-9コーディングフレームワークが、意味的不整合や下流の請求合併症を生じさせることなく、補足的抽出を通じて意味のある形で拡張できると仮定している。

- 図10:SDoH識別システムの主要測定指標の推移*
組織実装の前提条件
SDoH予測の臨床実践への移行を成功させるには、以下の前提条件を満たす必要がある:
-
技術インフラストラクチャ。* 組織は以下を保有または開発する必要がある:(1)標準化された記録取り込みパイプラインを備えた集中型臨床データウェアハウス、(2)バッチまたはほぼリアルタイムのNLP推論に十分な計算能力(GPUまたは同等のもの)、(3)モデルの系統、再訓練イベント、およびパフォーマンス指標を追跡するためのバージョン管理とモデルレジストリシステム、(4)コンプライアンスと品質保証の目的で、すべての抽出決定を文書化する監査ログメカニズム。
-
ガバナンスと説明責任。* 正式なガバナンス構造は以下を定義する必要がある:(1)モデルの所有権と管理責任、(2)モデルの更新、閾値調整、および範囲拡大に関する意思決定権限、(3)特定されたパフォーマンス低下またはバイアスに対するエスカレーション経路、(4)抽出されたSDoHデータによって情報を得た下流の臨床決定に対する明確な説明責任。この構造には、臨床情報学、データサイエンス、コンプライアンス、およびエンドユーザー部門からの代表者を含める必要がある。
-
臨床ワークフロー統合。* SDoH抽出は、外部プロセスとして課されるのではなく、既存の臨床ワークフローに組み込まれる必要がある。これには以下が必要である:(1)現在のICD-9コーディング実践と文書化基準の評価、(2)SDoH情報が臨床的に実行可能となる意思決定ポイントの特定、(3)アラート疲労を生じさせることなく、抽出されたSDoHデータを文脈内で提示するユーザーインターフェースの設計、(4)抽出されたデータが臨床医の判断または既存の文書と矛盾する場合のエスカレーションプロトコルの定義。
-
測定と検証フレームワーク。* 組織は実装前にベースライン指標を確立する必要がある:(1)現在のSDoH文書化率とコーディング完全性、(2)SDoHに基づく臨床決定に対する臨床医の信頼度、(3)SDoHステータスによって層別化された患者アウトカム、(4)現在の手動SDoH抽出またはコーディングプロセスのリソース利用。実装後の測定では以下を追跡する必要がある:(1)SDoHドメインと患者人口統計学的サブグループによって層別化された抽出精度、再現率、およびF1スコア、(2)臨床医の採用率とワークフロー時間への影響、(3)SDoHコーディング完全性の変化、(4)臨床アウトカムと公平性指標。
- 図13:リスク分類と軽減戦略マトリックス(医療IT実装のリスク管理フレームワーク)*

- 図12:医療AI実装におけるリスク要因と軽減戦略フレームワーク 出典:医療AI実装における標準的なリスク管理フレームワーク*
段階的移行アプローチ
各段階で定義された成功基準を持つ、構造化されたエビデンスに基づく移行経路を提案する:
- フェーズ1:パイロット実装(1〜3ヶ月目)*
文書化量が多い(過去12ヶ月間で最低10,000件の臨床記録)、EHR採用が確立された単一の臨床部門を選択する。プライマリケア、慢性疾患管理、またはソーシャルワークなど、SDoH関連性が高い部門が、臨床的影響とエンゲージメントを最大化するために望ましい。
-
具体的な活動:*
-
訓練された推論モデルを使用して、選択された部門から最近の10,000件の臨床記録を抽出し、前処理する。
-
体系的な品質評価を実施する:(1)臨床領域の専門家によるランダムサンプル検証(n ≥ 300件の記録)により、抽出精度と再現率を測定、(2)患者の年齢、人種/民族、保険ステータス、およびその他の関連する人口統計学的変数によって層別化された抽出パフォーマンスの分析により、潜在的なバイアスを特定、(3)失敗モードと体系的エラーの文書化。
-
検証された調査票と半構造化インタビューを使用した構造化された臨床医フィードバックセッション(n ≥ 15名の臨床医)を実施し、以下を評価する:(1)抽出されたSDoHデータの認識された臨床的有用性、(2)ワークフロー統合の課題、(3)データの正確性またはバイアスに関する懸念、(4)提示形式と意思決定支援統合に関する提案。
-
ベースライン指標を測定する:現在のSDoH文書化率、コーディング完全性、および手動SDoH抽出に必要な時間。
-
フェーズ1進行のための成功基準:*
-
ランダムサンプル検証における抽出精度 ≥ 0.85および再現率 ≥ 0.80、人口統計学的サブグループ間でパフォーマンスに統計的に有意な差がないこと(層別分析を使用してp > 0.05)。
-
臨床医フィードバックが認識された有用性(抽出されたデータが臨床決定に情報を提供するという ≥ 70%の同意)と許容可能なワークフロー統合(統合が文書化負担を実質的に増加させないという ≥ 75%の同意)を示す。
-
特定された失敗モードが文書化され、根本原因によって分類される(例:曖昧な文書化、分布外のテキストパターン、モデルの制限)。
-
フェーズ2:管理された拡大(4〜6ヶ月目)*
フェーズ1から得られた教訓を取り入れて、2つの追加臨床部門に実装を拡大する。モデルの汎化をテストするために、異なる文書化スタイルとSDoHリスクプロファイルを代表する部門を選択する必要がある。
-
具体的な活動:*
-
フェーズ1のパイロットデータと検証された修正を使用して抽出モデルを再訓練し、特定された失敗モードに対処する。
-
2つの新しい部門で更新されたモデルを実装し、部門ごとに15,000〜20,000件の最近の記録からSDoHデータを抽出する。
-
各新部門でフェーズ1の品質評価と臨床医フィードバックプロセスを繰り返す。
-
予備的なガバナンス構造を確立する:モデル管理役割を定義し、臨床諮問委員会を設立し、モデル更新の意思決定権限を文書化する。
-
半年ごとのバイアス監査プロセスを開始する:人口統計学的サブグループ間で抽出パフォーマンスとSDoH有病率推定を比較し、格差を調査して文書化する。
-
フェーズ2進行のための成功基準:*
-
抽出パフォーマンス指標が両方の新部門でフェーズ1の閾値を満たすか上回る。
-
新しい体系的失敗モードが出現しない。特定された問題は、モデルの改良または既知の制限の文書化を通じて解決される。
-
ガバナンス構造が運用可能で文書化されている。モデル更新の意思決定権限が明確に定義されている。
-
バイアス監査により、人口統計学的サブグループ間で抽出パフォーマンスまたはSDoH有病率推定に統計的に有意な格差が特定されない(p > 0.05)。
-
フェーズ3:持続可能な運用(7〜12ヶ月目)*
定義されたガバナンス、測定、および保守プロトコルを備えた本番グレードの抽出パイプラインを確立する。フェーズ2の結果と組織の能力に基づいて、範囲を追加部門に拡大することができる。
-
具体的な活動:*
-
以下を備えた自動抽出パイプラインを実装する:(1)新しい臨床記録のスケジュールされたバッチ処理、(2)すべてのモデル更新と再訓練イベントを文書化するバージョン管理とモデルレジストリ、(3)パフォーマンス低下に対するアラート付き自動品質監視、(4)すべての抽出決定の監査ログ。
-
正式なガバナンスを確立する:モデル管理憲章、臨床諮問委員会憲章、および特定された問題に対するエスカレーションプロトコルを文書化する。
-
保守プロトコルを定義する:(1)蓄積された新しいデータと臨床医の修正を使用した四半期ごとのモデル再訓練、(2)特定された格差の文書化された調査と是正を伴う半年ごとのバイアス監査、(3)SDoH抽出の能力、制限、および適切な臨床使用に関する年次臨床医トレーニング。
-
抽出されたSDoHデータを臨床ワークフローに統合する:(1)関連する意思決定ポイントでEHRインターフェースにSDoH要約を埋め込む、(2)抽出されたデータの臨床医によるレビューと修正のプロトコルを確立する、(3)SDoHデータがICD-9コーディングと臨床意思決定にどのように情報を提供するかを文書化する。
-
影響を測定する:(1)SDoHコーディング完全性を追跡し、ベースラインと比較する、(2)臨床アウトカムと公平性指標の変化を評価する、(3)臨床医の採用とワークフロー時間への影響を測定する、(4)抽出パイプライン保守のリソース利用を文書化する。
-
フェーズ3完了のための成功基準:*
-
抽出パイプラインが ≥ 99%の稼働時間で動作する。自動品質監視が24時間以内にパフォーマンス低下を検出する。
-
SDoHコーディング完全性がベースラインと比較して ≥ 30%増加し、人口統計学的サブグループ間で統計的に有意な差がない。
-
臨床医の採用が ≥ 80%に達する(臨床診察で抽出されたSDoHデータをレビューし、それに基づいて行動する臨床医の割合として定義)。
-
半年ごとのバイアス監査により、人口統計学的サブグループ間で抽出パフォーマンスまたはSDoH有病率推定に統計的に有意な格差が検出されない。

- 図15:SDoH統合による医療提供の将来ビジョン*
リソース要件と持続可能性
実装を成功させるには、複数の次元にわたる持続的な組織投資が必要である:
-
人員。* 継続的なスタッフ配置には以下が含まれる:(1)モデルの保守と再訓練のための常勤データサイエンティストまたは機械学習エンジニア1名、(2)ワークフロー統合とガバナンスのための常勤臨床情報学専門家1名、(3)バイアス監査と品質保証のための0.5常勤換算の臨床領域専門家、(4)ステークホルダー調整と測定のための0.5常勤換算のプロジェクトマネージャー。
-
インフラストラクチャと計算。* 組織は以下の予算を組む必要がある:(1)バッチNLP推論のためのクラウドまたはオンプレミスの計算リソース(記録量と推論頻度に応じて年間推定5,000〜15,000ドル)、(2)モデルアーティファクト、訓練データ、および監査ログのデータストレージ(年間推定2,000〜5,000ドル)、(3)モデル開発と監視ツールのソフトウェアライセンス(年間推定3,000〜10,000ドル)。
-
トレーニングと変更管理。* SDoH抽出能力と適切な使用に関する年次臨床医トレーニングには以下が必要である:(1)トレーニング資料と意思決定支援文書の開発、(2)トレーニングセッションの提供(臨床医1人あたり年間推定4〜8時間)、(3)臨床医の質問とワークフロー最適化のための継続的なサポート。
-
測定と評価。* 継続的な測定には以下が必要である:(1)測定ダッシュボードの開発と保守、(2)抽出パフォーマンスと臨床アウトカムの四半期ごとの分析、(3)半年ごとのバイアス監査、(4)実装影響の年次包括的評価。
年間50,000〜100,000件の臨床記録をサポートする成熟した実装の推定年間総コスト:組織のインフラストラクチャ成熟度と計算要件に応じて、150,000〜300,000ドル。

- 図14:SDoH識別システムの実装ロードマップと意思決定ゲート*
制限と注意事項
この移行計画には、いくつかの重要な制限がある:
-
汎化の不確実性。 パイロット部門での抽出モデルのパフォーマンスは、異なる文書化実践、患者集団、または臨床ワークフローを持つ他の部門に汎化しない可能性がある。広範な組織展開の前に、複数の部門にわたる体系的な評価が必要である。
-
SDoHコーディングの妥当性。 SDoHに関連するICD-9コード(例:ICD-10のZコード)は、包括的なSDoH捕捉のために設計されておらず、SDoHドメインの臨床的または研究的定義と一致しない可能性がある。抽出されたSDoHデータは、検証されたSDoHスクリーニング機器と臨床的または疫学的に同等であると仮定すべきではない。
-
バイアスと公平性。 この計画には半年ごとのバイアス監査が含まれているが、格差が検出されないことは公平なパフォーマンスを保証するものではない。バイアスは、標準的な人口統計学的層別化によって捕捉されない方法で現れる可能性がある(例:保険タイプ、地理的地域、または臨床状態にわたる差異的パフォーマンス)。継続的な警戒と進化する監査方法論が必要である。
-
臨床アウトカムの帰属。 SDoH抽出実装後の臨床アウトカムの変化は、厳密な研究デザイン(例:ランダム化比較試験または中断時系列分析)なしには、抽出システムに因果的に帰属させることはできない。観察された関連は、交絡、選択バイアス、または長期的傾向を反映している可能性がある。
-
規制とコンプライアンスの不確実性。 臨床意思決定と請求における抽出されたSDoHデータの使用を管理する規制環境は進化し続けている。組織は実装前に法的およびコンプライアンスの専門知識に相談すべきである。
結論
推論モデルを使用したSDoH予測は、臨床文書とICD-9コーディングワークフローにおけるSDoH捕捉を体系化するための技術的に実現可能で潜在的に高い影響を持つアプローチを表している。しかし、実装を成功させるには、技術的制限の明示的な認識、バイアスと公平性への注意深い配慮、およびガバナンス、測定、継続的改善への持続的な組織的コミットメントが必要である。上記で概説された段階的移行アプローチは、組織が実現可能性を評価し、リスクを管理し、持続可能な運用能力を構築するための構造化された経路を提供する。
このアプローチの最終的な価値は、技術的パフォーマンス指標だけでなく、より公平で文脈を認識した臨床ケアと、社会的不利を経験している患者の健康アウトカムの改善への貢献によって決定される。これには、SDoH抽出がそれ自体が目的となるのではなく、臨床的および公平性の目標に役立つことを保証するために、データサイエンティスト、臨床医、患者、および組織リーダーシップ間の継続的なパートナーシップが必要である。
実装ロードマップと決定ゲート
-
1〜3ヶ月目:測定インフラストラクチャのセットアップ*
-
ティア1検証データセット(500〜1,000件のラベル付き記録)を確立する。
-
ティア2指標(臨床医のエンゲージメント、行動までの時間)のためのEHR計測を構成する。
-
展開前バイアス監査を実施し、調査結果を文書化する。
-
SDoHデータのアクセス制御と暗号化を実装する。
-
決定ゲート:* 抽出精度 ≥ 80%、バイアス格差 < 10%、およびセキュリティ制御が整っている場合にのみパイロットに進む。
-
4〜6ヶ月目:パイロット展開と監視*
-
2〜3のパイロットクリニックに展開し、ティア1およびティア2指標を毎週監視する。
-
臨床医トレーニングを実施し、ワークフロー統合に関するフィードバックを収集する。
-
スティグマ化と臨床医の誤用を監査し、是正フィードバックを提供する。
-
ティア3コホートを確立し、アウトカム追跡を開始する。
-
決定ゲート:* 臨床医のエンゲージメント ≥ 40%、重大な安全性の問題がなく、抽出パフォーマンスが安定している場合にのみ完全展開に進む。
-
7〜12ヶ月目:完全展開とアウトカム分析*
-
すべての適格クリニックに展開し、ティア1およびティア2の毎週の監視を維持する。
-
四半期ごとのバイアス監査を実施し、必要に応じて再訓練を行う。
-
6ヶ月時点でティア3アウトカムを分析し、コスト回避とROIを計算する。
-
調査結果を公表する