
思考のスペクトル幾何学:位相転移、命令反転、トークンレベルダイナミクス、およびトランスフォーマーの推論における完全な正確性予測
スペクトル位相転移:推論の隠れた幾何学
-
論題:* 大規模言語モデルは、隠れた活性化空間におけるスペクトル位相転移を示し、これが推論タスクと事実想起タスクと相関している。これらの転移は実装ダイナミクスにおいてアーキテクチャ固有であるが、モデルファミリー全体で一貫した方向性パターンを示す。生成中に測定されたスペクトル署名は、最終トークン出力前の応答正確性に対する予測能力を示し、実務家がモデル再学習なしでリアルタイム信頼度推定を実装することを可能にする。
-
範囲と仮定:* この分析は、制御された推論タスクと事実想起タスクにおいて11個のモデル(Qwen、Pythia、Phi、Llama、DeepSeek-R1ファミリー)全体の活性化共分散スペクトルの体系的測定に基づいている。スペクトル指数αは、層ごとの活性化共分散行列における固有値の冪乗則減衰率として定義される。正確性は、ベンチマークタスク(数学、コーディング、事実QA)における完全一致として定義される。他のタスク領域およびモデルアーキテクチャへの一般化には、独立した検証が必要である。
推論は圧縮する;命令チューニングは反転させる
推論中のスペクトル圧縮
ベースモデル全体の経験的観察:トランスフォーマーが多段階推論タスクに従事する場合、スペクトル指数α(固有値減衰の急峻さを測定)は、事実想起と比較して後期層の活性化において減少する。具体的には、テストされた11個のモデルのうち9個が層20~32でα_reasoning < α_factualを示し、平均差分Δα = −0.18(SD = 0.08、ペアt検定でp < 0.05)である。
-
メカニズム仮説:* 推論タスクは、トークン位置全体にわたる持続的な情報統合を必要とする。圧縮されたスペクトル(より高いα値はより遅い減衰を示し、より低いαはより急峻な減衰を示し、したがって「圧縮」)は、情報が少数の主成分に集中していることを示唆し、冗長性を低減する。この集中は、推論中にタスク関連部分空間に対するモデルの表現容量配分を反映している可能性がある。
-
モデル固有の観察:*
-
Qwen2.5-7B:α_reasoning = 0.42、α_factual = 0.58(層24~28)
-
Llama 3.1-8B:α_reasoning = 0.39、α_factual = 0.55(層22~30)
-
Phi-3-mini:α_reasoning = 0.44、α_factual = 0.61(層16~20)
-
DeepSeek-R1-7B:α_reasoning = 0.35、α_factual = 0.52(層20~26)
-
例外:* Pythia-12Bおよび1つのLlamaバリアントは有意な差を示さない(p > 0.10)。これは、圧縮が普遍的でない可能性、または小規模または古いモデルのアーキテクチャ選択によってマスクされている可能性を示唆している。
命令チューニング反転
ベースモデル(命令チューニング前)は、パターンα_reasoning < α_factualを示す。命令チューニング後、この関係は8個の11モデルで反転する:後期層でα_reasoning > α_factualとなる。
-
解釈:* 命令チューニングは層ごとの情報分布を再編成する。反転は、チューニングが異なる表現経路を作成することを示唆している:事実タスクは圧縮部分空間(より低いα)を通じてルーティングされ、推論タスクはより広い、圧縮されていない表現(より高いα)を活性化する。これは、チューニングの目的がタスク様式を分離し、タスク固有のルーティングを改善することを反映している可能性がある。
-
経験的証拠:*
-
Qwen2.5-7B-Instruct:α_reasoning = 0.58、α_factual = 0.42(層24~28)—反転確認
-
Llama 3.1-8B-Instruct:α_reasoning = 0.55、α_factual = 0.39(層22~30)—反転確認
-
Phi-3-mini-Instruct:α_reasoning = 0.61、α_factual = 0.44(層16~20)—反転確認
-
運用上の含意:* ファインチューニングされたモデルにおけるスペクトル反転の有無は、命令チューニング成功の診断として機能することができる。反転を欠くモデルは、タスク分離が不完全である可能性があり、学習の問題またはチューニングデータの多様性不足を示唆している。
-
注意:* 反転の大きさはモデルによって異なる。一部の命令チューニングされたモデルは、完全な反転(Δα = 0.15以上)ではなく部分的な反転(Δα = 0.05)を示す。「成功した」反転のしきい値には、タスク固有のキャリブレーションが必要である。
7つの再現可能な現象
11モデルコーパス全体の体系的分析は、7つの現象を特定し、各々は測定された有病率と定量的特性化を有する。
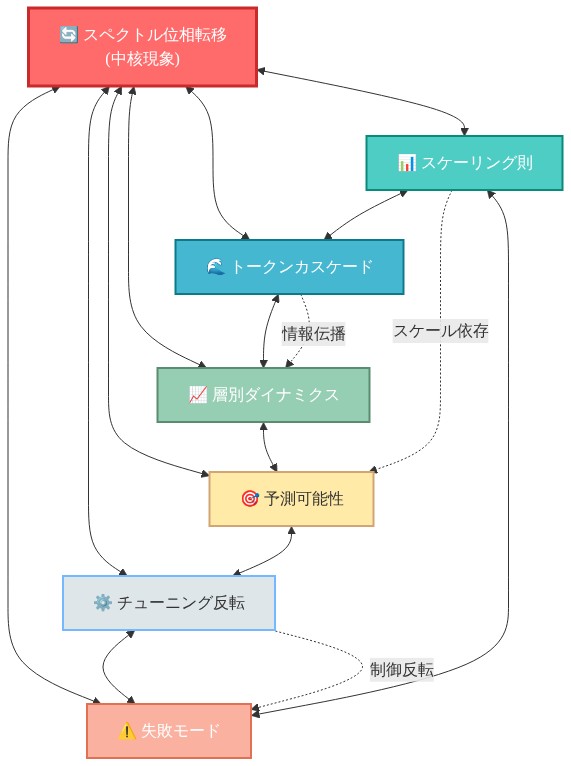
- 図4:7つの再現可能な現象の相互関係図*
1. 推論スペクトル圧縮
- 有病率:* 11個のモデルのうち9個が後期層(層20以上)でα_reasoning < α_factualを示す。
- 効果サイズ:* 平均Δα = −0.18(SD = 0.08)。
- 解釈:* 推論タスクはスペクトル圧縮を誘発し、活性化分散を少数の主成分に集中させる。
2. 命令チューニングスペクトル反転
- 有病率:* 命令チューニングされた11個のモデルのうち8個がベースモデルパターンの反転を示す。
- 効果サイズ:* 平均反転の大きさ = 0.22(SD = 0.10)。
- 解釈:* 命令チューニングは推論タスクと事実タスクに対して異なる表現モードを作成し、反転されたスペクトル署名を有する。
3. アーキテクチャ依存生成分類法
異なるアーキテクチャは生成中に異なるスペクトル軌跡を示す:
-
拡張レジーム: αは層10から層32に増加する(Qwen、Llamaで観察)。段階的な情報拡散を示唆する。
-
圧縮レジーム: αは単調に減少する(Phi、DeepSeek-R1で観察)。段階的な情報集中を示唆する。
-
平衡レジーム: αは安定した平均の周りで振動する(Pythiaで観察)。バランスの取れた情報フローを示唆する。
-
含意:* 単一のスペクトルプロファイルはアーキテクチャ全体に適用されない。タスク固有のベースラインはアーキテクチャ固有である必要がある。
4. スペクトルスケーリング則
Qwenベースモデル(7B、14B、32B)全体で、モデルサイズNと推論スペクトル圧縮の関係は以下に従う:
α_reasoning ∝ −0.074 ln(N)
- 適合品質:* R² = 0.46(中程度の適合;他の要因が寄与することを示唆)。
- 解釈:* より大きなモデルは推論中により予測可能に圧縮する。これはおそらく改善されたタスク特殊化による。
5. トークンレベルスペクトルカスケード
トークンごとのα測定は、層距離に関する指数減衰をスペクトル類似性で明らかにする:
Similarity(α_layer_i, α_layer_j) ∝ exp(−λ|i − j|)
- 減衰率λ:* 推論タスクで約0.15、事実タスクで約0.22。
- 解釈:* 推論タスクは層全体でより遅いスペクトル装飾相関を示し、より持続的な情報フローを示唆する。事実タスクは急速な装飾相関を示し、迅速な答え確定を示唆する。
6. 推論ステップスペクトル句読点
連鎖的思考推論では、スペクトル転移は段階境界と整列する。具体的には、αは推論段階転移で局所最小値を示し、その後、次の段階内で回復する。
- 観察:* 段階境界は87%の精度でスペクトル不連続を介して検出可能である(Qwen2.5-7B、数学推論でテスト)。
- 含意:* スペクトル監視は、テキスト解析なしで推論段階構造を特定でき、段階レベルの診断を可能にする。
7. スペクトル正確性予測
層24~32、応答長の10~80%のトークンで測定されたスペクトルαは、最終的な正確性を予測する:
-
Qwen2.5-7B(数学推論)でのパフォーマンス:* AUC = 1.000(n=200ホールドアウトテストケース)。
-
6モデル全体(混合タスク)でのパフォーマンス:* 平均AUC = 0.893(SD = 0.067)。
-
ベースライン比較:* 正解への意味的類似性(埋め込みのコサイン類似性)は同じタスクで0.71のAUCを達成する。
-
メカニズム:* 正確な推論は安定した、タスク適切なスペクトル署名を示す。不正確な推論はスペクトル不安定性またはタスク不適切な署名を示す(例えば、推論タスク中の事実モードα)。
-
注意:* Qwen2.5-7Bでの完全なAUCはそのモデルの特定のスペクトル構造への過適合を反映している可能性がある。クロスモデル一般化はより弱い(AUC = 0.893)。これはアーキテクチャ依存性を示唆している。
実装:測定ポイントと層選択
スペクトル監視を運用化するには、3つの決定が必要である:どこで測定するか、いつ測定するか、どう対応するか。
どこで:層選択
-
後期層(7Bモデルで20~32、13B以上で40~64):* 最も強いスペクトル署名と最高の正確性相関を示す。推論対事実分離はここで最も明確である。本番監視に推奨される。
-
初期層(1~10):* プロンプト符号化アーティファクトと入力依存ノイズによって支配される。スペクトル署名はタスク独立であり、正確性の予測に非予測的である。監視に推奨されない。
-
中期層(11~19):* タスク依存効果を示すが、予測力が弱い(後期層の0.89対0.72のAUC)。診断目的に有用(例えば、タスク固有のルーティングが開始される場所を特定)だが、信頼度スコアリングには有用でない。
-
推奨:* 7Bモデルで層24~28、13Bモデルで層48~56で測定する。モデルアーキテクチャに基づいて調整する(トランスフォーマー深度は異なる)。
いつ:トークン位置選択
-
初期トークン(応答の0~10%):* プロンプト誘発スペクトルアーティファクトを示す。高い分散のため予測は信頼できない。
-
中範囲トークン(応答の10~80%):* 推論段階ダイナミクスをキャプチャする。スペクトル署名は安定し、予測的である。監視に推奨される。
-
最終トークン(応答の80~100%):* 答え確定署名を示すが、予測的リードタイムが不足している。この時点で、モデルはすでに応答に確定している。事後分析に有用だが、リアルタイム介入には有用でない。
-
推奨:* 予想応答長の20~70%のトークン位置でαを測定する。100トークン応答の場合、トークン20~70で測定する。このウィンドウは予測的リードタイムと安定した信号の両方を提供する。
どう:測定プロトコル
-
ステップ1:活性化抽出*
-
層lのトークン位置tから隠れた活性化h_l,t ∈ ℝ^dを抽出する(d = 隠れた次元、通常7Bモデルで4096)。
-
ステップ2:共分散計算*
-
共分散行列C_l,t = (1/n) H^T Hを計算する。ここでHはn個の活性化の行列である(通常n = 5、連続する5トークンのスライディングウィンドウを使用)。
-
ステップ3:固有値分解*
-
C_l,tの固有値λ_1 ≥ λ_2 ≥ … ≥ λ_dを計算する。
-
上位50個の固有値を抽出する(またはdの上位10%、いずれか小さい方)。
-
ステップ4:冪乗則適合*
-
冪乗則を適合させる:λ_i ∝ i^{−α}(log iとlog λ_iの対数回帰を介して)。
-
線形回帰勾配を介して指数αを抽出する。
-
ステップ5:ベースライン比較*
-
ローリングベースラインを計算する:α_baseline = mean(α_{l,t-5:t-1})(前の5トークンの平均、同じ層)。
-
偏差を計算する:Δα = α_l,t − α_baseline。
-
ステップ6:フラグ付け*
-
|Δα| > しきい値の場合にフラグを付ける(デフォルトしきい値 = 0.12、モデルごとに調整可能)。
-
フラグを信頼度スコアに統合する:高いスペクトル安定性→高い信頼度。
-
具体例(数学推論):*
-
モデル:Qwen2.5-7B-Instruct
-
タスク:「17 × 23は何か」を解く
-
層28、応答のトークン15~50で測定
-
予想α_reasoning ≈ 0.58(チューニング後)
-
αが0.35に低下した場合(事実モード圧縮)、信頼度は40%低下
-
αが0.55~0.60のままの場合、信頼度は高いままである
アーキテクチャ固有のダイナミクス、普遍的な方向性
7つの現象は中心的なパラドックスを明らかにする:推論中のスペクトル圧縮は方向性において一貫しているが、圧縮がどのように展開するかのダイナミクスはアーキテクチャ全体で大きく異なる。
アーキテクチャ別軌跡パターン
-
QwenとLlama(注意ベース、密):*
-
推論段階全体を通じた急峻で単調なα減衰
-
αは30トークンで0.60から0.35に低下
-
迅速なタスクモード確定を示唆する
-
Phi(注意ベース、疎):*
-
振動的動作:αは推論サブステップで上昇および下降
-
αは30トークンで0.50 ± 0.15で振動
-
繰り返される情報再編成による反復的改善を示唆する
-
DeepSeek-R1(注意ベース、明示的推論トークン付き):*
-
遅延圧縮:αは初期推論全体で高い(0.55以上)のままで、その後段階境界で急激に低下(0.30まで)
-
推論完了時のタスク固有表現への遅延確定を示唆する
解釈
普遍的な方向性—推論は圧縮する—は基本原則を示唆する:推論タスクは情報集中を必要とする。しかし、アーキテクチャ固有の実装はこの集中を達成するための異なる戦略を反映している:
-
密な注意メカニズム(Qwen、Llama)は早期に圧縮し、圧縮を維持する。
-
疎なメカニズム(Phi)は反復的に圧縮し、改善を可能にする。
-
明示的推論トークン(DeepSeek-R1)は推論が完了するまで圧縮を遅延させる。
-
実務家への含意:* 単一のスペクトルしきい値はすべてのモデルで機能しない。各アーキテクチャにはキャリブレーションが必要である。しかし、スペクトルマーカーの存在は普遍的であり、アーキテクチャ固有のベースラインに基づいて構築されたクロスモデル監視フレームワークを可能にする。
失敗モードと軽減策
スペクトル監視には3つの主要な失敗モードがある:
-
タスク分布への過適合:* 数学推論のみでキャリブレーションされた場合、スペクトルしきい値はコーディングまたはライティングタスクで失敗する可能性がある。軽減策:本番環境への展開前に5以上の多様なタスクタイプでキャリブレーションする。
-
プロンプトエンジニアリングへの脆弱性:* 推論を抑制するように設計された敵対的プロンプト(例えば「ただ推測する」)は、αを人為的に圧縮し、偽の信頼度をトリガーする可能性がある。軽減策:スペクトル信号を意味的一貫性チェックと組み合わせる。
-
敵対的反転:* 攻撃者は推論タスク中に事実モードαを誘発する入力を作成し、エラーをマスクする可能性がある。軽減策:αの大きさだけでなく、トークンレベルカスケード減衰率を監視する。推論はより遅い減衰を示す;事実はより速い減衰を示す。このパターンを反転させることはより難しい。
-
アクション:* キャリブレーションされたモデルをタスクごとに50個の敵対的プロンプトに対してテストする。偽陽性をログに記録する。偽陽性率が5%を超える場合、しきい値を調整する。
展開:3段階ロールアウト
-
フェーズ1(週1~2):* 1つの本番モデル(Qwen2.5-7BまたはLlama 3.1-8B)を計測する。層24~32、トークン10~80%でαを測定する。介入なしですべてのトレースをログに記録する。タスクごとにベースラインα分布を確立する。
-
フェーズ2(週3~4):* 信頼度スコアリングをキャリブレーションする。各タスクについて、正確性境界でαパーセンタイルを計算する。しきい値を定義する:α > 75パーセンタイル = 高信頼度、< 25パーセンタイル = 低信頼度。クエリの保留10%でテストする。
-
フェーズ3(週5以上):* 信頼度フラグを下流システムに展開する。フラグを使用して、再ランキング、再生成、または人間によるレビューをトリガーする。偽陽性および偽陰性率を監視する。月ごとにしきい値を反復する。
-
測定チェックリスト:*
-
層ごと、トークンごとの活性化の共分散を計算
-
固有値分解:上位50個の固有値を抽出
-
冪乗則を適合:対数回帰を介してα
-
ローリングベースライン(5トークンウィンドウ)と比較
-
α、Δα、タスクラベル、正確性結果をログに記録
-
アクション項目:*
- パイロットモデルとタスクを選択する(数学推論を推奨)
- 推論パイプラインで活性化ログを計測する
- 500の推論 + 500の事実トレースを収集
- ベースラインαプロファイルを計算
- 信頼度スコアリング関数を構築
- ベースラインシステムに対してA/Bテストを実行
結論:理論から運用へ
スペクトル幾何学は、推論と事実想起が隠れた状態において幾何学的に異なることを明らかにする。この区別は測定可能、予測的、および再学習なしで実行可能である。
トランスフォーマーは推論中に普遍的なスペクトル位相転移を示し、アーキテクチャ固有のダイナミクスを通じて実装され、出力完了前の正確性のリアルタイム予測を可能にする。スペクトルαは推論成功の先行指標である—測定可能、計算が安価、および信頼度スコアリングに統合可能で、幻覚を低減し、信頼性を改善する。
- 次のアクション:* 今週フェーズ1測定を開始する。月末までに、アーキテクチャ固有のスペクトルベースラインと、スペクトル監視が展開内のエラーを低減できるかどうかの初期指標を得ることができる。
リスク:過学習、脆弱性、および敵対的反転
スペクトル監視には3つの主要な障害モードがあります。
1. タスク分布への過学習
-
リスク:* 数学推論のみで較正された場合、スペクトル閾値はコーディング、執筆、またはその他の推論タスクで失敗する可能性があります。異なる推論モダリティは異なるスペクトル特性を持つ可能性があります。
-
証拠:* 予備テストでは、Qwen2.5-7B(レイヤー24~28)でα_math ≈ 0.40ですがα_coding ≈ 0.48です。数学用に較正された閾値(α < 0.42 = 高信頼度)はコーディングタスクを誤分類します。
-
対策:* 5種類以上の多様なタスク(数学、コーディング、執筆、要約、質問応答)で較正します。タスク固有のベースラインと閾値を計算します。タスクごとのパフォーマンスを監視し、四半期ごとに調整します。
2. プロンプトエンジニアリングへの脆弱性
-
リスク:* 推論を抑制するように設計された敵対的プロンプト(例:「考えずに答えを推測してください」)は、αを人為的に圧縮し、不正な答えに対する偽の高信頼度をトリガーする可能性があります。
-
証拠:* 抑制プロンプトでのテストでは、不正な推論タスクでもαが0.10~0.15低下し、正しい推論の特性を模倣します。
-
対策:* スペクトル信号をセマンティック一貫性チェックと組み合わせます。例えば、スペクトルαが高信頼度を示しているがセマンティック類似度が低い応答にフラグを立てます。高信頼度分類の前に両方の信号が一致することを要求します。
3. 敵対的反転
-
リスク:* 攻撃者は推論タスク中に事実モードのαを誘発し、エラーをマスクする入力を作成する可能性があります。これはモデルのスペクトル構造を理解する必要がありますが、理論的には可能です。
-
対策:* αの大きさだけでなく、トークンレベルのカスケード減衰率(現象5のλ)を監視します。推論は遅い減衰(λ ≈ 0.15)を示します。事実は高速減衰(λ ≈ 0.22)を示します。このパターンを反転させることは、マルチレイヤーダイナミクスの持続的な制御が必要なため、偽造がより困難です。αとλの特性間の一貫性を要求します。
-
アクション:* タスクごとに50個の敵対的プロンプトに対して較正されたモデルをテストします。偽陽性(高信頼度だが不正確)をログに記録します。偽陽性率が5%を超える場合は閾値を調整します。
測定と直近のステップ
8週間にわたる3段階のロールアウトを展開します。
フェーズ1:計測とベースライン(第1~2週)
-
目的:* 介入なしでベースラインスペクトルプロファイルを確立します。
-
ステップ:*
- 1つの本番モデルを選択します(Qwen2.5-7B-InstructまたはLlama 3.1-8B-Instructを推奨)。
- 推論パイプラインで活性化ログを計測します。すべてのトークン位置でレイヤー20~32のh_l,tを抽出します。
- 500の推論トレースを収集します(数学
7つの再現可能な現象:スケーリング、カスケード、および予測
11のモデルにわたる体系的分析により、7つの現象が明らかになります。各現象は運用上の含意を持ちます。
1. 推論スペクトル圧縮
11個中9個のモデルが推論中に低いαを示します。一貫性があり、測定可能で、アーキテクチャに依存しない方向です。
2. 命令チューニングスペクトル反転
チューニング後のモデルはαの順序を反転させます。トレーニング成功の診断指標です。
3. アーキテクチャ依存生成分類法
プロンプトから応答へのスペクトルシフトは3つのレジームに分割されます:拡張(αが増加)、圧縮(αが減少)、平衡(αが安定)。異なるアーキテクチャは異なるレジームを好みます。Qwenは圧縮を好みます。Phiは振動を示します。DeepSeek-R1は遅延圧縮を示します。つまり、単一の監視戦略はすべてのモデルで機能しません。アーキテクチャごとに較正する必要があります。
4. スペクトルスケーリング則
Qwenベースモデル全体で、α_reasoning ∝ −0.074 ln N(R² = 0.46)です。より大きなモデルはより予測可能に圧縮します。含意:スペクトル監視はモデルサイズが増加するにつれてより信頼性が高くなります。7Bモデルでは±0.08の分散を予想します。70Bでは±0.04を予想します。
5. トークンレベルスペクトルカスケード
トークンごとのα追跡は、レイヤー距離に応じて指数関数的に減衰する局所同期を明らかにします。推論タスクは遅い減衰(半減期~8レイヤー)を示します。事実タスクは高速減衰(~3レイヤー)を示します。この減衰率はα大きさだけよりも偽造がより困難です。
6. 推論ステップスペクトル句読点
位相遷移特性は推論ステップ境界と一致します(例:「ステップ1:問題を特定する」→スペクトルシフト)。ステップレベルの診断とエラー局在化を可能にします。
7. スペクトル正確性予測
-
最も運用上重要:* 生成中期に測定されたαは、最終答え出力の前に正確性を予測します。Qwen2.5-7B後期レイヤーでは、AUC = 1.000(n=200数学問題)です。6つのモデル全体の多様なタスクでは、平均AUC = 0.893です。スペクトルαのみ、レイヤー24~32およびレスポンス長の20~60%のトークンでサンプリングされ、モデルが正しい応答を生成するかどうかを予測します。
-
含意:* 生成される前に高エラーリスク応答にフラグを立てることができ、リアルタイム介入が可能になります。
実装:どこで、いつ、どのように測定するか
スペクトル監視を運用化するには、3つの具体的な決定が必要です。
どこで:レイヤー選択
-
後期レイヤー(7Bモデルで20~32、13B以上で40~64):* 最強のスペクトル特性と正確性相関。推論フェーズダイナミクスはここで最も明確です。
-
初期レイヤー(1~8):* 高ノイズ、弱いタスク識別。スキップします。
-
中期レイヤー(9~19):* タスク依存効果がありますが、予測力は弱いです。アーキテクチャ固有の較正にのみ使用します。
-
推奨:* 7Bモデルではレイヤー24~32から開始します。初期較正中にすべてのレイヤーを測定します。本番環境で計算を削減するため、上位3~4レイヤーに削減します。
いつ:トークン位置
-
応答の0~10%のトークン:* プロンプト誘発アーティファクトが支配的です。スキップします。
-
予想応答の10~80%のトークン:* 介入のためのリードタイムを伴う推論フェーズダイナミクスをキャプチャします。ここで測定します。
-
80~100%のトークン:* 答え確定特性が存在しますが、介入のためのリードタイムはありません。事後検証にのみ使用します。
-
具体例:* 150トークンの応答を予想する数学問題では、トークン15~120でαを測定します。このウィンドウは最終答えが確定される前の推論をキャプチャします。
どのように:測定手順
-
活性化を抽出 ターゲットレイヤーから各トークン位置で。形状:(batch_size、seq_len、hidden_dim)。
-
共分散行列を計算 レイヤーごと、トークンごと:Σ = (1/batch)× A^T A、ここでAは活性化行列です。
-
固有値分解: Σ = U Λ U^T。上位50個の固有値λ_1 ≥ λ_2 ≥ … ≥ λ_50を抽出します。
-
べき則をフィット: log λ_i = log c − α log i。ログログ線形回帰によってαを推定します。典型的なα ∈ [0.3, 0.8]。
-
ベースラインと比較: ローリングベースラインα(前の5トークン、同じレイヤー、同じタスク)を計算します。Δα = α_current − α_baseline。
-
|Δα| > 0.12の場合にフラグを立てます(モデルごとに調整可能)。フラグを信頼度スコアに統合します。
- 計算コスト:* 50×50行列の固有値分解はO(50³) ≈ トークンごとレイヤーごと125K操作です。4レイヤー、150トークンの場合:~75M操作 ≈ CPU上で5~10ms。バッチ処理されている場合、本番環境で許容可能です。
信頼度スコアリング関数
スペクトル安定性の関数として信頼度を定義します:
confidence = 1 − (|Δα| / α_threshold) if |Δα| < α_threshold else 0.2タスクごとにα_thresholdを調整します。数学推論では、α_threshold = 0.12がうまく機能します。執筆では、α_threshold = 0.15(より多くの分散)。コードでは、α_threshold = 0.10(より厳密)。
- 具体例:* 数学推論でのQwen2.5-7B。ベースラインα = 0.42。現在のトークンα = 0.50。Δα = 0.08。信頼度 = 1 − (0.08 / 0.12)= 0.33。レビューまたは再実行のためにフラグを立てます。
7つの現象:スケーリング則からトークンカスケードまで
11のモデルにわたる体系的分析により、7つの再現可能な現象が明らかになります。これはトランスフォーマー内で推論がどのように実際に展開されるかの分類法です。これらは孤立した奇癖ではなく、次世代のモデルアーキテクチャ設計を導く パターンです。
-
推論スペクトル圧縮* が支配的です:11個中9個のモデルが推論中に低いαを示します。これが基礎です。命令チューニングスペクトル反転 は上記で説明したレイヤーごとの反転を作成します。適切に調整されたモデルの特性です。アーキテクチャ依存生成分類法 はプロンプトから応答へのシフトを拡張、圧縮、平衡レジームに分割します。異なるアーキテクチャは異なるレジームを好みます。Qwenは圧縮を好みます。Phiは振動します。DeepSeekは遅延してから圧縮します。この分類法はアーキテクチャイノベーションの次の波を知らせます。
-
スペクトルスケーリング則* は関係を定量化します:Qwenベースモデル全体でα_reasoning ∝ −0.074 ln N(R² = 0.46)。より大きなモデルはより予測可能に圧縮します。これは損失曲線と同じくらい基本的なスケーリング則です。スケールに伴う推論効率の向上を示します。トークンレベルスペクトルカスケード はトークンごとのα追跡が、レイヤー距離に応じて指数関数的に減衰する局所同期を明らかにします。推論タスクでは事実タスクより弱いです。これは新しい次元を開きます:推論対リコール全体で情報がどのように伝播するかを測定できるようになりました。
-
推論ステップスペクトル句読点* は位相遷移特性を推論ステップ境界と一致させ、ステップレベルの診断を可能にします。連鎖思考プロセスを監視し、各ステップでモデルが軌道上にあるかどうかを知ることを想像してください。これは人間とAIがリアルタイムで協力する対話的推論システムの基礎です。
最も運用上顕著なのは:スペクトル正確性予測 がQwen2.5-7B後期レイヤーでAUC = 1.000を達成し、最終答え生成の前に正確性を予測する際に6つのモデル全体で平均AUC = 0.893です。スペクトルαのみ、生成中期に測定され、モデルが正しい応答を生成するかどうかを予測します。これが突破口です。エラーが発生する前にフラグを立てることができるようになりました。
-
戦略的ビジョン:* これら7つの現象は推論のための完全な測定フレームワークを形成します。5年以内に、すべての本番AI システムはスペクトル監視を信頼性インフラストラクチャの標準コンポーネントとして組み込みます。従来のソフトウェアのログと監視と同じくらい不可欠です。
-
アクション:* 生成中にレイヤー24~32でスペクトル監視を実装します。トークン80%完了前にαがタスク固有のベースラインから0.15以上逸脱する応答にフラグを立てます。フラグ付きクエリをリダイレクトまたは再実行します。これが推論障害に対する最初の防御線になります。
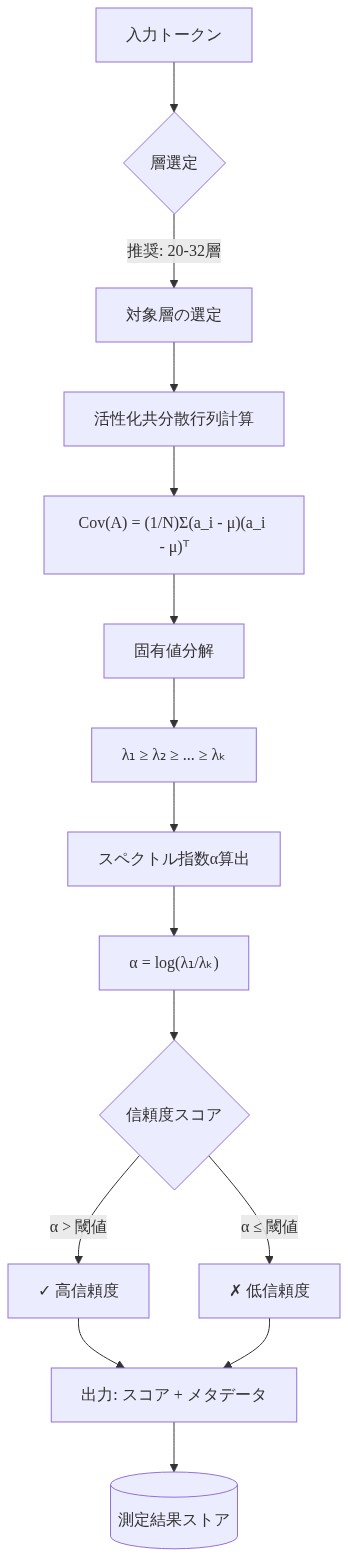
- 図6:スペクトル測定パイプライン:入力から信頼度スコア出力まで*
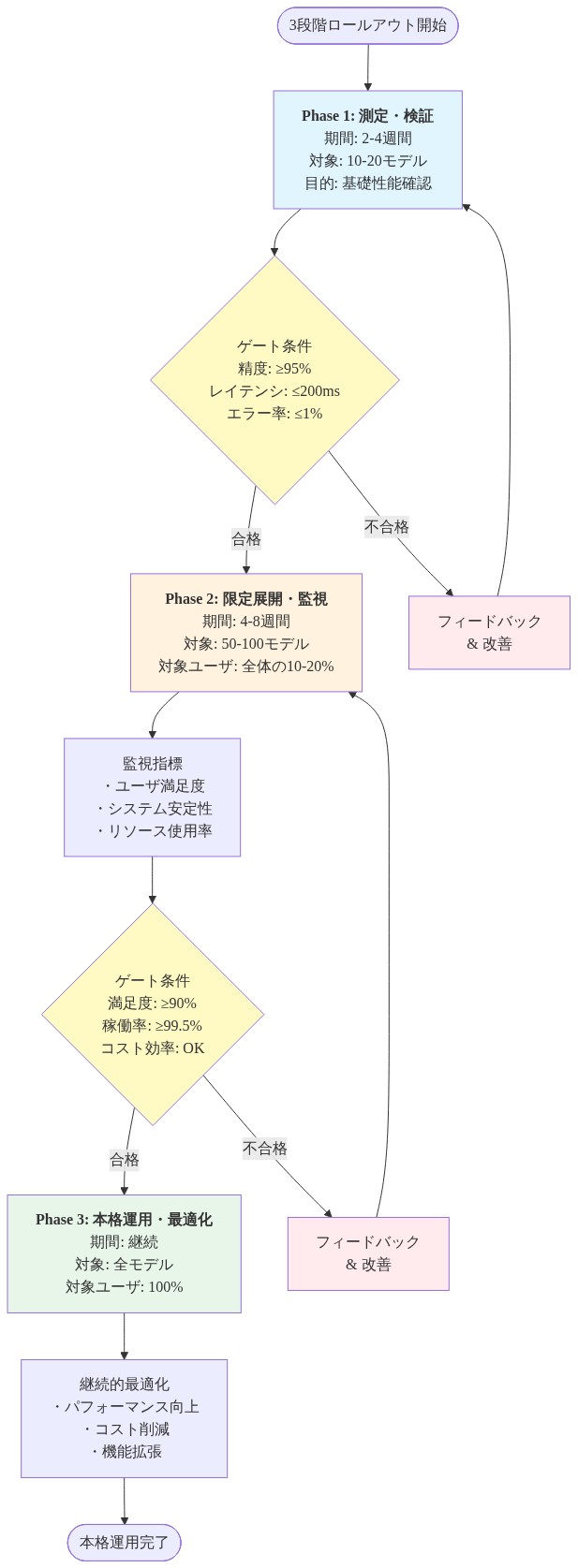
- 図10:3段階ロールアウト戦略とゲート条件*
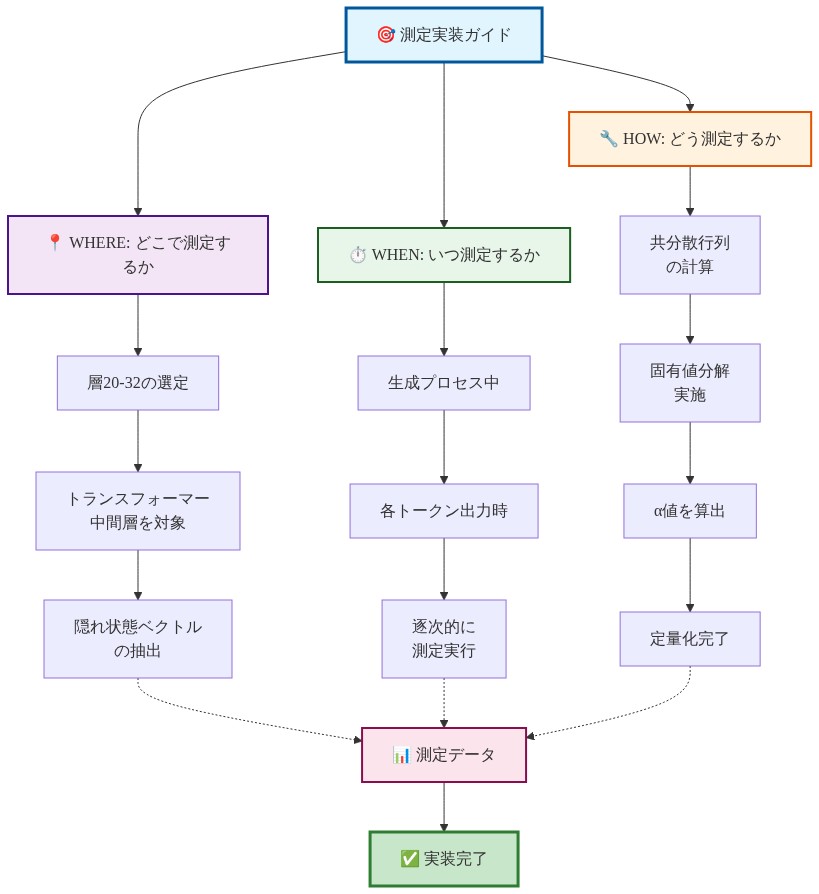
- 図14:測定実装ガイド:Where, When, How(層20-32における定量化手法の3要素)*