
AIで最も誤解されているグラフ
スケーリング則グラフの理解
-
主張*:AI分野で最も誤解されているグラフはスケーリング則曲線である。モデルサイズ、訓練データ量、タスク損失の間の経験的関係を示すこのグラフは、普遍的な予測モデルとして解釈されることが多いが、実際には特定の限定された実験条件下でのみ有効な条件付きトレンドを表している。
-
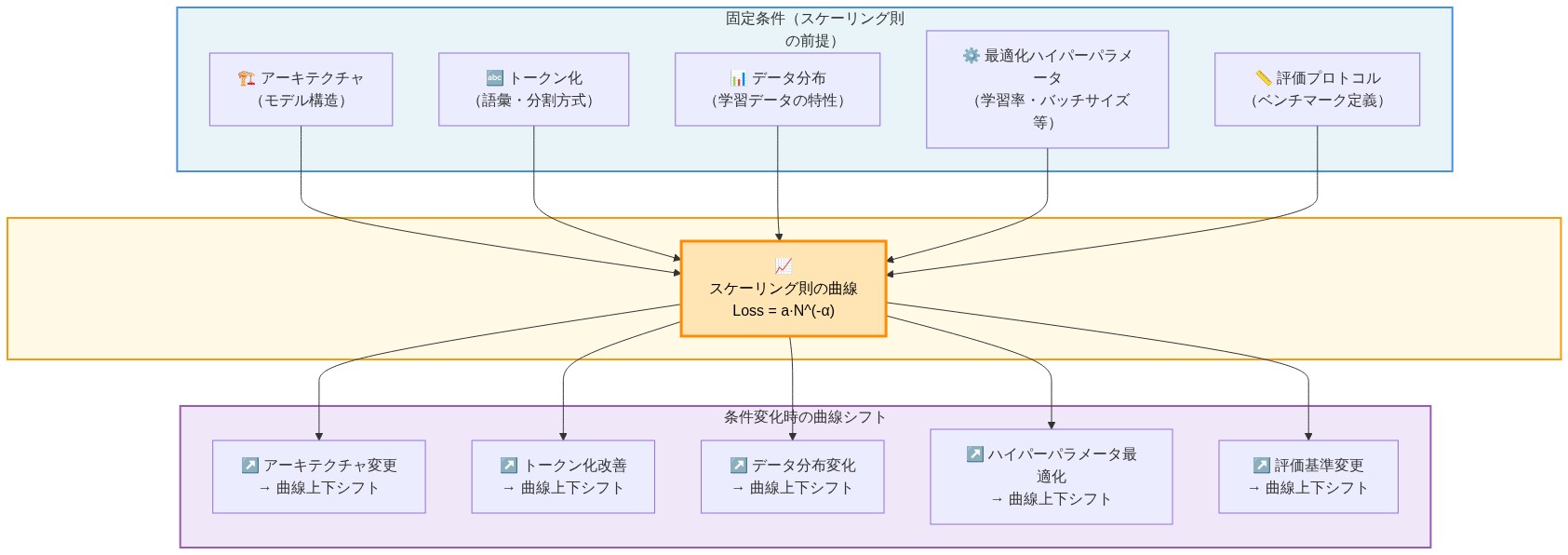
定義的前提*:Kaplan et al. (2020)とHoffmann et al. (2022)で形式化されたスケーリング則は、べき乗則関係を記述する。Loss(N, D) ≈ aN^(-α) + bD^(-β) + εという式において、Nはパラメータ数、Dは訓練トークン数、α、βは経験的に推定された指数である。この関係は固定されたアーキテクチャ、トークン化スキーム、データ分布、最適化ハイパーパラメータ、評価プロトコルという条件下でのみ成立する。曲線は普遍的法則ではなく、これらの条件のスナップショットに過ぎない。
-
根拠*:スケーリング則は、条件を固定した状態でモデルが成長するにつれて損失が予測可能に減少することを実証する統制された経験的研究から生まれた。しかし、この予測可能性は条件付きである。トークン化方法、データソースまたは品質、アーキテクチャ要素(注意機構、正規化)、学習率スケジュール、評価ベンチマークといった物質的条件が変わると、基礎となる曲線はシフトする。指数αとβそのものが変わる可能性もある。チームは歴史的スケーリング曲線をしばしば不変の原理として扱うが、実際には特定の実験設定に結びついた経験的観察として見るべきだろう。
-
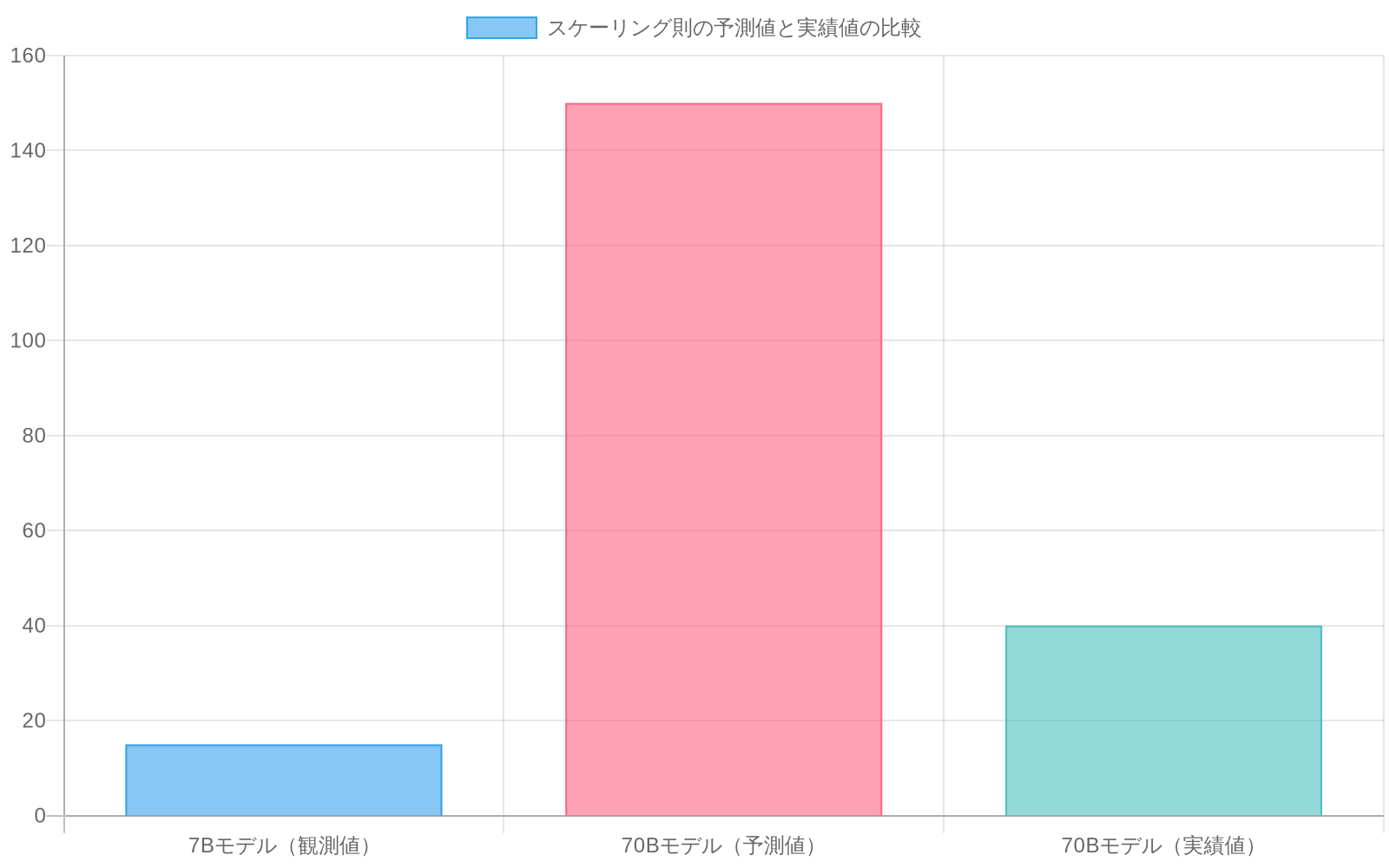
具体例*:あるチームが自社の独占的データセット上で7Bパラメータモデルを訓練し、データ量を一定に保ちながらパラメータを2倍にするごとに15%のパフォーマンス向上(ベンチマーク精度で測定)を観察した。彼らは70Bモデルが約150%の累積利益をもたらすと予測した。実際には、70Bモデルは40%の利益しか達成しなかった。事後分析により、元の曲線の仮定から2つの逸脱が明らかになった。(1)彼らのデータセットはスケール時に品質低下を含んでいた(後から追加されたデータはノイズ比率が低かった)、(2)学習率スケジュールを調整しなかったため、より高いパラメータ数で最適化が不適切になった。グラフの予測が失敗したのはスケーリング則が無効だからではなく、動作条件が元の曲線の暗黙的仮定から逸脱したからである。
-
実行可能な含意*:リソース配分のためにスケーリング曲線に依存する前に、それが導出された正確な条件を明示的に文書化すること。(1)アーキテクチャタイプとバージョン、(2)データ構成とソース、(3)訓練期間とトークン予算、(4)最適化ハイパーパラメータ(学習率スケジュール、バッチサイズ、オプティマイザ)、(5)評価ベンチマークとプロトコル。新しいプロジェクトごとに曲線のシフトの可能性として扱うこと。小規模検証実験(1B~3Bパラメータ)をインフラとデータ上で実施し、曲線の形状がセットアップに適用されるかどうかを確認する。歴史的曲線は方向性のガイダンスのみに使用し、正確な予測やリソースコミットメントには使用しないこと。
- 図4:具体例—予測値と実績値の乖離(7Bから70Bへのスケールアップ)(出典:記事内の具体例)*
- 図3:スケーリング則の有効条件と条件変化による曲線シフト*
フロンティアモデルのリリースサイクルと曲線の再解釈
-
主張*:フロンティアモデルのリリースのたびに、コミュニティは既存のスケーリンググラフを再解釈し、モデルの訓練方法論と基礎となるスケーリング関係について誤った推論を生み出すことが多い。
-
定義的前提*:「フロンティアモデル」とは、主要ラボ(OpenAI、Google DeepMind、Anthropic、Meta)がリリースした最先端の大規模言語モデルを指す。公開発表には通常、パラメータ数、ベンチマークスコア、時折アーキテクチャまたは訓練技術の概要が含まれる。詳細な訓練データ構成、ハイパーパラメータ設定、アブレーション研究はめったに開示されない。
-
根拠*:フロンティアラボが新しいモデルを発表すると、コミュニティはすぐにスケーリング則の含意を抽出しようとする。しかし、発表データは限定的で厳選されている。チームはその後、新しいモデルを既存のスケーリング曲線に遡及的に適合させ、観察されたパフォーマンスを生み出した訓練アプローチについての事後的物語を作成する。モデルは新規の訓練技術(カリキュラム学習、合成データ拡張、多段階訓練)、異なるデータ混合(ウェブテキスト、コード、指示データの比率)、またはアーキテクチャ革新(新規の注意パターン、層正規化バリアント)を採用しているかもしれず、これらはスケーリング関係を根本的に変える。これらの変更はいずれも公開ベンチマーク数値には見えないが、すべて基礎となる損失パラメータ関係をシフトさせる。
-
具体例*:フロンティアラボが名目上類似したパラメータスケールで前世代より30%優れたパフォーマンスを示すモデルをリリースした。コミュニティの観察者はスケーリング則の指数が加速したと結論づけ、将来のスケーリングがより速い改善をもたらすことを示唆していると考えた。その後の技術分析(モデルカード詳細と研究論文を通じて)は3つの交絡因子を明らかにした。(1)トークナイザーの再設計により有効トークン数が12%削減された、(2)合成データ拡張により有効訓練データ量が25%増加した、(3)新規の注意機構がサンプル効率を改善した。これらのいずれもベンチマーク比較だけでは見えない。スケーリングの見かけ上の加速は実際には、トークン化効率、データ拡張、アーキテクチャ改善の組み合わせであり、基本的なスケーリング指数の変化ではなかった。
-
実行可能な含意*:フロンティアリリースを分析する際、観察可能な事実と推論の間に厳密な分離を維持すること。検証可能なデータのみを文書化する。公開されたベンチマークスコア、開示されたパラメータ数、明示的に発表された技術。ベンチマーク結果だけから訓練データサイズ、アーキテクチャ選択、またはハイパーパラメータを推論することに抵抗する。代わりに、リリースが自分自身のスケーリング仮定を実質的に変えるかどうかに焦点を当てる。技術が公開されている場合(例えば、新しいトークナイザーまたは訓練方法)、インフラ上で統制された実験を実行して、それらの技術が発表されたパフォーマンス利益をコンテキストで複製するかどうかをテストする。公開ベンチマークでのパフォーマンス利益がタスクまたはデータ分布に転送されると仮定しないこと。
実装と運用パターン
-
主張*:チームはスケーリング則を研究段階の研究ツールではなく展開ガイダンスとして扱うことで体系的に誤用している。スケーリング曲線は訓練段階の損失削減を記述する。推論コスト、レイテンシ、実世界の有用性、またはエンドツーエンドのシステムパフォーマンスを直接予測しない。
-
定義的前提*:スケーリング則は訓練条件下でモデルサイズとタスク損失(または精度)の関係を予測する。これは能力(モデルが学習できるもの)に関する記述であり、運用可能性(モデルが効率的に展開できるかどうか)に関する記述ではない。推論コスト、レイテンシ、実世界の有用性はハードウェア制約、サービング基盤、量子化、蒸留、スケーリング曲線に直交するタスク固有の要因に依存する。
-
根拠*:スケーリング則はより大きなモデルがベンチマーク上でより低い損失を達成することを予測する。これは訓練段階の記述である。そのモデルが利用可能なハードウェアに適合するか、レイテンシサービスレベルアグリーメント(SLA)を満たすか、またはエンドユーザーが好むアウトプットを生成するかを予測しない。より低い損失とより良い実世界パフォーマンスの間のギャップは数学的ではなく運用的かつ経済的である。より大きなモデルはしばしば量子化(精度低下)、蒸留(より小さなモデルへの圧縮)、または専門的なサービング基盤(テンソル並列化、バッチ最適化)を必要とし、これらは予測された利益を無効にするか新しい制約を導入する。さらに、より大きなモデルは異なる障害モード、異なるプロンプト戦略、または異なるレイテンシ分布を持つアウトプットを示す可能性があり、これらの要因は損失曲線に捉えられない。
-
具体例*:あるチームはスケーリング曲線に基づいて13Bから70Bパラメータにスケールアップし、ベンチマークで25%の精度向上を予測した。より大きなモデルは実際に22%精度を改善し、スケーリング則を検証した。しかし、運用上の制約が生じた。(1)70Bモデルは4倍のGPUメモリを必要とし、より高価なハードウェアへの移行を強制した、(2)推論レイテンシは2倍になった(トークンあたり200msから400ms)、250ms SLAに違反した、(3)メモリとコンピュート要件により、サービングコストが3倍になった。運用上のオーバーヘッドは精度向上の価値を消費した。コスト便益分析により、13Bモデルはプロンプトエンジニアリングと検索拡張により70Bモデルの精度の95%をコストの30%で達成し、レイテンシ要件を満たしたことが明らかになった。
-
実行可能な含意*:スケーリング則と並行してコスト当たり能力曲線を構築すること。各モデルサイズについて測定する。(1)訓練時間とコンピュートコスト、(2)推論レイテンシ(p50、p95、p99パーセンタイル)、(3)メモリフットプリント(GPU/CPU)、(4)推論当たりのエンドツーエンドサービングコスト。パラメータ数ではなく総コスト(訓練+サービング)に対する精度またはタスク固有のパフォーマンス向上をプロット。パレート最適境界を特定する。制約に応じて、ドル当たり、ミリ秒当たり、またはワット当たりの能力を最大化するモデルサイズ。この最適境界はしばしばフロンティアラボスケールをはるかに下回り、より良い最適化を持つより小さなモデルを支持するかもしれない。

- 図7:ベンチマーク改善から実世界価値への変換プロセス*
測定とタスク固有の検証
-
主張*:スケーリング則はアプリケーションにとって重要なタスクに対して測定される場合にのみ意味がある。ベンチマーク損失は代理指標である。本番環境の有用性とタスク固有のパフォーマンスから頻繁に逸脱する。
-
定義的前提*:ベンチマーク損失(またはMMLA、HellaSwag、GSM8Kなどの標準化されたタスクの精度)は一般的能力の代理である。本番環境の有用性は展開における実際のエンドユーザータスクでのパフォーマンスを指す。タスク固有のパフォーマンスは特定のドメインまたはユースケースの精度または品質である。
-
根拠*:スケーリング曲線は通常、モデル比較用に設計された標準化されたベンチマークを使用して導出される。これらのベンチマークは相対的なランキングに有用だが、実際のユースケースのタスク分布、評価基準、または成功指標を反映しないかもしれない。複数選択問題でよくスケールするモデルは、長形式の推論、コード生成、またはドメイン固有のタスクでは不十分にスケールするかもしれない。実務者は、モデルが公開ベンチマークでよくスケールする場合、独占的タスクでも同じようにスケールすると仮定することが多い。これはドメイン語彙、推論深度、コンテキスト長要件などのタスク固有の要因を無視する危険な仮定である。
-
具体例*:カスタマーサービスチームは公開研究からスケーリング曲線を採用し、ベンチマーク改善に基づいて34Bモデルが13Bモデルより40%多くの複雑なクエリを処理すると予測した。実際のカスタマークエリを使用した内部評価では、改善は12%のみだった。根本原因分析により、公開ベンチマーク(MMLU、HellaSwag)は一般知識と推論を測定したが、カスタマークエリはニュアンスに富んだドメイン理解、マルチターンコンテキスト保持、会社固有のポリシーへの精通を必要としたことが明らかになった。タスク構造と評価基準がベンチマークから逸脱したため、スケーリング関係はそのタスクに対して根本的に異なっていた。
-
実行可能な含意*:大規模訓練にコミットする前に、自分自身のデータとタスク上で独自のスケーリング曲線を測定すること。測定段階を実施する。(1)本番タスクから代表的なサンプルを選択する(最小500~1000例)、(2)複数のスケール(3B、7B、13B、34Bパラメータ)でモデルを訓練する同一のデータとハイパーパラメータを使用して、(3)本番タスク上で実際の成功指標を使用して評価する、(4)結果の曲線をプロット。公開ベンチマークと比較。指数またはインターセプトで大きく逸脱する場合(>15%差)、スケーリング仮定は公開研究と異なる。計画に公開曲線ではなく自分の曲線を使用する。大規模訓練実行にコミットする前に、この測定段階に2~3週間を割り当てる。
- 図10:タスク固有スケーリングを競争優位性とするプロセス(測定・検証フレームワーク)*
リスクと軽減戦略
-
主張*:スケーリング則への過度な依存は2つの異なるリスクを生じさせる。(1)より小さなモデルが優れた訓練と最適化で十分な場合にスケールに過度投資する、(2)データ品質、タスク設計、訓練方法論改善への投資を過少にする。
-
根拠*:スケーリング則はより多くのパラメータが常にパフォーマンスを改善することを示唆し、これは集計では真だが、データ品質、タスク定式化、訓練方法論がしばしばより高い投資収益率をもたらすという事実を隠す。200万ドルを100Bパラメータモデルの訓練に投資するチームは、13Bモデルに50万ドル、データキュレーション、ドメイン固有の微調整、検索拡張に150万ドルを投資することでより良い結果を達成するかもしれない。スケーリング則はこのトレードオフを捉えない。固定されたデータ品質と訓練実践を仮定するからである。さらに、スケーリング則は通常、汎用ベンチマークで測定される。ドメイン固有の最適化はしばしばスケール単独よりも大きな利益をもたらす。
-
具体例*:2つのチームがカスタマーサポートボットを構築した。チームAはスケーリング則アプローチに従った。公開利用可能なサポートデータと一般的なウェブテキストで70Bパラメータモデルを訓練した。チームBはハイブリッドアプローチを採用した。13Bパラメータモデルを訓練したが、高品質なサポート会話のキュレーション、サポート固有のタスクでの指示チューニング、会社知識ベースにわたる検索拡張に大きく投資した。実際のサポートチケットを使用した評価では、チームBのモデルはチームAのモデルを35%上回った(解決率と顧客満足度で測定)、総コストの1/10で。スケーリング則はチームAが勝つと予測した。データ関連性、タスク固有の最適化、検索拡張を考慮しなかった。
-
実行可能な含意*:スケーリング前に訓練パイプラインを体系的に監査すること。問う。(1)タスクに利用可能な最良のデータを使用しているか。(2)タスク定式化は明確で成功指標とよく整合しているか。(3)指示チューニング、検索拡張、または他の最適化技術を試したか。(4)各最適化の投資収益率を測定したか。最初に小さなモデル(3B~7Bパラメータ)でこれらの実験を実行する。改善がプラトーし、スケーリングが次の最高ROIレバーである場合のみスケール。「スケーリング準備チェックリスト」を確立する。データ品質スコア(例えば、品質基準を満たす例の割合)、タスク明確性(例えば、評価の注釈者間合意)、基本最適化レベル(例えば、指示チューニングが適用されたかどうか)、検索拡張準備。チェックリストが緑色で小規模モデル最適化が枯渇した場合のみスケール。
- 図13:スケーリングトラップからの脱出戦略フロー*
結論:理論から実践へ
AI分野で最も誤解されているグラフが誤解されるのは、研究知見と運用ガイダンスを混同するからである。実務者はスケーリング則を法則ではなく方向性ツールとして扱うべきだろう。
スケーリング則は実験的文脈内で真である。また不完全である。展開制約、タスク特異性、データ品質を考慮しない。グラフは出発点であり、目的地ではない。この区別を内在化するチームはより良い投資決定を下し、コストのかかるスケーリング誤りを回避する。
- 3段階アプローチを採用すること*。(1)基本段階:自分のデータ上で独自のスケーリング曲線を測定する。(2)最適化段階:スケーリング前にデータ品質、タスク設計、訓練を改善する。(3)スケール段階:最適化がプラトーした後のみスケール。曲線を文書化し、四半期ごとに再検討する。新しいモデルをリリースする際、曲線をチームと共有する。法則としてではなく、特定の条件下で機能したもののスナップショットとして。これは機関知識を構築し、繰り返される誤解釈を防ぐ。
結論と制度的実践
-
主張*:AIにおける最も誤解されたグラフが誤解される理由は、特定の条件下で有効な研究知見と、文脈を超えて適用可能な運用指針を混同しているからだ。実務家はスケーリング則を展開やリソース配分の青写真ではなく、方向性を示すツールおよび研究インプットとして扱うべきである。
-
根拠*:スケーリング則は実験的文脈の中では経験的に有効だ。しかし同時に不完全である。展開制約、タスク特異性、データ品質のばらつき、最適化とファインチューニングへのリターンを考慮していない。グラフは調査の出発点であり、意思決定の終着点ではない。この区別を内在化したチームは、より優れたリソース配分決定を下し、高額なスケーリング失敗を回避する。
-
実行可能な含意*:モデル開発に三段階アプローチを採用せよ。(1)ベースライン・測定フェーズ:自社データとタスク上で独自のスケーリング曲線を測定する(2~3週間)。曲線の形状、指数、仮定を文書化する。(2)最適化フェーズ:スケーリング前にデータ品質、タスク設計、訓練方法論を改善する。小規模モデル(3B~7B)で実験を実行し、高ROI最適化を特定する。最適化リターンが平坦化してからのみスケーリングする。(3)スケール段階:最適化が枯渇し、測定曲線がスケーリングが制約条件(コスト、レイテンシ、精度)内で有意なゲインをもたらすことを検証した後にのみスケーリングする。曲線を文書化し、データ、タスク、インフラが変わるたびに四半期ごとに再検討する。チームが新しいモデルをリリースする際、スケーリング曲線をステークホルダーと共有せよ。法則としてではなく、特定の条件下で機能したもののスナップショットとして。これは制度的知識を構築し、繰り返される誤解を防ぎ、将来の決定を仮定ではなく経験的証拠に基づかせる。
スケーリング則グラフの理解:普遍的法則ではなく条件付きスナップショット
-
主張*:AIにおける最も誤解されたグラフはスケーリング則曲線である。モデルサイズ、訓練データ、性能の関係を示すこのグラフを、ほとんどの実務家は単純な線形予測ツールと解釈する。だが実際には特定の実験的制約下での条件付き傾向を表現している。この誤読は組織を時代遅れのメンタルモデルに閉じ込め、真の機会を見えなくさせる。その機会とは、スケーリング曲線を診断ツールとして使用し、訓練パイプラインの隠れたレバレッジポイントを解き放つことである。
-
根拠*:スケーリング則は経験的研究(Kaplan et al., 2020; Hoffmann et al., 2022)から生まれた。モデルが成長するにつれて損失が予測可能に減少することを示している。しかしこの関係は限定的な条件下でのみ成立する。固定されたアーキテクチャ、特定のデータ分布、特定の訓練体制である。これらのいずれかが変わると、新しいトークン化スキーム、異なるデータセット、mixture-of-expertsのような建築的革新、あるいは新規の注意機構が登場すると、曲線はシフトする。チームはしばしば歴史的スケーリング曲線を普遍的法則として扱い、特定の実験設定のスナップショットとしては扱わない。これが決定的な盲点だ。各スケーリング曲線は特定の訓練体制のタイムスタンプ付きアーティファクトである。 将来は、これらの曲線を予言ではなく診断信号として読むことを学んだ組織に属する。
-
具体例*:あるチームが自社の独自データセット上で7Bパラメータモデルを訓練し、2倍スケールアップあたり15%の性能向上を観察した。彼らは70Bモデルが150%のゲインをもたらすと予測した。現実には70Bモデルはわずか40%のゲインしか達成しなかった。理由は、スケール時にデータに品質問題があった(信号対ノイズ比の低下)こと、そして大規模モデルの異なる損失ランドスケープに対応するために学習率スケジュールを調整していなかったからだ。グラフの予測が失敗したのはスケーリング則が間違っていたからではなく、運用条件が元の曲線の仮定から乖離したからだ。真の洞察はこうだ。その乖離自体が価値あるデータだった。 それはパラメータ数ではなくデータ品質が制約であることを明かした。
-
実行可能な含意*:スケーリング曲線に依存する前に、正確な条件を文書化せよ。アーキテクチャタイプ、データ構成、訓練期間、最適化ハイパーパラメータ、評価ベンチマーク。各新規プロジェクトを曲線のシフトの可能性として扱え。小規模検証実験(1B~3B パラメータ)を実行して、曲線の形状が自社設定に適用されることを確認する。歴史的曲線は方向性指針のみに使用し、正確な予測には使用しない。さらに重要なことに、予測曲線からの乖離をイノベーション信号として扱え。 70Bモデルが曲線の予測を下回るパフォーマンスを示したとき、なぜそうなったのかを調査せよ。ボトルネックを特定したのだ。それを解決すれば、訓練操作全体で2~3倍の効率ゲインを解き放つ可能性がある。
フロンティアモデルリリースサイクルと曲線の再解釈:ベンチマークの行間を読む
-
主張*:フロンティアラボが新しいモデルをリリースするたびに、コミュニティはそのリリースのレンズを通して既存のスケーリンググラフを再解釈し、しばしば新しいモデルの訓練に何が関わったのかを誤って推論する。このパターンは偽りの物語のフィードバックループを生成し、フロンティアで実際に起きているイノベーションを曇らせる。機会はこれらのリリースにおけるシグナルとノイズを区別することを学ぶこと、そして最も重要なイノベーションはしばしばベンチマーク数値に見えないことを認識することにある。
-
根拠*:OpenAI、Google、Anthropic、Metaがモデルを発表するたびに、実務家は即座に問う。「これはスケーリング則について何を教えてくれるのか」と。だが発表データはめったに訓練の詳細を含まない。チームはその後、新しいモデルを古いスケーリング曲線に無理やり当てはめ、何が機能したのかについて偽りの物語を作成する。モデルは新規の訓練技法(constitutional AI、合成データ生成、カリキュラム学習)、異なるデータ混合(増加したコード、推論トレース、ドメイン特異的コーパス)、あるいはアーキテクチャ変更(スパース注意、適応計算、新規正規化スキーム)を使用した可能性がある。これらのいずれも公開ベンチマーク数値に見えないが、すべてが基礎的なスケーリング関係をシフトさせる。ここで真の競争優位が生まれる。フロンティアリリースの背後にある隠れた変数を推論できる組織は、発表前に次の改善の波を予期する。
-
具体例*:新しいフロンティアモデルは同等のスケールで前世代より30%優れた性能を示した。観察者はスケーリング則が加速したと結論づけた。後の調査で、モデルが使用していたことが明かになった。(1)トークン数を12%削減する異なるトークナイザー、(2)推論タスク上の合成データ拡張、(3)学習スパースパターンを持つ新規注意機構。これらの変更のいずれも公開ベンチマーク数値に見えなかったが、すべてが基礎的なスケーリング関係をシフトさせた。改善が「より良いスケーリング」から来たと仮定したチームはパラメータ数を追求するのに資源を浪費した。建築的およびデータレベルの変更を調査したチームは、それらのイノベーションを複製し拡張する立場に自分たちを置いた。
-
実行可能な含意*:フロンティアリリースを分析する際、知っていることと推論していることを分離せよ。観察可能な事実のみを文書化する。ベンチマークスコア、パラメータ数、発表された技法。訓練データサイズを逆算したり、建築的選択を推論したりする衝動に抵抗せよ。代わりに、リリースが自社のスケーリング仮定を変えるかどうかに焦点を当てよ。自社インフラで発表された技法(公開されている場合)をテストするために制御実験を実行する。より戦略的には、「フロンティア信号検出」プロセスを構築せよ。四半期ごとにリリースを追跡し、発表された技法を抽出し、自社モデルでA/Bテストを実行し、自社ユースケースで実際に針を動かすものを文書化する。 これはフロンティアリリースをノイズから継続的な学習信号に変換する。
実装と運用パターン:ベンチマークゲインから実世界価値へ
-
主張*:チームはスケーリング則を研究段階ツールではなく展開指針として扱うことで誤用する。スケーリング曲線は訓練効率とベンチマーク性能を記述するが、推論コスト、レイテンシ、実世界の有用性は記述しない。次のフロンティアは、スケーリングを単なる研究問題ではなく運用決定として扱う統合コスト・能力曲線を構築することだ。 このシフトは新しいカテゴリーの競争優位を解き放つ。パラメータあたりの能力ではなく、ドルあたりの能力またはミリ秒あたりの能力に対して最適化する組織。
-
根拠*:スケーリング則は、より大きなモデルがベンチマーク上でより低い損失を達成することを予測する。自社ハードウェアで実行できるかどうか、レイテンシSLAを満たすかどうか、エンドユーザーにとってより良い出力を生成するかどうかについては何も言わない。より低い損失とより優れた実世界性能の間のギャップは運用的であり、数学的ではない。より大きなモデルはしばしば量子化、蒸留、または予測ゲインを無効にする提供インフラを必要とする。さらに、ベンチマーク改善と本番ユーティリティの関係はしばしば非線形でタスク依存である。MMULUで20%の精度ゲインは、タスクが100ms以下のレイテンシを必要とする場合、実際の顧客満足度で5%の改善にしか変換されないかもしれない。今日勝っている組織はこのエンドツーエンド関係を測定し、明示的に最適化する組織だ。
-
具体例*:あるチームはスケーリング曲線に基づいて13Bから70Bパラメータにスケーリングし、25%の精度改善を予測した。より大きなモデルは実際に22%の精度を改善した。しかし4倍のGPUメモリが必要になり、推論レイテンシが2倍になり(50msから100msへ)、提供コストが3倍になった(推論あたり$0.001から$0.003へ)。運用オーバーヘッドは精度ゲインの価値を消費した。エンドツーエンド影響を測定したとき、70Bモデルは実際に顧客満足度を低下させた。レイテンシに敏感なユーザーはタイムアウトを経験した。彼らはベンチマーク改善ではなく、単位精度改善あたりのエンドツーエンド展開コストを測定すべきだった。積極的な量子化と検索拡張を備えた13Bモデルが正しい選択だったはずだ。
-
実行可能な含意*:スケーリング則と並行してコスト・能力曲線を構築せよ。各モデルサイズについて測定する。訓練時間、推論レイテンシ(p50、p95、p99)、メモリフットプリント、推論あたりの提供コスト。精度ゲインをパラメータ数ではなく総コストに対してプロットする。パレート境界を使用する。ドルあたりまたはミリ秒あたりの能力を最大化するモデルサイズ。これはしばしばフロンティアラボスケールをはるかに下回る。さらに野心的に、これを継続的最適化問題として扱え。 インフラが改善されるにつれて(より高速なGPU、より優れた量子化アルゴリズム)、四半期ごとに分析を再実行する。より優れた提供インフラを備えた小規模モデルが素朴な展開を備えた大規模モデルを上回ることに気づくかもしれない。次の10倍効率ゲインはここに存在する。
測定と次のアクション:タスク特異的スケーリングを競争優位として
-
主張*:スケーリング則は自社アプリケーションにとって重要なタスクに対して測定される場合にのみ意味がある。ベンチマーク損失はプロキシであり、しばしば本番ユーティリティから乖離する。独自のタスク特異的スケーリング曲線を測定し最適化する組織は、フロンティアラボが容易に複製できない防御可能な競争優位を構築する。 これはフロンティアラボが汎用性能に対して最適化するからだ。自社は特定のユースケースに対して最適化できる。
-
根拠*:スケーリング曲線は通常、標準化されたベンチマーク(MMLU、HellaSwag、GSM8K等)を使用する。これらのベンチマークはモデルを比較するのに有用だが、実際のユースケースを反映しないかもしれない。複数選択問題でよくスケーリングするモデルは、長文推論またはドメイン特異的タスクでは貧弱にスケーリングするかもしれない。実務家はしばしば、モデルが公開ベンチマークでよくスケーリングすれば、独自タスクでもよくスケーリングすると仮定する。危険な仮定だ。逆も真である。公開ベンチマークでスケーリングが貧弱なモデルは、そのタスクが異なる構造または要件を持つ場合、自社の特定のタスクで例外的にスケーリングするかもしれない。 これが非対称優位を見つける機会だ。
-
具体例*:カスタマーサービスチームは公開研究からスケーリング曲線を採用し、34Bモデルが13Bモデルより40%多くの複雑なクエリを処理することを予測した。内部評価では改善はわずか12%だった。公開ベンチマークは一般知識を測定した。顧客クエリはニュアンスのあるドメイン理解、複数ターン会話全体でのコンテキスト保持、曖昧または不完全な情報を処理する能力を必要とした。スケーリング関係はそのタスクに対して根本的に異なっていた。しかし、内部ベンチマーク(解決されたチケットの顧客満足度スコア)上でスケーリングを測定したとき、検索拡張なしの34Bモデルより検索拡張ありの13Bモデルがより良くスケーリングすることを発見した。これは隠れた洞察を明かした。自社のタスクでは、スケールより検索がより価値があった。彼らは今、それに応じて最適化できた。
-
実行可能な含意*:自社データ上で自社のスケーリング曲線を測定せよ。3Bモデルから始め、その後7B、13B、34Bとする。代表的な本番タスク(公開ベンチマークではなく)のサンプルで評価する。曲線をプロットする。公開ベンチマークと比較する。大きく乖離する場合、自社のスケーリング仮定は異なる。これは価値ある情報だ。公開曲線ではなく自社曲線を計画に使用する。大規模訓練にコミットする前に2~3週間をこの測定段階に投資する。これを一度限りの演習ではなく戦略的能力として扱え。 タスク特異的スケーリング曲線を生きた文書として維持する。データとタスク定義が進化するにつれて四半期ごとに更新する。制度的知識として組織全体で共有する。これが自社の内部「スケーリング則」になる。自社の特定の文脈に較正された。
リスクと軽減戦略:スケーリングの罠とそこから脱出する方法
-
主張*:スケーリング則への過度な依存は二つのリスクを生成する。(1)より小規模なモデルでより優れた訓練で十分な場合のスケールへの過剰投資、(2)データ品質とタスク特異的最適化への過少投資。繁栄する組織はスケーリングを多くのレバーの一つとして認識し、正しい順序で正しいレバーを引くことを学ぶ組織だ。 これは、チームがモデル開発についてどう考えるかの根本的シフトを必要とする。
-
根拠*:スケーリング則はより多くのパラメータが常に役立つことを示唆する。これは集計では真だが、データ品質、タスク設計、訓練方法論、推論時技法(検索、思考の連鎖プロンプティング、アンサンブル方法)がしばしばより高いROIをもたらすという事実を隠す。100Bモデルに200万ドルを費やすチームは、13Bモデルに50万ドル、データキュレーション、命令チューニング、検索インフラに150万ドルを投資してより優れた結果を達成するかもしれない。スケーリング則は固定されたデータと訓練実践を仮定するため、このトレードオフを捉えない。将来はこれらすべての次元を順序立ててではなく同時に最適化するチームに属する。 これは新しいメンタルモデルと新しいメトリクスを必要とする。
-
具体例*:二つのチームがカスタマーサポートボットを構築した。チームAはスケールがすべての問題を解決すると仮定して、公開データで70Bパラメータにスケーリングした。チームBは13Bにとどまったが、キュレーションされたサポート会話(10Kの高品質例)、サポート特異的タスク上の命令チューニング、知識ベース上の検索拡張に投資した。チームBのモデルは実際のサポートチケットで35%チームAを上回り、コストは1/10だった。スケーリング則はチームAが勝つと予測した。データ関連性、タスク特異的最適化、検索拡張を考慮していなかった。さらに重要なことに、チームBのアプローチはより防御可能だった。競争優位はパラメータ数ではなくドメイン専門知識とデータキュレーションから来た。チームAのアプローチはより多くのコンピュートを持つ競争相手なら誰でも容易に複製できた。
-
実行可能な含意*:スケーリング前に訓練パイプラインを監査せよ。利用可能な最良のデータを使用しているか。タスク定義は明確か。命令チューニング、検索拡張、思考の連鎖プロンプティングを試したか。小規模モデルでまずこれらの実験を実行する。改善が平坦化した場合のみスケーリングする。「スケーリング準備チェックリスト」を確立する。(1)データ品質スコア(注釈者間合意または専門家レビューとして測定)、(2)タスク明確性(人間は信頼できるようにタスクを実行できるか)、(3)ベースライン最適化レベル(標準技法を試したか)、(4)検索インフラ(該当する場合)、(5)推論時技法(プロンプティング戦略、アンサンブル方法)。チェックリストが緑の場合のみスケーリングする。スケーリングを最初に引くレバーではなく最後に引くレバーとして扱え。 この規律は数百万ドルを節約し、より優れた結果を解き放つ。
結論と移行計画:スケーリング・インテリジェンスを組織に組み込む
-
主張:* AI における最も誤解されたグラフが誤解される理由は、研究知見と運用指針を混同しているからだ。実務家はスケーリング則を設計図ではなく診断ツールとして扱うべきである。勝利する組織とは、スケーリングの周辺に制度的能力を構築した者たちだ。すなわち、自らの文脈に固有なスケーリング曲線を測定し、解釈し、最適化する能力を持つ者たちである。 これは習得可能なスキルであり、いま競争優位の中核となりつつある。
-
根拠:* スケーリング則は実験的文脈の内部では真である。だが同時に不完全だ。デプロイメント制約、タスク特異性、データ品質、モデル性能を改善するための技法の全スペクトラムを考慮していない。グラフは出発点であって到着点ではない。この区別を内面化したチームは、より良い投資判断を下し、スケーリングの失敗を避ける。さらに重要なのは、時間とともに改善する組織学習システムを構築することだ。 測定するスケーリング曲線ひとつひとつが、あなたのデータ、タスク、インフラについて何かを教える。この知識は複利で増殖する。
-
実行可能な含意:* 三段階のアプローチを採用せよ。
-
ベースライン段階(第1~3週): 自らのデータ上でスケーリング曲線を測定する。3B、7B、13B、34Bパラメータでモデルを訓練する。本番タスク上で評価する。曲線を記録する。公開ベンチマークと比較する。乖離を特定する。この乖離こそが競争優位のシグナルだ。
-
最適化段階(第4~12週): データ品質を改善する(キュレーション、クリーニング、重複排除)。タスク定式化を明確にする(インストラクション・チューニング、少数ショット例)。推論時技法を実装する(検索、プロンプト戦略)。小規模モデル(3B~7B)上で改善を測定する。改善が頭打ちになるまでスケールしない。
-
スケール段階(第13週以降): 最適化が頭打ちになった後にのみ、より大規模なモデルにスケールする。タスク特異的なスケーリング曲線を使用して適切なサイズを予測する。機能あたりのエンドツーエンドコストを測定する。自らの特定の制約(レイテンシ、コスト、精度)に対して最適化する。
- 曲線を記録せよ。* 四半期ごとに再検討する。新しいモデルをリリースするとき、曲線をチーム全体と共有する。法則としてではなく、特定の条件下で機能したものの一時的なスナップショットとして。これが制度的知識を構築し、繰り返される誤解を防ぐ。さらに野心的には、組織内に「スケーリング・インテリジェンス」機能を構築せよ。 このチームがスケーリング曲線を所有し、検証実験を実行し、他のチームにいつどのようにスケールするかについて助言する。これは領域が進化するにつれて、持続的な競争優位の源泉となる。
スケーリング則グラフが誤解されるのは、それが間違っているからではない。不完全だからだ。そしてその不完全性こそが、あなたの機会が潜む場所なのだ。

- 図15:理論から実践へのマイグレーション計画(実装ロードマップフレームワーク)*