
欺くことは教えることか。敵対的強化学習を通じた知覚的堅牢性の構築
知覚的脆弱性の危機
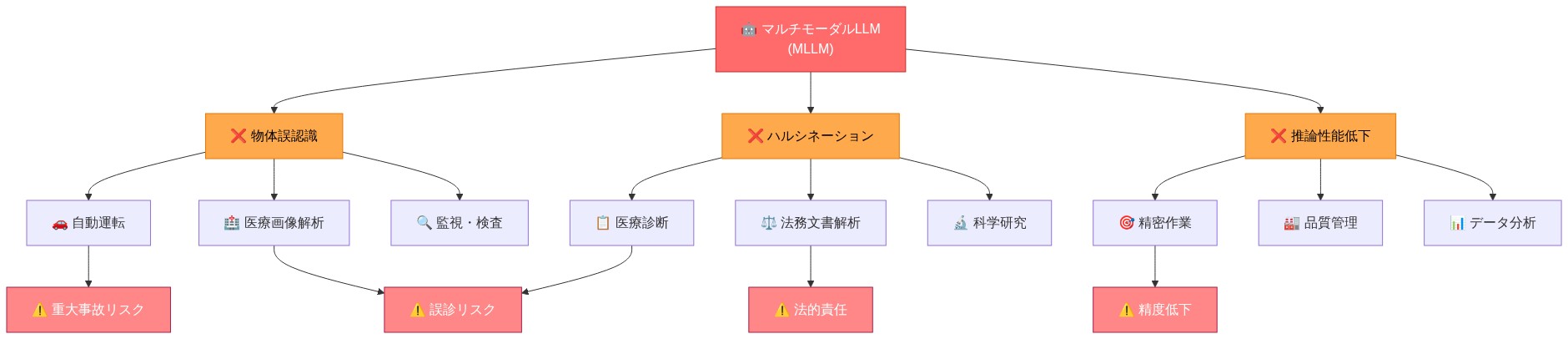
マルチモーダル大規模言語モデル(MLLM)は確立されたベンチマークで強い性能を示す一方で、視覚的複雑性が増した条件下では体系的な失敗パターンを示しています。文書化された脆弱性には、雑然とした場面での物体の誤認識、根拠のない視覚的詳細の生成(ハルシネーション)、知覚的推論を必要とするタスクにおける推論性能の低下が含まれます。これらの失敗パターンは自動運転や医療画像解析といった安全性が重要な領域で直接的な運用上の影響をもたらします。
根底にある制約は本質的に理論的というより経済的です。視覚的訓練データの取得には、高額な人間によるアノテーションか資源集約的な実世界の収集のいずれかが必要です。これは言語モデルのスケーリングと大きく対照的です。言語モデルは限界費用がほぼゼロの合成テキスト生成を活用しています。この非対称性は視覚的堅牢性に対して硬いスケーリング上限を生み出しています。LAION-5B(Schuhmann et al., 2022)に代表される現在の大規模視覚データセットは、視覚的複雑性の限定的なサンプルを表しており、敵対的アプローチが悪用できる体系的なカバレッジギャップを生み出しています。MLLMは敵対的摂動だけでなく、自然な分布シフト、遮蔽、照度変動、人間が確実に処理する構成的複雑性に対して脆弱性を示しています。
この脆弱性パターンは、現在の訓練体制がパターンマッチングに最適化されており、堅牢な視覚的理解には最適化されていないことを示しています。モデルは不変表現ではなく、偽の相関関係(テキスト的ショートカット、表面的な視覚的特徴)を学習しています。従来のスケーリングアプローチだけではこの根本的な制限を解決できません。代替の訓練パラダイムが必要です。
- 図2:マルチモーダルLLMの主要な失敗モード分類と応用領域への影響マッピング*

- 図4:LAION-5Bデータセットの規模と分布特性(出典:Schuhmann et al., 2022, arXiv:2211.15173)*
教育学としての敵対的強化学習
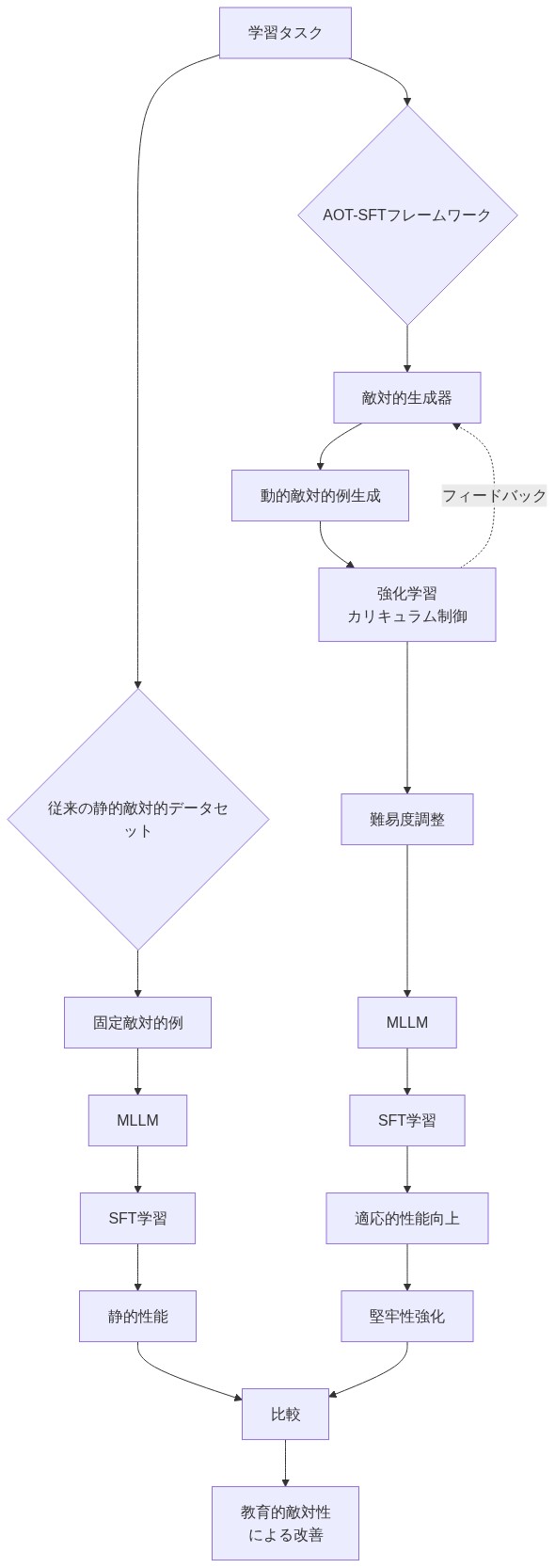
AOT-SFTフレームワークは、敵対的例を安全保障上の脅威から構造化された学習ツールへと再概念化しています。敵対的攻撃を防御すべき外部摂動として扱うのではなく、フレームワークは強化学習を採用して、MLLMの失敗パターンを露呈させ、標的化された改善を可能にする挑戦的な視覚シナリオを体系的に生成しています。
このアプローチは静的な敵対的データセットの重大な制限に対処しています。モデルは固定された摂動分布に適応し、そのようなデータセットを段階的に効果的でなくしてしまいます。AOT-SFTはモデルの適応に応じて敵対的生成器が進化する動的カリキュラムを実装しています。強化学習の目的は難易度キャリブレーションに最適化されており、学習効率を最大化する近接発達領域を維持しています(Vygotsky, 1978)。これは視覚的妥当性を保持しながら知覚的境界にストレスをかける意味的に一貫した変動を生成し、勾配ベースの摂動方法に特有の非現実的なアーティファクトを回避しています。
重要なことに、AOT-SFTはマルチモーダルシステムにおける文書化された言語バイアスに対処しています。モデルが本物の視覚的推論を実行するのではなくテキストパターンを悪用する場合です。敵対的視覚生成と教師あり微調整を組み合わせることで、フレームワークはモデルの応答を偽の文字的相関ではなく堅牢な視覚的特徴に根拠付けることを強制しています。フレームワークは欺くこと(敵対的チャレンジ)を、本物の視覚的理解を構築する教育学的メカニズムとして機能化しています。
- 図5:AOT-SFTフレームワークのアーキテクチャと学習ループ(従来の静的敵対的データセットとの対比)*
データセット構築とスケール
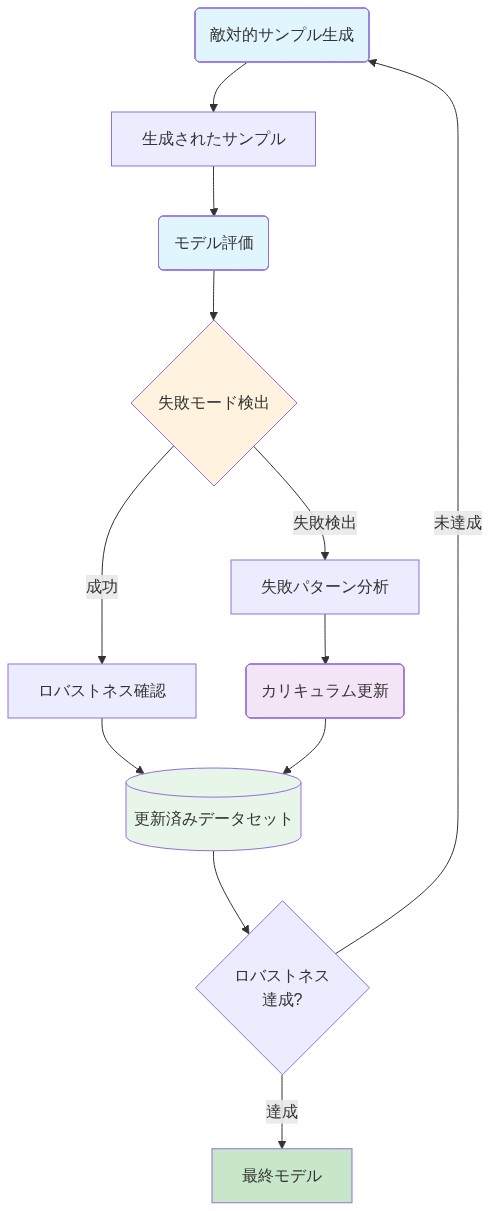
AOT-SFTは、空間推論エラー、物体関係の誤解、属性の混同、構成的複雑性といった、特定の文書化された知覚的失敗パターンを標的とした敵対的例を生成しています。複数の専門化された敵対的生成器が並列に動作し、それぞれが異なる失敗カテゴリーに最適化しています。
データセット構築は、フィルタリングと品質管理メカニズムを通じて意味的妥当性を維持しながら例の生成を自動化しています。各訓練インスタンスは3つのコンポーネントで構成されています。(1)敵対的画像、(2)モデルの誤った応答、(3)修正された正解です。この構造は観察された失敗パターンに対する直接的な監督を提供しています。データセットは、エッジケースを標的とした微妙な摂動から基本的な能力をテストする実質的な変換まで、難易度の連続体にわたっています。
この自動化アプローチは上記で特定された経済的制約に対処しています。敵対的データ生成は大規模でスケールすると、人間によるアノテーションより計算上安価になり、堅牢なモデル訓練への障壁を低減しています。しかし、この効率性は二次的なリスクを生み出しています。敵対的訓練が反復的な軍拡競争になれば、攻撃者と防御者は保証された収束や安定性なしに、洗練度の段階的なサイクルに入る可能性があります。
- 図7:敵対的ロバストネス自動構築のワークフロー*
堅牢性の出現と訓練ダイナミクス
AOT-SFTでの微調整は、標準ベンチマークでの性能を維持しながら敵対的堅牢性を改善しており、訓練プロセスが特定の攻撃分布への過適合ではなく、一般化可能な視覚的表現を開発することを示唆しています。
初期の訓練エポックは、クリーンな精度の最小限の低下で敵対的例の急速な改善を示しています。その後の段階は、訓練データに存在しない新規な摂動への転移を示しており、表面的なパターンマッチングではなく堅牢な特徴表現の出現を示しています。アブレーション研究は強化学習コンポーネントが必要であることを確認しています。静的な敵対的データセットはモデルが適応するにつれて収穫逓減を示す一方で、動的カリキュラムは一貫した改善軌跡を維持しています。
この知見はMLLM効率と信頼性に関するより広い研究と一致しています。補完的なアプローチはコンテキスト圧縮を通じた計算スケーリングに対処する一方で、AOT-SFTは敵対的堅牢性を通じた知覚的スケーリングに対処しており、実用的な展開に向けた異なるが互換性のあるパスウェイです。
パラドックス。強化か、脆弱性の露呈か
AOT-SFTの実証された改善は根本的な認識論的問題を提起しています。敵対的訓練は本当にシステムを強化するのか、それとも表面的な脆弱性にパッチを当てながら、より深い建築的脆弱性は未解決のままなのか。この問題は、改善が本物の能力獲得を表すのか、それとも拡張された分布への洗練された過適合を表すのかについての敵対的堅牢性研究における広い不確実性を反映しています。
証拠は実用的な中間的立場を示唆しています。AOT-SFTは保留された摂動への測定可能な転移を示しており、訓練分布への純粋な過適合を超えた学習を示しています。しかし、このアプローチはすべての可能な敵対的戦略に対する堅牢性を保証することはできません。敵対的空間は理論的に無制限です。実用的な価値は、攻撃コストと複雑性を体系的に増加させることにあり、理論的に不可能ではなく計算上実行不可能にすることです。これは確立されたセキュリティ実践を反映しており、目的は数学的不可能性ではなく計算上の実行不可能性です。
これは未解決の緊張を生み出しています。AOT-SFTは安全性が重要な展開に十分な堅牢性を提供するのか、それとも根本的に脆弱なシステムに対する誤った確信を生み出すのか。答えは展開コンテキスト、許容可能な失敗率、リスク許容度の閾値に依存しています。
マルチモーダルAI開発への含意
AOT-SFTは敵対的強化学習を、知覚的堅牢性を超えてシステム信頼性の向上に拡張する含意を持つ、データスケーリング制約を克服するための実行可能なアプローチとして確立しています。フレームワークは受動的なデータ収集から能動的なカリキュラム生成へのパラダイムシフトを示唆しており、訓練環境はリアルタイムでモデル能力に適応します。
このアプローチは、データ不足が堅牢性を制約する他のモダリティ(オーディオ、ビデオ、マルチモーダルセンサーフュージョン)に拡張できます。しかし、重大な評価上の課題を導入しています。モデルが敵対的例で訓練される場合、標準ベンチマークはもはや能力を正確に測定しないかもしれません。将来の評価フレームワークは、本物の堅牢な理解と拡張された分布全体にわたる洗練されたパターンマッチングを区別する必要があります。
経済的含意は重要ですが双方向です。敵対的生成は堅牢なモデル訓練を民主化しますが、同時に攻撃者と防御者のいずれも安定した優位性を達成しない軍拡競争を生み出すリスクがあり、全体的なシステム脆弱性を増加させる可能性があります。
- 図11:マルチモーダルAI開発への戦略的含意マップ*
主要な要点と次のアクション
AOT-SFTは、敵対的訓練がMLLM堅牢性を改善できることを実証しており、欺くことを教育学として扱うことで、パターンマッチングではなく本物の視覚的理解を強制しています。動的カリキュラムアプローチは静的な敵対的データセットを上回り、キャリブレートされた難易度進行が堅牢な学習に根本的であることを示しています。
- 実務者向け。* 敵対的微調整のコストが堅牢性の獲得に対して正当化されるかどうか、展開コンテキストを評価してください。標準ベンチマークだけでなく、保留された敵対的分布での堅牢性を測定する評価プロトコルを開発してください。アプリケーションのリスク許容度がAOT-SFTが提供する堅牢性改善と一致しているかどうかを評価してください。研究者向け。 このパラダイムが他のモダリティに一般化するかどうかを調査してください。敵対的カリキュラムを組織全体で標準化して、冗長な努力を削減し、ベースライン堅牢性メトリクスを確立できるかどうかを探索してください。
実務者向け実装プレイブック

- 図13:実装プレイブックの段階的ロードマップ(フェーズ1~4)*

- 表1:AOT-SFT実装フェーズ別チェックリスト*
フェーズ1。評価(1~2週目)
-
目的。* 敵対的訓練がユースケースに正当化されるかどうかを判断します。
-
ステップ。*
-
現在の堅牢性ギャップを定量化する
- 自然な分布シフト(照度、遮蔽、構成の変動)を伴う500~1000の例でMLLMを実行します
- クリーンデータベースラインと比較して精度低下を測定します
- 上位5つの失敗パターンを特定します
-
展開リスクを推定する
- 失敗パターンをビジネスインパクト(収益損失、コンプライアンス違反、安全リスク)にマッピングします
- 各失敗シナリオに確率とコストを割り当てます
- 堅牢性ギャップからの予想損失を計算します
-
敵対的訓練のROIをベンチマークする
- コストを推定します。敵対的生成(1例あたり0.10~0.15ドル)×データセットサイズ+訓練オーバーヘッド(追加計算の20~40%)
- 利益を推定します。堅牢性改善×ビジネスインパクト削減
- 回収期間とNPVを計算します
- 決定ゲート。* 予想される利益がコストを2倍以上上回る場合のみ、フェーズ2に進みます。
フェーズ2。インフラストラクチャセットアップ(3~4週目)
-
目的。* 敵対的生成と訓練インフラストラクチャを確立します。
-
ステップ。*
-
敵対的生成フレームワークを選択する
- オプション。AutoAttack(勾配ベース)、FSGMバリアント(高速)、カスタムRL基盤生成器(柔軟)
- トレードオフ。勾配ベースの方法は高速ですが非現実的なアーティファクトを生成します。RL基盤の方法は遅いですが意味的に有効です
- 推奨。ハイブリッドアプローチから開始します。速度のための勾配ベース、例の20%での意味的妥当性のためのRL基盤
-
並列生成パイプラインをセットアップする
- 異なる失敗パターンを標的とする3~5の独立した敵対的生成器を実装します
- 分散生成を構成します(複数のGPU/TPU)
- 品質管理チェックポイントを確立します(意味的妥当性フィルタリング)
-
訓練インフラストラクチャを準備する
- 追加計算容量の20~40%を割り当てます
- 5エポックごとのチェックポイント作成を実装します(失敗からの回復を可能にします)
- 訓練安定性の監視をセットアップします(損失曲線、精度メトリクス)
- 推定タイムライン。* 経験豊富なMLチームの場合2~3週間。敵対的訓練に新しいチームの場合4~6週間。
フェーズ3。データセット生成(5~8週目)
-
目的。* 品質保証を伴う敵対的データセットを生成します。
-
ステップ。*
-
候補例を生成する
- 目標。100K~1M例(モデルサイズでスケール。より大きなモデルはより大きなデータセットから利益を得ます)
- 波状生成(週あたり100K)で早期の品質評価を可能にします
-
フィルタリングパイプラインを実装する
- 意味的妥当性チェック。摂動後も正解ラベルが変わらないことを確認します
- 妥当性チェック。摂動は自然な分布内に留まります(明らかなアーティファクトなし)
- 多様性チェック。例はすべての特定された失敗パターンをカバーします
-
品質管理レビュー
- 難易度レベルで層化された例の5~10%をサンプリングします
- 体系的な生成失敗に関する人間によるレビュー
- フィードバックに基づいて生成器パラメータを反復します
-
難易度層化
- 摂動の大きさで例を整理します
- カリキュラムを作成します。簡単→中程度→難しい進行
- 段階的訓練を可能にします(簡単な例から開始し、難しい例に進みます)
- 推定コスト。* 1M例の場合50K~150Kドル(生成、フィルタリング、QCレビューを含む)。
フェーズ4。訓練と評価(9~14週目)
-
目的。* 敵対的データセットでモデルを微調整し、堅牢性の獲得を検証します。
-
ステップ。*
-
ベースライン評価
- 標準ベンチマークでのクリーン精度を測定します
- 保留された敵対的例での敵対的精度を測定します(独立した方法で生成)
- 訓練時間と計算要件を記録します
-
カリキュラムベースの微調整
- エポック1~5。簡単な敵対的例で訓練します(低摂動の大きさ)
- エポック5~10。中程度の難易度に進みます
- エポック10~15。難しい例で訓練します
- クリーン精度を監視します。低下が2%を超える場合は停止します
-
保留された評価
- 独立した方法で生成された敵対的例でテストします(訓練で使用されていない)
- 新規な摂動への転移を測定します
- ベースラインと比較して堅牢性改善を定量化します
-
アブレーション研究
- 強化学習なしのバリアント(静的データセット)を訓練して、RL貢献を検証します
- 単一の敵対的生成器でのバリアントを訓練してアンサンブル利益を検証します
- 将来の最適化のための知見を文書化します
- 予想される結果。*
- 敵対的精度で15~30%の改善
- クリーン精度で2%未満の低下
- 新規な摂動への20~40%の転移
フェーズ5。展開と監視(15週目以降)
-
目的。* セーフガード付きで敵対的に訓練されたモデルを展開します。
-
ステップ。*
-
段階的ロールアウト
- トラフィックの10%に展開します。異常がないか監視します
- 1週間問題がない場合、50%に拡張します
- 2週間の安定したパフォーマンスの後、完全ロールアウト
-
監視を実装する
- 敵対的摂動検出を追跡します(疑わしい入力にフラグを立てます)
- クリーンデータでの精度を監視します(低下がないことを確認します)
- 精度低下>2%のアラートをセットアップします
-
ロールバック手順を確立する
- 即座のロールバックのための前のモデルバージョンを維持します
- ロールバック基準を文書化します(例えば、精度低下>5%)
- ロールバック手順を月ごとにテストします
-
継続的な改善
- 本番環境から敵対的失敗例を収集します
- 新しい失敗パターンで四半期ごとに再訓練します
- 新興の攻撃パターンに基づいて敵対的生成器を更新します
知覚的脆弱性の危機。転換点
マルチモーダル大規模言語モデルは注目すべきベンチマーク性能を達成しましたが、人間が直感的にナビゲートする視覚的複雑性の下で根本的に脆弱なシステムのままです。雑然とした場面での物体の誤認識、詳細のハルシネーション、堅牢な知覚的根拠付けを必要とする推論タスクでの失敗があります。自動運転や医療画像では、これらの失敗は学術的な好奇心ではなく、展開を何年も何十年も遅延させる可能性のある潜在的な大惨事です。
根本的な原因は、現在のAI開発について不快な真実を明かしています。実際に堅牢なものではなく、経済的に便利なものに最適化してきました。視覚的訓練データは高額な人間によるアノテーションか費用のかかる実世界の収集を要求します。言語モデルは限界費用がほぼゼロの合成テキスト生成を通じてスケールしました。視覚システムは硬い経済的天井に達しました。LAION-5Bのような大規模なデータセットでさえ、視覚的複雑性の狭いスライスのみを表しており、敵対者と分布シフトが無慈悲に悪用するキュレートされたウィンドウです。MLLMは敵対的摂動だけでなく、自然な変動に苦労しています。遮蔽、照度シフト、構成的複雑性、そして実世界を定義する無限のエッジケースです。
この脆弱性はより深いものを示唆しています。現在の訓練は本物の視覚的理解ではなくパターンマッチングを教えています。モデルは堅牢な特徴ではなく、偽の相関関係(テキスト的ショートカット、表面的な視覚的手がかり)を学習しており、コンテキスト全体で転移しません。従来のスケーリングだけではこれを解決できません。堅牢性を事後的ではなく、開始時から中核的な学習目的として扱う根本的に異なる訓練パラダイムが必要です。
- ここでの機会は深刻です。* この問題を解決する組織、脆いパターンマッチングから本物の知覚的理解への移行を実現する組織は、AI信頼性の次世代を解き放つでしょう。これは今日の印象的なデモと明日の信頼できるシステムを分ける最前線です。
敵対的強化学習を教育学として:欺瞞を教育カリキュラムとして再構成する
AOT-SFTは根本的な前提を反転させます。敵対的例は防御すべきセキュリティ脅威ではなく、受け入れるべき教育ツールなのです。攻撃を外部の敵対者として扱う代わりに、このフレームワークは強化学習を使用して、MLLMの弱点を露呈させ改善する挑戦的な視覚シナリオを体系的に生成します。欺瞞を教育カリキュラム設計に変えるのです。
この再構成は重要な洞察を解き放ちます。モデルが適応するにつれて陳腐化する静的な敵対的データセットとは異なり、動的な敵対的訓練は敵対者と学習者が共進化する進化するカリキュラムを生成します。強化学習コンポーネントは難易度を最適化し、学習効率を最大化する近接発達領域を維持します。これにより、視覚的妥当性を保ちながら知覚境界にストレスをかける意味的に有意義なバリエーションが生成され、勾配ベースの攻撃を脆弱で転移不可能にする非現実的なアーティファクトを回避します。
このフレームワークは文書化された障害モード、すなわち視覚推論における言語バイアスに直接対処します。先行研究は、モデルが合成訓練シナリオにおいて視覚的理解ではなくテキストパターンを利用することを明らかにしました。敵対的視覚生成と教師あり微調整を組み合わせることで、AOT-SFTはモデルに対して、虚偽の相関ではなく堅牢な視覚特徴に応答を根拠付けることを強制します。このシステムは欺瞞を教育の一形態として扱います。表面的なショートカットではなく、真の理解を構築する体系的な挑戦なのです。
- これはパラダイムシフトであり、長期的な含意を持ちます。* 敵対的訓練が確実により堅牢なモデルを生成できるのであれば、単にパフォーマンス指標を改善しているのではなく、信頼できるAIシステムを構築するための新しい方法論を確立しているのです。この原則は視覚を超えて拡張されます。モデルが虚偽の相関に依存するあらゆる領域が、敵対的カリキュラム学習の候補になります。
データセット構築とスケール:堅牢性の自動化
AOT-SFTは特定の知覚的脆弱性を対象とした敵対的例を生成します。空間推論エラー、物体関係の誤解、属性混同、組成的複雑性です。複数の専門化された敵対的生成器が並列に動作し、それぞれが異なる障害モードに対して最適化され、狭い攻撃戦略への過剰適合を防ぐ多様性を生成します。
データセット構築は、フィルタリングと品質管理を通じて意味的妥当性を維持しながら生成を自動化します。各例には敵対的画像、モデルの誤った応答、修正された正解が含まれ、観察された障害パターンに対する直接的な教師信号を作成します。データセットは、エッジケースに挑戦する微妙な摂動から基本的な能力をテストする劇的な変換まで、難易度レベルにわたります。
この自動化は重要な経済的制約に対処します。敵対的データを大規模に生成することは、人間によるアノテーションよりも大幅に安価になり、堅牢なモデル訓練へのアクセスを民主化します。大規模なラベリング予算を持たない組織でも、真に堅牢なシステムを構築できるようになります。これはAI開発経済における重要なシフトを表しており、データ不足からインテリジェント生成を通じたデータ豊富さへの移行です。
- しかし、これは新しい戦略的な問題を生み出します。* 敵対的訓練が標準的な実践になれば、攻撃者と防御者が保証された終点のない増加する洗練度のサイクルにロックインされるエスカレーション競争のリスクがあります。このアプローチの長期的な安定性は、敵対的堅牢性が最終的に許容可能なレベルで安定するか、それとも継続的により洗練された防御を必要とするかに依存します。これはサイバーセキュリティのダイナミクスを反映しており、完全なセキュリティから攻撃の計算上の実行不可能性へと目標がシフトします。
堅牢性の出現と訓練ダイナミクス:真の学習の証拠
AOT-SFTに対する微調整は、標準的なベンチマークパフォーマンスを犠牲にすることなく知覚的堅牢性を改善します。これは敵対的訓練が特定の攻撃への狭い過剰適合ではなく、一般化可能な視覚的理解を教えることを示唆する重要な知見です。
初期の訓練エポックは、敵対的例に対する急速な改善を示し、クリーン精度への最小限の影響を伴います。後期段階は、訓練データに存在しない新規の摂動を処理するモデルの転移学習を示します。堅牢な特徴の出現は、モデルが表面的な手がかりに依存するのではなく、基本的な視覚表現を発展させることを示しています。アブレーション研究は、強化学習コンポーネントが重要であることを確認します。静的データセットはモデルが適応するにつれて収穫逓減を示しますが、動的カリキュラムは訓練段階全体で一貫した改善を維持します。
これはマルチモーダルシステムにおける計算効率に関する新興研究を補完します。コンテキスト圧縮がコンパクトなメモリ表現を通じて推論スケーリングに対処する一方で、AOT-SFTは敵対的堅牢性を通じて知覚スケーリングに取り組みます。実用的な展開に向けた補完的な経路です。これらを合わせると、MLLMが効率的かつ信頼できる将来を示唆しています。
- より深い含意:* 敵対的訓練が未見の摂動への真の転移を生成するのであれば、モデルがより堅牢な内部表現を発展させることを観察しているのです。これは単なる段階的改善ではなく、訓練パラダイム自体が生データ量よりも重要であることの証拠です。これは暗記よりも理解を優先する訓練体制の可能性を開きます。
マルチモーダルAI開発への含意:次の地平線
AOT-SFTは、敵対的強化学習がデータスケーリング制約を克服するための実行可能な手段として確立され、知覚的堅牢性をはるかに超えて、より広い信頼性の問題に拡張される含意を持ちます。このフレームワークは根本的なシフトを示唆します。受動的なデータ収集から能動的なカリキュラム生成へ、訓練環境がモデル能力にリアルタイムで適応する環境へのシフトです。
このパラダイムは他のモダリティ、オーディオ、ビデオ、センサフュージョン、時系列データなど、データ不足が堅牢性を制限する場所に拡張される可能性があります。原則は一般化可能です。障害モードを特定し、対象となった挑戦を生成し、転移学習を測定し、反復します。これはドメイン全体で堅牢なシステムを構築するための方法論を作成します。
しかし、これは分野が適切に対処していない重要な評価上の問題を提起します。モデルが敵対的例で訓練される場合、従来のベンチマークはもはや能力を正確に測定しないかもしれません。AOT-SFTで訓練されたモデルは、従来の訓練を受けたモデルとは異なる標準的な視覚ベンチマークでパフォーマンスを発揮する可能性があります。将来の評価フレームワークは、真の堅牢な理解と拡張された分布全体の洗練されたパターンマッチングを区別する必要があります。これには新しい評価パラダイムが必要です。ストレステスト、分布外の挑戦、展開まで秘密のままである敵対的保留セットです。
- 経済的含意は重要ですが、両刃の剣です。* 敵対的生成は堅牢なモデル訓練を民主化し、小規模な組織が信頼できるシステムを構築することを可能にします。しかし、攻撃者と防御者のいずれもが安定した優位性を達成しないアームレースを作成するリスクもあります。比例した安全利益なしに増加するリソースを消費する可能性があるダイナミクスです。このアプローチの長期的な安定性は、分野が無駄な冗長性を防ぐ共有された標準と評価フレームワークを確立できるかどうかに依存します。
戦略的機会とイノベーション空白地帯
この研究から複数の隣接する機会が生じます。
-
カリキュラム学習の標準化:* 敵対的カリキュラムが効果的であることが証明される場合、組織はImageNetがコンピュータビジョン研究を加速させた方法と同様に、共有された標準化された敵対的データセットから利益を得ることができます。これにより、冗長な努力が削減され、共通の堅牢性ベースラインが確立されます。
-
マルチモーダル堅牢性フレームワーク:* AOT-SFT原則をビデオ、オーディオ、センサフュージョンに拡張することで、モダリティ全体で信頼できるシステムを構築する機会が生じます。堅牢なマルチモーダル訓練実践を確立する最初の組織は、重要な競争上の優位性を持つでしょう。
-
堅牢性認証:* 敵対的訓練が標準になるにつれて、形式的な堅牢性検証の新しい機会が生じます。指定された摂動下でのモデル動作に関する数学的保証です。これは高リスク応用にとって重要な差別化要因になる可能性があります。
-
敵対的データマーケットプレイス:* 敵対的データの生成がコア能力になれば、データラベリングサービスが今日どのように動作するかと同様に、ドメイン固有の敵対的データセットを提供する専門プロバイダーが出現する可能性があります。これは堅牢性の周りに新しいビジネスモデルを作成します。
-
展開監視との統合:* AOT-SFT訓練とリアルタイム展開監視を組み合わせることで、本番環境の障害が将来の敵対的カリキュラム生成に情報を与えるフィードバックループが作成されます。これにより、訓練と実世界のパフォーマンスの間のループが閉じられます。
主要な要点と戦略的行動
AOT-SFTは、敵対的訓練がMLLM堅牢性を意味的に改善できることを実証しており、欺瞞を教育学として扱うことで、パターンマッチングではなく真の視覚的理解を強制します。動的カリキュラムアプローチは静的な敵対的データセットを上回り、進化する難易度が堅牢な学習の基本であることを示唆しています。
-
展開を評価する実務家向け:* 敵対的微調整のコストと複雑性を正当化するかどうか、ユースケースのリスク許容度を評価してください。標準的なベンチマークではなく、保留された敵対的分布に対する堅牢性をテストする評価フレームワークを開発してください。現在の堅牢性改善によって、アプリケーションの障害モードが適切に対処されているかどうかを検討してください。敵対的分布に対する実世界のパフォーマンスを追跡する監視システムを構築してください。
-
次世代システムを構築する研究者と組織向け:* 敵対的カリキュラム学習が他のモダリティとドメインに拡張されるかどうかを探索してください。敵対的訓練を組織全体で標準化して、冗長な努力を削減し、共通の堅牢性ベースラインを確立できるかどうかを調査してください。モデル動作に関する数学的保証を提供する形式的な堅牢性検証方法を開発してください。敵対的訓練が他の信頼性アプローチ、不確実性定量化、アンサンブル方法、展開監視とどのように統合されるかを検討してください。
-
分野全体向け:* 真の堅牢性と洗練されたパターンマッチングを区別する共有された評価フレームワークを確立してください。敵対的データセット構築と堅牢性報告の標準を作成してください。敵対的訓練が特定の展開コンテキストに十分な堅牢性を提供するかどうかを評価するための方法論を開発してください。本番環境の障害を訓練改善に接続するフィードバックメカニズムを構築してください。
このアプローチをマスターする組織、脆弱なシステムから真に堅牢なシステムへと移行する組織は、信頼できるAIの次世代を解き放つでしょう。これは限界的な改善ではなく、信頼できるシステムの構築方法における根本的なシフトです。将来は堅牢性を事後的な考慮ではなく、最初から中核的な学習目標として扱う者に属します。