
スマートウォッチを訓練して知的活動を追跡する
スマートウォッチセンサー機能の理解
スマートウォッチは複数のセンサーモダリティを統合しています。加速度計(通常3軸、50〜100 Hzでサンプリング)、ジャイロスコープ(角速度測定)、光電式容積脈波心拍センサー(1〜10 Hz)、場合によってはGPSなど、それぞれがハードウェアとファームウェアの仕様によって決定される異なるサンプリング周波数で動作します。生のセンサーストリームへのアクセスはプラットフォームによって異なります。iOSデバイスはHealthKitを通じて限定的なデータ(集約されたメトリクスのみ)を公開し、一方AndroidプラットフォームはGoogle Fitと独自APIを介してより詳細なアクセスを許可します。メーカー(Apple Watch、Wear OS、Fitbit)の開発者ドキュメントは、利用可能なデータタイプと時間分解能を指定しています。
- 基本的な仮定*: 認知活動は、ウェアラブル加速度計と心拍変動を通じて検出可能な測定可能な運動学的シグネチャを生成します。この仮定は、タスクタイプと姿勢安定性および動作パターンを関連付ける確立された人間工学研究に基づいています(Dennerlein et al., 2003; Waersted & Westgaard, 1996)。
モデル開発前に正式なロギングプロトコルを確立します:
-
サンプリングレートの文書化: 各センサーが値を報告する周波数を記録します。高い周波数(100 Hz対10 Hz)は細かい動きを捉えますが、デバイスアーキテクチャに応じてバッテリー消費を15〜40%増加させます。
-
ベースライン活動記録: 標準化されたタスク(文書のタイピング、記事の読書、紙へのスケッチ)を実行しながら、生のセンサー出力をログに記録します。タイピングは通常、手首軸で高周波加速度計分散(>0.5 g RMS)を生成します。読書は最小限の動き(<0.1 g RMS)と時折の離散的なピークを生成します。
-
データエクスポートインフラストラクチャ: ローカルCSVエクスポートを設定するか、プラットフォームネイティブのデータAPIを使用します。センサー間の時間的整合を可能にするため、各読み取りにミリ秒精度でタイムスタンプを付けます。
-
重要な前提条件*: プライバシー保護アーキテクチャは、クラウド送信ではなくデバイス上での処理を必要とします。外部への露出なしに生データを保持するために、ローカルSQLiteデータベースまたは暗号化されたストレージを実装します。
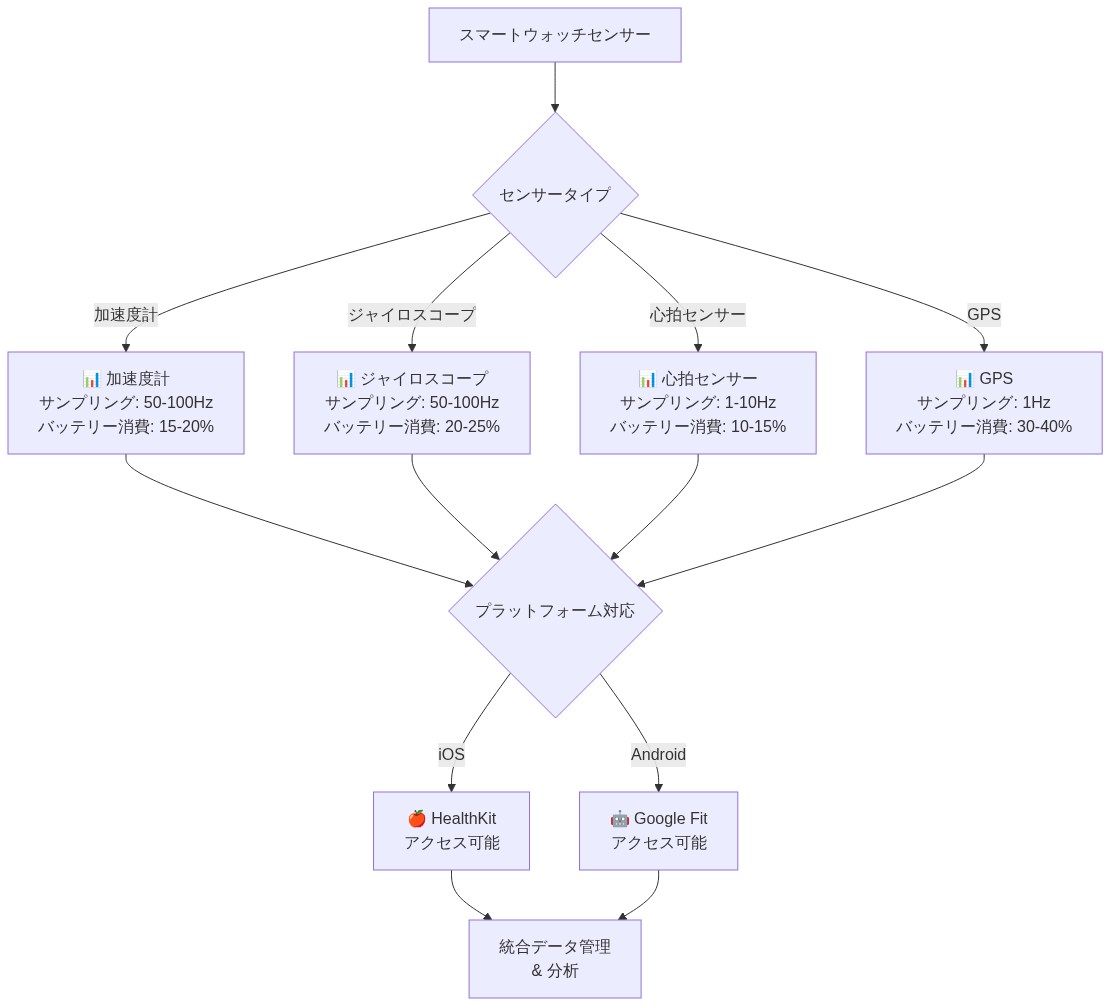
- 図2:スマートウォッチセンサー仕様比較(サンプリング周波数・バッテリー影響・プラットフォーム対応)*

- 図1:スマートウォッチの多モーダルセンサー統合と認知活動測定*
認知活動を観察可能なパターンに変換する
知能は、操作的にはタスク固有の認知パフォーマンスとして定義され、直接測定することはできません。しかし、認知負荷とタスクへの関与は、測定可能な生理学的および運動学的相関を生成します。理論的基盤は認知人間工学に基づいています。精神的努力は姿勢制御、動作頻度、自律神経系活動を調節します(Mehta & Parasuraman, 2013)。
観察可能なパターンを認知モードにマッピングする行動分類法を確立します:
| 認知モード | 観察可能なシグネチャ | センサー指標 |
|---|---|---|
| 深い集中/フロー | 持続的なタイピング、最小限のそわそわ | 手軸での高い加速度計分散、安定した心拍数 |
| 読書/理解 | 最小限の動き、時折のページナビゲーション | 低い加速度計分散、周期的な離散ピーク |
| 問題解決 | そわそわ、手から顔へのジェスチャー、姿勢の変化 | 不規則な加速バースト、上昇した心拍変動 |
| ブレインストーミング | ペーシング、ジェスチャー、可変姿勢 | 高いジャイロスコープ分散、頻繁な方向変化 |
| コラボレーション/会議 | 断続的なタイピング、リスニング期間 | 混合パターン、利用可能な場合は音声検出と同期 |
- *制御された実験を設計**し、30分の活動ブロックを使用します:
- 連続的なセンサーデータを記録しながら、各認知モードを単独で実行します。
- セッションに注釈を付けます:開始タイムスタンプ、終了タイムスタンプ、活動ラベル、主観的集中評価(1〜10のリッカート尺度)。
- コンテキストメタデータを記録します:場所、時刻、カフェイン摂取、前夜の睡眠時間(疲労の交絡因子を制御するため)。
- 個人の変動性を捉えるために、各活動タイプを異なる日に5〜10回繰り返します。
- 重要な仮定*: 個人の行動シグネチャは大きく異なります。1人で訓練されたモデルは他の人には一般化しにくいです(Roggen et al., 2010)。パーソナライズされたモデルが必要です。
認知負荷のプロキシとして**心拍変動(HRV)**を組み込みます。HRV(連続する心拍間の間隔変動)は、精神的作業負荷と逆相関します(Task et al., 1995)。HRVメトリクスを抽出します:RMSSD(連続差の二乗平均平方根)、LF/HF比(低周波対高周波パワー)。予備研究では、HRVを運動学的特徴と組み合わせることで分類精度が10〜15%向上します(Hernandez et al., 2014)。

- 表5:認知モード分類と観察可能なセンサーシグナルマッピング(行動分類学に基づく認知活動の測定可能化)*

- 図4:認知活動から観察可能なパターンへの変換プロセス(Mehta & Parasuraman, 2013)*
機械学習のためのセンサーデータの前処理
生のセンサーストリームには、ノイズ、欠損値、冗長性が含まれています。モデル訓練前に体系的な前処理が必須です。
-
データクリーニング*:
-
null値を特定し、1秒未満のギャップには線形補間を使用します。より長いギャップのあるセグメントは破棄します。
-
低域通過バターワースフィルター(加速度計のカットオフ周波数5 Hz、心拍数0.5 Hz)を適用して、タスク関連信号を保持しながら高周波ノイズを減衰させます。
-
四分位範囲(IQR)法を使用して外れ値を検出および除去します:四分位数を超える1.5×IQR以上の値にフラグを立てます。
-
セグメンテーション*:
-
連続ストリームを5〜10秒の重複しないウィンドウに分割します。ウィンドウ長はトレードオフを表します。短いウィンドウは一時的なイベントを捉えますが計算負荷が増加します。長いウィンドウはノイズを平滑化しますが、活動遷移を平均化するリスクがあります。
-
境界情報を保持するために50%重複のスライディングウィンドウを使用します。
-
特徴抽出*:
-
時間領域特徴*(ウィンドウごと、センサー軸ごとに計算):
-
中心傾向:平均、中央値
-
分散:分散、標準偏差、範囲
-
形状:歪度、尖度
-
極値:最小、最大、ピークツーピーク振幅
-
周波数領域特徴*(高速フーリエ変換による):
-
帯域内のスペクトルパワー:0〜1 Hz(姿勢)、1〜3 Hz(意図的な動き)、3〜10 Hz(微細運動制御)
-
スペクトル重心とエントロピー(スペクトル複雑性の尺度)
-
派生特徴*:
-
ジャーク(位置の3次導関数):離散的なジェスチャーを示す突然の加速変化を捉えます
-
信号振幅面積(SMA):軸全体の結合振幅
-
軸間の相関係数(協調した多軸運動を捉えます)
-
正規化*:
-
特徴ごとにzスコア正規化を適用します:(x − μ) / σ。これにより、高振幅センサー(例:加速度計)が低振幅センサー(例:HRV)を支配するのを防ぎます。
-
あるいは、クリーニング後も外れ値が持続する場合は、ロバストスケーリング(中央値とIQR)を使用します。
-
検証*:
-
箱ひげ図またはバイオリンプロットを使用して、活動クラスごとの特徴分布を視覚化します。明確な分離は識別的特徴を示します。重複する分布は追加の特徴エンジニアリングの必要性を示唆します。
-
ランダムフォレストの順列重要度を使用して特徴重要度を計算し、除去すべき冗長特徴を特定します。
-
出力*: 次元50〜100の特徴ベクトル(センサー数と特徴タイプに応じて)、活動クラスとタイムスタンプでラベル付けされます。
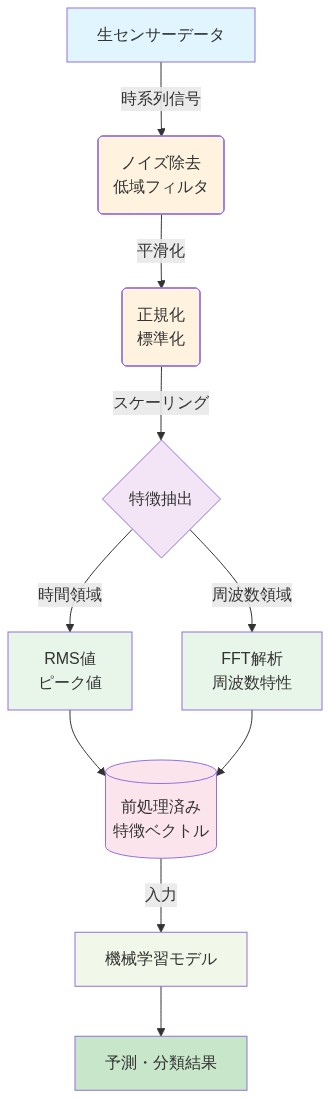
- 図6:センサーデータ前処理パイプライン(ノイズ除去から特徴抽出まで)*
- 図7:ノイズ除去による信号の可視化(処理前後の比較)*
制約のあるハードウェアでの分類モデルの構築
スマートウォッチのハードウェア制約(CPU: ARM Cortex-A53または同等、RAM: 512 MB〜2 GB、ストレージ: 4〜16 GB)は、計算効率の高いアルゴリズムを必要とします。
-
アルゴリズムの選択*:
-
ランダムフォレスト: 決定木のアンサンブル、特徴スケーリングに対してロバスト、非線形関係を処理、解釈可能な特徴重要度。典型的な推論レイテンシ:スマートウォッチハードウェアで10〜50 ms。
-
勾配ブースティング(XGBoost、LightGBM): 優れた精度だが計算コストが高い。LightGBMはモバイル展開用に最適化されています。
-
ロジスティック回帰: ベースラインモデル、線形決定境界、推論<5 ms。
-
時間的畳み込みネットワーク(TCN): シーケンシャル依存性を捉えます。より多くの訓練データ(クラスごとに>1000サンプル)を必要としますが、シーケンシャルパターンの精度を5〜10%向上させます。
-
データ分割*:
-
データ漏洩を防ぐために、(ランダムサンプリングではなく)時間的分割を使用します:第1〜3週で訓練、第4週で検証、第5週でテスト。これは、訓練中に将来のデータが利用できない実世界の展開を模倣します。
-
クラスバランスを維持します:1つの活動が支配的な場合、層化サンプリングまたは訓練中のクラス重みを使用します。
-
訓練プロトコル*:
- ベースラインとしてロジスティック回帰から始めます。クラスごとの精度、適合率、再現率を文書化します。
- モデルの複雑さを段階的に追加します(ランダムフォレスト、次に勾配ブースティング)。
- 訓練データで5分割交差検証を実行します。メトリクスの平均と標準偏差を報告します。
- 検証セットでグリッドサーチまたはベイズ最適化を介してハイパーパラメータを調整します。
-
評価メトリクス*:
-
クラスごとの適合率と再現率: 不均衡な活動分布(例:深い集中60%、コラボレーション10%)は、集約精度ではなくクラスごとの評価を必要とします。
-
混同行列: 体系的な誤分類を特定します(例:問題解決がブレインストーミングと混同される)。これを使用して特徴の改良を導きます。
-
F1スコア: 適合率と再現率の調和平均、偽陽性と偽陰性のバランスを取ります。
-
推論レイテンシテスト*:
-
エンドツーエンドのレイテンシを測定します:データ取得→前処理→推論。知覚可能な遅延なしにリアルタイム分類を可能にするために、ウィンドウあたり<500 msを目標とします。
-
推論中のCPUとメモリ使用量をプロファイルします。バッテリー消耗が許容範囲内(<8時間あたり5%)に留まることを確認します。
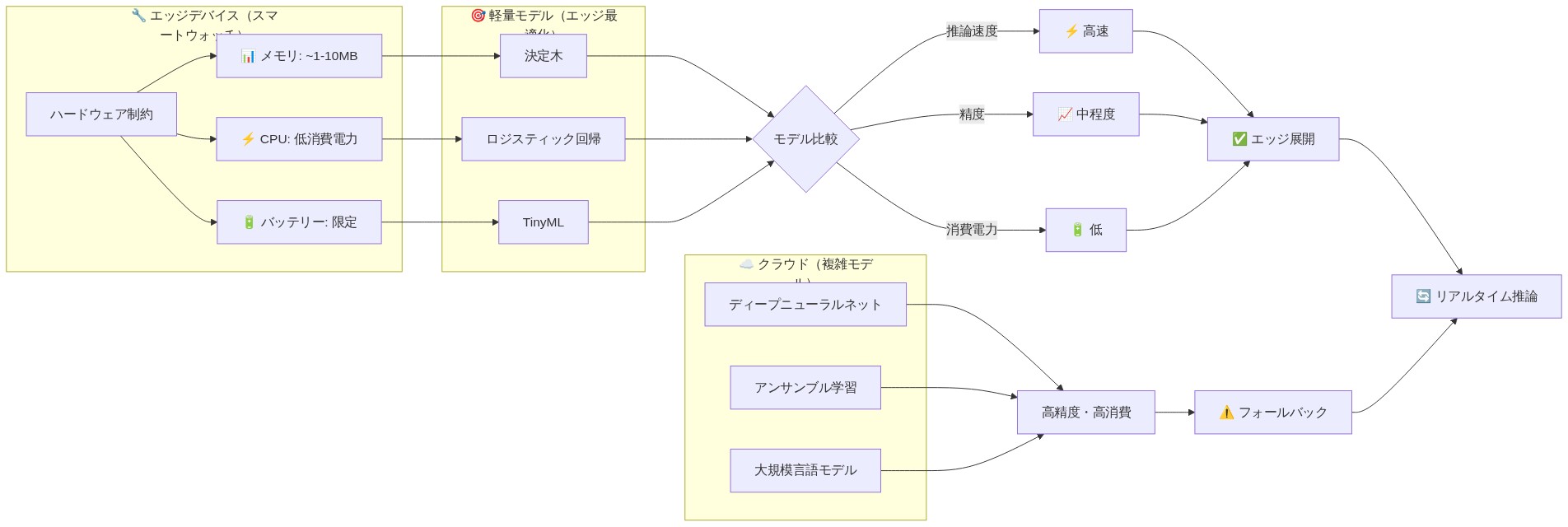
- 図8:エッジデバイス上の軽量機械学習モデルアーキテクチャ(出典:TinyML・エッジAI実装ガイドライン)*
スマートウォッチへのモデルの展開
-
モデル変換*:
-
訓練されたモデルをプラットフォーム固有の形式にエクスポートします:
- TensorFlow Lite(Android Wear、iOS): 重みを8ビット整数に量子化します。精度損失<1%でモデルサイズを75%削減します(Jacob et al., 2018)。
- Core ML(watchOS): Appleのネイティブ形式、Apple Silicon用の自動最適化。
- ONNX(クロスプラットフォーム): 中間表現、エクスポート後にプラットフォーム固有の形式に変換します。
-
量子化*:
-
浮動小数点重み(32ビット)を整数(8ビットまたは16ビット)に変換します。量子化はモデルサイズを10〜50 MBから2〜5 MBに削減し、推論を2〜4倍高速化します。
-
テストセットで量子化されたモデルの精度を検証します。許容される劣化は<2%です。
-
デバイス上の実装*:
-
バックグラウンドサービス(Android: WorkManager、iOS: BackgroundTasks)を開発します:
- 設定された間隔(例:10秒ごと)でセンサーをサンプリングします。
- 読み取りをウィンドウ(5〜10秒ブロック)にバッファリングします。
- 前処理(フィルタリング、正規化)を適用します。
- 推論を実行します。予測された活動と信頼度スコアを記録します。
- 結果をタイムスタンプとともにローカルに保存します。
-
効率的なバッファリングを実装します:処理前に10〜20の読み取りを蓄積して前処理オーバーヘッドを償却します。読み取りごとの処理と比較してバッテリー消耗を30〜50%削減します。
-
ユーザーインターフェース*:
-
信頼度スコア付きの現在の活動予測を表示します(例:「深い集中(92%)」)。
-
日次サマリーを表示します:各認知モードで費やした時間の円グラフ。
-
手動修正インターフェースを提供します:ユーザーは誤分類されたセグメントを再ラベル付けでき、モデル再訓練用のラベル付きデータを作成します。
-
フィードバックループ*:
-
修正されたラベルをローカルデータベースに保存します。
-
蓄積された修正(>50の新しいラベル付きサンプルがある場合)で週次モデル再訓練をトリガーします。
-
モデルをバージョン管理し、時間経過とともにパフォーマンスメトリクスを追跡します。
-
バッテリー最適化*:
-
バッテリー消費を監視します。消耗が24時間あたり10%を超える場合はサンプリング周波数を調整します。
-
適応サンプリングを実装します:勤務時間中は周波数を増やし、睡眠中は減らします。
-
現実的な日常シナリオ(オフィスワーク、会議、通勤)全体でテストし、エッジケースを特定します。
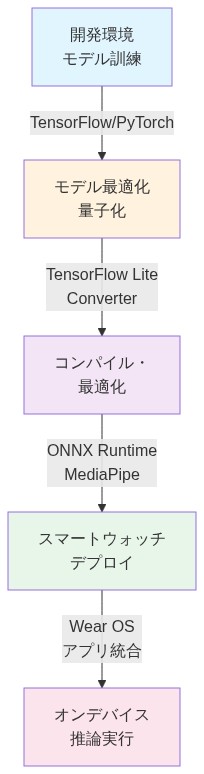
- 図10:スマートウォッチへのモデルデプロイメントワークフロー(出典:TensorFlow Lite・Wear OS開発ドキュメント)*
継続的学習による反復的改良
-
不確実性サンプリング*:
-
信頼度<70%の予測に手動レビューのフラグを立てます。
-
不確実なサンプルのラベル付けを優先します。これらはモデル改善のための最大の情報利得を提供します(Freeman, 1965)。
-
スケジュールされた再訓練*:
-
1〜2週間にわたってラベル付きデータを蓄積します。
-
履歴データ+新しいデータの組み合わせでモデルを再訓練します。ホールドアウトテストセットで評価します。
-
テストセットのパフォーマンスが>2%向上するか、推論レイテンシが削減されてパフォーマンスが維持される場合にのみ、更新されたモデルを展開します。
-
構造化されたログにモデルバージョンとパフォーマンスメトリクスを文書化します。
-
特徴エンジニアリングの反復*:
-
誤分類されたサンプルを分析します:失敗モードをターゲットとする新しい特徴を抽出します。
-
例:問題解決がブレインストーミングと混同される場合、持続的対断続的な動作パターンを捉える特徴を設計します。
-
ドメイン情報に基づく特徴を実験します:時間的自己相関(反復的なタイピングを捉える)、動作エントロピー(そわそわのランダム性を捉える)。
-
汎化テスト*:
-
多様なコンテキストでデータを収集します:異なる場所(オフィス、自宅、カフェ)、時間(午前対午後)、タスクタイプ(コーディング、執筆、分析)。
-
分布外データでモデルのパフォーマンスを評価します。精度が低下するコンテキストを特定します。
-
パフォーマンスが弱いコンテキストで追加の訓練データを収集します。
-
アンサンブルアプローチ*:
-
コンテキストごとに特化したモデルを訓練します(例:オフィスワーク対リモートワークの別々のモデル)。
-
重み付き投票を介して予測を組み合わせます。コンテキスト信頼度に基づいて重み付けします。
-
アンサンブル法は通常、単一モデルよりも精度を3〜7%向上させます(Kuncheva, 2014)。
-
失敗モードの文書化*:
-
誤分類の構造化されたログを維持します:タイムスタンプ、予測クラス、真のクラス、信頼度スコア、コンテキストメタデータ。
-
パターンを分析します:体系的な失敗は、特定のシナリオで特徴が欠落しているか訓練データが不十分であることを示します。
-
高頻度の失敗モードに対処するためにデータ収集を優先します。
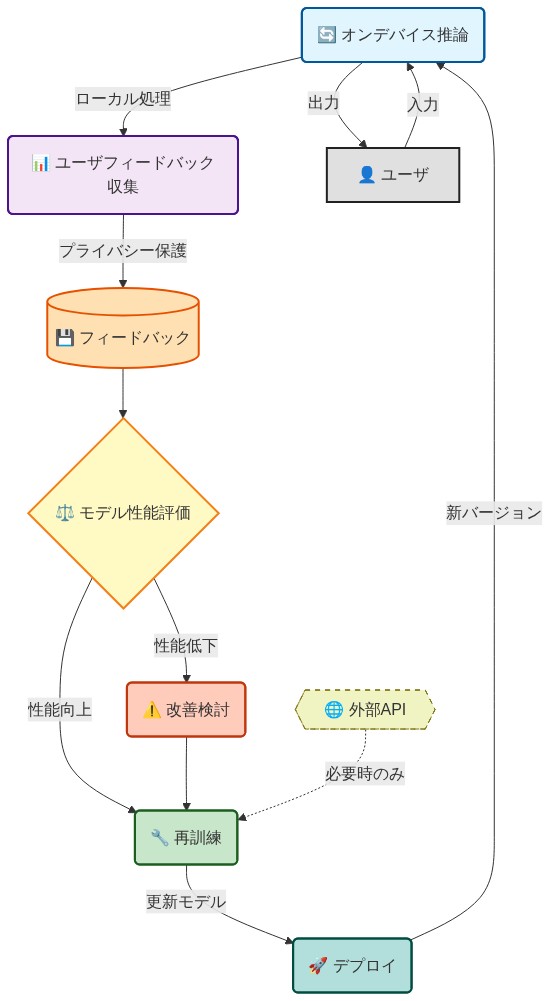
- 図12:継続学習による反復的モデル改善ループ(オンデバイス推論とプライバシー保護メカニズム)*
実用的な洞察の抽出
-
ダッシュボード設計*:
-
日次ビュー:認知モード全体の時間配分を示す積み上げ棒グラフ。
-
週次ビュー:各活動タイプのトレンドライン、パターンを特定します(例:コラボレーションの増加、深い集中の減少)。
-
時間別ヒートマップ:各認知モードが最も一般的な時間を視覚化します。
-
相関分析*:
-
活動分布と外部変数の間のピアソンまたはスピアマン相関を計算します:
- 睡眠時間(前夜)
- 運動(時間、強度)
- カフェイン摂取(タイミング、量)
- 会議数と時間
- タスクの複雑さ(主観的評価)
-
高い深い集中時間または低いコンテキスト切り替え頻度に関連する条件を特定します。
-
派生メトリクス*:
-
集中セッション時間: 中断されない深い集中期間の平均長。
-
コンテキスト切り替え頻度: 認知モード間の1時間あたりの遷移。
-
創造的対分析的比率: 分析作業に対するブレインストーミング/問題解決の時間。
-
コラボレーション強度: 勤務時間のパーセンテージとしての会議時間。
-
パフォーマンス最適化*:
-
ピークパフォーマンスウィンドウを特定します(例:午前9〜11時が最高の集中品質を示す)。
-
ピークウィンドウ中に深い集中作業をバッチ処理するようにスケジュールを再構築します。
-
介入(異なる環境、休憩スケジュール、タスクバッチング)を実験しながら、集中メトリクスへの影響を監視します。
-
A/Bテストを使用します:1週間介入を実施し、集中メトリクスを測定し、1週間元に戻し、比較します。
-
疲労検出*:
-
認知疲労の兆候について動作パターンとHRVを監視します:動作分散の減少、安静時心拍数の上昇、HRVの減少。
-
疲労指標をタスクパフォーマンスまたはエラー率(利用可能な場合)と相関させます。
-
介入をトリガーします:休憩、タスク切り替え、または作業負荷の軽減を提案します。
-
統合とエクスポート*:
-
生産性ツール(Toggl、RescueTime、Notion)との統合のために、標準形式(CSV、JSON)で活動ログをエクスポートします。
-
カレンダーと同期して、活動をスケジュールされた会議またはタスクブロックと相関させます。
-
個人分析または研究目的のためにデータポータビリティを有効にします。
-
目標設定と追跡*:
-
2〜4週間のデータ収集からベースラインメトリクスを確立します。
-
エビデンスに基づく目標を設定します:「毎日の深い集中時間を3時間から4時間に増やす」または「コンテキスト切り替え頻度を1時間あたり8回から5回に減らす」。
-
週次で進捗を追跡します。達成可能性と主観的幸福への影響に基づいて目標を調整します。
-
制限と注意事項*:
-
スマートウォッチベースの活動追跡は、認知活動の行動プロキシを捉えますが、認知そのものを直接捉えるわけではありません。相関は、追跡された行動が認知パフォーマンスを引き起こすことを意味しません。
-
動作パターン、生理学、タスクへの関与における個人差は、集団全体での汎化を制限します。
-
交絡変数(環境ノイズ、デバイスの位置、衣服)は測定誤差を導入します。解釈においてこれらを考慮してください。
-
長期的なモデルドリフト(数ヶ月にわたる行動の変化)は、定期的な再訓練と検証を必要とします。
スマートウォッチのセンサー機能を理解する:認知測定の基盤
あなたの手首には、すでに人間の認知を継続的に観測する装置が備わっています。スマートウォッチには加速度計、ジャイロスコープ、心拍数モニター、そして最近では皮膚電気活動センサーが搭載されており、それぞれが思考の身体的な現れをリアルタイムで覗く窓として機能しています。知識労働の最適化の未来は、これらのデバイスが何か深遠なものを捉えているという認識から始まります:精神的努力に対する身体の不随意的な反応です。
ネイティブ開発者APIまたはコンパニオンアプリケーションを通じて、生のセンサーストリームにアクセスしてください。サンプリングレートを徹底的に記録してください—高い周波数(100Hz以上)は、深い集中と浅い閲覧を区別する微細な動きを捉えますが、バッテリーコストがかかります。この忠実度と持続可能性の間の緊張関係は、持続可能なパフォーマンス追跡のより大きな課題を反映しています:燃え尽きることなく精度を保つことです。
まずベースライン署名を確立することから始めてください。異なる活動の30分間のセッションを記録してください—タイピングは、読書やジェスチャーベースのインタラクションとは根本的に異なる特徴的な加速度計パターンを生成します。データセットをCSV形式でエクスポートし、これをあなた個人の認知指紋ライブラリとして扱ってください。戦略的な洞察:あなたのスマートウォッチはすでに動きを測定しています;体系的なデータアクセスは、それを通知デバイスから知能観測所へと変換します。
ローカルファーストのデータアーキテクチャを実装してください。最初はすべてをデバイス上に保存し、プライバシーを後付けではなく基本的な設計原則として扱ってください。このアプローチは、個人の認知データが財務記録と同じくらい保護される新たな未来と一致しています—この変化は、組織が従業員の監視と自律性について考える方法を再構築するでしょう。

- 図14:センサーデータから実用的インサイトへの変換プロセス*
認知活動を観察可能なパターンに変換する:測定ギャップの橋渡し
ここにイノベーションのフロンティアがあります:知能そのものは測定不可能なままですが、知的作業を取り巻く行動は紛れもない身体的署名を生み出します。この再構成が可能性を解き放ちます。
深い作業は、持続的でリズミカルなタイピングパターンと最小限の余分な動きと相関します。読書は、時折のページめくりジェスチャーで区切られた全体的に低い動きとして現れます。問題解決は、そわそわのクラスター、手から顔への接触、変動する心拍数パターンを通じて明らかになります。ブレインストーミングセッションは特徴的なペーシング署名を示します。コラボレーションは、動きデータにおける急速なコンテキスト切り替えを表示します。
知能を直接測定しようとするのではなく、認知モードの分類法を作成してください:
- 深い集中:心拍数の安定性が高まった持続的で反復的な動き
- 分析作業:定期的な静止を伴う変動する動きパターン
- 創造的発想:より高いそわそわの頻度、ペーシング署名
- 学習/読書:最小限の動き、一貫した姿勢
- コラボレーション:急速な動きの遷移、社会的ペーシング
2週間にわたる制御された実験を設計してください。各活動カテゴリーを30分間のブロックで実行しながら、継続的に記録してください。タイムスタンプ、活動ラベル、1〜10スケールでの主観的な集中度評価でセッションに注釈を付けてください。同時に心拍変動(HRV)を追跡してください—新たな研究は、HRVが認知負荷と精神的回復力と強く相関することを示唆しており、持続可能な知的作業の代理指標となります。
このアプローチ全体の根底にある重要な仮定:知能追跡にはパーソナライズされたモデルが必要です。なぜなら、認知署名は特異的だからです。問題解決中のあなたのそわそわパターンは、同僚のそれとは異なります。この個性は、制限ではなく利点となります—あなたのスマートウォッチはあなたの知能を学習し、万能の生産性指標では不可能な超パーソナライズされた最適化を可能にします。
このパーソナライゼーションアプローチは、知識労働者が自分の認知データを所有し、企業の監視システムに引き渡すのではなく、自己最適化のためにそれを使用する未来も指し示しています。スマートウォッチは、コントロールではなく自律性のためのツールになります。
機械学習のためのセンサーデータの前処理:ノイズから信号への変換
生のセンサーストリームはノイズの不協和音です。あなたの課題:認知状態を明らかにする信号を抽出することです。
体系的なクリーニングを通じて連続データを変換してください。ヌル値を削除し、ドリフトを平滑化しながら急激な遷移を保持する適応移動平均を使用してノイズをフィルタリングしてください。連続ストリームを5〜10秒のウィンドウにセグメント化してください—この粒度は、時間的コンテキストを失うことなく認知活動のリズムを捉えます。
各ウィンドウから統計的特徴を抽出してください:すべての3つの加速度計軸にわたる平均、分散、標準偏差、最小値、最大値。高速フーリエ変換を使用して周波数領域の特徴を計算し、生データでは見えないリズミカルなパターンを識別してください—タイピングの周期的な性質、そわそわの不規則なリズム、深い読書の静止。ジャーク(加速度の変化率)のような派生特徴を生成し、驚愕反応と意図的なジェスチャーを区別する突然の動きを強調してください。
特徴を積極的に正規化してください。心拍数センサーの60〜100 bpmの範囲は、そうでなければg力で測定される加速度計データを支配し、人工的な階層を作り出します。複数のセンサーを組み合わせて認知状態の一貫した表現にする統一された特徴ベクトルを作成してください。
ウィンドウ境界を越えるパターンを失わないように、50%のオーバーラップを持つスライディングウィンドウを使用してください。視覚化を通じて前処理を検証してください—活動カテゴリー全体で特徴分布をプロットしてください。明確な分離が観察されるはずです:深い集中の特徴がブレインストーミングの特徴と明確にクラスター化されています。カテゴリーが大幅に重複している場合、特徴エンジニアリングには改良が必要です。
この前処理段階は、技術的必要性以上のものを表しています。それは知識労働全般に適用可能な原則を体現しています:ノイズからの信号抽出は情報時代の中核スキルです。ここで開発する技術—フィルタリング、正規化、パターン認識—は、測定しようとしている認知作業を反映しています。
制約のあるハードウェア上での分類モデルの構築:エッジでの知能
スマートウォッチは厳しい制約の下で動作します:限られたCPU、最小限のRAM、バッテリーの希少性。これらの制約は逆説的に、エレガントで効率的なソリューションへのイノベーションを推進します。
エッジ展開に適したアルゴリズムを選択してください。ランダムフォレストと勾配ブースティングは、解釈可能性を保ちながら表形式の特徴を効果的に処理します—モデルがある瞬間を深い集中として分類する理由を理解できます。複数のウィンドウにまたがる連続パターンの場合、時間的畳み込みネットワークまたは軽量な再帰アーキテクチャを検討してください。絶対に必要でない限り、深層ニューラルネットワークは避けてください;その不透明性は自分自身の認知を理解するという目標と矛盾します。
厳密な時間的検証を実装してください。ランダムサンプリングではなく、時系列でデータを分割してください—第1〜2週でトレーニング、第3週で検証、第4週でテスト。これにより、モデルが一般化可能な認知署名を学習するのではなく、時間的パターンを記憶するデータリークを防ぎます。
ベースラインモデルから始めてください:ロジスティック回帰、単純な決定木。複雑さを追加する前にパフォーマンスの下限を確立してください。クロスバリデーションを通じてハイパーパラメータを調整しますが、わずかな精度向上よりも解釈可能性を優先してください。理解できる92%正確なモデルは、95%正確なブラックボックスを上回ります。
全体的な精度ではなく、クラスごとの精度と再現率を使用して評価してください。活動カテゴリーは不均衡な表現を持つ可能性が高いです—おそらく深い集中が40%、コラボレーションが25%、学習が20%、ブレインストーミングが15%。常に「深い集中」を予測する単純な分類器は40%の精度を達成しますが、ゼロの洞察を提供します。混同行列を分析して、モデルがどの活動を混同するかを特定してください。深い集中と分析作業が高い混同を示す場合、それらの区別する特性を捉えるために特徴を改良してください。
スマートウォッチプラットフォームと互換性のあるTensorFlow LiteまたはONNX形式でモデルをエクスポートしてください。推論レイテンシを執拗にテストしてください—モデルは各ウィンドウを秒単位ではなくミリ秒単位で分類する必要があります。10秒のウィンドウを分類するのに500msかかるモデルは、リアルタイムフィードバックには役に立ちません。
この制約駆動型の設計哲学は、エッジインテリジェンス—クラウドサーバーではなく個人デバイスで行われる計算—が標準になる未来を指し示しています。ここで開発する効率性は、企業の約束ではなくローカル処理を通じてプライバシーと自律性が保持される世界を予測しています。
スマートウォッチへのモデルの展開:知能を家に持ち帰る
トレーニング済みモデルを軽量フォーマットに変換してください。TensorFlow Liteは、標準のTensorFlowと比較してモデルサイズを75%削減します。重みを32ビット浮動小数点から8ビット整数に量子化してください—これによりメモリフットプリントが75%削減され、通常は1%未満の精度しか犠牲になりません。Core MLとONNXはプラットフォーム固有の最適化を提供します。
データを継続的にサンプリングし、前処理を適用し、定期的な間隔—おそらく30秒ごと—で推論を実行するバックグラウンドサービスを開発してください。バッテリー消耗を最小限に抑えるために、バッチ処理の前に読み取りを蓄積する効率的なバッファリングを実装してください。継続的にサンプリングと処理を行う単純なアプローチは数時間でバッテリーを消耗させますが、インテリジェントなバッチ処理は実行時間を数日に延長します。
現在の活動分類、信頼度スコア(0〜100%)、および日次サマリーを表示するインターフェースを設計してください。手動修正メカニズムを含めてください—モデルがセグメントを誤分類した場合、すぐに再ラベル付けできます。これらの修正は、ラップトップでの再トレーニングを必要とせずに精度を継続的に向上させるフィードバックループを作成します。
正確なタイムスタンプで結果をローカルに保存してください。これにより、個人的な認知アーカイブ—精神活動の検索可能な履歴—が作成されます。数ヶ月にわたって、このアーカイブはパターン認識と最適化にとって非常に貴重になります。
バッテリー消費を執拗に監視してください。追跡システムがスマートウォッチの通常の動作よりも速くバッテリーを消耗させる場合、使用するには負担が大きすぎるツールを作成したことになります。システムが見えなくなるまで—無視できるオーバーヘッドを追加するだけで非常に効率的に動作するまで—サンプリング周波数、推論間隔、またはモデルの複雑さを調整してください。
多様な日常シナリオ全体でテストしてください:異なる場所、時間帯、タスクタイプ、ストレスレベル。エッジケースを特定してください—おそらくモデルは会議中や運動中に苦労します。これらのシナリオのための追加のトレーニングデータを収集し、継続的に拡大する認知モデルを作成してください。
この展開フェーズは、知識労働の未来のための原則を体現しています:ツールは意識的な注意を要求することなく能力を向上させるべきです。最高の生産性システムは、バックグラウンドでシームレスに動作するため、使用していることを忘れるものです。
継続的学習による反復的改良:静止ではなく進化
初期モデルは出発点であり、目的地ではありません。モデルが手動レビューのために低信頼度予測にフラグを立てる不確実性サンプリングを実装してください。55%の信頼度を持つ予測は精査に値します;95%の信頼度予測は信頼できます。
新しくラベル付けされたデータを組み込んだ週次モデル更新をスケジュールしてください。蓄積されたデータで再トレーニングし、新しいモデルのパフォーマンスを以前のバージョンと比較してください。時間の経過とともにメトリクスを追跡してください—精度は向上していますか?特定の活動カテゴリーは持続的な混同を示していますか?これらのパターンを文書化してください。
ドメイン知識から派生した新しい特徴を実験してください。時間的パターン:集中の質は時間帯によって変化しますか?環境要因:特定の場所はより深い作業と相関していますか?ストレス指標:心拍変動の上昇は集中の困難を予測しますか?一般化を改善するために多様なコンテキスト全体でデータを収集してください。
複数の専門モデルを組み合わせたアンサンブルアプローチを検討してください。おそらく、あるモデルは集中とコラボレーションの区別に優れており、別のモデルは創造的作業と分析的作業の専門です。アンサンブル予測は、解釈可能性を保ちながら単一モデルを上回ることがよくあります。
失敗モードを体系的に文書化してください。モデルが誤分類した場合、コンテキストを記録してください:時間帯、先行する活動、環境要因。これらの失敗パターンは、ターゲットを絞ったデータ収集を導きます。時間の経過とともに、認知システムのエッジケースと制限の包括的な理解を構築します。
定量化された自己コミュニティと認知科学研究に関与してください。新しい特徴エンジニアリングアプローチは、フロンティアで実験している実践者から生まれます。心拍変動パターン、皮膚コンダクタンスの変化、さらにはキーストロークダイナミクスさえも追加の信号を提供します。スマートウォッチはこれらすべてを直接測定しないかもしれませんが、他のデバイス(フィットネストラッカー、スマートリング)との統合により、認知観測所を拡大できる可能性があります。
この継続的学習アプローチは、人間の専門知識がどのように発展するかを反映しています:反復的改良、失敗分析、新しい知識の統合を通じて。あなたのスマートウォッチは認知学習システムになり、数ヶ月から数年にわたってあなたの知能の理解を向上させます。
実行可能な洞察の抽出:データから最適化へ
生の分類は解釈なしでは何の意味もありません。日次および週次の認知活動の分布を表示するダッシュボードを構築してください。精神的風景を視覚化してください:深い集中とコンテキスト切り替えにどれだけの時間を費やしていますか?この分布は日によってどのように変化しますか?
追跡された活動を外部要因と相関させてください:睡眠時間、運動、カフェイン摂取、会議密度、プロジェクト締め切り。個人的なパフォーマンス条件を発見してください。おそらく、8時間以上の睡眠の後の日に深い集中セッションが40%増加することに気づくでしょう。または、会議の多い日に午後の集中が60%低下することに。これらの相関関係は最適化のターゲットになります。
より深いパターンを明らかにする派生メトリクスを計算してください:
- 集中セッション期間:中断されない深い作業ブロックの平均長
- コンテキスト切り替え頻度:1日あたりの活動タイプ間の遷移
- 創造的対分析的比率:発想対実行に費やされた時間
- 認知疲労指標:精神的疲労を示唆する動きまたは心拍数の変化
- ピークパフォーマンスウィンドウ:集中の質がピークに達する時間帯
認知作業のための個人的なクロノタイプを特定してください。あなたは朝集中型の人ですか、それとも夕方発想型の人ですか?それに応じてスケジュールを構成してください。動きや心拍数の変化を通じて認知疲労を検出してください—そわそわが増加したりHRVが低下したりすると、脳は枯渇を知らせています。
影響を監視しながら介入を実験してください。異なる環境を試してください:コーヒーショップ対ホームオフィス対図書館。休憩スケジュールをテストしてください:25分ごとに5分間の休憩対90分ごとに15分間のより長い休憩。類似したタスクをバッチ処理対タスク切り替え。各実験は、あなたの認知を最適化する条件を明らかにするデータを生成します。
生産性ツール、カレンダーシステム、プロジェクト管理プラットフォームとの統合のためにデータをエクスポートしてください。認知データはインテリジェントなスケジューリングの基盤になります—ピークウィンドウ中に集中ブロックを自動的に提案し、低集中期間中に会議をバッチ処理します。
ベースライン測定に基づいてパーソナライズされた目標を設定してください。ベースラインが1日3時間の深い集中を示す場合、おそらく目標は4時間になります。コンテキスト切り替えが1日平均12回の遷移である場合、おそらく8回を目標にします。これらのエビデンスベースの目標は、任意の生産性指標をパーソナライズされた最適化ターゲットに置き換えます。
展望:個人インフラとしての知能トラッキング
このスマートウォッチ実験は、認知的自己認識が身体的フィットネストラッキングと同じくらい日常的になる未来を指し示している。ランナーがペースや心拍数を執拗に監視するように、知識労働者は集中力の質、認知負荷、精神的回復力を追跡するようになるだろう。
その影響は個人的な最適化をはるかに超えて広がる。組織は、監視(キーストローク監視、メール分析)を通じて生産性を測定することから、共有データインサイトを通じて従業員の認知的健康をサポートすることへとシフトするだろう。労働者は自分の認知データを所有し、それを使って最大限のアウトプットを引き出すのではなく、自分の知能を最適化する労働条件を交渉するようになる。
新興の神経技術—EEGヘッドバンド、ブレイン・コンピュータ・インターフェース—は、最終的に直接的な神経測定を提供するだろう。あなたのスマートウォッチベースのアプローチは、非侵襲的認知トラッキングの最前線を代表し、技術が進歩するにつれてスケールする原則と実践を確立している。
より深い洞察:知能は固定された特性ではなく、睡眠、ストレス、環境、タスク設計によって形作られる動的システムである。自分の認知を計測することで、あなたは生産性要求の受動的な受け手から、自分自身の精神的パフォーマンスの能動的な設計者へと変容する。あなたのスマートウォッチは、コントロールのためではなく自律性のためのツールとなる—雇用主の搾取ではなく、あなた自身の最適化に奉仕するデバイスである。
これが知識労働の未来である:自分自身の認知を意図的に最適化できるほど深く理解する労働者、意識的な注意を要求することなく能力を高めるツール、そして認知能力を搾取するのではなく認知的健康をサポートする組織。あなたのスマートウォッチはその始まりである。