
前置き
事前学習の成果と運用現場のギャップ
トランスフォーマーベースのモデルは、大規模な自己教師あり事前学習を通じて、縦断的な電子健康記録(EHR)の予測精度において改善を示しています。GT-BEHRTおよび関連アーキテクチャは、患者軌跡から大規模に分散表現を学習することで、再入院、死亡率、有害事象を含む臨床転帰の予測において測定可能な成果を達成しています。しかし、この実験室環境での性能は、根本的なメカニズムを隠蔽しています。すなわち、研究環境での性能と運用現場での成果の間に存在する体系的な乖離です。
-
主張:* 保留されたテストセットにおける高いベンチマーク精度は、臨床的有用性、運用可能性、または実世界のヘルスケアシステムでの採用を保証しません。
-
理論的根拠:* 事前学習の最適化は、統制された実験条件下での保留テストセットの性能を対象としています。これに対して、運用中のEHRシステムは、体系的な分布シフトの源泉に遭遇します。すなわち、(1)時間的データドリフト(モデル学習と運用展開の間に疾病有病率と治療プロトコルが進化する)、(2)学習データの仮定に違反する不規則な来院間隔と欠損値、(3)臨床コード基準の進化とEHRシステム移行に伴う特徴表現の変化、(4)純粋な予測最適化目標には存在しない推論レイテンシ要件、説明可能性要件、監査証跡要件を含む運用上の制約です。2019年から2021年のデータで学習されたモデルは、2024年の患者集団に遭遇し、その患者集団は実質的に異なる疫学的および治療的プロファイルを持ちます。さらに、臨床展開には透明性メカニズム(特徴帰属、信頼区間、故障モード文書化)が必要であり、これらは事前学習中に最適化されません。
-
経験的事例:* GT-BEHRTモデルが、保留されたコホートでの遡及的検証において30日再入院予測のための受信者動作特性曲線下面積(AUC)0.82を達成しているとします。病院の入院ワークフローに展開されると、モデルは以下に遭遇します。(1)学習データに存在しない稀な併存疾患の組み合わせを持つ患者部分集団、(2)新しいEHRベンダーへの移行に伴う診断および処置コード変更、(3)モデルの透明性と意思決定根拠に関する臨床医の懐疑心。展開から3ヶ月以内に、測定されたAUCは0.71に低下し、臨床採用は適格な入院の12%で停滞します。これは、運用上の摩擦と信頼障壁が予測性能の向上を上回ることを示しています。
-
運用要件:* 臨床展開前に、目標展開サイトからの見込みデータに対する基準性能を最低30日間の期間にわたって確立してください。AUCだけでなく、以下も測定してください。キャリブレーション(予測確率と観測度数の一致)、運用上の意思決定閾値下での偽陽性率、臨床ワークフロータイミングに対する予測レイテンシ、患者部分群(年齢、併存疾患負担、保険状況)で層別化された性能。臨床ワークフローへの統合前に、臨床医がモデル出力を独立した臨床判断に対して監査する必須のヒューマン・イン・ザ・ループ検証段階を実装してください。性能低下パターンを文書化し、モデル再学習または撤回のための事前決定された閾値を確立してください。
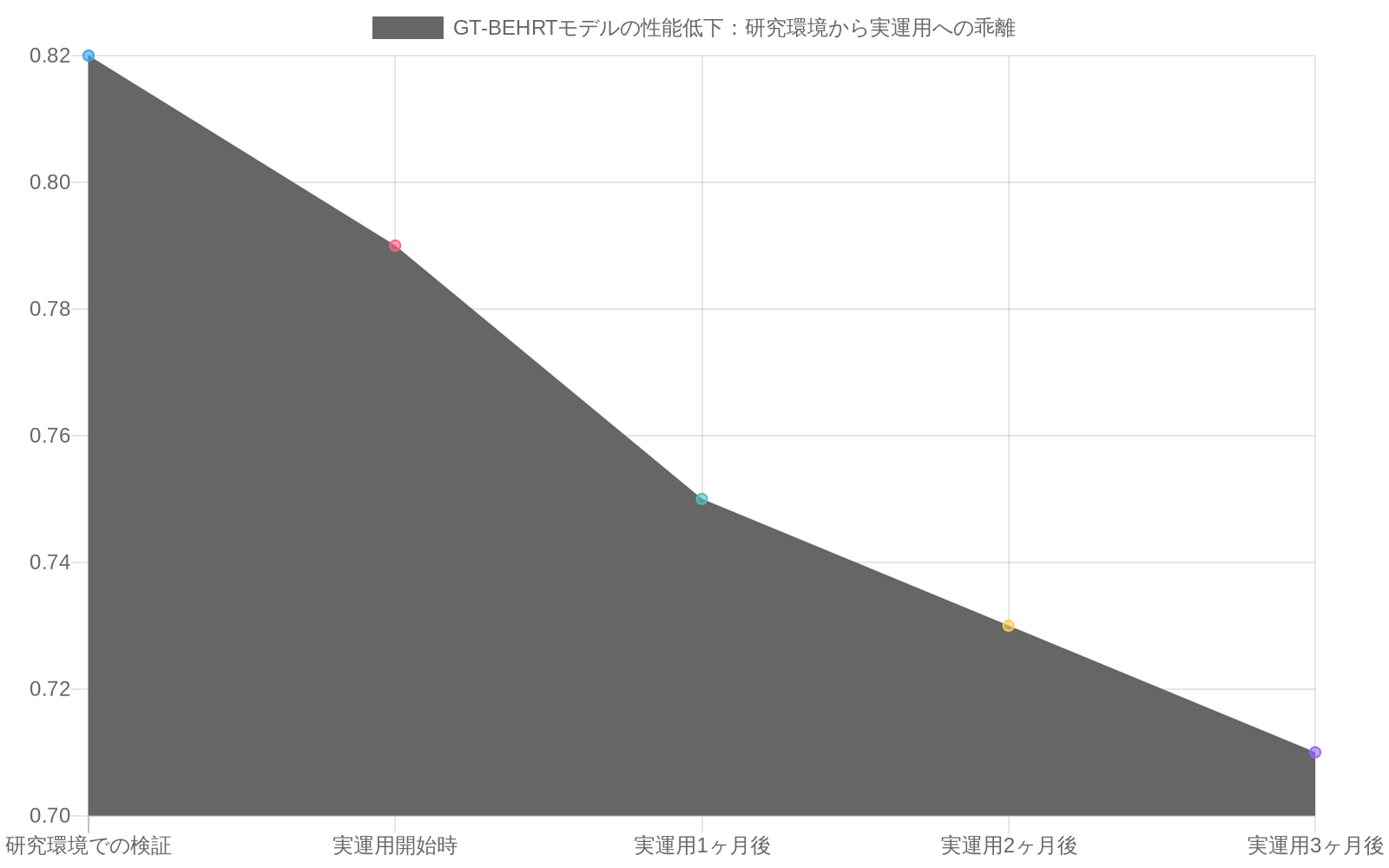
- 図2:実運用環境におけるAUC値の時間経過による低下(出典:記事内の事例データ - GT-BEHRT 30日再入院予測)*
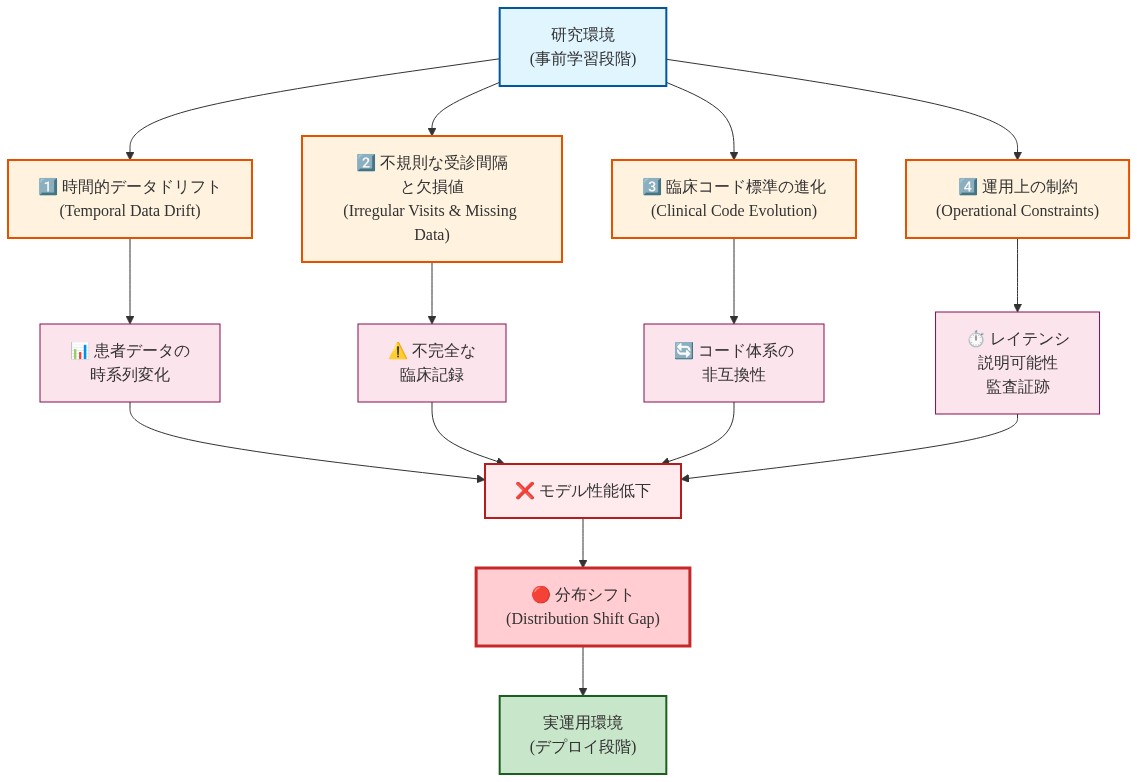
- 図3:実運用環境における4つの主要な分布シフト要因と性能低下メカニズム*
順序なし遭遇問題
ほとんどの現代的なEHRトランスフォーマーアーキテクチャは、各臨床来院を診断コード、処置コード、および医薬品注文の順序なしコレクションとして表現しています。この設計選択は計算複雑性を低減しますが、来院レベルの構造情報(単一の遭遇内で共起するコード間の意味的および因果的関係)を破棄します。
-
主張:* 来院内容の順序なしトークン化は、臨床的に意味のある関係パターンを破棄し、モデルが時間的注意メカニズムを通じてこの構造を非効率に回復することを要求します。
-
理論的根拠:* 単一の臨床遭遇内で、特定の診断、処置、および治療コードは、診断推論と治療決定を反映する一貫した臨床ナラティブを形成します。例えば、市中肺炎の診断(ICD-10:J18.9)、胸部X線検査の指示(CPT:71046)、およびベータラクタム系抗生物質の処方(RxNorm:7052)は、統一された臨床意思決定経路を表しています。順序なしトークン化スキームはこれら3つの信号を独立したものとして扱い、モデルが交差時間的注意メカニズムを通じてそれらの条件付き依存性を推論することを要求します。このアプローチは計算効率が低く、モデルが患者タイムライン全体にわたって真の因果関係と偶然の共起を区別する必要があるため、虚偽相関のリスクを導入します。対照的に、臨床医は領域知識を通じて来院内構造について推論します。この構造を無視するモデルは、同等の推論を回復するために実質的により多くの学習データと計算を必要とします。
-
経験的事例:* 患者が急性胸痛(ICD-10:R07.9)で来院し、12誘導心電図(CPT:93000)を受け、アスピリン(RxNorm:7052)を処方されます。順序なしモデルはこれら3つの信号を独立した信号としてトークン化し、モデルが注意を通じてアスピリン処方が胸痛とEKG所見の両方に条件付き依存していることを学習することを要求します。臨床的共起または階層的関係を表す明示的な来院内エッジを持つグラフ認識モデルは、この依存性構造を直接認識し、学習表現のノイズを低減し、急性冠症候群リスクまたは30日主要有害心臓イベントの下流予測のための信号を改善します。
-
運用要件:* 現在のEHRトランスフォーマー実装のトークン化スキームを監査してください。臨床来院が来院内構造情報なしで単一の時間的シーケンスにフラット化されている場合、ノードが臨床コードを表し、エッジが文書化された共起または臨床階層(例えば、主診断に従属する処置と医薬品)を表す来院グラフバリアントをプロトタイプしてください。収束率(目標検証性能に到達するまでの学習ステップ)と保留されたテストセットでの最終検証性能を測定してください。来院グラフモデルが同等の最終精度を維持しながら順序なしベースラインより20~30%高速に目標性能を達成する場合、アーキテクチャ修正は計算効率の根拠に基づいて正当化されます。性能向上が学習コホートで表現されていないサイトからの見込みデータで持続するかどうかを文書化してください。
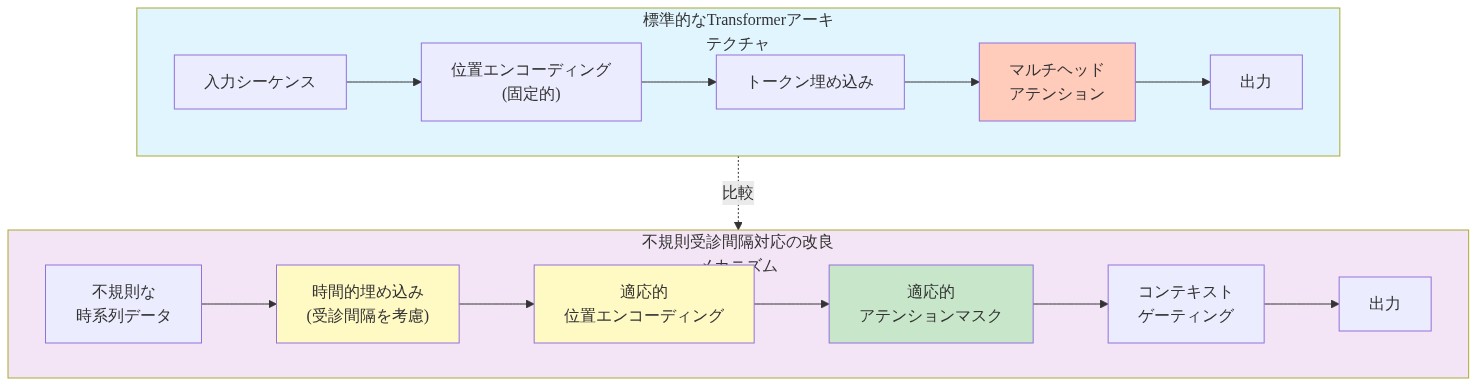
- 図5:不規則時系列データに対応するTransformerの改良メカニズム*
時間的構造のためのグラフトランスフォーマーメカニズム
グラフトランスフォーマーアーキテクチャは、来院レベルの構造的関係をモデル化しながら、縦断的な時間的推論能力を維持することが提案されています。標準的なアプローチは、個々の来院をサブグラフとして埋め込みます。ここでノードは臨床コードを表し、エッジは関係をエンコードし、交差来院注意メカニズムを適用して来院シーケンス全体のパターンを学習します。
-
述べられた主張:* 二重レベル分解(来院内グラフ構造+来院間トランスフォーマー注意)は、フラットシーケンスモデルよりも臨床的複雑性をより効果的にキャプチャします。
-
理論的根拠と仮定:* この主張は2つの基礎的仮定に基づいています。(1)臨床来院は順序なしトークンコレクションではなく構造化イベントを構成する、および(2)学習問題は2つの分離可能なサブタスクに分解される。これらの仮定の下で、局所グラフ畳み込みは来院内コード関係を解決し、トランスフォーマー注意は来院間の時間的依存性を解決します。この因数分解は、O(V × C²)からO(V × C + V²)への理論的複雑性低減をもたらします。ここでVは来院数を示し、Cは来院あたりの平均臨床コード数を示します(Vaswani et al., 2017; Kipf & Welling, 2017)。臨床的には、これは仮説的な2段階の医師推論プロセスを反映しています。(a)単一の遭遇内での所見の統合、その後(b)その統合を縦断的患者文脈に統合する。
-
検証を要する重要な仮定:*
-
来院レベルのコード共起パターンは、別個のグラフ学習を正当化するのに十分に安定している。
-
来院間で学習された注意重みは、見たことのない患者軌跡に一般化される。
-
複雑性低減は、疎い来院グラフでの過小適合ではなく、改善された一般化に変換される。
-
説明的事例:* GT-BEHRTは、臨床コードがノードとして機能し、来院内の共起がエッジを定義する来院レベルグラフを構築します。トランスフォーマー層は、その後、来院埋め込みのシーケンス上で動作します。6ヶ月にわたる3つの来院を持つ患者の場合、モデルは最初にグラフ畳み込みを通じて来院固有のコード相互作用を学習し、その後、注意を通じて来院レベルの要約が時間的にどのように進化するかを学習します。この2段階構造は、(a)どのコードが来院レベルの表現を駆動するか、および(b)予測時にどの先行来院が最高の注意重みを受け取るかの検査を許可します。しかし、この解釈可能性の利点は、学習された注意パターンが臨床的に意味のある時間的依存性に対応するという仮定に基づいており、この仮定はまだ査読済みの縦断的EHR研究で検証されていません。
-
運用監視要件:* 展開には、(a)来院内グラフ密度(来院あたりの平均エッジ、学習データから事前に定義された予想範囲を含む)および(b)来院間注意集中度(来院間の注意重みのエントロピー)を追跡するための計測が含まれるべきです。異常(密度の急激な低下や単一来院への注意崩壊を含む)は、データ品質低下またはモデルドリフトを示す可能性があります。推奨アラート閾値:ローカルデータでの検証を保留して、ベースラインに対する月次ベースで15%を超えるグラフ密度低下。
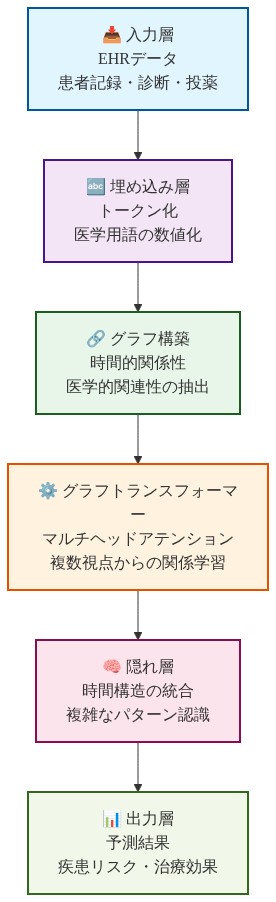
- 図7:GT-BEHRTのアーキテクチャと情報フロー*
実装と運用パターン
EHRシステムでのグラフトランスフォーマーモデルの本番展開は、研究環境に存在しない技術的および規制上の制約を導入します。これらの制約は、推論レイテンシ、メモリ消費、監査可能性、および臨床ワークフロー要件への準拠にわたります。
-
述べられた主張:* グラフトランスフォーマー推論レイテンシとメモリ要件は、明示的なアーキテクチャ最適化なしに臨床ワークフロー許容度を頻繁に超過します。
-
経験的根拠と制約:* 最適化されていない来院グラフ上の完全注意は、患者あたり推論時間5~10秒を要する可能性があります。臨床意思決定支援ワークフローは、通常、ワークフロー中断を回避するために1秒未満のレイテンシを要求します(Hripcsak & Heitjan, 2002)。さらに、FDA医療機器ソフトウェアガイダンス(FDA, 2021)および機関準拠要件を含む規制枠組みは、モデル予測が再現可能、監査可能、および入力データに追跡可能であることを要求します。グラフトランスフォーマーは、エンドツーエンドで注意パターンを学習し、ルールベースまたは透明な特徴エンジニアリングアプローチと比較して監査可能性の課題を提示します。学習された注意重みは、本質的に臨床的に解釈可能な意思決定ルールに対応しません。
-
具体的な運用シナリオ:* 病院システムがICU入院ワークフローでの敗血症リスク予測のためにGT-BEHRTを実装します。単一患者クエリ下での初期レイテンシテストは患者あたり8秒の推論をもたらします。本番環境では、入院ダッシュボードにアクセスする複数の臨床医からの同時リクエストがキュー遅延を作成し、臨床的有用性を低減します。実装チームはこれに対処します。(a)先行する90日間の来院埋め込みをキャッシング(グラフ構築オーバーヘッドを低減)、(b)注意重み行列にint8量子化を適用(メモリ帯域幅を低減)、および(c)リアルタイムスクリーニング用の軽量グラフトランスフォーマーバリアントを展開(200msレイテンシ、低感度)、完全モデルはバッチ処理用に予約(高感度、8秒レイテンシ)。この2層戦略は、完全モデル容量をオフライン危険層別化のために保持しながら、リアルタイムダッシュボードに対して200msレイテンシを達成します。
-
実装の前提条件:* この最適化戦略は以下を要求します。(1)軽量バリアント用の許容感度特異度トレードオフの事前定義、(2)リアルタイムおよびバッチ推論パイプラインの両方をサポートするインフラストラクチャ、および(3)異なる動作特性を持つ2つのモデルからのアラートを管理するための臨床ガバナンスプロセス。
-
展開のための実行可能な要件:* 本番ローンチ前に、現実的な同時負荷下(例えば、10~50の同時患者ルックアップ)でレイテンシプロファイリングを実施してください。臨床ワークフローに合わせた厳密なレイテンシ予算を確立してください。通常、リアルタイム意思決定支援ダッシュボードの場合は500ミリ秒です。最適化されていないモデルレイテンシがこの予算を超過する場合、以下の順序で優先順位を付けてください。(1)モデル圧縮(量子化、プルーニング)、(2)埋め込みキャッシング戦略、(3)2層推論アーキテクチャ。軽量バリアントと完全バリアント間のレイテンシ精度トレードオフを臨床ステークホルダーとガバナンス委員会に明示的に文書化してください。95パーセンタイル推論レイテンシ、キャッシュヒット率、および軽量バリアントと完全バリアント間のモデル一致を追跡する監視ダッシュボードを確立してください。レイテンシが低下するか、モデル不一致が事前定義された閾値(例えば、高リスク患者での予測不一致>5%)を超過する場合のエスカレーション手順を定義してください。
測定と検証プロトコル
臨床機械学習における翻訳的成功は、集計ベンチマーク性能を超えた評価指標を必要とします。医療配置環境は特定の要件を課します。確率的キャリブレーション(予測と観測イベント頻度の一致)、人口統計学的および臨床的部分集団全体での公平な性能、時間的データドリフトへの堅牢性です。標準的なテストセット受信者動作特性曲線下面積(AUC)は必要ですが、これらの目的には不十分です。
キャリブレーション評価
-
定義的前提:* キャリブレーションとは、予測確率と経験的頻度の一致を指します。モデルが確率 p に割り当てられたすべてのインスタンスの中で、イベントがおよそ p × 100% の時間で発生する場合、モデルは適切にキャリブレーションされています(Guo et al., 2017)。
-
制限事項:* 高い判別性能(AUC)はキャリブレーションを保証しません。モデルはAUC = 0.80を達成しながら、確率範囲全体でリスクを体系的に過大評価または過小評価する可能性があります。これはAUCが予測のランク順序を測定し、確率精度ではないために発生します。
-
測定プロトコル:*
-
予測確率によって予測を十分位数に分割します(0~10%、10~20%、…、90~100%)。
-
各十分位数について、観測イベント率を計算します(イベント数 / 十分位数内の総インスタンス数)。
-
期待キャリブレーション誤差(ECE)を計算します。予測率と観測率の平均絶対差を十分位数サイズで重み付けしたもの(Niculescu-Mizil & Caruana, 2005)。
-
閾値:ECEは0.05を超えてはいけません(つまり、予測は観測率の5パーセンテージポイント以内である必要があります)。
-
臨床的帰結:* キャリブレーション不良は臨床意思決定に直接影響します。イベント発生率が40%である場合に70%のリスクを予測するモデルは、不要な介入をトリガーし、コストと患者負担を増加させながら、比例した利益をもたらしません。
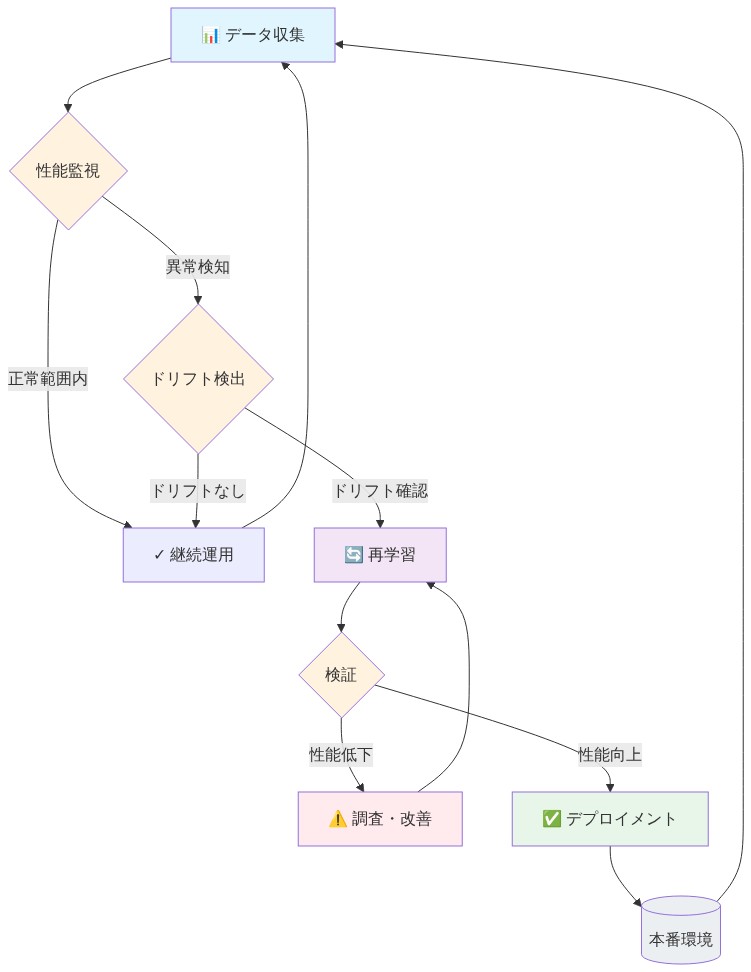
- 図11:運用環境における継続的監視と再学習サイクル*
層別性能評価
-
定義的前提:* 部分集団性能とは、人口統計学的または臨床的層内で個別に測定されたモデル精度、キャリブレーション、および判別を指します。層全体での性能の相違は、配置における潜在的な不公正を示します。
-
制限事項:* 集計指標は部分集団の失敗を隠します。全体的にAUC = 0.80を達成するモデルは、少数派部分集団ではAUC = 0.65で性能を発揮する可能性があり、これは臨床的に有意な低下を表しており、要約統計では見えません。
-
測定プロトコル:*
-
臨床的および人口統計学的要因に基づいて事前に層を定義します。年齢グループ(例:18~65、65~85、>85)、人種/民族(EHRに記載されている通り)、併存疾患負担(例:Charlsonインデックス三分位数)、および疾患特異的コホート(例:慢性腎臓病患者)。
-
各層について独立してAUC、キャリブレーション誤差、感度、特異度を計算します。
-
層別テーブルで結果を報告します。全体コホートAUCより0.05以上低いAUC、またはECE ≥0.10を持つ層にフラグを立てます。
-
仮定:各層内に安定した推定値をもたらすのに十分なサンプルサイズが存在します(層あたり最小100イベント推奨;Lalkhen & McCluskey, 2008)。
-
臨床的帰結:* 85歳以上の高齢患者は、病院入院の増加する割合を占めます。再入院予測モデルがこのグループでリスクを体系的に過大評価する場合、退院計画は不必要に保守的になり、入院期間を延長し、合併症を増加させます。

- 表1:リスク要因と軽減策の対応表(医療AI システムのリスク管理フレームワーク)*
閾値特異的動作特性
-
定義的前提:* 感度と特異度は、予測確率に適用される決定閾値に依存します。臨床有用性は、選択された特定の閾値に依存し、これは配置環境における偽陽性対偽陰性のコスト便益トレードオフを反映する必要があります。
-
制限事項:* AUCとキャリブレーションは最適な動作点を指定しません。モデルは適切にキャリブレーションされていても、感度を優先する閾値で適用される可能性があります(すべての高リスク症例をキャッチする)が、許容できない偽陽性率の代償があります。またはその逆です。
-
測定プロトコル:*
-
臨床的に関連のある閾値を事前に特定します(例:ICU入院の予測リスク30%、早期介入の50%)。
-
各閾値について、感度(真陽性率)、特異度(真陰性率)、陽性予測値(PPV)、陰性予測値(NPV)を計算します。
-
決定曲線を構築します(Vickers & Elkin, 2006)。閾値範囲全体での正味利益を示します。
-
選択された閾値での動作特性を報告します。閾値選択の臨床的根拠を文書化します。
-
臨床的帰結:* ICU入院の30%リスク閾値は一般内科病棟には適切ですが、緩和ケアユニットには不適切な場合があります。閾値選択は明示的で臨床的に正当化される必要があります。

- 図13:研究から臨床運用への移行ロードマップ(成功基準と意思決定ゲート付き)*
前向き検証と監視
-
定義的前提:* 前向き検証は、モデルトレーニング後に収集されたデータ、実際の配置環境でのモデル性能を測定します。これは履歴データを使用する後ろ向きテストセット評価とは異なります。
-
制限事項:* 後ろ向きテストセット性能は、データリーケージ、時間的傾向、および分布シフトのため、前向き性能を過大評価することが多いです(Rajkomar et al., 2018)。EHRデータは非定常性を示します。コーディング慣行は進化し、患者集団はシフトし、臨床ワークフローは変わります。
-
測定プロトコル:*
-
前向き監視スケジュールを確立します。キャリブレーション、層別AUC、閾値特異的動作特性を四半期ごと(または配置ボリュームが高い場合はより頻繁に)測定します。
-
保留された前向き検証セットを維持します。モデル配置後に収集され、モデル更新に使用されないものです。
-
前向き指標をベースライン(テストセット)指標と比較します。AUCで0.05以上、キャリブレーション誤差で0.10以上の低下にフラグを立てます。
-
EHRコーディング、患者集団、または臨床ワークフローの変化を文書化します。これは性能変化を説明する可能性があります。
-
性能低下が連続する2つの監視サイクルにわたって持続する場合、モデル再トレーニングをトリガーします。
-
臨床的帰結:* 配置時に適切に性能を発揮するモデルは、患者集団がシフトするか、コーディング慣行が変わるにつれて、数ヶ月にわたって低下する可能性があります。前向き監視がなければ、臨床転帰が悪化するまで低下は検出されません。
リスクと軽減戦略
グラフトランスフォーマーアーキテクチャは、標準ニューラルネットワークとは異なる特定の失敗モードを導入します。これらのモードはしばしば静かです。モデルは不確実性や低下を信号することなく、自信を持った予測を生成します。
アテンション機構の失敗モード
-
定義的前提:* トランスフォーマーのマルチヘッドアテンションは、異なる入力要素(この場合、以前の臨床訪問)の重要性を重み付けすることを学習します。アテンション重みはすべての訪問にわたって正規化され、確率分布を生成します。
-
失敗モード—アテンション崩壊:* アテンション機構は、(a)すべてのアテンションが単一の訪問に集中する(例えば、最も最近の訪問)、または(b)アテンションがすべての訪問にわたって均一になり、事実上時間的構造を破棄する、という退化した解に収束する可能性があります。両方の結果は、複雑な時間的依存性をキャプチャするモデルの能力を低下させます。
-
機構的説明:* アテンション崩壊は、最適化ランドスケープが単純な解を優先する場合に発生します。単一の最近の訪問がアウトカムの高い予測力を持つ場合、勾配降下は、その訪問が90%以上のアテンション重みを受け取る解に収束する可能性があり、モデルは以前の訪問を無視します。これは局所的に最適ですが、臨床的には問題があります。疾患軌跡に関する情報を破棄します。
-
検出プロトコル:*
-
各アテンションヘッドについて、訪問全体のアテンション重み分布のエントロピーを計算します。H = −Σ(w_i × log(w_i))。ここで、w_i は訪問 i のアテンション重みです。
-
閾値:エントロピーは臨床的に合理的な範囲内に収まる必要があります(例えば、典型的な10訪問シーケンスの場合0.3~0.9ナット)。エントロピー <0.3は単一訪問への崩壊を示します。エントロピー >0.9はほぼ均一なアテンションを示します。
-
検証セット全体でエントロピーを監視します。予測の10%以上が崩壊したアテンションを示す場合、アラートを出します。
-
仮定:合理的なエントロピー範囲は文脈に依存し、特定のEHRデータセットとタスクで調整される必要があります。
-
軽減:*
-
トレーニング中にアテンションエントロピーを正則化します(中程度のエントロピーを促進するペナルティ項を追加)。
-
アテンション可視化ダッシュボードを実装します。崩壊したアテンションを持つ予測に手動レビューのフラグを立てます。
-
アブレーション研究を実施します。最高アテンション訪問を削除して再予測します。予測が劇的に変わる場合、アテンション崩壊が起こっている可能性があります。
グラフ畳み込みでの過度な平滑化
-
定義的前提:* グラフ畳み込み層は、隣接ノード(訪問)からの情報を集約します。深いアーキテクチャ(多くの層)では、繰り返される集約により、ノード埋め込みが類似の値に収束し、判別情報が失われる可能性があります。
-
失敗モード—過度な平滑化:* k層のグラフ畳み込み後、埋め込みはすべての訪問にわたってますます類似になります。層10~15までに、モデルは異なる訪問タイプまたは時間的パターンを区別する能力を失う可能性があります。これは非常に深いフィードフォワードネットワークの情報損失に類似しています。
-
機構的説明:* 各グラフ畳み込み層は、隣接する埋め込みの重み付き平均として新しいノード埋め込みを計算します。繰り返される平均化により、埋め込みはグローバル平均に収束し、局所構造を消去します。これはグラフニューラルネットワーク文献で十分に文書化されています(Li et al., 2018)。
-
検出プロトコル:*
-
各層深度で異なる訪問の埋め込み間のペアワイズコサイン類似度を計算します。
-
層深度の関数として検証セット全体での平均類似度を追跡します。
-
閾値:平均類似度は0.85を超えてはいけません(実質的な埋め込み発散を示す)。層kで平均類似度 >0.85の場合、過度な平滑化が起こっている可能性があります。
-
仮定:閾値値は経験的に導出され、特定のアーキテクチャとデータセットで検証される必要があります。
-
軽減:*
-
グラフ深度を3~5層に制限します。より深いアーキテクチャは性能向上によって正当化されず、過度な平滑化リスクを増加させます。
-
スキップ接続(残差リンク)を層間に実装して、初期層情報を保持します。
-
層正規化を使用して、深度全体で埋め込み大きさを安定させます。
稀な訪問パターンでの分布外予測
-
定義的前提:* EHRデータはロングテール分布を示します。一般的な診断と訪問パターンはトレーニングデータで十分に表現されていますが、稀な状態と異常なシーケンスはまばらです。一般的なパターンでトレーニングされたモデルは、稀なパターンに遭遇する場合、信頼できない予測を生成する可能性があります。
-
失敗モード—静かな分布外エラー:* モデルが稀な訪問シーケンス(例えば、稀な遺伝的障害を持つ患者)に遭遇する場合、一般的な状態で学習されたパターンから外挿する可能性があります。モデルはトレーニング分布外で動作しているにもかかわらず、自信を持った予測を生成します。臨床医は予測が信頼できないという信号を持ちません。
-
機構的説明:* ニューラルネットワークはトレーニング分布外で自信を持って外挿することが知られています(Hendrycks & Gimpel, 2017)。主に一般的な状態でトレーニングされたモデルは、これらの状態に最適化された埋め込みとアテンションパターンを学習します。稀な状態に適用される場合、これらの学習されたパターンは適用されない可能性がありますが、モデルはこの不一致を信号するメカニズムを持ちません。
-
検出プロトコル:*
-
トレーニングセットに対する各テストインスタンスの埋め込み空間距離メトリクスを計算します。具体的には、各テストインスタンスについて、トレーニングセット内のk最近傍までの距離を計算します(例えば、k=5)。
-
閾値:最近傍までの距離がパーセンタイル閾値を超える場合(例えば、トレーニングセット距離の95パーセンタイル)、インスタンスを分布外としてフラグを立てます。
-
仮定:分布外インスタンスは埋め込み空間距離で識別可能です。この仮定は学習された埋め込みに対して合理的ですが、保証されません。
-
保留された検証セットで閾値を交差検証して、許容可能な感度と特異度を達成することを確認します。
-
軽減:*
-
不確実性定量化を実装します。アンサンブル方法またはベイズアプローチを使用して予測信頼度を推定します。低信頼度予測に手動レビューのフラグを立てます。
-
稀な疾患コホートのレジストリを維持します。これらのコホートで四半期ごとにターゲット検証を実施します。
-
フィードバックループを確立します。臨床医が不正確な予測にフラグを立てます。これらのインスタンスは再トレーニングデータセットに追加され、類似の稀なパターンの合成例で拡張されます。
-
閾値を設定します。単一四半期で稀な疾患コホートの予測の5%以上が不正確としてフラグが立てられた場合、配置を一時停止し、拡張データでモデルを再トレーニングします。
データドリフトと時間的低下
-
定義的前提:* データドリフトとは、時間経過に伴う入力特性またはアウトカムの分布の変化を指します。EHR環境では、ドリフトはコーディング慣行の進化、患者集団の変化、臨床ワークフローのシフトのため発生します。
-
失敗モード—静かな性能低下:* 配置時に適切に性能を発揮するモデルは、EHRデータ分布がシフトするにつれて数ヶ月にわたって低下する可能性があります。体系的な監視がなければ、この低下は臨床転帰が悪化するまで検出されません。
-
機構的説明:* 機械学習モデルはデータのスナップショットでトレーニングされます。データ分布が変わる場合—例えば、病院が新しい診断コーディング基準を採用する、または患者集団が高齢化する場合—モデルの学習されたパターンはもはや適用されない可能性があります。これはランダムノイズとは異なります。基礎となる分布の体系的な変化です。
-
検出プロトコル:*
-
前向き監視を実装します(上記の測定と検証プロトコルセクションで説明)。
-
さらに、特性レベルのドリフト統計を計算します。各入力特性(例えば、年齢、診断コード)について、最近のデータ(過去3ヶ月)の分布をトレーニングデータの分布と比較します。Kolmogorov-Smirnovテストまたは母集団安定性指数(PSI)を使用してドリフトを定量化します。
-
閾値:PSI >0.25は実質的なドリフトを示します(Naeem et al., 2020)。
-
ドリフトのソース(例えば、コーディング慣行の変化、集団シフト)を文書化して、再トレーニング決定を知らせます。
-
軽減:*
-
再トレーニングスケジュールを確立します。最近のデータで四半期ごとにモデルを再トレーニングするか、ドリフトが検出された場合はより頻繁に行います。
-
ドメイン適応技術を使用して、既知のドリフトソースに対してモデルを堅牢にします(例えば、コーディング慣行の変化)。
-
モデルのバージョン管理を維持します。比較とフォールバック用に古いモデルを保存します。
監視とエスカレーションフレームワーク
-
運用プロトコル:*
-
キャリブレーション誤差、層別AUC、アテンションエントロピー、埋め込み空間距離メトリクス、特性レベルのドリフト統計を追跡する監視ダッシュボードを確立します。
-
各メトリクスのアラート閾値を設定します(特定の閾値は上記で提供)。
-
エスカレーションパスウェイ:(1)アラートトリガー → (2)臨床および技術チームによる手動レビュー → (3)根本原因分析 → (4)再トレーニング、閾値調整、または配置変更の決定。
-
規制遵守と継続的改善のため、すべてのアラートと決定を監査ログに文書化します。
-
仮定:* 根本原因分析を実施し、モデル更新に関する情報に基づいた決定を下すために、配置組織内に十分な技術的および臨床的専門知識が存在します。この仮定はすべての医療設定で成立しない可能性があり、明示的に検証される必要があります。
結論と移行計画
グラフトランスフォーマーは電子カルテモデリングにおいて測定可能な技術的優位性を示しています。具体的には、訪問レベルの構造と二重レベルの時間的依存性をエンコードする能力です。しかし、ベンチマーク性能から臨床導入への移行は、文献において本質的に過度に単純化されています。翻訳的成功には、ベンチマークメトリクスだけでは評価できない運用上の制約、公平性特性、および障害モードの明示的な検証が必要です。
理論的および運用上の前提条件
-
事前学習の利得は導入環境に自動的には転移しません。* ベンチマーク改善(例えば、保留されたテストセットでのAUROC向上2~5%)は、制御されたデータ分布と評価プロトコルの下での性能を反映しており、本番環境の条件とはめったに一致しません。見落とされがちですが、前向き検証(ここでは、モデル完成後に収集された時間的に保留されたデータ上での評価であり、実際の臨床ワークフロー制約下での評価)は、統合前に新しいベースラインを確立する必要があります。この前提条件は、異なる施設または時期からのデータで評価された場合の電子カルテモデルにおける性能低下の文献化された事例によって支持されています(Rajkomar et al., 2018; Gianfrancesco et al., 2020)。
-
訪問レベルの構造は臨床的かつ計算的要件の両方です。* 電子カルテデータの階層的組織(患者→入院/遭遇→訪問→臨床イベント)は臨床ワークフローと意思決定の粒度を反映しています。この構造をトークンシーケンスに平坦化するモデルは、解釈可能性を失い、訪問固有の臨床文脈を捉えられない可能性があります(例えば、一緒に注文された検査パネル、薬剤調整イベント)。現在のモデルがこの階層を明示的に保持しているか、注意メカニズムを通じて暗黙的に再構成しているかを監査してください。前者はより検証可能で臨床的に防御可能です。
-
二重レベル学習(訪問内+訪問間)はモデルの脆弱性を低減し、解釈可能性を向上させます。* 訪問内学習は単一の臨床遭遇内の依存性を捉えます(例えば、どの診断と処置が共起するか)。訪問間学習は縦断的軌跡を捉えます(例えば、疾患進行、治療反応)。GT-BEHRTがそのグラフ構造を通じて試みるように、この分離を強制するアーキテクチャは、これらのレベルを混同するエンドツーエンド注意メカニズムよりも、欠落データに対してより堅牢であり、臨床説明に対してより適切です。
交渉の余地のない導入基準
臨床採用前に、3つの測定可能な特性を検証する必要があります。
-
本番負荷下でのレイテンシー。 推論時間は臨床ワークフローと互換性がある必要があります。リアルタイム意思決定支援(例えば、入院時)の場合、レイテンシーは2~5秒を超えてはいけません。バッチ処理(例えば、夜間リスク階層化)の場合、レイテンシーはそれほど重要ではありませんが、予測可能である必要があります。代表的な患者コホート全体で、グラフサイズの変動(疎な対密な患者履歴)を考慮して、50パーセンタイル、95パーセンタイル、99パーセンタイルでレイテンシーを測定してください。
-
予測期間とサブグループ全体での較正。 較正(予測確率と観測頻度の一致)は臨床意思決定に不可欠です。高いAUROCを持つが較正が不十分なモデルは、リスクを体系的に過大または過小評価し、不適切な臨床行動につながります。予測期間(例えば、7日、30日、90日の再入院)と患者サブグループ(年齢、併存疾患負担、稀な診断、保険状況)別に較正分析を階層化して、体系的なバイアスを検出してください。
-
人口統計学的および臨床的階層全体での公平性検証。 ここでの公平性は、保護属性(人種、民族、性別、年齢)および臨床的に関連するサブグループ(稀な診断、低リソース設定)全体での実質的な性能格差の不在として運用的に定義されます。単一のメトリクスは公平性のすべての側面を捉えないため、複数のメトリクス(例えば、人口統計学的パリティ、等化オッズ、グループ内較正)を使用して公平性を測定してください(Obermeyer et al., 2019; Mitchell et al., 2019)。
体系的な監視が必要な無音障害モード
2つの障害モードは、導入後に特に検出が困難です。
-
稀なケースの脆弱性。* グラフトランスフォーマーは一般的な患者表現型では良好に機能する可能性がありますが、稀な診断、異常な薬物組み合わせ、または非定型的な臨床軌跡では壊滅的に失敗する可能性があります。これらのケースは訓練データで過少代表であり、全体的なメトリクスが安定したままである場合、性能アラートをトリガーしない可能性があります。軽減には、臨床入力に基づいて事前に定義された稀なケースサブグループ内での予測信頼度とエラー率の明示的な監視が必要です。
-
注意の崩壊。* トランスフォーマーアーキテクチャでは、注意メカニズムは均一または準均一分布に退化し、事実上グラフ構造を無視してバッグオブワード動作に戻る可能性があります。この障害は無音です。モデル性能は許容可能なままである可能性がありますが、解釈可能性は失われ、グラフ構造の主張された利点は否定されます。注意エントロピーとグラフ利用率(例えば、無視できない注意重みを持つエッジの割合)を注意崩壊の代理指標として監視してください。
前向き検証プロトコル
臨床導入前に、以下の仕様に従って、対象臨床施設で30日間の前向きパイロットを実施してください。
-
ベースライン測定。 同じ前向きデータ上で、同一の評価ウィンドウと患者コホートを使用して、既存モデル(例えば、ロジスティック回帰、従来の電子カルテベースのリスクスコア)のパフォーマンスベースラインを確立してください。これにより、公正な比較が保証され、臨床的に根拠のある参照点が提供されます。
-
主要メトリクス。 実際のワークフロー条件下で、AUROC、AUPRC(精度再現曲線下面積)、較正(ブライアスコア、較正勾配)、およびレイテンシー(50パーセンタイル、95パーセンタイル、99パーセンタイル)を測定してください。テストセットメトリクスに依存しないでください。前向きデータは異なる分布を持つ可能性があります。
-
階層化分析。 すべてのメトリクスを患者サブグループ別に分解してください。
- 年齢(例えば、40歳未満、40~65歳、65歳以上)
- 併存疾患負担(例えば、チャールソン指数四分位数)
- 稀な診断(訓練データでの有病率が1%未満として定義)
- 保険状況または社会経済的代理(利用可能な場合)
- 欠落パターン(例えば、疎な対密な電子カルテ履歴を持つ患者)
-
公平性評価。 各保護属性(人種、民族、性別、利用可能な場合)について、グループ内での較正を計算し、階層化分析または公平性固有のメトリクス(例えば、等化オッズ差)を使用して有意な差をテストしてください。格差とその臨床的含意を文書化してください。
再訓練および監視プロトコル
以下のトリガーとアクションを備えた前向き監視システムを確立してください。
-
性能監視トリガー:*
-
全体的なAUROCが2%以上低下するか、既存モデルベースラインを下回る
-
較正勾配が前向きベースラインから0.1以上逸脱する(体系的な過大または過小推定を示す)
-
いずれかのサブグループでのAUROCがベースラインから相対的に5%以上低下する
-
95パーセンタイルでのレイテンシーが5秒を超える
-
構造監視トリガー:*
-
グラフ密度(患者あたりの平均エッジ)が20%以上低下する(潜在的なデータ品質問題を示す)
-
注意エントロピーが0.5を下回る(潜在的な注意崩壊を示す)
-
注意重み0.1を超えるエッジの割合が0.3を下回る(疎な注意利用を示す)
-
アクションプロトコル:*
-
ティア1(黄色アラート): 根本原因を調査してください。即座のアクションは不要です。次のスケジュール済みレビュー(週次)で再評価してください。
-
ティア2(赤色アラート): 新しい患者コホートへの導入を一時停止してください。根本原因を調査してください。根本原因がデータドリフトの場合、最近のデータで再訓練してください。500以上の新しい患者での前向き検証後にのみ導入を再開してください。
-
ティア3(重大): 導入を停止してください。既存モデルに戻してください。完全な遡及分析を実施してください。
-
再訓練プロトコル:*
-
データドリフトに適応するために、最近のデータのローリングウィンドウ(例えば、過去12ヶ月)で再訓練してください。
-
導入前に、保留された前向きコホートで再訓練を検証してください。
-
トリガー、データウィンドウ、性能変化を含む、すべての再訓練イベントを文書化してください。
制限事項と仮定
この移行計画は以下を仮定しています。
-
十分な前向きデータの可用性。 30日間のパイロットには、少なくとも500~1,000の予測インスタンスが必要です。小規模な施設は、より長いパイロットまたはコンソーシアムベースの検証が必要な場合があります。
-
安定したデータインフラストラクチャ。 電子カルテデータ品質、コーディング慣行、および臨床ワークフローは、パイロット中に比較的安定したままである必要があります。実質的な変更(例えば、電子カルテシステム移行、新しい臨床プロトコル)は前向きベースラインを無効にします。
-
定義された臨床ユースケース。 移行計画は単一の予測タスク(例えば、30日間の再入院)に固有です。複数のタスクまたは予測期間への一般化には、それぞれの個別の検証が必要です。
-
人口統計学的および公平性データへのアクセス。 公平性検証には、人口統計学的情報(人種、民族、性別)および臨床サブグループ定義が必要であり、すべての電子カルテシステムで利用可能または確実にコード化されていない可能性があります。
まとめ
グラフトランスフォーマーは電子カルテモデリングに対して真の技術的利点を提供しますが、導入成功はベンチマークメトリクスを超えて前向き検証、公平性評価、および体系的な監視への移行に依存しています。ここで概説した移行計画は、臨床採用のための具体的で測定可能な基準と、無音障害モードを検出および対応するためのフレームワークを提供します。実装には、技術的能力が臨床ワークフロー、患者安全性、および公平性目標と一致することを確保するために、データサイエンティスト、臨床医、および保健システムリーダーシップ間の緊密な協力が必要です。