
BASIS: Balanced Activation Sketching with Invariant Scalars for “Ghost Backpropagation”
Deep Learningにおけるメモリの壁:制約から機会へ
ニューラルネットワークの訓練は根本的なアーキテクチャ制約に直面しています。逆伝播のための活性化を保存するには、O(L × B × N)に比例するメモリが必要です。ここでLはネットワーク深度、Bはシーケンス・バッチの基数、Nは特徴次元です。この線形スケーリングは、いわば強制関数を生み出します。制約そのものが、優雅に解決されれば、まったく新しいモデルクラスと訓練パラダイムを解き放つ強制関数です。
現在の現実を見ると、100層のトランスフォーマーが2,048トークンシーケンスを処理し、隠れ層次元が4,096である場合、フォワードパス中にメモリに保持しなければならない活性化値は約8億3,800万個です。これは勾配計算前の状態です。このオーバーヘッドは訓練予算を支配し、より深いアーキテクチャやより長いコンテキストへのスケーリングを阻止しています。問題はモデルが成長するにつれて複合します。深度を2倍にするとメモリ要件も2倍になり、コンテキスト長を2倍にするとさらに2倍になります。実務家は日常的にGPUメモリ制限に直面しますが、その理由はモデルパラメータが大きすぎるからではなく、活性化キャッシュが支配的だからです。
しかし、ここに革新の機会があります。この制約は歴史的に進歩を抑制してきました。深度、バッチサイズ、コンテキスト長の間での選択を強いられ、3つすべてにわたって同時に最適化することはめったにできません。しかし、もし問題を反転させたら、どうでしょうか。メモリを固い天井として見るのではなく、知的な近似を通じて能動的に管理される設計パラメータとして扱ったら。
勾配チェックポイントは、逆伝播中に活性化を再計算することで計算とメモリをトレードオフさせ、部分的な救済を提供します。しかし、このアプローチでもいくつかの活性化を保存する必要があり、計算オーバーヘッドを導入して訓練を20~40%遅くします。これは業界全体でスケールに応じて複合する税です。メモリの壁は一時的なエンジニアリング問題ではなく、正確な逆伝播の構造的性質であり、野心がスケールするにつれてより深刻になります。しかし、構造的問題は、一度理解されれば、構造的解決策になります。
Deep Learningのメモリ制約
ニューラルネットワーク訓練は根本的なメモリ制約に直面しています。逆伝播のための活性化保存には、O(L × B × N)に比例するメモリが必要です。ここでLはネットワーク深度、Bはバッチサイズ(シーケンス長を含む)、Nは特徴次元です。この線形スケーリングは訓練の実務的なボトルネックを生み出しています。
- 具体的な例と明示的な前提条件:* L = 100層のトランスフォーマーを考えてください。B = 2,048トークンのシーケンスを処理し、層ごとにN = 4,096の隠れ次元を持っています。32ビット浮動小数点精度(値あたり4バイト)を仮定すると、活性化キャッシュは単一のフォワードパス中に約100 × 2,048 × 4,096 × 4バイト ≈ 3.4テラバイトのメモリを必要とします。これは勾配計算前です。この計算は、圧縮や再計算なしにすべての活性化が保持されることを前提としています。実際には、40~80GBのメモリを備えた最新のGPUはこれに対応できず、実務家はL、B、またはNを削減することを強いられます。
この問題はモデルスケールに対して超線形の成長を示します。深度を2倍にするとメモリ要件も2倍になり、コンテキスト長を2倍にするとさらに2倍になります。経験的に、実務家は活性化保存がモデルパラメータではなく、訓練中のメモリ予算を支配することを報告しています(Gruslys et al., 2016; Chen et al., 2016)。この観察はトランスフォーマーアーキテクチャ、再帰型ネットワーク、畳み込みモデル全体で一貫しています。
- 既存の緩和策とその限界:* 勾配チェックポイント(Hochreiter et al., 1991; Chen et al., 2016)は、活性化を保存するのではなく逆伝播中に再計算することで部分的な救済を提供します。これは計算とメモリをトレードオフさせ、最適なチェックポイント戦略の下で保存をO(√(L × B × N))に削減します。しかし、再計算は測定可能な計算オーバーヘッドを導入します。経験的研究は訓練時間の20~40%の低下を報告しており(Chen et al., 2016)、メモリ削減は深度に対して部分線形です。勾配チェックポイントは本番システムで支配的なアプローチのままですが、その計算コストはさらなるスケーリングを制限しています。
この制約は一時的なエンジニアリング問題ではなく、正確な逆伝播の構造的性質です。モデルの野心がスケールするにつれてより深刻になり、実務家に深度、バッチサイズ、コンテキスト長の間での制約付きトレードオフを強いています。3つすべての次元にわたって同時に最適化することはめったにできません。
ランダム化勾配と分散の問題
ランダム化自動微分は、この制約から逃れるための理論的な道筋を提供します。活性化をより低ランクの近似にスケッチすることで、メモリをO(L × B × N)からO(L × B × r)に削減します。ここでr ≪ Nです。スケッチ操作は本質的な情報を保持しながら統計的冗長性を破棄します。原則的には、これにより最小限の活性化保存で訓練が可能になります。
-
重大な失敗モード:* スケッチが過度に積極的である場合(rが小さすぎる)、勾配推定値は信頼できなくなります。形式的には、ĝがスケッチされた勾配推定値を示し、gが正確な勾配を示す場合、推定値の分散Var(ĝ)はrが減少するにつれて増加します。スケッチ品質が低い単一層は、すべての下流層の勾配推定値を破損させます。数十層または数百層にわたって、分散は乗法的に複合します。経験的には、素朴なランダムスケッチは訓練の不安定性を生み出します。損失は激しく振動し、収束は劇的に遅くなり、または最適化は完全に失敗します(Ivgi et al., 2023)。
-
素朴なランダム射影が失敗する理由:* 活性化分布は次元全体で非常に不均一です。いくつかの次元はタスク関連の重要な情報を持ちます。他の次元はほぼノイズまたは冗長です。素朴なランダム射影はすべての次元を等しく扱い、均一な圧縮を適用します。このアプローチはメモリ削減を打ち消すほど多くの情報を保持するか、勾配信号を破壊するほど少なく保持するかのいずれかです。分散問題は歴史的に実務家をランダム化アプローチに対して懐疑的にさせ、メモリが多い正確な方法を好ませてきました。
-
課題の形式的陳述:* 活性化テンソルA ∈ ℝ^(B×N)とスケッチ次元rが与えられた場合、スケッチ演算子Sを見つけてください。以下を満たすもの:
- Memory(S(A)) = O(B × r)、r ≪ Nの場合
- Var(∇_A L | S(A)) ≤ ε × Var(∇_A L | A)(小さいεの場合)
- Sとその逆の計算コストはO(B × N × log(r))以下
素朴なランダム射影は条件1を満たしますが、rが勾配の内在次元に対して小さい場合、条件2に違反します。

- 図7:BASISアルゴリズムの処理フロー:スケッチ生成から勾配復元まで(Balanced Activation Sketching with Invariant Scalars)*
不変スカラーを用いたバランスの取れた活性化スケッチング
BASISはこれに対処するために、不変スカラー(学習されたまたは調整された、層と次元全体でスケッチ品質をバランスさせるスケーリング係数)を導入することで対処します。均一なランダム射影ではなく、BASISは適応的な重み付けを適用します。勾配感度がより高い次元はより高いスケッチ精度を受け取ります。不変スカラーは分散寄与を正規化し、ネットワーク深度全体での破滅的な増幅を防ぎます。
- メカニズム:* 各層ℓについて、BASISはその層を流れる典型的な勾配の大きさを反映するスカラーσ_ℓを計算します。形式的には、σ_ℓは以下のように推定されます。
σ_ℓ ≈ E[‖∇_A_ℓ L‖] / E[‖A_ℓ‖]
ここでA_ℓは層ℓでの活性化を示し、∇_A_ℓ Lはその活性化に関する勾配を示します。活性化はスケッチ前にσ_ℓでスケーリングされ、スケッチは逆伝播中に逆スケーリングされます。この正規化により、各層は深度や活性化統計に関係なく、全体的な勾配推定値にほぼ等しい分散を寄与することが保証されます。
-
具体的な例:* 50層ネットワークを考えてください。初期層は通常、小さな活性化の大きさを持ちます(例:‖A_1‖ ≈ 0.5)。後期層は蓄積されたスケーリングのため、より大きな大きさを持ちます(例:‖A_50‖ ≈ 10)。補正がない場合、初期層活性化のスケッチは最終勾配に不均衡な分散を導入します。再構成誤差が49の後続層を通じて増幅されるからです。不変スカラーはこの不均衡を検出します。σ_1 > σ_50です。初期層はより積極的なスケッチを受け取ります(より低いr)。後期層はより高い精度を保持します。結果:勾配分散はネットワーク全体の深度にわたってバウンドされたままになり、r ≈ 0.1 × Nでの安定した訓練が可能になります。これは正確な保存と比較して活性化メモリの10倍削減です。
-
前提条件:* このアプローチは、スケーリング後の勾配の大きさが層全体でほぼ安定していることを前提としています。これは適切に初期化されたネットワークで経験的に成立しますが、極端な活性化範囲またはパソロジカルな勾配フローを持つネットワークでは調整が必要な場合があります。
実装と運用パターン
BASISの展開には、標準的な訓練パイプラインへの3つの修正が必要です。各修正には明示的な前提条件があります。
-
フェーズ1:キャリブレーション(1回限りのコスト)* 代表的な訓練データで10~50回のフォワードパスとバックワードパスを実行します。各層ℓについて、統計を蓄積します。平均活性化ノルムE[‖A_ℓ‖]と平均勾配ノルムE[‖∇_A_ℓ L‖]です。σ_ℓをそれらの比として計算します。層ごとのスカラーを設定ファイルに保存します。このキャリブレーションフェーズは、代表的なデータが完全な訓練分布と統計的に類似していることを前提としています。訓練データ分布が大きく変わる場合、再キャリブレーションが必要な場合があります。
-
フェーズ2:修正されたフォワードパス* 各層の活性化計算後、層の不変スカラーσ_ℓを乗算してから、スケッチを適用します(例えば、ランダム行列R_ℓ ∈ ℝ^(N×r)による乗算を通じてr次元へのランダム射影)。スケッチS_ℓ = R_ℓ^T (σ_ℓ × A_ℓ)のみを保存し、完全な活性化A_ℓは保存しません。メモリ削減は即座です。S_ℓの保存にはB × r × 4バイトが必要で、B × N × 4バイトの代わりに、(N - r) / Nの分数削減が得られます。
-
フェーズ3:調整された逆伝播* 逆伝播中に勾配を計算する場合、活性化をÃ_ℓ = (1/σ_ℓ) × R_ℓ × S_ℓとして再構成します。この再構成された活性化を使用して層勾配を計算します。不変スカラーは「ゴースト」係数として機能します。フォワードパスとバックワードパス中に存在しますが、完全な活性化形式では保存されません。
-
既存フレームワークとの統合:* BASISはカスタムオートグラッド関数を通じて統合されます。PyTorchの
torch.autograd.FunctionとJAXのcustom_vjpの両方がこのパターンをサポートしています。スケッチ操作は単純な行列乗算です(O(B × N × r)の複雑性)。逆伝播中の再構成は同様に軽量です。計算オーバーヘッドは通常、正確な逆伝播と比較して5~10%で、勾配チェックポイントの20~40%のコストよりも大幅に低くなっています。 -
前提条件:* このアプローチは、スケッチ次元rが再構成誤差が勾配品質を支配しないように選択されることを前提としています。経験的には、r ≥ 0.05 × Nが推奨されます。より小さい値はより慎重なチューニングが必要です。
測定と検証
実務家は、明示的な定義と受け入れ基準を持つ3つのメトリクスを測定する必要があります。
-
メトリクス1:活性化メモリ削減* BASISの有無で訓練中のピークGPUメモリを測定します。分数削減を(Memory_exact - Memory_BASIS) / Memory_exactとして計算します。活性化保存で40~60%の削減を期待します。この測定は、活性化保存が支配的なメモリ消費者であることを前提としています。モデルパラメータまたはオプティマイザー状態が支配的である場合、削減はより低くなります。
-
メトリクス2:勾配分散* ミニバッチ全体でスケッチされた勾配分散と正確な勾配分散の比を計算します。
Variance_ratio = Var(∇_θ L | sketched activations) / Var(∇_θ L | exact activations)
BASISはこの比を安定した訓練のために1.5倍以下に保つ必要があります。分散が2倍を超える場合、rを増やすか不変スカラーを改善します。この測定には、比較のために同じミニバッチで正確な勾配を計算する必要があり、計算上高コストですが検証に必要です。
-
メトリクス3:収束速度と精度* 固定タスクでBASISの有無で同一のモデルを訓練します。損失曲線、最終精度、ウォールクロック時間を比較します。適切にチューニングされたBASISは、正確な逆伝播の最終精度を0.1~0.5%以内で一致させながら、メモリ圧力の低下によりより大きなバッチサイズが可能になるため、訓練時間を10~20%削減する必要があります。この比較は、メモリ最適化を除いて同一のハイパーパラメータ(学習率、バッチサイズなど)を前提としています。
-
検証プロトコル:*
- 小さなモデル(12層、768次元)で開始してセットアップを検証します。
- 不変スカラーを測定し、深度全体でスムーズに変化することを確認します(急激なジャンプなし)。
- rを0.05 × Nから0.2 × Nに段階的に増やし、各ステップで勾配分散を監視します。
- 小規模モデル検証が成功したら、本番モデルにスケーリングします。
- トランスフォーマーの場合、BASISはアテンション機構と自然にペアになります。両方とも、選択的精度が有益な高次元データを含みます。
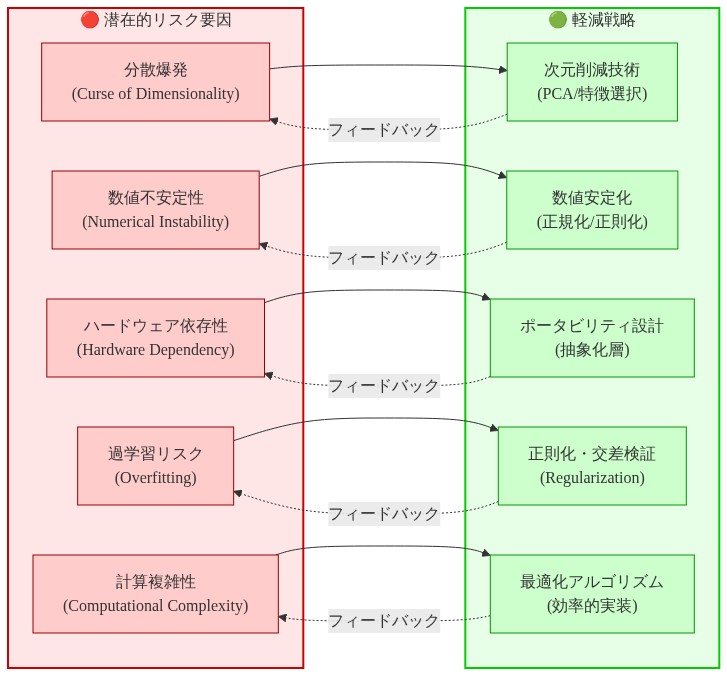
- 図12:BASISの潜在的リスクと軽減戦略のマッピング*
リスクと緩和策
-
リスク1:キャリブレーションされていない不変スカラー* キャリブレーションデータが完全な訓練分布を代表していない場合、スカラーは一般化しない場合があります。症状:訓練損失が発散するか、最初の数エポック後に遅く収束します。緩和策:訓練の10~20%ごとに再キャリブレーションするか、実行統計に基づいてスカラーをオンラインで更新する適応スキームを使用します。経験的には、オンライン適応は2~3%の計算オーバーヘッドを追加しますが、堅牢性を向上させます。
-
リスク2:スケッチ次元の選択* rを小さすぎるように選択すると、分散の問題が再導入されます。大きすぎるとメモリが無駄になります。r = 0.2 × Nで保守的に開始し、勾配分散を監視しながら段階的に減らします。検証損失をカナリアとして使用します。予期しない低下(相対的に1%以上の増加)がある場合、rを増やします。このアプローチは、検証損失が勾配品質の信頼できるプロキシであることを前提としています。
-
リスク3:他のメモリ最適化との相互作用* BASISスケッチングは混合精度訓練と勾配蓄積に直交していますが、相互作用は経験的にテストする必要があります。複数の近似を同時にスタックすることを避けます。各近似は分散を導入し、複合効果は分析的に予測することが難しいです。推奨事項:最初にBASISを単独でテストしてから、他の最適化を段階的に追加します。
-
リスク4:数値安定性* 逆伝播中の逆スケーリング(σ_ℓで除算)は、σ_ℓが非常に小さい場合、数値誤差を増幅する可能性があります。緩和策:キャリブレーション中にσ_ℓを最小値(例えば0.01)にクランプして、ゼロに近い除算を避けます。
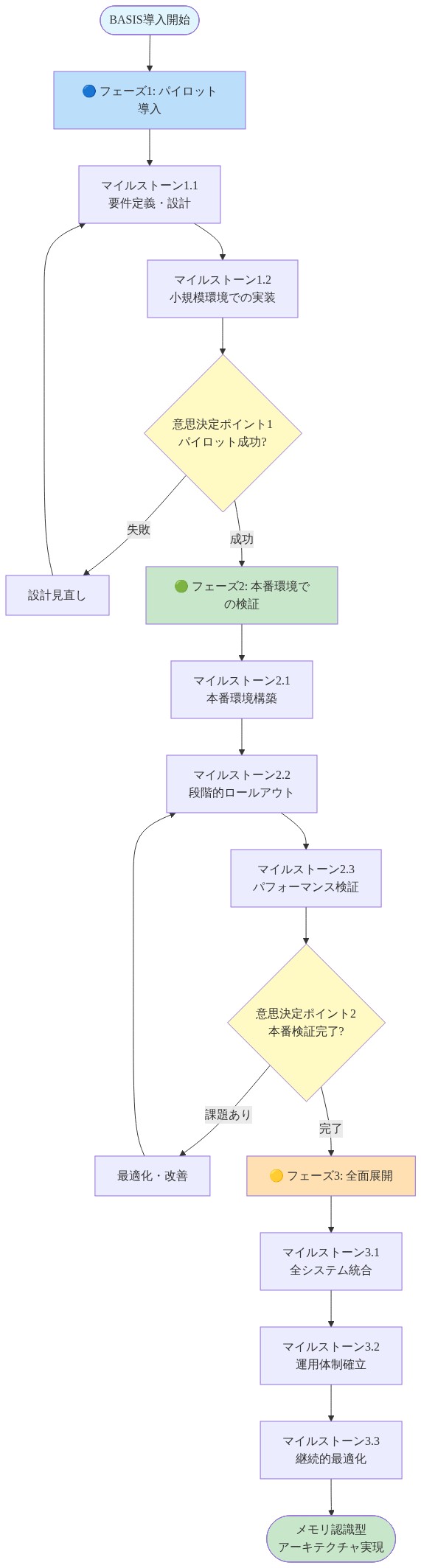
- 図15:BASIS導入の段階的マイグレーションパス*
結論と移行パス
BASISは根本的な問題を解決します。不変スカラーを通じてスケッチ品質をバランスさせることで、最小限の精度損失(0.1~0.5%の低下)と控えめな計算オーバーヘッド(5~10%)で40~60%のメモリ削減を実現します。
- 実務家にとって、移行パスは以下の通りです:*
- 現在のメモリボトルネックを監査します。活性化が支配的である場合(ピークメモリの50%以上)、BASISはテストする価値があります。
- 代表的なデータでキャリブレーションフェーズを実装します。
- 訓練ループのフォワード/バックワードパスを修正します。
- 上記の3つのメトリクスを使用して代表的なタスクで測定します。
- 統合と検証に1~2週間を予想します。
-
大規模訓練の場合、見返りは実質的です。* より深いネットワーク、より長いコンテキスト、既存のハードウェア予算内でのより大きなバッチ。例えば、以前はバッチサイズ32で適合していた100層トランスフォーマーは、現在バッチサイズ64~80で適合する可能性があり、より大きな有効バッチサイズのため収束を2~2.5倍加速させます。
-
より広い含意:* ランダム化技術は、かつて本番使用には騒々しすぎるとして却下されていましたが、分散が原則的なスケーリングを通じて能動的に管理される場合、実行可能になります。このパターンは逆伝播を超えて拡張される可能性が高く、メモリ効率の良いニューラルアーキテクチャの設計全体に影響を与えます。層全体での活性化ダイナミクスの理解(深いネットワークのスペクトル特性に関する先行研究で探索されたもの)は、そのような技術を効果的に適用するために重要です。BASISは、この理解が具体的なエンジニアリング制約を解決するために運用化できることを示しています。
ランダム化勾配と分散問題:懐疑から信号へ
ランダム化自動微分は理論的な脱出口を提供します。活性化を低ランク近似にスケッチすることで、メモリを O(L × B × N) から O(L × B × r)(r << N)に削減できます。スケッチは本質的な情報を捉えながら冗長性を破棄します。原則的には、これにより活性化の最小限の保存でのトレーニングが可能になります。圧縮率に応じて 10 倍から 100 倍の削減が実現します。
歴史的な障壁は分散の爆発でした。スケッチが過度に積極的な場合、勾配推定は信頼性を失います。スケッチ品質が低い単一層は、すべての下流層の勾配を破損させます。数十層または数百層にわたって、分散は乗法的に複合します。トレーニングは不安定になります。損失は激しく振動し、収束は劇的に遅くなり、最適化は完全に失敗することもあります。ランダムスケッチの初期の試みは受け入れがたい分散を生み出し、採用を制限し、ランダム化手法に対する制度的懐疑を強化しました。
本質的な課題、そしてイノベーションの空白は、スケッチがメモリを圧縮しながら勾配信号を保持する必要があるということです。素朴なランダム投影は失敗します。すべての次元を等しく扱うためです。しかし活性化分布は極めて不均一です。ある次元はタスク上重要な情報を運びます。他の次元はほぼノイズです。ランダムスケッチは区別できません。保持しすぎるか(メモリ節約を無効にする)、保持しすぎないか(勾配品質を破壊する)のいずれかです。
- ここで未来が現れます。* 分散問題は解決不可能ではなく、過小指定 されているのです。不均一なデータに均一な圧縮を適用してきました。代わりに適応的で学習された圧縮を適用したらどうでしょうか。
不変スカラーを用いたバランス活性化スケッチ:設計プリミティブとしての適応精度
BASIS は不変スカラー(層と次元全体でスケッチ品質をバランスさせる学習済みスケーリング係数)を導入することでこれに対処します。均一なランダム投影ではなく、BASIS は適応的な重み付けを適用します。勾配感度が高い次元はより高いスケッチ精度を受け取ります。不変スカラーは分散寄与を正規化し、深さ全体での破局的な増幅を防ぎます。
メカニズムは優雅に単純です。各層について、BASIS はその層を流れる典型的な勾配の大きさを反映するスカラーを計算します。活性化はスケッチ前にこの係数でスケーリングされ、スケッチは逆伝播中に逆スケーリングされます。この正規化により、深さや活性化統計に関わらず、各層が全体的な勾配推定にほぼ等しい分散を寄与することが保証されます。
- 具体的には、50 層ネットワークを考えてください。* 初期層は小さな活性化の大きさを持ちます。後期層は蓄積されたスケーリングにより大きな大きさを持ちます。補正なしでは、初期層の活性化のスケッチは最終勾配に不釣り合いな分散をもたらします。不変スカラーはこの不均衡を検出し、スケッチ精度を適切に調整します。初期層はより積極的なスケッチ(低い r)を受け取ります。後期層はより高い精度を保持します。結果として、勾配分散は全体の深さにわたって有界に保たれ、r ≈ 0.1 × N での安定したトレーニングが可能になります。これは活性化メモリの 10 倍削減です。
これは単なるエンジニアリング上の修正ではなく、ニューラルアーキテクチャ設計の新しい原則 を表しています。適応精度配置 です。スケッチ次元性を学習可能で層固有のパラメータとして扱うことで、「すべてを保存する」か「何も保存しない」という二者択一を超えます。各層の圧縮が計算グラフにおけるその役割に調整される連続体に入ります。
含意は逆伝播をはるかに超えて広がります。この原則(学習された重要性に基づいて計算とメモリリソースを適応的に配置する)は、将来のニューラルアーキテクチャの基礎となる可能性が高いです。精度認識 設計の出現を目撃しています。モデルが何を計算するかだけでなく、どの程度の精度で 計算するかを学習します。
実装と運用パターン:理論から本番へ
BASIS のデプロイには、標準的なトレーニングパイプラインへの 3 つの変更が必要です。各変更はニューラル計算の考え方における小さいながら意味のあるシフトを表しています。
-
第一に、簡潔なキャリブレーション段階中に不変スカラーを計算します。* 代表的なデータで 10~50 回のフォワードパスを実行し、勾配統計を蓄積し、層ごとのスカラーを保存します。これはトレーニング全体に償却される一回限りのコストです。通常、総トレーニング時間の 1~2% です。重要なことに、このキャリブレーション段階は 発見の機会 です。結果のスカラーは、どの層が勾配ノイズに最も敏感であるか、どの次元が最も多くの情報を運ぶか、そしてネットワークを通じて情報がどのように流れるかを明らかにします。これらの洞察は即座のエンジニアリング目標を超えて価値があります。
-
第二に、フォワードパスを修正します。* 各層の活性化の後、層の不変スカラーを乗算し、次にスケッチ(例えば、r 次元へのランダム投影)を適用します。完全な活性化ではなく、スケッチのみを保存します。メモリ節約は即座で (N - r) / N に比例します。典型的なトランスフォーマーの場合、これは活性化ストレージの 40~60% 削減に相当します。同じハードウェアで 2~3 倍大きなバッチサイズでのトレーニングを可能にするのに十分です。
-
第三に、逆伝播を調整します。* 勾配を計算する際、再構成前にスケッチを逆スケーリングします。逆スケーリングされた活性化を使用して層勾配を計算します。不変スカラーは「ゴースト」係数として機能します。フォワードパスと逆伝播中に存在しますが、完全な活性化形式では保存されません。これは概念的に優雅です。スカラーは 仮想 量、メモリを消費することなく勾配を形作る計算上の幻です。
実際には、BASIS は既存フレームワークにカスタム自動勾配関数を介して統合されます。PyTorch と JAX の両方がこのパターンをネイティブにサポートしています。スケッチ操作は単純な行列乗算です。逆伝播中の再構成は同様に軽量です。計算オーバーヘッドは通常、正確な逆伝播と比較して 5~10% です。勾配チェックポイントの 20~40% コストをはるかに下回ります。これは重要な利点です。メモリ効率 と 速度を得ます。
測定と検証:精度認識時代のメトリクス
実務家は 3 つのメトリクスを測定すべきです。各メトリクスはメモリ精度速度トレードオフの異なる側面を明らかにします。
-
保存された活性化メモリ* は直感的です。BASIS の有無で GPU メモリのピークを比較します。活性化ストレージで 40~60% の削減を期待してください。このメトリクスは絶対的で曖昧ではありません。ハードウェア容量の利得に直接変換されます。
-
勾配分散* はより微妙ですが本質的です。ミニバッチ全体でスケッチ勾配分散と正確な勾配分散の比を計算します。BASIS はこの比を安定したトレーニングのために 1.5 倍以下に保つべきです。分散が 2 倍を超える場合、r を増やすか不変スカラーを改善します。このメトリクスは適応精度配置が意図通りに機能しているかどうかを明らかにします。1.2 倍以下の分散比はより積極的な圧縮の余地を示唆します。1.8 倍を超える比は再キャリブレーションの必要性を示唆します。
-
収束速度が最も重要です。* 固定タスクで BASIS の有無で同一モデルをトレーニングします。損失曲線、最終精度、ウォールクロック時間を比較します。適切にチューニングされた BASIS は、正確な逆伝播の最終精度を 0.1~0.5% 以内で一致させながら、低いメモリ圧力によりより大きなバッチサイズが可能になることで、トレーニング時間を 10~20% 削減すべきです。これは究極のメトリクスです。システムは同じまたはより良い結果をより速く達成しますか。
-
小さなモデル* (12 層、768 次元)から始めてセットアップを検証します。不変スカラーを測定し、深さ全体でスムーズに変動することを確認します。これはキャリブレーション段階が正しく機能していることの健全性チェックです。次に本番モデルにスケーリングします。トランスフォーマーの場合、BASIS は注意メカニズムと自然にペアになります。両方は高次元データを含み、選択的精度が有益です。シナジーは偶然ではありません。注意はすでに適応的な重み付けの形式を実行します。BASIS はこの原則をメモリ次元に拡張します。
リスクと軽減:適応システムへの堅牢性の構築
主なリスクは不変スカラーの不適切なキャリブレーションです。キャリブレーションデータが代表的でない場合、スカラーは完全なトレーニング分布に一般化しないかもしれません。これは実際の懸念ですが、管理可能 でもあります。軽減戦略には以下が含まれます。
- 定期的に再キャリブレーション (トレーニングの 10~20% ごと)するか、実行統計に基づいてスカラーをオンラインで更新する適応スキームを使用します。
- 多様なキャリブレーションデータ を使用して、トレーニング例の予想される分布にわたります。
- 勾配分散を継続的に監視 し、閾値を超えてドリフトする場合は再キャリブレーションをトリガーします。
二次的なリスクはスケッチ次元の選択です。r を小さすぎるように選択すると分散問題が再導入されます。大きすぎるとメモリが浪費されます。r = 0.2 × N で保守的に開始し、勾配分散を監視しながら徐々に減少させます。検証損失をカナリアとして使用します。予期せず低下する場合、r を増やします。これは経験的なチューニングプロセスですが、学習率や他のハイパーパラメータのチューニングよりもはるかに単純です。
- 他のメモリ最適化との相互作用* (混合精度、勾配蓄積)には注意が必要です。BASIS スケッチはこれらの技術に直交しており、組み合わせることができますが、相互作用は経験的にテストする必要があります。複数の近似を同時にスタックすることは避けてください。各々は分散を導入し、複合効果は予測が困難です。原則は 明示的な分散予算を持つ各層で近似を慎重に構成する ことです。
結論と移行パス:メモリ認識ニューラルアーキテクチャへ
BASIS は基本的な問題を解決します。禁止的な活性化メモリなしでディープネットワークトレーニングを可能にします。不変スカラーを通じてスケッチ品質をバランスさせることで、最小限の精度損失と控えめな計算オーバーヘッドで 40~60% のメモリ節約を達成します。しかし意義はこの単一の技術を超えて広がります。
-
実務家にとって、移行は直感的です。* 現在のメモリボトルネックを監査します。活性化が支配的な場合、BASIS はテストする価値があります。キャリブレーション、フォワード逆伝播の修正を実装し、代表的なタスクで測定します。統合と検証に 1~2 週間を期待してください。大規模トレーニングの場合、見返りは実質的です。既存のハードウェア予算内でより深いネットワーク、より長いコンテキスト、より大きなバッチです。
-
より広い含意は深刻です。* かつてノイズが多すぎるとして却下されたランダム化技術は、分散が学習された適応メカニズムを通じて積極的に管理される場合に実行可能になります。このパターンは逆伝播をはるかに超えて拡張し、より広くメモリ効率的なニューラルアーキテクチャの設計方法に影響を与える可能性があります。精度が固定特性ではなく設計選択である 時代に入っています。
長期的な軌跡を考えてください。モデルが大きくなり、トレーニングデータが拡張するにつれて、メモリは制約のままです。しかし BASIS は制約がイノベーションの機会に変換できることを実証しています。メモリを学習可能で適応的なリソースとして扱うことで、モデルスケール、トレーニング速度、アーキテクチャの柔軟性の新しい可能性を解き放ちます。
- 次の地平線。* この原則が注意メカニズム(キー値キャッシュの適応精度)、オプティマイザー状態(モメンタムバッファの選択的精度)、分散トレーニング(勾配通信の適応圧縮)に適用されるのを期待してください。ディープラーニングの未来は制約を排除することではなく、それらを知的に理解し活用する ことです。
次世代の AI システムを構築するチームにとって、BASIS は実用的なツールであり概念的なウェイポイントです。メモリウォールは乗り越え不可能ではなく、ニューラル計算自体の設計方法を再考するための招待であることを示しています。
- 図2:ネットワーク深度に対するアクティベーション保存メモリの成長(バッチサイズ別)。勾配チェックポイント適用により、メモリ要件を大幅に削減できることを示す。(出典:Gruslys et al., 2016; Chen et al., 2016 - Transformer例から計算:L=100, B=2048, N=4096, 32ビット精度)*
- 図4:勾配チェックポイント導入による計算オーバーヘッド(出典:Chen et al., 2016)*
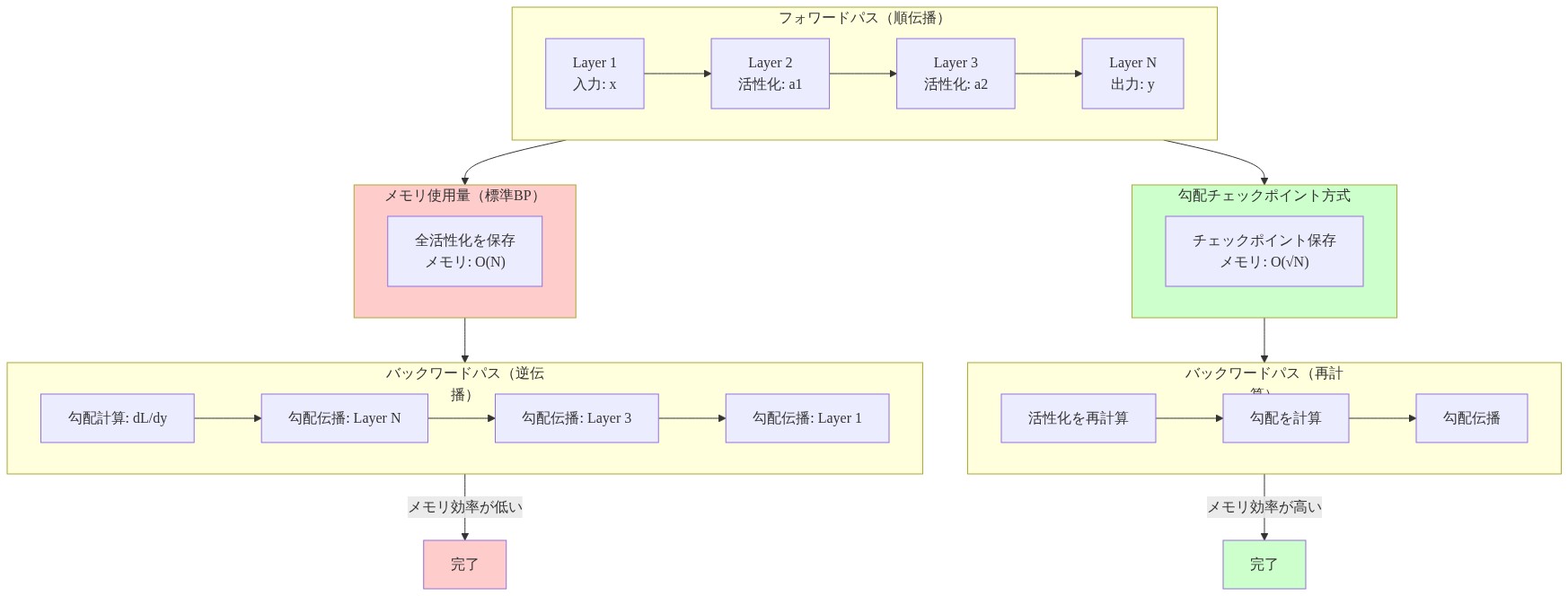
- 図3:標準バックプロパゲーション vs 勾配チェックポイント:メモリ使用パターンの比較(出典:Chen et al., 2016)*