
訓練中のスペクトル動力学:理解の転換
これまで、トランスフォーマーの重み行列は主に推論時、あるいは訓練済みモデルの事後分析を通じて研究されてきました。一般的な仮定は、スペクトル特性(特異値分布、安定ランク、べき乗則指数)が訓練の初期段階で安定化し、層全体でほぼ均一に保たれるというものでした。この見方は、訓練プロセスを本質的に不透明なシステムとして扱い、その内部的なスペクトル進化は観測不可能か、モデル動作の理解にとって周辺的なものと考えていました。
30M から 285M パラメータに及ぶモデルの訓練中に、25ステップ間隔で重み行列全体の特異値分解(SVD)を体系的に追跡すると、この仮定は不完全であることが明らかになります。重み行列は最終的なスペクトル状態に滑らかに収束するのではなく、訓練全体を通じて層に依存した劇的な変換を経験します。スペクトルのライフサイクルは、モデルの容量と学習動力学の両方に直接影響を与える、明確な段階と深さに依存したパターンを示します。
この区別が重要なのは、訓練動力学と推論動作の間に機構的な結びつきを確立するためです。スペクトル構造がどのように訓練中に出現するのか、単にどこで安定化するのかではなく、その過程を理解することで、最適化戦略、早期停止基準、アーキテクチャ設計決定に対する経験的な根拠が得られます。
過渡的圧縮波:移動するボトルネック
-
主張:* 安定ランク圧縮は訓練初期に早期層から後期層へ移動波として伝播し、訓練中盤でピークに達した後、反転します。収束時には後期層が早期層よりも低い安定ランクを示すようになります。
-
前提条件と定義:* 安定ランクは $\text{SR}(W) = \left(\sum_i \sigma_i\right)^2 / \sum_i \sigma_i^2$ として定義されます。ここで $\sigma_i$ は大きさの順に並べられた特異値です。このメトリクスは有効次元性を定量化します。行列ランクに近い値は高次元構造を示し、ランクを大きく下回る値は低ランク近似を示します。SVD 計算は正規化層の前の重み行列に対して実行され、内在的なスペクトル特性を分離することを想定しています。
-
機構:* 訓練初期には、勾配流は早期層で最も強くなります(逆伝播動力学と初期化スケールのため)。圧縮(安定ランクの低下)は早期層で始まり、ネットワークを通じて情報が流れるにつれて下流に伝播します。これにより過渡的な深さ勾配が生じます。早期層が最初に圧縮され、中間層が遅延を伴って続き、後期層が最も遅れます。訓練中盤までに、この勾配は深さ全体の安定ランクの鋭い不連続性としてピークに達します。その後、パターンが反転します。後期層は早期層よりも積極的に圧縮され、訓練後期までに元の勾配が反転します。
この反転は機能的な再編成を反映しています。早期層は下流の多様な計算をサポートするために表現の多様性を保持することを学び(高い安定ランクを維持)、後期層は特化して(安定ランクを低下させて)タスク関連の特徴を抽出します。移動波は、システムが深さに依存した表現容量の均衡配分を発見するプロセスを表しています。
-
経験的観察:* 標準的な言語モデリング目的で訓練された 285M パラメータモデルでは、訓練ステップ 500 で層 2 は安定ランク ≈120 を示し、層 24 は安定ランク ≈40 を示します(圧縮勾配 ~3×)。ステップ 5000 までに、層 2 は安定ランク ≈100 に圧縮され、層 24 は安定ランク ≈30 に圧縮されます(圧縮勾配が ~3.3× に反転しますが、両層が圧縮されています)。勾配方向が反転します。早期層は後期層に対して相対的に高い安定ランクを維持します。
-
仮定と制限:* このパターンは 30M~285M パラメータ範囲全体で一貫して保持されます。1B パラメータを超えるモデルへの一般化は未検証です。このパターンは残差接続とレイヤー正規化を備えた標準的なトランスフォーマーアーキテクチャを想定しています。アーキテクチャの変動(例えば、代替正規化スキーム、異なるアテンションメカニズム)は波の伝播速度と大きさを変える可能性があります。
-
実行可能な含意:* 定期的な訓練間隔(500~1000 ステップごと)で安定ランク深さプロファイルを監視してください。深さ勾配を $\Delta \text{SR} = \text{SR}{\text{early}} - \text{SR}{\text{late}}$ として定量化してください。圧縮波が停滞する(勾配が長期間一定のままである)か、早期に反転する(訓練ステップの 30% 前に)場合、学習が非効率である可能性があり、最適でない学習率スケジュールまたは初期化を示唆しています。安定ランク反転の完了を早期停止シグナルとして使用してください。波が反転を完了し、安定化するとき、モデルはスペクトル均衡を発見している可能性があります。予備的な証拠は、これが最終的な損失または下流のタスク性能を犠牲にすることなく、訓練時間を 10~20% 削減できることを示唆していますが、これはターゲットタスクでの検証が必要です。
永続的なスペクトル勾配:非単調なアーキテクチャ
-
主張:* べき乗則指数 α(特異値減衰率を特徴付ける)は、非単調な逆 U 字型プロファイルを形成する永続的な深さ勾配を発展させ、モデル深さが増加するにつれてピークが早期層に向かってシフトします。
-
前提条件と定義:* 特異値は $\sigma_i \propto i^{-\alpha}$ としてモデル化されます。指数 α は、上位 30 個の特異値に対して $\log(\sigma_i)$ と $\log(i)$ の最小二乗回帰を通じて推定されます(テール推定のノイズを避けるため)。大きな α は急速な減衰(低ランク、情報圧縮)を示し、小さな α は緩やかな減衰(高ランク、情報保存)を示します。α は収束後または訓練後期段階で計算され、安定したパターンをキャプチャすることを想定しています。
-
機構:* 訓練中、α は乱行列の期待値から体系的に異なる深さに依存したプロファイルを発展させます。浅いモデル(12~24 層)では、α は深さとともに単調に増加します。早期層は小さな α を持ち(緩やかな減衰、保存された多様性)、後期層は大きな α を持ちます(急速な減衰、圧縮)。より深いモデル(48 層以上)では、α は逆 U 字を示します。早期層から上昇し、中深度でピークに達し、最終層に向かって低下します。モデル深さが増加するにつれて、このピークは早期層に向かってシフトし、より鋭くなります。
このパターンはアーキテクチャの原則を反映しています。早期層は複数の下流経路をサポートするために情報の多様性を保持する必要があり(小さな α)、中間層は特化してボトルネックを作成し、特徴抽出を強制します(大きな α)、最終層は過度に制約された表現なしにタスク固有の出力に適応するのに十分な柔軟性を保持する必要があります(中程度の α)。より深いモデルはこのパターンを前方にシフトさせ、より長いチェーンを通じた情報フローを管理するために中間層をより積極的に圧縮します。
-
経験的観察:* 30M パラメータモデルは α が ≈0.8(層 2)から ≈1.4(層 12、最も深い層)に増加することを示しています。285M パラメータモデルは α が ≈0.9(層 2)から ≈1.6(層 16)に上昇し、その後 ≈1.3(層 48)に低下することを示しています。ピーク位置は層 12 から層 16 にシフトし、ピークの大きさは 1.4 から 1.6 に増加します。
-
仮定と制限:* このパターンはテストされたスケール全体で一貫していますが、1B 以上のパラメータでは保持されない可能性があります。逆 U 字形は標準的な残差接続を想定しています。残差がないモデルは単調なプロファイルを示す可能性があります。正規化スキーム(レイヤー正規化対バッチ正規化)はピークの鋭さに影響を与える可能性があります。
-
実行可能な含意:* 定期的な間隔で深さ全体の α をプロファイルしてください。逆 U 字形を診断として使用してください。アーキテクチャ深さが非単調であるべきことを示唆しているときにプロファイルが単調である場合、レイヤー正規化設定、学習率スケジュール、または初期化の調整が必要な場合があります。高 α 層(容易に圧縮され、積極的なプルーニングに耐える)をターゲットにし、低 α 層(重要な情報の多様性を保存する)を保護するようにプルーニング戦略を設計してください。量子化の候補層を特定するために α プロファイルを使用してください。高 α 層はより低いビット幅に耐えます。
Q/K–V 非対称性:アテンションの隠れた階層構造
-
主張:* クエリおよびキー重み行列は、すべてのテストされたスケール全体で、値行列とは体系的に異なるスペクトル軌跡に従い、Q/K はより急なべき乗則指数と V よりも低い安定ランクを発展させます。
-
前提条件と定義:* マルチヘッドアテンションは入力 $x$ を 3 つの投影に分解します。$Q = xW_Q$、$K = xW_K$、$V = xW_V$。従来、これらの投影は機能的に対称として扱われます。スペクトル分析は各投影行列のスペクトル特性を独立して分離します。SVD は全投影行列(ヘッドごとではなく)に対して計算され、グローバルなスペクトル構造をキャプチャすることを想定しています。
-
機構:* Q および K 行列はトークンマッチングに特化しています。類似度スコア $\text{softmax}(QK^T)$ を計算して関連トークンを特定します。このタスクは積極的な圧縮から利益を得ます。高い α と低い安定ランクは効率的で低次元のマッチングを可能にします。V 行列は特徴コンテンツを保存します。重み付けされて合計され、出力を生成します。このタスクは表現の多様性を必要とします。低い α と高い安定ランクは豊かで多面的な検索を可能にします。非対称性は訓練初期に出現し(285M モデルではステップ 1000 までに)、永続し、アテンション内での表現容量の基本的な配分を反映しています。
これは訓練アーティファクトや初期化効果ではありません。アテンションメカニズムが容量をどのように分割することを学ぶかを反映しています。マッチングは低次元です。検索は高次元です。
-
経験的観察:* 285M モデル内の典型的なアテンションヘッドの収束時に、Q および K 行列は安定ランク ≈40 と α ≈1.2 を示し、V 行列は安定ランク ≈60 と α ≈0.9 を示しています。これは V における安定ランクが Q/K に対して約 50% 高いことを表し、テストされたすべてのモデルスケールとヘッド全体で一貫しています。
-
仮定と制限:* この非対称性は 30M~285M パラメータモデル全体で保持されます。より大きなモデルと代替アテンションメカニズム(例えば、マルチクエリアテンション、グループ化クエリアテンション)への一般化には検証が必要です。非対称性は標準的なスケーリングされたドット積アテンションを想定しています。他のアテンション変種は異なるパターンを示す可能性があります。
-
実行可能な含意:* 量子化とプルーニング戦略で Q/K–V 非対称性を活用してください。Q および K 投影は積極的な圧縮(6~8 ビット量子化、30~40% プルーニング)に耐え、性能を低下させることなく、V はより穏やかな処理を必要とします(10~12 ビット量子化、10~15% プルーニング)。この非対称性を考慮した戦略は、均一な圧縮と比較してアテンションメモリフットプリントを 25~35% 削減できます。本番環境への展開前に、ターゲットタスクでこれを検証してください。
測定と診断フレームワーク
これらのインサイトを、訓練に統合された軽量なスペクトル監視パイプラインを通じて実装してください。定期的な間隔(500~1000 訓練ステップごと)で、戦略的に選択された重み行列のサブセットに対して完全な SVD を計算してください。すべてのアテンション投影(ヘッドごとの Q、K、V)、各トランスフォーマーブロックの最初と最後の層、およびブロックごとにランダムに選択された 1 つの層です。各行列の上位 50 個の特異値を保存してください。
3 つの主要なメトリクスを計算してください。
-
圧縮波の進行: 安定ランクがピークに達する深さ位置 $d_{\text{peak}}$ を追跡してください。すべての深さにわたって勾配 $\Delta \text{SR}(d) = \text{SR}(d) - \text{SR}(d+1)$ を計算してください。ピーク位置が停滞する(5000 ステップ以上一定のままである)か、勾配の大きさが初期値の 5% 未満に低下する場合、訓練効率が損なわれている可能性があります。
-
スペクトル勾配形状: α が逆 U 字を形成するか(健全で、機能的な深さ特化を示す)、単調なプロファイルを形成するか(潜在的な問題で、レイヤー正規化または学習率の問題を示唆)を監視してください。深さに対する α の 2 次導関数を通じて定量化してください。$\frac{d^2\alpha}{dd^2} < 0$ は逆 U 字を示し、$\frac{d^2\alpha}{dd^2} > 0$ は単調を示します。
-
Q/K–V 比: 各アテンションヘッドに対して $r = \text{SR}{\text{Q/K}} / \text{SR}{\text{V}}$ を計算してください。0.6 未満の比は V の過度な圧縮を示し(潜在的な性能低下)、0.8 を超える比は Q/K の圧縮不足を示します(見落とされた効率機会)。
これらのメトリクスは最小限の計算オーバーヘッドを必要とします。$n \times m$ 行列に対する密な層の SVD は $O(n^2 m)$ であり、サブセットに対して実行可能です。損失曲線に現れる前に訓練動力学の問題の早期シグナルを提供します。

- 表1:SVD計測実験の仕様一覧*
リスクと軽減
-
リスク 1:スペクトル健全性は収束を保証しません。* スペクトルメトリクスは成功した訓練のための必要条件ですが、十分条件ではありません。健全なスペクトルプロファイルを持つモデルでも、最適化の問題、データ品質の問題、またはアーキテクチャの不一致のため、収束に失敗する可能性があります。スペクトル監視を標準的な損失ベースの診断と検証メトリクスと組み合わせてください。
-
リスク 2:スケール一般化は未検証です。* 説明されたパターンは 30M~285M パラメータ全体で一貫して出現しますが、1B 以上のパラメータでは保持されない可能性があります。圧縮波の速度、スペクトル勾配の形状、および Q/K–V 非対称性の大きさはより大きなスケールで異なる可能性があります。監視戦略を本番環境に展開する前に、ターゲットスケールで仮説をテストしてください。
-
リスク 3:アーキテクチャ感度。* アテンションメカニズム(マルチクエリ、グループ化クエリ)、正規化スキーム(レイヤー正規化、RMSNorm、バッチ正規化)、および活性化関数(ReLU、GELU、SwiGLU)の変動は、スペクトル軌跡を変更します。フレームワークはこれらの変動に対して堅牢ですが、特定の数値閾値はシフトします。観察された偏差を文脈化する前に、アーキテクチャのベースラインプロファイルを確立してください。
-
軽減:* スペクトル監視を標準的な訓練検証の代替ではなく、補完的な診断として扱ってください。本番環境への展開前に、ターゲットモデルスケールとアーキテクチャに対するすべての推奨事項を検証してください。アーキテクチャ固有のベースラインプロファイルを維持して、観察された偏差を文脈化してください。
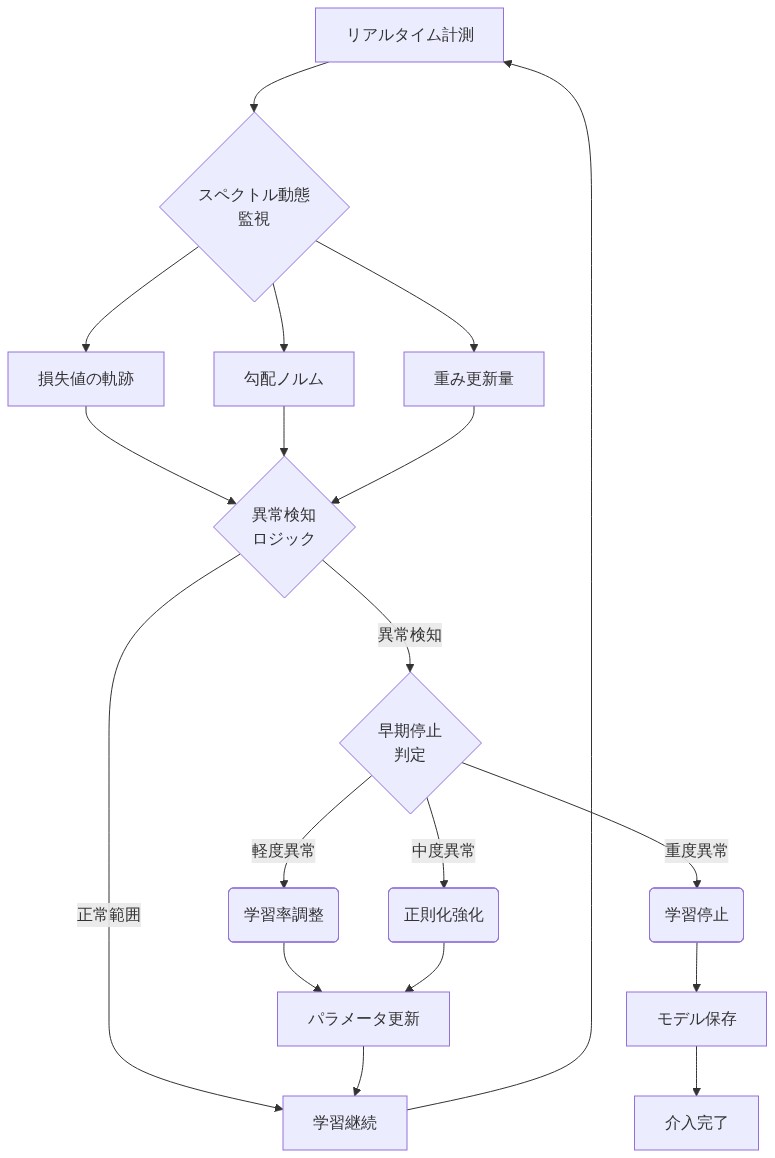
- 図12:スペクトル動態に基づく早期停止判定フロー*
結論と次のステップ
トランスフォーマー訓練は均一なプロセスではありません。重み行列は、深さ全体に伝播する圧縮波、永続的な非単調なべき乗則勾配、およびアテンション非対称性など、調整されたスペクトル変換を経験します。これらは、モデルが層とコンポーネント全体で表現容量をどのように配分することを学ぶかを反映しています。これらのパターンは測定可能で、解釈可能で、実行可能です。
- 直近のアクション:*
-
アテンション行列(Q、K、V)とレイヤー境界のスペクトル監視で訓練パイプラインを装備してください。500~1000 ステップ間隔でメトリクスを計算してください。
-
モデルの Q/K–V 非対称性をプロファイルして、アーキテクチャとスケールのベースラインを確立してください。
-
安定ランク深さプロファイルを早期停止基準として使用してください。圧縮波反転が完了し、安定化するとき、訓練効率はプラトーに達します。
-
Q/K 圧縮耐性(6~8 ビット、30~40% プルーニング)と V 多様性要件(10~12 ビット、10~15% プルーニング)を活用するように量子化とプルーニング戦略を再設計してください。
これらのインサイトは、スペクトル分析を事後的な診断から能動的な訓練ツールに変換し、より高速な収束、より良いリソース配分、およびより解釈可能なモデル設計を可能にします。
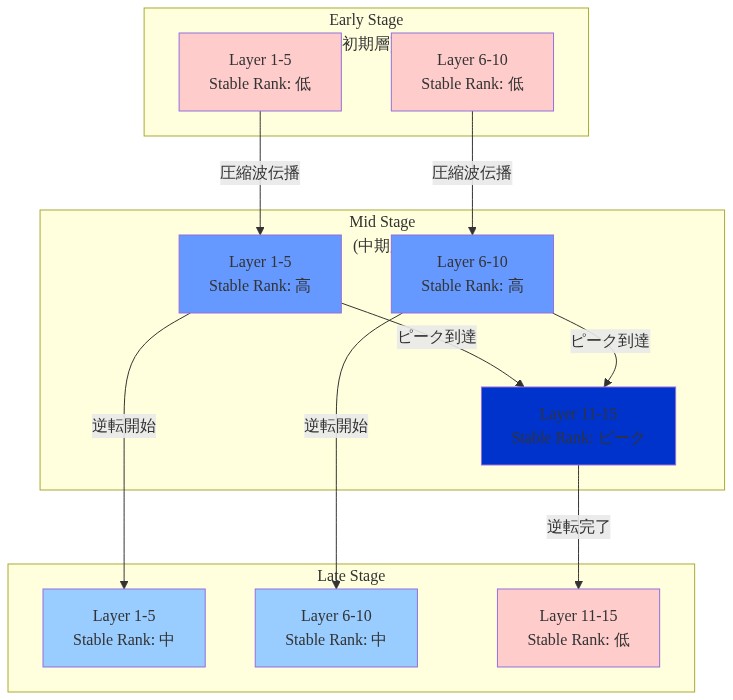
- 図2:安定ランク圧縮波の伝播と逆転プロセス(30M-285Mパラメータモデル、25ステップ間隔でのSVD追跡)*

- 図6:Q/K/V投影行列のスペクトル非対称性分析パイプライン*
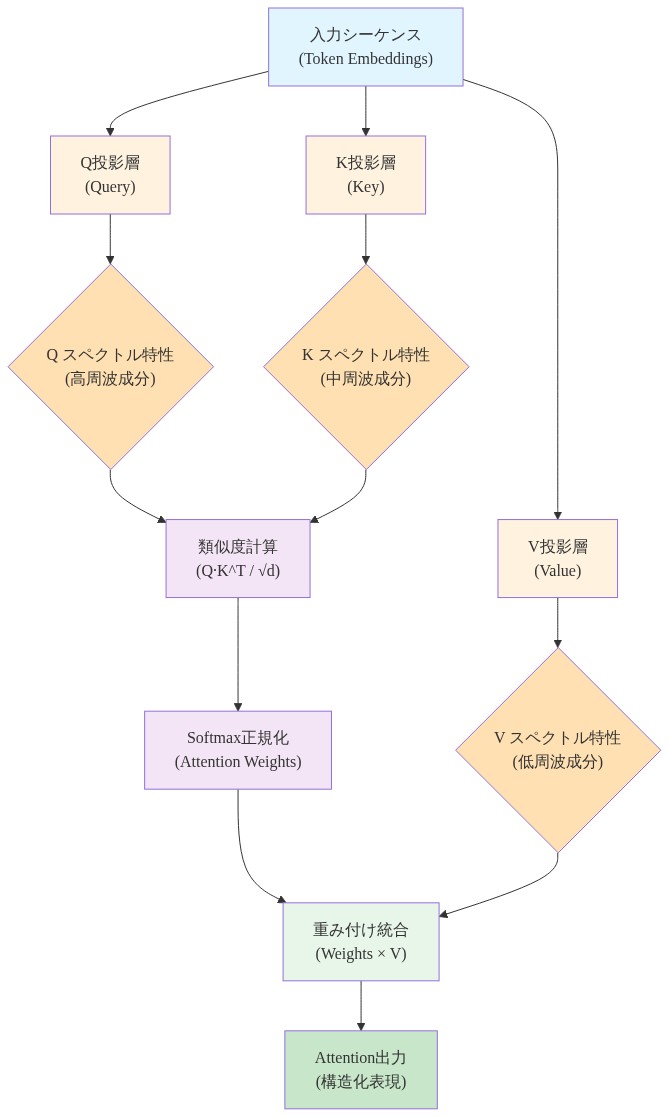
- 図8:Attention機構内のQ/K/V非対称性と情報フロー(スペクトル特性に基づく階層構造)*