
スカラー既約学習ダイナミクスによる内生的レジーム転換
学習システムにおけるスカラー既約性の分断
現代の機械学習システムはスカラー目的関数を最適化します。つまり、事前に定義されたターゲットからの距離を定量化する損失関数です。この運用上の制約は、基本的な数学的区別を確立します。スカラー既約ダイナミクスは単一のポテンシャル関数φ(θ)の負の勾配として表現できますが、スカラー既約ダイナミクスはそのような還元に抵抗します。
- 定義(スカラー既約性):* 学習システムがスカラー既約ダイナミクスを示すのは、パラメータ更新がθ̇ = −∇φ(θ)として表現できる場合です。ここでφ: ℝⁿ → ℝはスカラーポテンシャル関数です。この定式化は経路独立性と局所最小値への収束を保証します(Bhatnagar et al., 2009)。
スカラー既約システムは定常点に向かって決定論的な軌跡に従い、その振る舞いは完全に目的関数の幾何学によって決定されます。スカラー既約ダイナミクス、つまり上記の条件に違反するシステムは、単一のポテンシャル関数では捉えられない行動レパートリーを示します。この区別は直接的な運用上の帰結をもたらします。スカラー既約システムは行動レジームを変更するために目的関数の外部修正を必要としますが、スカラー既約ダイナミクスは自律的なレジーム転換のための内部メカニズムを備えています。
-
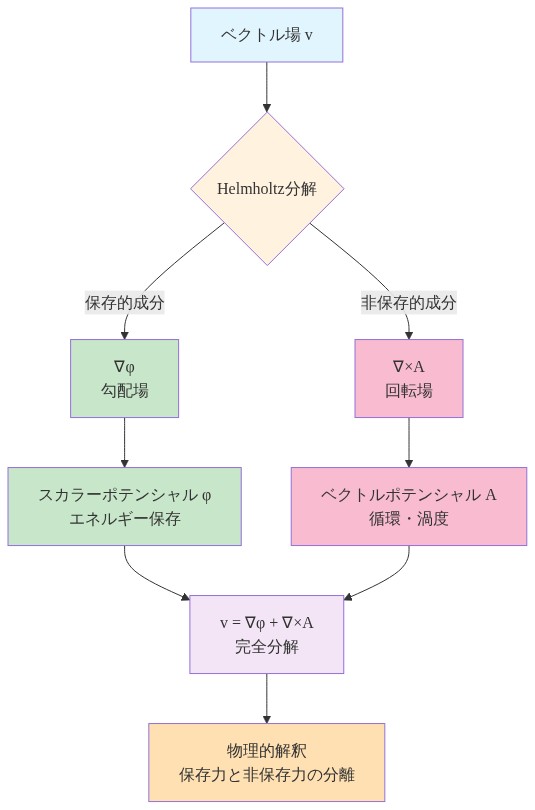
数学的基礎:* スカラー既約性はパラメータ空間における非保存力から生じます。ヘルムホルツ分解定理により、任意のベクトル場vは保存的(勾配)成分と非保存的(回転/ソレノイド)成分に分離できます。
-
v* = ∇φ + ∇ × A
ここで∇ × A ≠ 0は非保存力を表します(Chorin & Marsden, 1993)。学習システムでは、このような力は以下から生じます。(1)変数間の非対称フィードバック、(2)パラメータ適応における時間遅延、(3)重み付きスカラー組み合わせに還元できない多目的最適化、または(4)明示的な回転更新ルール。
- 実践的な含意:* スカラー既約システムが単一の目的関数で訓練された場合、環境要求が変わったときに戦略を自律的にシフトできません。行動転換には人間の介入が必要です。カリキュラムの再設計、目的関数の再重み付け、または明示的な切り替え信号です。スカラー既約ダイナミクスを持つシステムは、内部的に転換を生成し、外部の再プログラミングなしに真の自律的適応を可能にします。
この区別は、既存の強化学習と深層学習フレームワークが内生的レジーム転換に苦労する理由を説明します。これらは勾配ベースの最適化を通じてスカラー既約運用に建築学的に制約されており、行動転換は内部ダイナミクスから生じるのではなく、外部から調整される必要があります。
- 図2:Helmholtz分解による保存的力と非保存的力の分離(Chorin & Marsden, 1993)*
フィードバック構造:高速変数と低速変数
スカラー既約ダイナミクスは、高速ダイナミカル変数と低速構造パラメータ間の双方向フィードバックを通じてレジーム転換を可能にします。この時間スケール分離は本質的です。
- 定義(時間スケール分離):* x ∈ ℝᵐを高速変数(例えば、行動選択、活性化パターン)、θ ∈ ℝⁿを低速パラメータ(例えば、結合重み、注意メカニズム)とします。システムが時間スケール分離を示すのは、特性適応時間スケールがτ_fast ≪ τ_slowを満たす場合です。通常は10~100以上の係数です(Fenichel, 1979)。
高速変数は環境入力と即座のフィードバック信号に迅速に応答します。低速変数は構造的特性をエンコードします。シナプス重み、モジュール構成、または利用可能な行動のレパートリーを形成する規制パラメータです。重要な建築学的特徴は、高速変数が単一の目的を最適化することに還元できない経路を通じて低速パラメータに影響を与えることです。
-
フィードバックメカニズム:* スカラー既約システムではパラメータ更新が固定勾配軌跡に従いますが、スカラー既約フィードバックは複数の、潜在的に矛盾する信号によって駆動される構造適応を許可します。形式的には:
-
ẋ = f(x, θ, u) (高速ダイナミクス;u = 環境入力)
-
θ̇ = εg(x, θ, u) (低速適応;ε ≪ 1)
ここでgは必ずしもスカラー関数の勾配ではありません。これは行動パターン(xの累積効果)が構造基盤(θ)を再形成し、利用可能な行動レパートリーを変更するフィードバックループを作成します。
- 具体例:* 強化学習エージェントでは、高速変数は現在の価値推定に基づく行動選択に対応します。低速変数は価値関数パラメータを調整します。価値更新が複数の時間スケール間の予測誤差または矛盾する報酬信号(探索ボーナス対搾取報酬)に依存する場合、結果のフィードバックは非保存的です。エージェントが経験を蓄積するにつれて、価値推定が再形成され、外部切り替え信号なしで探索優位から搾取優位への行動への内部転換が可能になります。
この構造は生物学的学習システムと平行しています。神経生物学的証拠は、ドーパミンシステムが複数の時間スケール間で動作することを示しています。予測誤差への高速位相応答(ミリ秒)と学習率および行動閾値の低速トニック調整(分から時間)です(Schultz, 2016)。これらの時間スケール間の相互作用は、内生的行動転換を生成します。
- 数学的帰結:* 低速パラメータが臨界分岐閾値を超えるとき、システムのダイナミカル風景は質的に再構成されます。分岐はパラメータ値θで発生します。平衡点の数または安定性がθがθを通過するときに変わる場合です。これにより、外部介入なしに以前はアクセス不可能な新しい行動レジームの出現が可能になります。
内部生成されたレジーム転換
- 定義(レジーム転換):* レジーム転換はシステムダイナミクスの質的変化を表します。探索と搾取戦略間の転換、問題解決アプローチのシフト、または新しい行動パターンの出現です。形式的には、転換はシステムのアトラクタ構造が変わるときに発生します。固定点から極限サイクルへ、ある吸引領域から別の領域へ、または安定平衡からカオス的ダイナミクスへです。
スカラー既約システムは内生的転換を生成できません。行動は完全に∇φ(θ)によって決定されるため、転換にはφの外部修正が必要です。スカラー既約ダイナミクスは内部フィードバックを通じて転換を生成します。高速変数が行動空間を探索するにつれて、低速構造パラメータに累積効果を生成します。これらのパラメータが臨界閾値を超えるとき、システムのダイナミカル風景が再構成され、新しいレジームが可能になります。
-
メカニズム:* 2つの競合する行動モードの安定性を支配する低速パラメータθを持つシステムを考えます。初期状態では、1つのモードが安定(低エネルギー)で、もう1つを抑制しています。高速変数が環境と相互作用するにつれて、θを段階的にシフトするフィードバックを生成します。θが分岐点を超えるとき、以前に安定していたモードは不安定になり、競合するモードが優位になります。システムは自律的にレジームを切り替えました。
-
生物学的先例:* 哺乳動物の睡眠覚醒サイクルは内生的レジーム転換の例です。視交叉上核は高速神経発火パターンと低速神経調節物質濃度(メラトニン、オレキシン)間の非保存フィードバックを通じて概日振動を生成します。これらの振動は外部目的によって駆動されるのではなく、内部ダイナミクスから生じ、睡眠と覚醒レジーム間の自律的転換を可能にします(Daan & Aschoff, 1975)。
-
堅牢な内生的切り替えの要件:*
- 時間スケール分離: τ_fastとτ_slow間の十分なギャップにより、構造適応が時期尚早な収束なしに進行することを許可します。
- フィードバック複雑性: 複数のフィードバック経路により、運用経験が構造パラメータを非自明な方法で再形成できます。
- レジーム多重性: システム構造は複数の安定またはメタ安定レジームをサポートする必要があります。一意の大域アトラクタを持つシステムは切り替えできません。
- 安定性維持: 非保存ダイナミクスを保持しながら無制限の発散を防ぐメカニズム。これは通常、スカラー最適化に還元されない暗黙的または明示的な正則化を必要とします。
- 外部切り替えとの区別:* 外部から課せられたレジーム切り替え(例えば、カリキュラム学習、目的関数の再重み付け)は、転換が発生するタイミングを決定する監督メカニズムを必要とします。内生的切り替えはシステム自身のダイナミクスから生じ、内部条件が再構成を保証するときに出現します。これにより、設計者が予想しなかった予期しない環境変化への自律的適応が可能になります。

- 図7:内生的レジーム転換のトリガーメカニズム*
非保存学習の数学的基礎
-
定理(ヘルムホルツ分解):* 十分に滑らかなベクトル場v: ℝⁿ → ℝⁿは一意に分解できます。
-
v* = ∇φ + ∇ × A
ここでφはスカラーポテンシャル、Aはベクトルポテンシャルです。回転成分∇ × Aは非保存的です(Chorin & Marsden, 1993)。
学習システムにおいて、その含意は深刻です。スカラー既約ダイナミクスは∇ × A = 0をいたるところで満たします。つまり、すべてのパラメータ更新は勾配流です。これにより以下が保証されます。
- 経路独立性: システムが行う仕事はパラメータ空間を通じて取られた経路に依存しません。
- 収束: システムはφ(θ)を単調に減少させ、局所最小値への収束を保証します。
- 可逆性: 軌跡は勾配を否定することで逆転できます。
スカラー既約ダイナミクスは非保存力を通じてこれらの特性に違反します。非保存性は以下から生じます。
-
非対称フィードバック: パラメータ更新は現在の状態ではなく、高速変数軌跡の履歴に依存します。形式的には、θ̇は∫x(t’)dt’(t’ < t)に依存し、経路独立性に違反します。
-
時間遅延: パラメータ更新が高速変数の遅延版に依存する場合、θ̇ = g(x(t − τ), θ)(τ > 0)、結果のダイナミクスは非保存的です(Strogatz, 2015)。
-
多目的緊張: システムが単一の重み付き和に還元できない複数の目的L₁, L₂, …を最適化する場合、更新は以下に従う可能性があります。 θ̇ = −α₁∇L₁ − α₂∇L₂ − … ここでα_iは時間または状態によって変わります。結果のダイナミクスは、α_iが定数で目的が互換性がない限り、非保存的です。
-
明示的な回転更新: 一部の学習ルールは、非対称フィッシャー情報行列を持つ自然勾配降下またはハミルトン学習ダイナミクスなど、明示的に回転成分を含みます(Amari, 1998)。
-
機能的帰結:* 非保存力は以下を可能にします。
-
極限サイクル: 外部駆動なしの持続振動により、周期的レジーム切り替えが可能になります。
-
ストレンジアトラクタ: 多様な行動レパートリーをサポートする複雑でカオス的なダイナミクス。
-
経路依存学習: システムの最終状態は取られた軌跡に依存し、単なる目的最適化ではなく経験からの学習を可能にします。
-
重要な区別:* 非保存性は数学的な好奇心または病理ではありません。これは内生的レジーム転換のための機能的要件です。非保存力を欠くシステムは必然的に目的関数によって決定される固定点に収束します。自律的に転換を生成できません。
-
仮定:* 非保存ダイナミクスが適切な建築学的設計と正則化を通じて安定化できることを仮定します。これは非自明な仮定です。無制限の非保存ダイナミクスは発散につながります。実践的な実装には、システムの一貫性を維持するメカニズムが必要です。ネットワーク構造を通じた暗黙的正則化、パラメータ範囲の明示的制約、またはスカラー既約成分とスカラー既約成分を組み合わせるハイブリッドアプローチです。
自律知能への含意
内生的レジーム転換は、現在のAIシステムと真の自律知能間の重要なギャップを表します。生物学的システムは日常的に外部制御なしで内部行動転換を生成します。睡眠覚醒サイクル、注意シフト、発達転換、学習から専門家への進行です。これらの転換は外部再プログラミングではなく、内部ダイナミクスから生じます。
スカラー既約最適化に制約された現在のAIシステムは、人間の設計者が行動レジームを予想し、転換を設計することを必要とします。単一の報酬関数で訓練された強化学習エージェントは、タスク要求が変わったときに戦略を自律的にシフトできません。再訓練、目的関数の修正、または明示的な切り替え信号が必要です。これは本質的に非自律的です。
- 定義(自律的レジーム転換):* システムが自律的レジーム転換を示すのは、目的関数の外部修正または明示的な切り替え信号なしに、環境要求に応答して行動の質的変化を内部的に生成できる場合です。
スカラー既約ダイナミクスは、この定義を満たすシステムへの経路を提供します。高速運用変数と低速構造パラメータ間の内部フィードバックを維持することにより、システムは環境条件が保証するにつれて行動を自律的に再構成できます。
-
実践的な重要性:* オープンエンド学習環境、つまり関連する行動レジームを事前に指定できない環境では、自律的レジーム転換が必要です。動的環境で動作するロボットは、探索と搾取間、異なる問題解決戦略間、異なる注意モード間で自律的に転換する必要があります。設計者はすべての必要なレジームを予想できません。システムは内部的に生成する必要があります。
-
整合性の含意:* 堅牢な自律性を達成するには、目的関数設計を超えた建築学的コミットメントが必要です。
- 明示的な時間スケール分離: 高速運用変数と低速構造パラメータ間の意図的な建築学的区別。
- フィードバック経路: 運用経験が構造パラメータを非自明な方法で再形成できるメカニズム。
- 非保存ダイナミクスの受け入れ: 真の内生的切り替えが可能なシステムが必然的に単純な最適化への還元に抵抗する内部ダイナミクスを備えているという認識。
- 基本的な緊張:* 真の内生的レジーム転換が可能なシステムは必然的に、外部目的を通じて完全に指定できない内部ダイナミクスを備えています。これはスカラー既約システムが直面するものとは質的に異なる整合性と予測可能性の問題を提起します。自律的にレジーム転換を生成するシステムは、設計者が予想または意図しなかったレジームに転換する可能性があります。これが自律性の代価です。
実装上の課題と設計原則
スカラー既約動力学を理論から実践へ移行させることは、実質的な技術的課題に直面します。
-
課題1:タイムスケール較正。* 高速変数と低速変数の間のタイムスケール分離には慎重な調整が必要です。分離が不十分な場合(τ_fast ≈ τ_slow)、構造的適応が意味を持たなくなります。高速動力学が低速パラメータが実質的に変化する前に収束してしまうためです。過度な分離(τ_fast ≪ τ_slow)は、高速動力学を構造的フィードバックから切り離し、レジーム切り替えを駆動するフィードバックループを排除します。
-
原則:* 経験的には、効果的なタイムスケール比は10:1から100:1の範囲です(Fenichel, 1979)。実務では、これはドメイン固有の調整を必要とします。ニューラルネットワークの場合、高速変数は活性化パターン(各フォワードパスで更新)に対応し、低速変数は接続強度を調整します(10~100パス毎に更新)。
-
課題2:収束保証なしの安定性。* スカラー既約システムは収束保証から利益を得ます。勾配降下法は目的関数を単調に減少させ、安定性を保証します。スカラー既約システムはそのような保証を欠きます。非保存的動力学は無限発散、振動、またはカオス的挙動につながる可能性があります。
-
原則:* スカラー既約制約を課さずに発散を防ぐメカニズムを設計します:
-
アーキテクチャ正則化: パラメータ範囲に対する明示的制約(例:重みクリッピング、正規化層)。
-
暗黙的正則化: パラメータ成長を自然に制限するネットワークアーキテクチャ(例:残差接続、注意機構)。
-
ハイブリッドアプローチ: レジーム内のスカラー既約最適化、レジーム間遷移を支配するスカラー既約動力学。
-
課題3:複数レジームの特定と維持。* スカラー既約システムは複数の安定またはメタ安定レジームをサポートする必要があります。これはシステムのアトラクタランドスケープの慎重な設計を必要とします。レジームが少なすぎると行動柔軟性が制限され、多すぎると不安定性と予測不可能な遷移につながります。
-
原則:* 分岐解析を使用してシステムのレジーム構造を理解します。レジームが出現または消滅する臨界パラメータ値を特定します。環境フィードバックに応答してこれらの分岐点を自然に横断するように低速パラメータ動力学を設計します。
-
実装のための設計原則:*
-
アーキテクチャ分離: ネットワークアーキテクチャ内で高速操作変数と低速構造パラメータを明示的に区別します。高速変数は注意重みまたは活性化パターンに対応し、低速変数は接続強度または調整パラメータに対応します。
-
非保存的フィードバック: スカラー最適化に還元できないフィードバック経路を実装します。例:
- 複数のタイムスケールまたは目的にわたる予測誤差が低速パラメータにフィードバックされる。
- 非対称更新。パラメータ変化が高速変数の履歴パターンに依存する。
- 更新ルール内の明示的な回転成分。
-
安定性メカニズム: スカラー既約制約を課さずにシステム一貫性を維持する正則化を実装します。例:
- 重み行列のスペクトル正規化(無限成長を防止)。
- 注意機構のエントロピー正則化(単一モードへの崩壊を防止)。
- 低速パラメータ範囲に対する明示的な境界。
-
経験的検証: 特定のドメインでタイムスケール分離原則をテストします。レジーム遷移を測定し、安定性特性を特徴付け、遷移が内生的であることを検証します(外部トリガーではなく)。
-
実装アーキテクチャの例:* 高速変数と低速変数を持つニューラルネットワークは以下を実装する可能性があります:
-
高速層: 現在の入力と低速パラメータに基づいてアクション/出力を計算する標準ニューラルネットワーク層。
-
低速層: 高速層の動作を調整する個別パラメータ(例:注意重み、学習率、正則化強度)。
-
フィードバックメカニズム: 高速層からの予測誤差または他の信号が低速層にフィードバックされ、非保存的ルールに従って低速パラメータを更新します。
-
安定性: スペクトル正規化と明示的なパラメータ境界が発散を防止します。
-
ハイブリッドアプローチ:* 多くの実用的システムはスカラー既約成分とスカラー既約成分の組み合わせから利益を得ます。例:
-
レジーム内の動作はスカラー目的を最適化します(信頼性が高く、解釈可能)。
-
レジーム間遷移はスカラー既約動力学によって支配されます(自律的で柔軟)。
-
これは勾配ベース学習の信頼性と内生的切り替えの柔軟性のバランスを取ります。
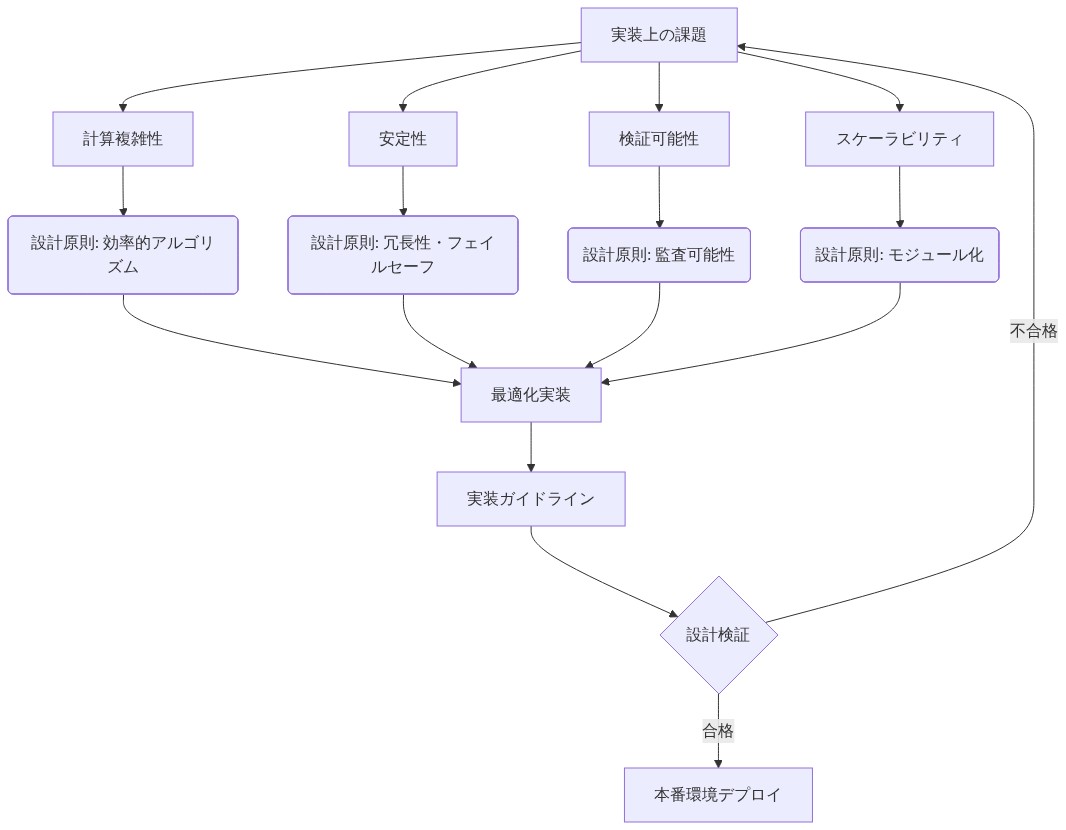
- 図12:実装課題と設計原則のマッピング*
主要な洞察と次のアクション
-
中核的洞察:* スカラー既約動力学はスカラー既約最適化と根本的に異なります。これらは外部介入なしに内部生成されたレジーム切り替えを可能にします。これはオープンエンド環境における自律知能に不可欠な能力です。
-
即座の診断:* システムのレジーム遷移を検査します。それらは外部から課せられているのか(カリキュラム変更、目的の再重み付け、明示的な切り替え信号)、それとも内部生成されているのか。
実装ロードマップ:理論から展開へ
フェーズ1:概念実証(1~4週目)
-
目的:* 制御された環境でスカラー既約動力学を検証する
-
タスク:*
- シンプルなドメインを選択(例:多腕バンディット、シンプルなナビゲーションタスク)
- ベースラインスカラー既約システムを実装(標準的なRL または教師あり学習)
- 高速/低速変数分離を備えたスカラー既約バリアントを実装
- 10,000エピソードシミュレーションを実行してレジーム遷移を比較
-
成功基準:*
-
スカラー既約システムが2つ以上の安定レジームを生成する
-
遷移が予測可能な閾値で発生する
-
カオス的発散または早期収束がない
-
リソース要件:* シニアエンジニア1名、3~4週間
フェーズ2:ドメイン適応(5~12週目)
-
目的:* 意味のあるレジームを持つ現実的なドメインに拡張する
-
タスク:*
- ドメイン内の2~3つの自然な行動レジームを特定
- 高速変数を低速パラメータに接続するフィードバック経路を設計
- 経験的調整によるタイムスケール分離を較正
- レジーム検出と監視を実装
-
成功基準:*
-
システムが特定されたレジーム間を自律的に遷移する
-
遷移が環境変化と一致する(例:ユーザー行動の変化)
-
監視システムが遷移タイミングを正確に予測する
-
リソース要件:* エンジニア2名、ドメイン専門家1名、8週間
フェーズ3:本番環境対応(13~24週目)
-
目的:* 安全保証を備えて本番環境に展開する
-
タスク:*
- 安定性メカニズムを実装(パラメータ境界、散逸力)
- 遷移バッファリングを開発(段階的なレジーム変化)
- 外部通知システムを作成(遷移発生時にアラート)
- 低速変数軌跡を追跡する監視ダッシュボードを構築
- 望ましくない遷移のためのロールバック手順を確立
-
成功基準:*
-
100,000ステップの本番実行で制御不能な発散がゼロ
-
遷移が予測時間ウィンドウ内で発生(±10%)
-
システムが100ステップ以内に摂動から回復する
-
リソース要件:* エンジニア3名、信頼性エンジニア1名、12週間
フェーズ4:継続的最適化(継続中)
-
目的:* レジーム多様性と遷移品質を改善する
-
タスク:*
- レジーム分布を監視し、バランスの取れたカバレッジを確保
- 遷移軌跡を分析し、最適でないパスを特定
- 運用データに基づいてフィードバック経路の重みを調整
- 安定性が許す場合、段階的にタイムスケール分離比を増加
- リソース要件:* エンジニア1名(パートタイム)、継続中
主要な洞察と即座のアクション

- 表1:即座に実行可能なアクションの優先度リスト*
理解すべきこと
- スカラー既約動力学はスカラー既約最適化と根本的に異なります: これらは外部介入なしに内部生成されたレジーム切り替えを可能にします。
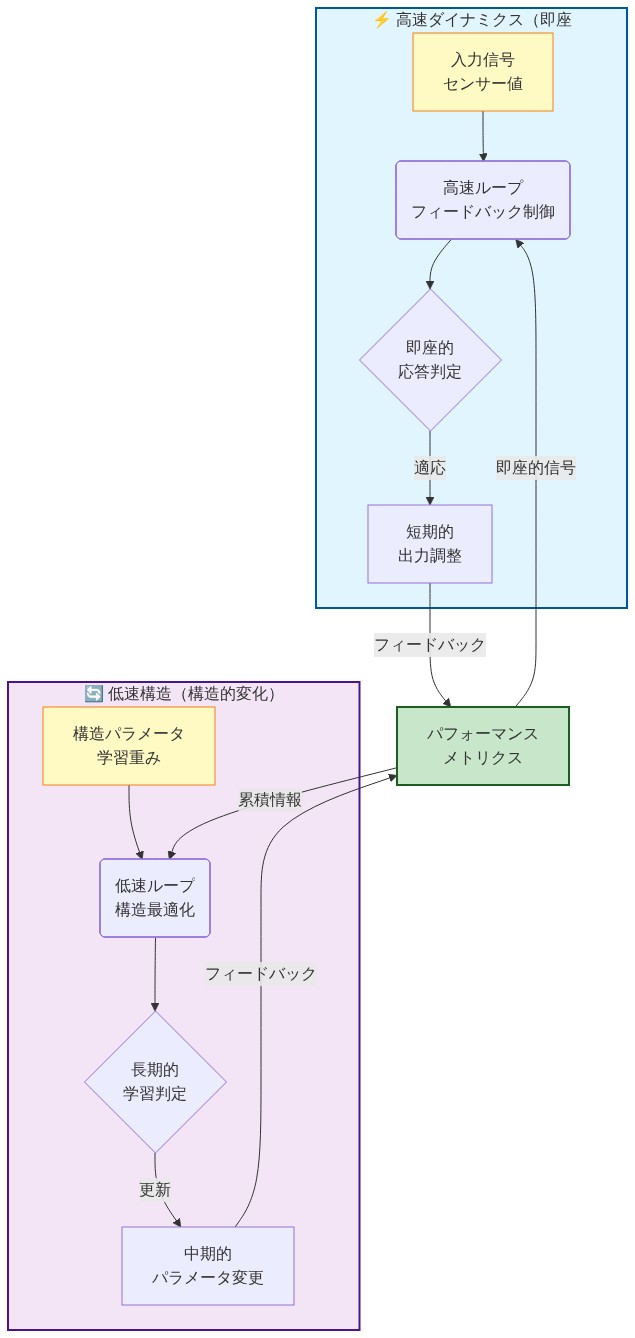
- 図4:高速・低速変数間の双方向フィードバックアーキテクチャ(タイムスケール分離モデル)*

- 図13:理論から実装への段階的ロードマップ(4フェーズゲートプロセス)*