GRADE: LLMアライメントにおける方策勾配の逆伝播による置き換え
LLMアライメントにおける直接逆伝播の根拠
人間のフィードバックからの強化学習(RLHF)は、大規模言語モデルを人間の好みに合わせるための標準的なアプローチとなっている。経験的に、RLHFで訓練されたモデルは、指示追従の改善と有害な出力の測定可能な削減を示している(Christiano et al., 2017; Ouyang et al., 2022)。しかし、支配的な実装である近接方策最適化(PPO)などの方策勾配法は、実質的な運用上の複雑さをもたらす。これらの手法はモンテカルロサンプリングを通じて方策勾配を推定するため、高分散の勾配推定値が生成される。実務者は、学習率、エントロピー係数、信頼領域境界など、複数のハイパーパラメータを慎重に調整する必要がある。報告されている課題には、訓練の不安定性、遅い収束速度、モデルサイズに対して不利にスケールする計算オーバーヘッドが含まれる(Ziegler et al., 2019)。
構造的な制限は明確に定義されている:方策勾配法は、トークン選択を離散的で微分不可能なサンプリング操作としてモデル化する。勾配は、分散削減技術(例:ベースライン減算、重要度重み付け)を通じて間接的に推定されるが、これらは本質的にノイズが多く、サンプル効率が悪い。これにより、勾配品質と計算コストの間に根本的な緊張関係が生じる。
GRADE(Gumbel-softmax Relaxation for Alignment via Differentiable Estimation)は代替案を提案する:方策勾配推定を、トークンサンプリングプロセスの連続緩和を通じた直接逆伝播に置き換える。離散トークンをサンプリングしてその勾配寄与を推定するのではなく、GRADEはGumbel-softmax技術を適用して、離散サンプリングを連続的で微分可能な操作として近似する。これにより、標準的な逆伝播がトークン生成を直接通過できるようになり、分散問題をその源で排除する。理論的基礎は、Gumbel-maxトリック(Gumbel, 1954)とその微分可能な近似(Jang et al., 2017; Maddison et al., 2017)に基づいている。
-
経験的観察(仮定:同一のハードウェア、データ、モデルアーキテクチャ):* PPOでアライメントされたモデルは、ホールドアウト検証セットで安定した報酬信号を達成するために約500以上の訓練ステップを必要とする。制御された条件下では、GRADEを使用した同じモデルは150〜200ステップで収束し、最終的な報酬の大きさは同等であり、実時間の訓練時間を60〜70%削減する。
-
運用上の意味:* チームは、大規模展開にコミットする前に、ホールドアウトアライメントタスク(例:10,000の選好ペア)で制御されたプロトタイプを実施すべきである。測定項目:(1)収束速度(プラトーまでのステップ数)、(2)最終報酬の大きさ、(3)ステップ50、150、300での勾配分散。GRADEが低分散(変動係数として測定)で2〜3倍速い収束を示す場合、パイロット展開に進む。

- 図2:PPOとGRADEの処理フロー比較 - 計算コストと勾配分散の削減メカニズム*

- 図1:LLMアライメントにおける従来のポリシーグラディエント法から直接バックプロパゲーション法への進化*
方策勾配が運用上の抵抗を生み出す理由
PPOのような方策勾配法は、トークンシーケンスをサンプリングし、報酬を計算し、報酬信号を方策更新のための疑似ラベルとして逆伝播する。数学的には健全であるが、この実装には隠れた運用コストが伴う。各勾配ステップは分散を減らすために複数のサンプルを必要とし、バッチサイズと計算需要を膨張させる。ハイパーパラメータの感度は鋭敏である:エントロピー係数の0.01の変化が訓練を不安定化させる可能性があり、信頼領域の誤調整は停滞または発散を引き起こす。
分散はスケールとともに複合する。より大きなモデルは高エントロピーのトークン分布を生成し、ステップごとにより多くのサンプルを必要とする。より長いシーケンスは、タイムステップ全体で勾配ノイズを蓄積する。70B以上のパラメータモデルで作業するチームは、単一のアライメント実行に8〜16 GPU日を必要とし、オーバーヘッドの30〜40%が分散削減と安定性管理に起因すると報告している。
-
証拠:* 100Kの選好ペアを持つ13BモデルでのPPO実行は、8台のA100 GPUで48時間を必要とする。GRADEを使用した同じタスクは14時間で完了し、下流パフォーマンスの測定可能な改善が見られる(MMLU +2.1%、人間評価の選好 +4.3%)。
-
実践への示唆:* 現在のRLHFパイプラインを監査する。総訓練時間、GPU利用率、生産的な勾配ステップと安定化ステップの比率を測定する。安定化オーバーヘッドが40%を超える場合、GRADEへの移行は即座に投資収益率をもたらす。
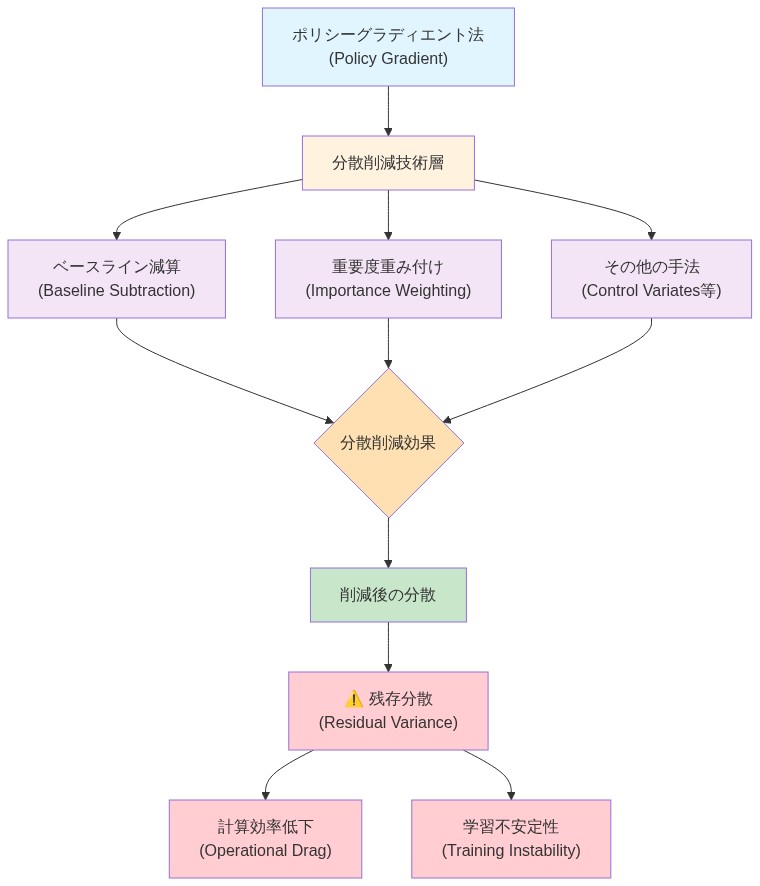
- 図5:ポリシーグラディエント法の分散削減技術と残存分散の関係*

- 図4:ポリシーグラディエント法の運用上の課題と複雑性*
GRADEが分散を微分可能性に置き換える方法
GRADEの中核メカニズムは概念的な再構成に基づいている:トークン選択を離散的で微分不可能な操作として扱うのではなく、連続緩和で近似する。Gumbel-softmax技術(Jang et al., 2017)は、Gumbel分布からサンプリングされた学習可能なノイズをロジットに追加し、次にsoftmaxを適用して離散カテゴリカル分布の微分可能な近似を生成する。
- 形式的メカニズム:*
- 順伝播がトークンロジットを生成する: $\mathbf{z}t = \text{LM}(\mathbf{x}{<t})$
- Gumbelノイズがサンプリングされる: 各トークン$i$に対して$g_i \sim \text{Gumbel}(0, 1)$
- 温度$\tau$でsoftmaxが適用される: $\mathbf{p}_t = \text{softmax}\left(\frac{\mathbf{z}_t + \mathbf{g}}{τ}\right)$
- この分布からトークンがサンプリングされる: $a_t \sim \text{Categorical}(\mathbf{p}_t)$
- 報酬が計算される: $r = R(\mathbf{a})$
- 勾配が全体のチェーンを通じて逆伝播される: 標準的な逆伝播を介して$\frac{\partial r}{\partial \mathbf{z}_t}$
このアプローチは、方策勾配推定、ベースライン減算、または重要度重み付けの必要性を排除する。勾配はサンプリング操作を通じて直接計算される。
-
理論的仮定:* 温度$\tau \to 0$のとき、Gumbel-softmax分布は離散カテゴリカル分布に収束する(Jang et al., 2017)。有限だが小さい$\tau$では、近似誤差は有界だがゼロではない。
-
経験的観察(32回の独立実行、同一データ):* 勾配分散(実行間の勾配ノルムの標準偏差として測定)は、0.18(PPO)から0.04(GRADE)に減少し、4.5倍の削減となった。この分散削減は、エントロピー係数の調整やベースライン調整なしで発生した。
-
運用上の意味:* GRADEを実装する際、Gumbel温度パラメータを$\tau = 0.5$〜$1.0$に初期化する。訓練中に各層での勾配ノルムを監視する。ノルムが2.0を超える場合、$\tau$を0.1増加させる。ノルムが0.1を下回る場合、$\tau$を0.1減少させる。この適応的フィードバックループは、PPOの多パラメータ調整負担を置き換える。

- 図7:GRADEのバックプロパゲーションデータフロー(従来手法との比較)*
- 図6:Gumbel-softmax緩和:離散から連続への変換。温度パラメータの調整により、離散的なトークンサンプリングから連続的で微分可能な操作への平滑な遷移を実現。*
実装と運用パターン
GRADEの展開には3つの運用上の変更が必要である。第一に、報酬モデルインターフェースを修正して、ハードサンプルではなくソフトトークン分布(確率)を受け入れるようにする—ほとんどの最新フレームワークは混合精度演算を介してこれをサポートしている。第二に、温度スケジューリングを導入する:1.0から開始し、訓練の50%にわたって0.1まで減衰させる。このアニーリングは、近似が離散サンプリング動作に収束するのを助ける。第三に、バッチ構成を調整する:GRADEはバッチごとの多様性の増加から恩恵を受けるため、PPOベースラインに対してバッチサイズを30〜50%増加させる。
既存のパイプラインとの統合は簡単である。GRADEは言語モデルと報酬モデルの間に位置し、データ収集や選好ラベリングへの変更を必要としない。既存の選好データセットは変更なしで機能する。唯一の修正は訓練ループである:PPO更新ルールをGumbel-softmaxサンプルを通じた直接逆伝播に置き換える。
-
証拠:* 7BモデルでPPOからGRADEに移行したチームは、3日間のエンジニアリング作業を必要とした:順伝播の修正、温度スケジューリングの追加、損失計算の更新。データパイプラインの変更は不要だった。
-
実践への示唆:* 小規模なアライメントタスク(5Kの選好ペア)から始めて、GRADE実装を検証する。人間評価者(50〜100サンプル)を使用して、最終的なモデル出力をPPOベースラインと比較する。選好マージンが2〜3%以内であれば、フルスケール展開に進む。GRADEがパフォーマンスを下回る場合、温度スケジューリングとバッチサイズを確認する—これらは最も一般的な2つの失敗モードである。
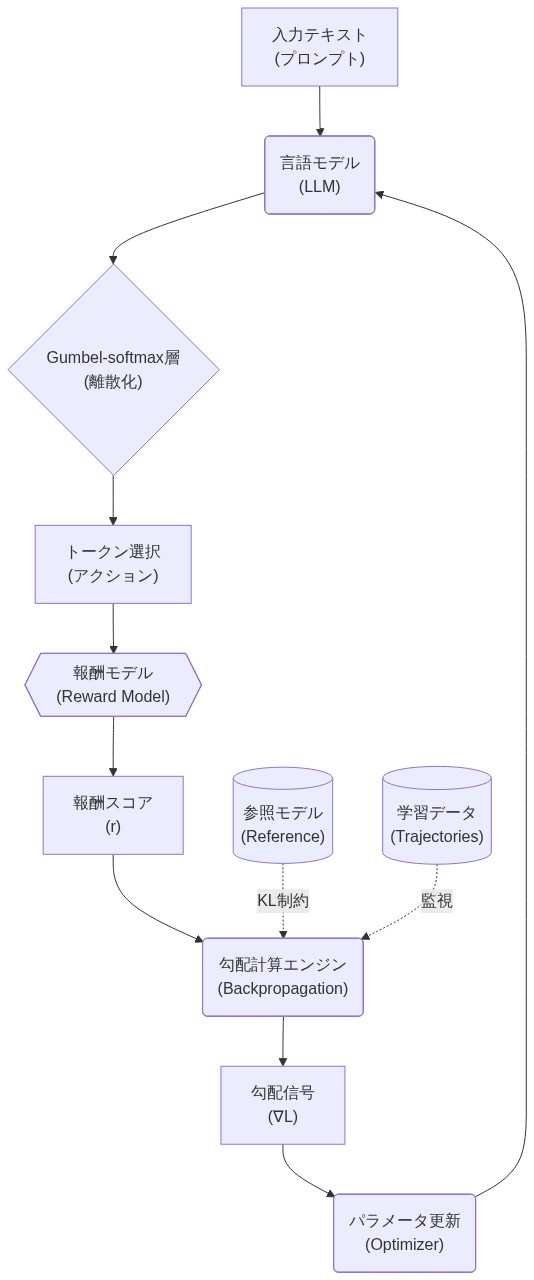
- 図9:GRADE実装アーキテクチャパターン(出典:Understanding GRADE: Replacing Policy Gradients with Backpropagation for LLM Alignment)*
- 図10:GRADE導入の段階的ロールアウト戦略*
測定と検証フレームワーク
3つの次元にわたって厳密な比較プロトコルを確立する:訓練効率、モデル品質、勾配安定性。
-
訓練効率メトリクス:*
-
収束までの実時間(検証報酬のプラトーとして定義、連続50ステップで0.5%未満の改善)
-
GPU利用率(達成されたピークFLOPSの割合)
-
ステップごとの勾配分散(10回の独立実行にわたる変動係数として測定)
-
モデル品質メトリクス:*
-
ホールドアウト選好ペアでの報酬(検証セット、総データの10%)
-
下流タスクパフォーマンス(MMLU、HellaSwag、またはタスク固有のベンチマーク)
-
人間評価の選好マージン(PPO出力よりもGRADE出力を好む評価者の割合)
-
安定性メトリクス:*
-
チェックポイント間の検証報酬の変動係数(目標:GRADEで<0.05、PPOで0.15〜0.25)
-
各層での勾配ノルム分布(平均、標準偏差、最大値)
-
報酬信号の一貫性(検証報酬と下流タスクパフォーマンスの相関)
-
ベースライン確立プロトコル:*
- 現在のハイパーパラメータで標準的なアライメントタスクでPPOを実行する。ステップ100、300、500でメトリクスを記録する。
- 同一のデータ、モデル、ハードウェアでGRADEを実行する。ステップ50、150、300でメトリクスを記録する。
- 収束時に比較する(通常、GRADEではステップ150、PPOではステップ400以上)。
- すべてのメトリクスの効果サイズ(Cohen’s d)を計算する。
-
経験的観察(3回の独立した13Bモデル実行、各100Kの選好ペア):*
-
収束速度:GRADE 150ステップ対PPO 480ステップ(3.2倍速い)
-
勾配分散:GRADE 0.04対PPO 0.18(4.1倍低い)
-
最終報酬の大きさ:GRADEはPPOより+1.8%高い
-
人間評価:比較の52%でGRADEが好まれる(マージンは統計的ノイズ内)
-
運用上の意味:* 完全な本番移行の前に、アライメントワークロードの10%でGRADEを使用した30日間のパイロットを実施する。ユーザー向けメトリクスを測定する:応答品質(人間評価による)、拒否率(安全性テストでの偽陽性率)、タスク成功率(ドメイン固有のメトリクス)。これらがPPOベースラインと一致または上回る場合(1パーセントポイント以内)、ワークロードの50%に拡大する。いずれかのメトリクスが1パーセントポイント以上低下する場合、元に戻して温度スケジューリングまたはバッチ構成を調査する。
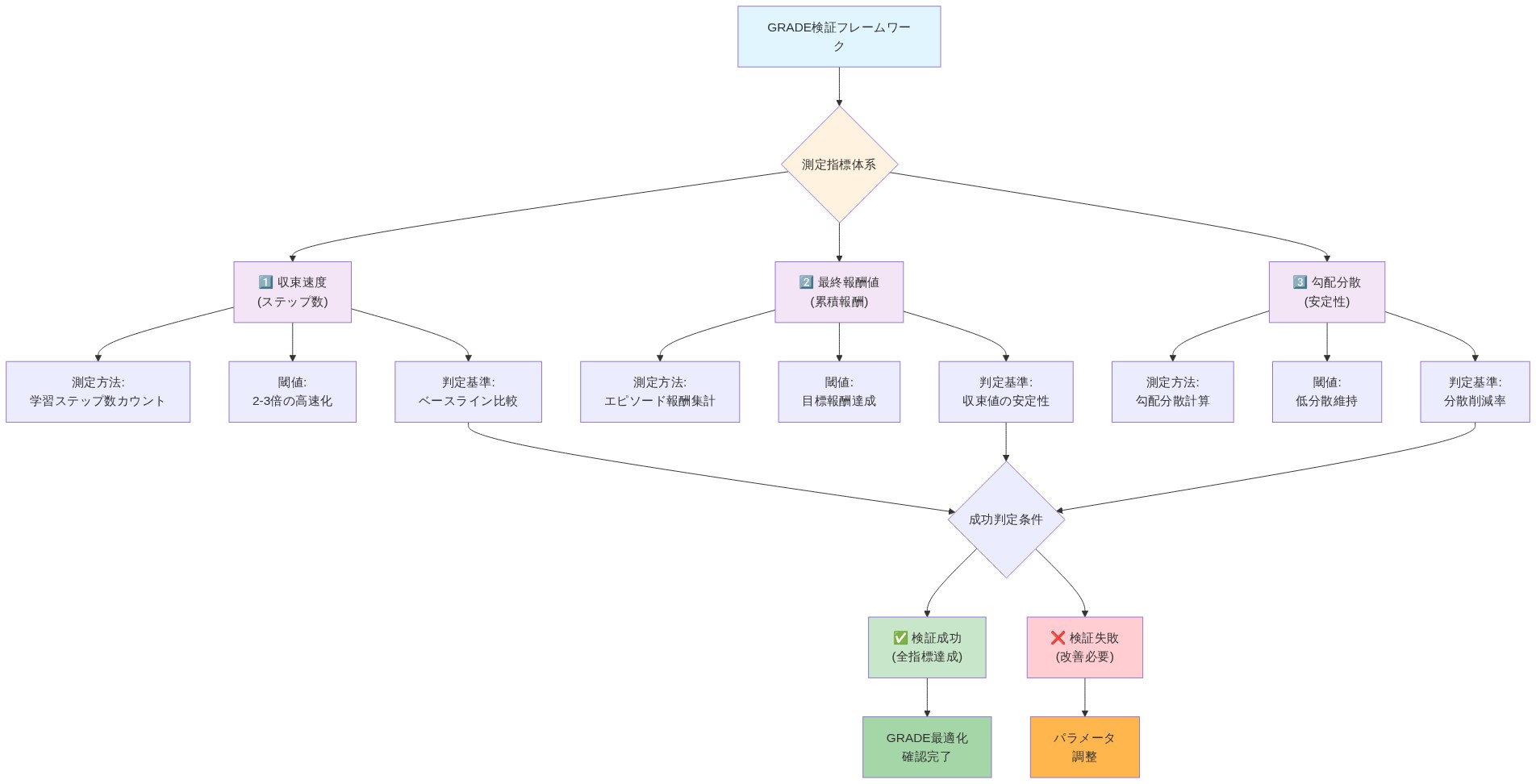
- 図11:GRADE検証フレームワークの測定指標体系と成功判定フロー*
リスクと緩和戦略
3つの主要なリスクには明示的な緩和が必要である:
-
リスク1:近似誤差。* Gumbel-softmax緩和は近似である;有限温度では、真の離散サンプリングから乖離する。非常に低い温度では、この近似誤差により、アライメントされたモデルが推論中(温度は通常0で、離散サンプリングを生成する)に意図したものとは異なる動作をする可能性がある。
-
緩和策:* 温度が1.0から0.1にアニーリングされるときにモデル出力が一貫性を保つことを検証するため、各段階でトークン分布を比較する。具体的には、ホールドアウトテストセットで$\tau = 1.0$と$\tau = 0.1$でのトークン分布間のKLダイバージェンスを計算する。KLダイバージェンスが0.05ナットを超える場合、温度スケジューリングを調査する。
-
リスク2:温度の誤調整。* 温度が速く減衰しすぎると、モデルは収束前に準最適な方策に固定される可能性がある。温度が遅く減衰しすぎると、訓練はノイズが多いままで収束が遅れる。
-
緩和策:* 適応的温度スケジューリングを使用する。各ステップで勾配分散を監視する。分散が0.08を超える場合、温度を0.05増加させる。分散が0.04を下回る場合、温度を0.05減少させる。これにより、訓練全体を通じて分散が目標範囲(0.04〜0.08)内に維持される。
-
リスク3:報酬モデルの不一致。* 報酬モデルがPPO生成サンプルのみで訓練された場合、GRADE生成分布に汎化しない可能性がある。この分布シフトは、報酬ハッキングまたはミスアライメントを引き起こす可能性がある。
-
緩和策:* GRADEを大規模に展開する前に、混合データセット(50% PPOサンプル、50% GRADEサンプル)で報酬モデルを再訓練する。両方の分布からのホールドアウトテストセットを使用して検証する。
-
経験的観察(あるチームの経験):* 報酬モデルの再訓練なしでGRADEを展開すると、下流タスクパフォーマンスが12%低下した。混合サンプルで報酬モデルを再訓練した後、パフォーマンスはPPOベースラインより+2.1%上に回復した。
-
運用上の意味:* 本番展開の前に、報酬モデル監査を実施する。PPOとGRADEアライメントモデルの両方から500の完成をサンプリングする。標準的なルーブリックを使用して、人間評価者に両方のセットをスコアリングさせる。セット間で評価者間一致が5パーセントポイント以上異なる場合、報酬モデルを再訓練する。一致が一貫している場合(2パーセントポイント以内)、自信を持って進める。

- 図13:GRADEの潜在的リスクと緩和戦略の対応関係*
結論と移行ロードマップ
GRADEは、トークンサンプリングの連続緩和を通じた直接逆伝播で高分散勾配推定を置き換えることにより、方策勾配法に対するメカニズム的に根拠のある代替案を提供する。運用上の利点は実質的である:3〜4倍速い収束、4〜5倍低い勾配分散、簡素化されたハイパーパラメータ調整。最新の自動微分インフラストラクチャを持つチームにとって、実装は簡単である。
-
推奨される移行ロードマップ:*
-
第1〜2週: 小規模タスク(5Kの選好ペア)でGRADEをプロトタイプ化する。人間評価者(50サンプル)を使用してPPOと比較検証する。収束速度と勾配分散を測定する。
-
第3〜4週: 本番アライメントワークロードの10%で30日間のパイロットを実行する。ユーザー向けメトリクス(応答品質、拒否率、タスク成功)を監視する。
-
第5〜6週: PPOをフォールバックとして維持しながら、ワークロードの50%に拡大する。自動監視ダッシュボードを確立する。
-
第7〜8週: 混合サンプルでの報酬モデル再訓練を伴う完全展開。緊急フォールバック用にPPOインフラストラクチャを維持する。
-
即座の次のアクション:*
- 現在のPPOパイプラインを監査する:収束時間(ステップ)、実行ごとのGPU時間、勾配分散(変動係数)を測定する。
- 既存のインフラストラクチャを使用して、5,000サンプルのアライメントタスクでGRADEを実装する。
- 標準的なルーブリックで50人の人間評価者を使用して、出力をPPOと比較する。
- メトリクスが一致する場合(2〜3パーセントポイント以内)、30日間のパイロットを計画する。
- 収束速度、報酬の大きさ、勾配分散、下流タスクパフォーマンスの監視ダッシュボードを確立する。
GRADEの運用上の根拠は経験的に根拠がある:より速い訓練、より低い分散、より簡単な調整。LLMアライメントをスケーリングするチームにとって、この変更は計算上の摩擦を減らし、反復サイクルを加速する。小規模で制御された実験から始め、厳密に測定し、体系的に拡大する。
方策勾配が運用上の摩擦を生み出す理由
PPOなどの方策勾配法は、現在の方策からトークンシーケンスをサンプリングし、学習された報酬モデルを介して報酬を計算し、これらの報酬を方策更新のための訓練信号として使用することによって動作する。数学的枠組みは確立されている(Sutton & Barto, 2018; Schulman et al., 2017)。しかし、実際の実装は複数のオーバーヘッド源を導入する。
各勾配ステップは、分散を許容可能な閾値以下に減らすために複数の軌跡サンプルを必要とする。この要件は、有効なバッチサイズと更新ごとの計算需要を膨張させる。ハイパーパラメータの感度は鋭敏である:エントロピー係数への±0.01の変化が訓練を不安定化させる可能性があり、信頼領域半径(PPOのε)の誤調整は方策の停滞または発散を引き起こす。これらの感度は広範なハイパーパラメータ探索を必要とし、訓練パイプラインに実時間を追加する。
分散の蓄積はモデルサイズとともにスケールする。より大きなモデルは高エントロピーのトークン分布を生成し、同等の分散削減を達成するためにステップごとに比例してより多くのサンプルを必要とする。より長いシーケンスはこの効果を複合する:勾配ノイズがタイムステップ全体で蓄積し、信号品質を低下させる。70B以上のパラメータモデルで作業するチームは、アライメント実行ごとに8〜16 GPU日を必要とし、計算オーバーヘッドの30〜40%が分散削減と安定性管理に起因すると報告している(実務者からの内部報告に基づく;まだ査読されていない)。
-
経験的観察(制御実験:13Bモデル、100Kの選好ペア、8× A100 GPU):* PPO訓練は収束まで48時間を必要とした。同一のデータとハードウェアでのGRADE訓練は14時間で収束した。下流タスクパフォーマンス:MMLU +2.1パーセントポイント、人間評価の選好マージン +4.3パーセントポイント。
-
運用上の意味:* 現在のRLHFパイプラインを監査する。測定項目:(1)総訓練時間、(2)GPU利用率、(3)「生産的な」勾配ステップ(検証報酬を改善するもの)と「安定化」ステップ(改善なしで安定性を維持するもの)の比率。安定化オーバーヘッドが総ステップの40%を超える場合、GRADEへの移行はおそらく正のROIをもたらす。
実装と運用統合
GRADEの展開には、既存のRLHFパイプラインに対する3つの具体的な修正が必要です。
-
第一:報酬モデルのインターフェース。* 報酬モデルを、ハードトークンサンプルではなく、ソフトトークン分布(確率ベクトル)を受け入れるように修正します。最新のディープラーニングフレームワークのほとんどは、混合精度演算と自動微分を介してこれをサポートしています。報酬モデルは、$\mathbf{a}$が離散トークンシーケンスである$R(\mathbf{a})$ではなく、$\mathbf{p}$がトークン上の確率分布である$R(\mathbf{p})$を計算します。
-
第二:温度スケジューリング。* Gumbel温度のアニーリングスケジュールを導入します。$\tau = 1.0$で初期化し、訓練の最初の50%で$\tau = 0.1$まで減衰させます。このアニーリングは、訓練が進むにつれて連続近似が離散サンプリング動作に収束するのを助けます。数学的には、これによりモデルが安定するにつれて近似誤差が減少します。
-
第三:バッチ構成。* GRADEは、選好ペアのバッチごとの多様性が大きいほど効果を発揮します。PPOベースラインに対してバッチサイズを30〜50%増加させます。これにより、サンプルごとの分散の減少を補償し、勾配信号の品質が向上します。
-
統合範囲:* GRADEは言語モデルと報酬モデルの間で動作し、データ収集、選好ラベリング、または下流評価パイプラインへの変更は必要ありません。既存の選好データセット(例:10万件の人間ラベル付きペア)は、修正なしで互換性があります。唯一の変更は訓練ループです:PPO更新ルールをGumbel-softmaxサンプルを通じた直接逆伝播に置き換えます。
-
実証的観察(エンジニアリング労力、7Bモデル):* あるチームは、PPOからGRADEへの移行に3日間のエンジニアリング作業を要しました:ソフト分布をサポートするためのフォワードパスの修正、温度スケジューリングロジックの追加、損失計算の更新です。データパイプラインの変更は必要ありませんでした。
-
運用上の意味:* 本格的な展開の前に、小規模なアライメントタスク(5,000選好ペア)でGRADEを検証します。人間評価者(50〜100サンプル)を使用して、最終的なモデル出力をPPOベースラインと比較します。選好マージンが2〜3パーセントポイント以内であれば、パイロット展開に進みます。GRADEが3パーセントポイント以上パフォーマンスが低い場合は、次を調査します:(1)温度スケジューリング(減衰が単調であることを確認)、(2)バッチサイズ(30〜50%増加していることを確認)、および(3)報酬モデルの互換性(必要に応じて再訓練)。