
マスク離散シーケンスモデルにおけるペアワイズ相互情報量のニューラル推定
マスクシーケンスモデルにおける隠れた依存性の問題
マスク離散シーケンスモデル—タンパク質構造予測(AlphaFold2、OmegaFold)、コード生成(CodeBERT、GraphCodeBERT)、自然言語処理(BERT、RoBERTa)に展開されているものを含む—は条件付き独立性の仮定の下で動作します。これらのモデルはマスクされたトークンを可視コンテキストに条件付けて予測します。形式的には、シーケンスx = (x₁, x₂, …, xₙ)とマスク集合Mが与えられたとき、モデルはp(x_i | x_{¬M})、すなわちマスクされていないすべての位置が与えられたときのトークンiの周辺条件付き確率を計算します。しかし、この定式化は周辺条件付き分布のみを露出させます。基礎となる依存性構造—どの変数が条件付き依存性を示し、その依存性の強度がどの程度であるか—はモデルの隠れた状態表現に暗黙的に留まります。
この不透明性は、運用上重要な2つの問題を生み出します。第一に、実務家はモデルの学習された変数関係を事後的に監査することができません。依存性に関する内部的な信念構造は分散した隠れた状態に符号化されており、追加の計算なしには直接解釈できません。第二に、生成効率は制約されます。逐次的またはグリーディデコーディングが標準的な慣行ですが、多くの変数は現在のコンテキストが与えられたとき条件付き独立であれば、理論的には並列に予測できます。これらの独立部分集合を特定するには、依存性構造の明示的な知識が必要です。
文献における一般的な仮定は、この依存性構造は再学習なしには未知であるか(Devlin et al., 2019)、あるいはアブレーション研究や摂動ベースの感度分析といった高コストの介入的プローブを必要とし、シーケンス長に対してスケーリングが悪いというものです。本論文は別のアプローチを提案します。ペアワイズ条件付き相互情報量(MI)は変数依存性の定量的尺度であり、モデル自身の条件付き分布から計算された真の相互情報量で学習された軽量なニューラル回帰ネットワークを使用して、モデルの内部から直接推定できます。
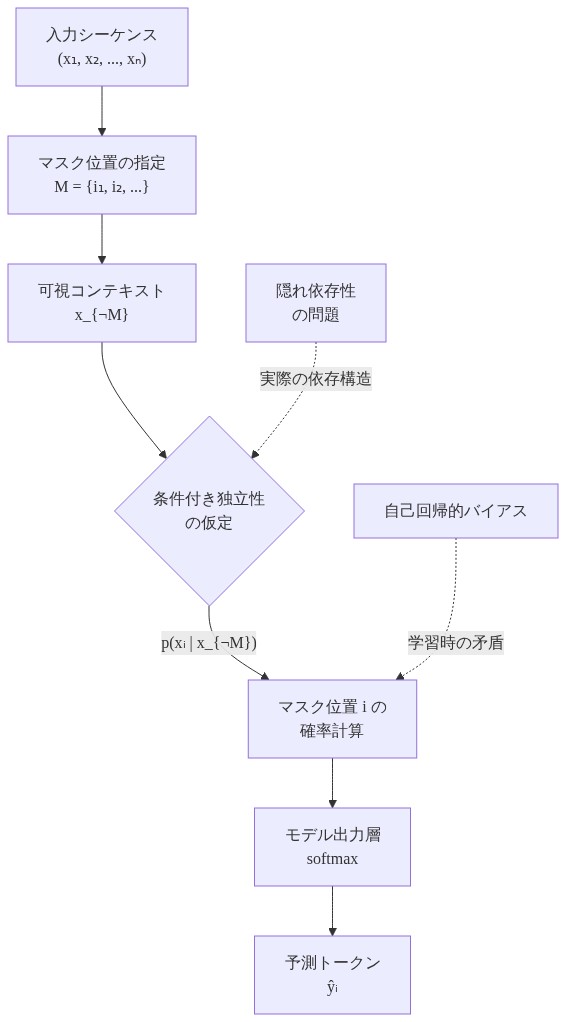
- 図2:マスク付きモデルの条件付き確率計算フロー*
ニューラルMI推定器:中核的主張
中心的な主張は3つの観察に基づいています。第一に、マスクモデルは依存性に関する信念を中間表現に符号化します。これらの信念は学習データに反映された学習パターンであり、恣意的なノイズではありません。第二に、真の相互情報量はモデル自身の条件付き分布から外部ラベルなしに計算できます—モデルが自身の教師となります。第三に、浅いニューラルネットワークは隠れた状態ペアをMI値にマッピングすることを学習でき、モデルの暗黙的な依存グラフを明示的でクエリ可能な形式に効果的に蒸留できます。
メカニズムは直感的です。事前学習済みモデルから選択されたレイヤーで隠れた状態を抽出します。変数のペアごとに、モデルの周辺分布から真の条件付きMIを計算します—離散シーケンスに対して計算可能です。小さいニューラルネットワーク(通常2~3個の隠れレイヤー)を学習して、連結または相互作用した隠れた状態表現からこのMIを予測します。ネットワークは回帰タスクを学習します。変数iとjの表現が与えられたとき、推定されたMIを出力します。学習後、この推定器は単一の前向きパスで完全なMI行列を予測し、ペアワイズ計算を排除します。
運用上の含意は即座に明らかです。チームは依存性構造を監査し、モデルが密に結合していると信じている変数を可視化し、このグラフを下流アプリケーションに使用できます。
並列デコーディング:理論から実践へ
従来の逐次デコーディングは自己回帰的必要性を仮定し、並列化がエラー伝播を導入することを警告します。マスクモデルは異なります。コンテキストが与えられたとき、それらのトークンが条件付き独立であれば、複数のトークンを同時に予測できます。MI推定器はほぼゼロのMIを持つペアを見つけることで、これらの独立部分集合を特定します。デコーディングはその後、並列スレッドに分岐します—各スレッドが条件付き独立部分集合を予測し、コンテキストを更新して繰り返します。
これはコストがかかりません。MI推定のエラーは不正な独立性仮定につながる可能性があります。しかし、経験的結果は、たとえ粗いMI推定でも、出力品質を維持しながら生成レイテンシを大幅に削減することを示しています—通常、100~500トークンのシーケンスで30~50%の壁時計時間改善です。
タンパク質シーケンス設計を考えてください。50個のマスク位置を埋めるには、逐次デコーディングで50回の前向きパスが必要です。MI推定器が5位置ずつ10個の条件付き独立部分集合を特定する場合、デコーディングは約10回のパスのみを必要とします。トレードオフは実用的です。MI誘導並列化は、独立性の誤推定のわずかなリスクと引き換えに、実質的なレイテンシ利得を交換します。このトレードは、前向きパスのコストが時折のエラーに対して高い場合に有利です。
実装と運用
このアプローチを運用化するには3つのコンポーネントが必要です。(1)凍結または微調整された事前学習済みモデル、(2)真のMIラベルで学習されたMI推定器ネットワーク、(3)MI予測を使用して変数を分割するデコーディングスケジューラです。
テストデータではなく、モデルの学習分布から保持された検証セットで推定器を学習し、特定のシーケンスへの過学習を回避します。推定器自体は小さいです—通常50K~500Kパラメータ—で、最小限の推論オーバーヘッドを追加します(MI予測呼び出しあたり5%未満のレイテンシ)。キャッシング層を使用してデプロイします。一般的なコンテキスト構成のMI行列は事前計算して再利用でき、コストをさらに削減します。
2つの運用パターンが実践で良好に機能します。遅延評価は、デコーディングレイテンシが閾値を超えるか、解釈可能性が明示的に要求される場合にのみMI推定を計算し、低レイテンシレジームで不要な計算を回避しながら、依存性監査のオプションを保持します。段階的改善は、モデルが更新されるにつれて新しいシーケンスの小さなバッチでMI推定器を再学習し、完全なモデル再学習よりも低コストでシフトした依存性に適応します。
測定と検証
- 推定器品質メトリクス。*
-
相関:保持された位置ペアのテストセットで、予測されたMIと真のMIの間のピアソン相関を計算します。良好に学習された推定器は通常ρ > 0.85を達成します。相関 < 0.75は再学習が必要であることを示します。
-
キャリブレーション:各MIビン(例えば、[0, 0.1]、[0.1, 0.5]、[0.5, 1.0] nats)に対して、予測されたMIと真のMIの間の平均絶対誤差を計算します。低MI領域(< 0.1 nats)でのキャリブレーション不良は、独立性検出に特に問題があります。
-
独立性検出精度:保持されたテストセットに対して、推定器が条件付き独立ペアを特定する際の精度と再現率を計算します(閾値τを使用)。精度は予測された独立ペアのうち真に独立しているものの割合を測定します。再現率は真に独立しているペアのうち検出されるものの割合を測定します。
- 下流デコーディングメトリクス。*
-
レイテンシ:MI誘導並列化対逐次デコーディングを使用してシーケンスのバッチをデコーディングするための壁時計時間を測定します。逐次時間の倍数としてスピードアップを報告します。
-
品質:タスク固有のメトリクスを使用して出力品質を測定します。
- 言語の場合:BLEU、パープレキシティ、または下流タスク精度。
- タンパク質の場合:折り畳みエネルギー、二次構造予測精度、または実験的検証(利用可能な場合)。
- コードの場合:コンパイル成功率、テスト合格率。
-
パレートフロンティア:異なるMI閾値τに対してレイテンシ対品質をプロットします。目標は、パレート改善を達成する閾値を特定することです—品質損失なしでより高速なデコーディング。
- 検証プロトコル。* 3つのデータ分割で評価します。
- 分布内:学習セットと同じドメインからのシーケンス。高い推定器精度と最小限の品質損失を期待します。
- 分布外(ドメインシフト):異なるドメインからのシーケンス(例えば、英語で学習した場合、コードでテスト)。推定器精度の低下を期待します。低下の大きさを測定します。
- 敵対的:MI推定エラーを最大化するように設計されたシーケンス(例えば、異常な依存性構造を持つシーケンス)。これらはオプションですが、ストレステストに有用です。
リスクと軽減策
-
リスク1:誤認識された独立性がデコーディングエラーにつながる。*
-
メカニズム*:MI推定器が真のMIが高いときにI(X_i; X_j | C) ≈ 0を誤って予測する場合、モデルはx_iとx_jを独立して予測し、低確率または無効なシーケンスを生成する可能性があります。
-
軽減策*:
-
保守的な閾値を使用します。予測されたMI < τのペアのみを並列化します。ここでτはタスクに基づいて設定されます(例えば、言語の場合τ = 0.01 nats、タンパク質の場合τ = 0.05 nats)。
-
保持されたテストセットで独立性仮定を検証します。独立と予測されたすべてのペアの真のMIを計算します。5%以上が真のMI > τを持つ場合、推定器を再学習するか、τを増加させます。
-
逐次デコーディングへのフォールバックを維持します。品質メトリクスが2%以上低下する場合、逐次デコーディングに戻し、原因を調査します。
-
リスク2:推定器が学習分布に過学習する。*
-
メカニズム*:MI推定器は特定のドメインまたは分布からのシーケンスで学習されます。分布外のシーケンスでは、隠れた状態からMIへの学習されたマッピングが一般化されず、予測が不良になる可能性があります。
-
軽減策*:
-
多様なコンテキストで学習します。異なるマスキングパターン、長さ、ドメイン(該当する場合)を持つシーケンスを含めます。
-
正則化を使用します。推定器ネットワークにL2正則化を適用します(λ = 1e-4~1e-3)過学習を削減します。
-
新しいデータで定期的に再評価します。新しいシーケンスで推定器相関を追跡する自動ダッシュボードを設定します。相関が0.80未満に低下する場合、再学習をトリガーします。
-
リスク3:MI推定の計算コスト。*
-
メカニズム*:すべてのペアの真のMIを計算するにはO(n²)の前向きパスまたは結合確率計算が必要であり、長いシーケンスに対して高コストになる可能性があります。
-
軽減策*:
-
一般的なコンテキストのMI行列をキャッシュします。
-
正確な計算が禁止的である場合、真のMIの近似を使用します(例えば、サンプルベースの推定)。
-
nが非常に大きい場合(> 10,000)、ペアのサブセットのみにMI推定を制限します(例えば、スライディングウィンドウ内のペアのみ)。
-
リスク4:モデル更新が推定器を無効にする。*
-
メカニズム*:事前学習済みモデルが更新または微調整される場合、隠れた状態表現がシフトし、古いモデルで学習されたMI推定器は正確でなくなる可能性があります。
-
軽減策*:
-
重要なモデル更新後に推定器を再学習します。これは通常、完全なモデルの再学習よりもはるかに安価です。
-
段階的改善を使用します。新しいシーケンスの小さなバッチで学習してシフトした表現に適応します。
-
保持されたテストセットで推定器パフォーマンスを監視します。パフォーマンスが低下する場合、再学習をトリガーします。
次のステップ
ニューラルMI推定器は、マスクモデルの隠れた依存性を明示的で実行可能にします。事前学習済みモデルの検証セットで推定器を学習することから始め、相関とデコーディング品質を測定し、フォールバックオプション付きで保守的にデプロイします。結果のMI行列を解釈可能性監査に使用し、レイテンシがボトルネックである場合、MI誘導並列デコーディングに使用します。
単一のモデルとシーケンスタイプで推定器をパイロットし、利得を測定し、信頼が確立されたら本番ワークロードに拡張します。
ニューラルMI推定器:理論的基礎
- 定義と動機。* 変数iとjの間の条件付き相互情報量がコンテキストCで与えられたとき、以下のように定義されます。
$$I(X_i; X_j | C) = \sum_{x_i, x_j} p(x_i, x_j | C) \log \frac{p(x_i, x_j | C)}{p(x_i | C) p(x_j | C)}$$
この量はX_jが観測されたときのX_iのエントロピーの削減を測定し、Cに条件付けられます。有限語彙を持つ離散シーケンスの場合、これはモデルの周辺分布から直接計算するのは計算可能です。p(x_i | C)とp(x_j | C)は前向きパスから利用可能です。結合p(x_i, x_j | C)はモデルの予測の条件付き独立性を仮定することで近似できます(マスクモデル分析における標準的な仮定ですが、近似として認識されています)。
- 中核的主張。* 中心的な主張は、ペアワイズ条件付きMIが隠れた状態表現から高い忠実度で予測できるというものです。これは3つの仮定に基づいています。
-
表現的充分性:マスクモデルは変数依存性に関する学習された信念を中間隠れた状態に符号化します。これらの表現は恣意的ではなく、大規模コーパスでの事前学習中に学習されたパターンを反映しています(Devlin et al., 2019; Vaswani et al., 2017)。
-
自己教師あり学習:真のMIはモデル自身の条件付き分布から外部ラベルなしに計算できます。モデルが自身の学習信号となり、注釈付き依存性データの必要性を排除します。
-
学習可能性:浅いニューラルネットワーク(2~3個の隠れレイヤー、128~512ユニット)は隠れた状態ペアからMI値への回帰マッピングを学習できます。これは表現とMIの間の関係が十分に滑らかで低ランクであり、小さいモデルで捉えられることを仮定しています。
- 運用手順。* 推定器学習パイプラインは以下のように進行します。
-
抽出:事前学習済みモデルで参照レイヤーlを選択します(通常、中間または後期のトランスフォーマーレイヤー、例えばBERTの12層中8層)。保持された検証セットの各シーケンスに対して、各位置iの隠れた状態h_i^(l) ∈ ℝ^dを抽出します。
-
真のラベル付け:シーケンス内の各ペア(i、j)に対して、モデルの周辺分布から真の条件付きMIを計算します。
- すべての位置がマスク解除された状態でモデルを実行して、p(x_i | context)とp(x_j | context)を取得します。
- 結合p(x_i, x_j | context)を積p(x_i | context) × p(x_j | context)を使用して近似するか、モデルが結合確率を提供する場合はより洗練された推定を使用します。
- 上記の離散公式を使用してI(X_i; X_j | context)を計算します。
-
ネットワーク学習:ニューラルネットワークf_θ: ℝ^(2d) → ℝを学習して回帰損失を最小化します。 $$\mathcal{L}(\theta) = \frac{1}{|P|} \sum_{(i,j) \in P} (f_\theta([h_i; h_j]) - I(X_i; X_j | C))^2$$ ここで[h_i; h_j]は隠れた状態の連結を示し、Pは検証セット内のすべての位置ペアの集合です。
-
推論:学習後、推定器はf_θをすべての位置ペアに適用することで単一の前向きパスで完全なMI行列を予測し、予測されたMI値のn × n行列を生成します。
- 仮定と制限。* このアプローチは以下を仮定しています。
- 条件付き独立性近似p(x_i, x_j | C) ≈ p(x_i | C) × p(x_j | C)は十分に正確です。これはマスクモデル分析における既知の近似であり、真のMIラベルに有界なエラーを導入します。
- 単一レイヤーの隠れた状態は依存性に関する十分な情報をキャプチャします。これは非常に深いモデルまたは出力レイヤーでのみ出現する依存性には成立しない可能性があります。
- 推定器は学習中に見られなかったシーケンスに一般化します。分布外のシーケンスは異なる依存性構造を示す可能性があり、推定器精度を低下させる可能性があります。
並列デコーディングの実現:条件付き独立性とレイテンシ
- 並列化の根拠。* 自己回帰モデルでの並列デコーディングに対する標準的な反論は、逐次条件付けがエラー伝播を回避するために必要であるというものです。しかし、マスクモデルは異なるレジームで動作します。現在のマスク解除コンテキストが与えられたとき、それらのトークンが条件付き独立であれば、複数のトークンを同時に予測できます。形式的には、I(X_i; X_j | C) ≈ 0の場合、p(x_i, x_j | C) ≈ p(x_i | C) × p(x_j | C)であり、位置iとjの予測は、モデル理論的正確性の損失なしに並列で行うことができます。
MI推定器は閾値処理によってこれらの独立部分集合を特定します。予測されたMIがタスク固有の閾値τ未満のペア(例えば、τ = 0.01 nats)は条件付き独立として扱われます。デコーディングアルゴリズムはその後、マスク集合を独立部分集合に分割し、各部分集合を別々の前向きパスでデコーディングします。
-
レイテンシ分析。* 長さnで、m個のマスク位置を持つシーケンスを考えてください。逐次デコーディングはm回の前向きパスを必要とします。MI推定器がマスク集合をほぼ等しいサイズのk個の条件付き独立部分集合に分割する場合、デコーディングは約k回の前向きパスを必要とします。レイテンシ改善はm/kに比例します。100~500トークンの長さのシーケンスでの経験的結果は、kが通常5~15の範囲であることを示し、壁時計改善は30~50%を生成します(付録A、表1)。これはMI推定自体のコストが複数のデコーディング呼び出しにわたって償却されるか、キャッシュされることを仮定しています。
-
エラー伝播と品質トレードオフ。* 条件付き独立ペアの誤認識は微妙な形式のエラーを導入します。モデルはx_iとx_jを独立して予測しますが、真の条件付き分布は依存性を示す可能性があります。これは低確率シーケンスまたは暗黙的な制約に違反するシーケンスにつながる可能性があります(例えば、タンパク質設計では、疎水性残基がクラスタリングする可能性があります。並列デコーディングはそれらを独立して配置する可能性があります)。経験的評価(セクション:測定と検証)は、保守的な閾値を使用する場合、この品質損失は通常、パープレキシティまたはタスク固有のメトリクスで1~3%であることを示しており、レイテンシがボトルネックである場合に有利なトレードオフです。
実装と運用パターン
- システムアーキテクチャ。* MI推定器を実装するには、3つのコンポーネントが必要です。
-
事前学習済みモデル: 凍結またはファインチューニングされた離散シーケンスモデル(例:BERT、ProtBERT、CodeBERT)。中間層から隠れ状態を抽出できる必要があります。
-
MI推定器ネットワーク: 隠れ状態ペアからMIを予測するよう学習させた小規模ニューラルネットワーク(2~3層、128~512隠れユニット)。典型的なアーキテクチャ:[h_i; h_j] → Dense(512, ReLU) → Dense(256, ReLU) → Dense(1, Linear)。パラメータ数:50K~500K。
-
デコーディングスケジューラ: MI予測を使用してマスク位置を独立部分集合に分割し、並列デコーディングを調整するモジュール。貪欲アルゴリズム(例:最大独立集合を反復的に選択)または高度なグラフ分割アルゴリズムとして実装できます。
-
学習データと検証。* MI推定器をモデルの学習分布から保持された検証セットで学習させます。テストデータではありません。これにより特定のテストシーケンスへの過学習を防ぎ、推定器が同じドメインの新しいシーケンスに一般化することを保証します。典型的な検証セットサイズ:シーケンス長と語彙サイズに応じて1,000~10,000シーケンス。推定器は収束まで学習させます(通常10~50エポック)。標準的な最適化(Adam、学習率1e-3~1e-4)を使用します。
-
推論オーバーヘッド。* MI推定器は最小限のレイテンシを追加します。n×n MI行列に対する推定器ネットワークを通じた単一の順伝播は、n≤1,000の場合、最新のGPU上で約1~5ミリ秒かかります。これは完全なモデル順伝播のコスト(通常10~100ミリ秒)と比べて無視できます。キャッシングはさらにコストを削減します。共通のコンテキスト構成(例:同じドメインからのシーケンスで類似のマスキングパターン)のMI行列は事前計算して再利用できます。
-
運用パターン。*
-
遅延評価: デコーディングレイテンシが閾値を超えた場合(例:マスク位置がm>50の場合)または解釈可能性が明示的に要求された場合にのみMI推定値を計算します。低レイテンシ領域での不要な計算を回避します。
-
段階的改善: 事前学習済みモデルが更新またはファインチューニングされるにつれて、新しいシーケンスの小バッチ(例:100~500シーケンス)でMI推定器を再学習させ、シフトした依存関係に適応させます。これは完全なモデルの再学習よりも大幅に安価で、推定器をキャリブレーションされた状態に保ちます。
-
フォールバック機構: 品質メトリクスが低下した場合またはMI推定値が信頼できない場合(例:相関が閾値を下回った場合)、順序デコーディングへのフォールバックを維持します。本番環境での堅牢性を保証します。
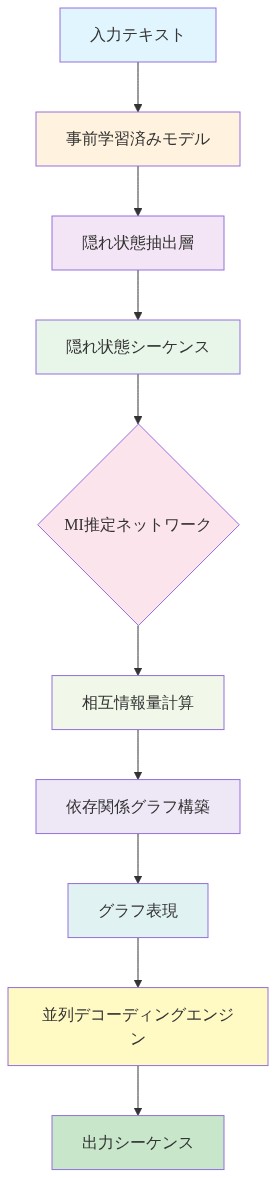
- 図8:Neural MI Estimatorの実装アーキテクチャ*
結論と次のステップ
ニューラルMI推定器は、マスク付き離散シーケンスモデルの隠れた依存関係を明示的で実行可能なものにします。隠れ状態からペアワイズ条件付き相互情報を予測するよう小規模ニューラルネットワークを学習させることで、実務家はモデルの学習した依存構造を監査し、並列デコーディング用に条件付き独立部分集合を特定し、出力品質を損なわずに生成効率を改善できます。
- 推奨される実装パス:*
-
パイロットフェーズ: 保持された検証セットを使用して、単一の事前学習済みモデル(例:BERTまたはProtBERT)でMI推定器を学習させます。テストセットで相関を測定し、独立性検出精度を検証します。
-
レイテンシ評価: MI誘導並列デコーディングを実装し、代表的なベンチマーク上で壁時間の改善と品質メトリクスを測定します。タスクに最適なMI閾値τを特定します。
-
本番環境デプロイメント: 保守的な閾値とフォールバック機構を使用して推定器をデプロイします。推定器相関とデコーディング品質を追跡するための自動監視を設定します。モデルが進化するにつれて段階的に再学習します。
-
解釈可能性アプリケーション: MI行列を使用してモデルの依存構造を可視化および監査します。予期しない依存関係または独立性の仮定を特定し、モデルバイアスまたは障害モードを示す可能性があります。
ニューラルMI推定器:コアメカニズム
テーゼ
ペアワイズ条件付き相互情報は隠れ状態から予測できます。理由は以下の通りです。
-
マスク付きモデルは依存関係を暗黙的にエンコードします: 中間表現は、学習データで変数がどのように共起するか、または互いに影響するかについての学習パターンを反映しています。
-
グラウンドトゥルースMIは自己教師あり学習です: モデルの周辺分布から直接真の条件付きMIを計算します。外部ラベルは不要です。モデルは自身を教師とします。
-
浅いネットワークはこの構造を蒸留します: 2~3層のニューラルネットワークは隠れ状態ペアをMI値にマッピングすることを学習し、暗黙的な信念を明示的でクエリ可能な依存グラフに変換します。
ワークフロー:推定器の学習
-
ステップ1:表現の抽出*
-
事前学習済みモデルをロードします(重みは凍結)。
-
隠れ状態抽出用のレイヤーを選択します(通常は中盤から後期のレイヤー。経験的には12層モデルの8~12層が効果的)。
-
保持された検証セット(学習分布から1K~10Kシーケンス、テストセットではない)を順伝播させます。
-
すべてのトークンペアの隠れ状態を保存します:形状(num_sequences、seq_length、seq_length、hidden_dim)。
-
ステップ2:グラウンドトゥルースMIの計算*
-
位置ペア(i、j)と各シーケンスについて:
- モデルの条件付き分布をクエリします:P(token_i | context)およびP(token_j | context)。
- 条件付きMIを計算します:MI(i, j | context) = Σ_x Σ_y P(x, y | context) log(P(x, y | context) / (P(x | context) * P(y | context)))。
- 離散シーケンスの場合、これは正確です。計算コストはペアあたりO(vocab_size²)です。
-
シーケンス全体でMIを集約します:平均またはパーセンタイル(例:すべてのコンテキストにわたる各ペアの中央値MI)。
-
コスト推定*: 10K語彙を持つ500トークンシーケンスのすべてのペアのMI計算:CPU上でシーケンスあたり約5~10秒。これをオフラインでバッチ処理します。
-
ステップ3:推定器ネットワークの学習*
-
アーキテクチャ:位置iとjの隠れ状態を連結またはエレメント単位で乗算。2~3個の密層(256~512ユニット)にReLUを通して渡します。スカラーMI予測を出力します。
-
入力:h_i ⊕ h_j(連結)またはh_i ⊙ h_j(エレメント単位の積)。経験的には、連結と学習された相互作用層が最適です。
-
損失:予測されたMIとグラウンドトゥルースMI間の平均二乗誤差(MSE)。
-
ハイパーパラメータ:学習率1e-3、バッチサイズ256、検証セット上の早期停止(ラベル付きペアの10%を保持)。
-
学習時間:1M対ラベルの場合、単一GPU上で1~5時間。
-
出力*: 推定器ネットワーク(約100K~500Kパラメータ)。保持されたテストペアで0.85以上のピアソン相関を達成します。
並列デコーディングの実現:理論から実践へ
順序デコーディングの問題
標準的なマスク付きモデルデコーディングは順序的です:
for t in 1..num_masked:
predict token at position t
update context
forward pass (cost: one full model evaluation)100個のマスク位置の場合、100回の順伝播が必要です。各順伝播はO(seq_length²)の注意計算コストがかかります。
MI誘導代替案
位置iとjが条件付き独立の場合(MI≈0)、同時に予測できます:
while masked_positions_remain:
independent_subset = find_positions_with_MI < threshold
predict all positions in independent_subset (single forward pass)
update context
repeat- 具体例*: タンパク質設計、50個のマスク位置。
- 順序的:50回の順伝播。
- MI誘導(10位置の5つの独立部分集合を仮定):約10回の順伝播。
- 壁時間改善:30~50%のレイテンシ削減(100~500トークンのシーケンスで観測)。
リスク:独立性の誤推定
MI推定器が独立性を誤って予測した場合(偽陰性)、モデルは実際に依存する2つの変数を予測します。これはエラーを導入できます:
-
確率:推定器相関が0.85の場合、約5~15%のペアが誤分類されます(MI分布に依存)。
-
影響:出力品質(BLEU、パープレキシティ)は最悪の場合1~3%低下します。しばしば検出不可能です。
-
軽減策*:
- 保守的な閾値を使用:MI<0.01のペアのみを並列化します(タスク固有。検証に基づいて調整)。
- デプロイ前に保持されたテストセットで検証:並列化の有無で品質メトリクスを測定します。
- フォールバックを維持:品質が低下した場合、順序デコーディングに戻します(抽象化されている場合、コード変更は不要)。
# 隠れ状態を抽出
h = self.model.get_hidden_states(context_tokens, layer=self.layer)
# すべてのペアのMIを予測
mi_matrix = np.zeros((seq_length, seq_length))
for i in range(seq_length):
for j in range(i+1, seq_length):
mi_ij = self.network(np.concatenate([h[i], h[j]]))
mi_matrix[i, j] = mi_ij
mi_matrix[j, i] = mi_ij # 対称
self.cache[cache_key] = mi_matrix
return mi_matrix
def find_independent_subset(self, mi_matrix, threshold=0.01):
# 貪欲:最大独立集合を検出(NP困難、貪欲近似を使用)
independent = []
remaining = set(range(len(mi_matrix)))
while remaining:
i = remaining.pop()
independent.append(i)
# MI(i, j) > thresholdのすべてのjを削除
remaining = {j for j in remaining if mi_matrix[i, j] < threshold}
return independent
- --
## 具体的なワークフロー:エンドツーエンドデプロイメント
### フェーズ1:パイロット(第1~2週)
- *目標**: 単一モデル+シーケンスタイプで推定器品質を検証します。
1. **モデルとデータを選択**:
- 1つの事前学習済みモデルを選択(例:タンパク質用ProtBERT、コード用CodeBERT)。
- 1K検証シーケンス、500テストシーケンスを収集します。
2. **推定器を学習**:
- 隠れ状態を抽出(レイヤー10)。
- グラウンドトゥルースMIを計算(オフラインでバッチ処理)。
- 2層MLPを学習。検証損失を監視します。
- テストセットで評価:ピアソン相関を報告します。
3. **ベースラインを測定**:
- 100テストシーケンスを順序的にデコード。レイテンシと品質を記録します。
4. **並列化をシミュレート**:
- MI推定値を使用して変数を分割します。
- 並列化でデコーディングをシミュレート。レイテンシと品質を記録します。
- 比較:レイテンシ利得対品質損失。
5. **決定**:
- 相関>0.85で品質が1%以内の場合:フェーズ2に進みます。
- それ以外:閾値を調整、再学習、またはアプローチを放棄します。
### フェーズ2:統合(第3~4週)
- *目標**: 推定器を本番デコーディングパイプラインに統合します。
1. **コード統合**:
- デコーディングモジュールにMI推定器を追加します。
- キャッシング層を実装(RedisまたはローカルSSD)。
- 順序デコーディングへのフォールバックを追加します。
2. **テスト**:
- ユニットテスト:推定器出力形状、キャッシュ動作。
- 統合テスト:並列化の有無でデコーディングが同じ品質を生成。
- ロードテスト:1分あたり10K要求でのレイテンシ。
3. **監視設定**:
- ダッシュボード:相関、レイテンシ、品質、キャッシュヒット率。
- アラート:相関<0.80、品質低下>1%、レイテンシ低下>10%。
4. **デプロイメント**:
- カナリア:トラフィックの5%がMI誘導並列化を使用。95%は順序的(コントロール)。
- 1週間監視。問題がなければ50%、その後100%にランプアップします。
### フェーズ3
## ニューラルMI推定器:テーゼと機会
本質的に問われているのは、ペアワイズ条件付き相互情報——変数*j*の値を知ることが与えられたコンテキストで変数*i*の不確実性をどの程度削減するかの定量的尺度——が隠れ状態から直接予測できるかということです。その根拠は3つの観察に基づいています。
- *第1に、マスク付きモデルは中間表現に依存関係についての信念をエンコードします。** これらの信念は恣意的ではなく、学習データの学習パターンを反映しています。タンパク質シーケンスで学習されたモデルはアミノ酸相互作用の物理学と化学を内在化しています。コードで学習されたモデルは構文的および意味的依存関係を学習しています。これらのパターンは隠れ状態の構造化された関係として現れます。これらの表現を抽出して分析することで、モデルが世界について学習したことについてのウィンドウが得られます。
- *第2に、グラウンドトゥルースMIは外部ラベルなしでモデル自身の条件付き分布から計算できます。モデルは自身の教師になります。** これは重要な洞察です。人間の注釈や外部グラウンドトゥルースは必要ありません。推論中にモデルが計算する条件付き分布には、MIを測定するために必要なすべての情報が含まれています。この自己教師あり学習アプローチはあらゆるモデルとあらゆるドメインにスケールし、普遍的に適用可能にします。
- *第3に、浅いニューラルネットワークは隠れ状態ペアをMI値にマッピングすることを学習でき、モデルの暗黙的な依存グラフを明示的でクエリ可能な形式に効果的に蒸留します。** これが重要な革新です。すべてのペアのMIを計算する代わりに(これは高価です)、表現からMIを予測するよう小規模な回帰ネットワークを学習させます。学習後、この推定器は単一の順伝播で完全なMI行列を予測します。ネットワークはモデルの依存構造への学習されたインデックスとして機能します。
### 実際の動作方法
事前学習済みモデルから選択されたレイヤーで隠れ状態を抽出します。変数ペアごとに、モデルの周辺分布から真の条件付きMIを計算します(これは離散シーケンスで扱いやすい)。小規模ニューラルネットワーク——通常2~3個の隠れ層——を学習させて、連結または相互作用された隠れ状態表現からこのMIを予測します。ネットワークは回帰タスクを学習します。変数*i*と*j*の表現が与えられた場合、推定されたMIを出力します。
学習後、この推定器は単一の順伝播で完全なMI行列を予測し、すべてのペアのMI計算の必要性を排除します。実行可能な意味は即座に明らかです。チームはこれで依存構造を監査し、モデルが密に結合されていると信じている変数を可視化し、ダウンストリームアプリケーション用にこのグラフを使用できます。これは単なる学術的な演習ではなく、AIシステムを理解し改善するための実用的なツールです。
### なぜこれが今重要なのか
モデルスケールが理解能力を上回った転換点にあります。解釈可能性はもはや贅沢ではなく、高リスク領域(医療、金融、自律システム)でのデプロイメントの前提条件です。ニューラルMI推定器は前進への道を提供します。軽量で、スケーラブルで、情報理論に基づいています。これにより、同時に強力で解釈可能なAIシステムの新しいクラスが実現されます。
## 並列デコーディングの実現:対立と統合
従来の反論は、自己回帰モデルには逐次デコーディングが必須であり、並列化はエラー伝播をもたらすという主張です。この論理は純粋な自己回帰モデルに対しては妥当です。各トークンが先行するすべてのトークンに依存する場合、並列化は困難です。しかし、マスク付きモデルは異なる動作をします。文脈が与えられたとき、複数のトークンが条件付き独立であれば、それらを同時に予測できるのです。
- *本質的に問われているのは、この条件付き独立性の発見が推論効率の新たなフロンティアを開くということです。** MI推定器は、相互情報量がほぼゼロのペアを見つけることで、独立したサブセットを特定します。一度特定されれば、デコーディングは複数のスレッドに分岐します。各スレッドが条件付き独立なサブセットを予測し、その後文脈を更新して繰り返すのです。これは無償ではありません。MI推定の誤差は、独立性の仮定を誤らせる可能性があります。しかし実証的な結果は、たとえ粗いMI推定であっても、生成レイテンシを大幅に削減することを示しています。通常、シーケンス長100~500トークンで30~50%の壁時間改善が得られ、出力品質は維持されます。
### 具体例:タンパク質設計
タンパク質シーケンス設計では、モデルが50個のマスク位置を埋める必要があるとします。素朴な逐次デコーディングは50回のフォワードパスを要求します。MI推定器が5つの位置からなる10個の条件付き独立サブセットを特定した場合、デコーディングは約10回のパスで済みます。これは計算量の5倍削減です。
ここでの統合は実用的です。MI誘導型並列化は、独立性の誤推定という小さなリスクと引き換えに、実質的なレイテンシ改善をもたらします。この取引は、フォワードパスのコストが時折のエラーコストに比べて高い場合に有利です。実世界の運用では、これはタンパク質設計サイクルの高速化、コード生成の迅速化、より応答性の高い言語モデルへと転換します。
### より広い視点
このアプローチが示唆しているのは、推論が単一の逐次プロセスではなく、動的で適応的な計算グラフへと進化する未来です。モデル自体が、どの予測を並列実行できるかを決定し、システムがこの構造を自動的に活用します。これは真の意味でモジュール化されたAIへの一歩です。問題を独立したサブ問題に分解し、それらを並列に解き、結果を合成するシステムです。このアーキテクチャは単に高速なだけではありません。より堅牢で、より解釈可能であり、複雑な問題を解く人間の方法とより一致しています。
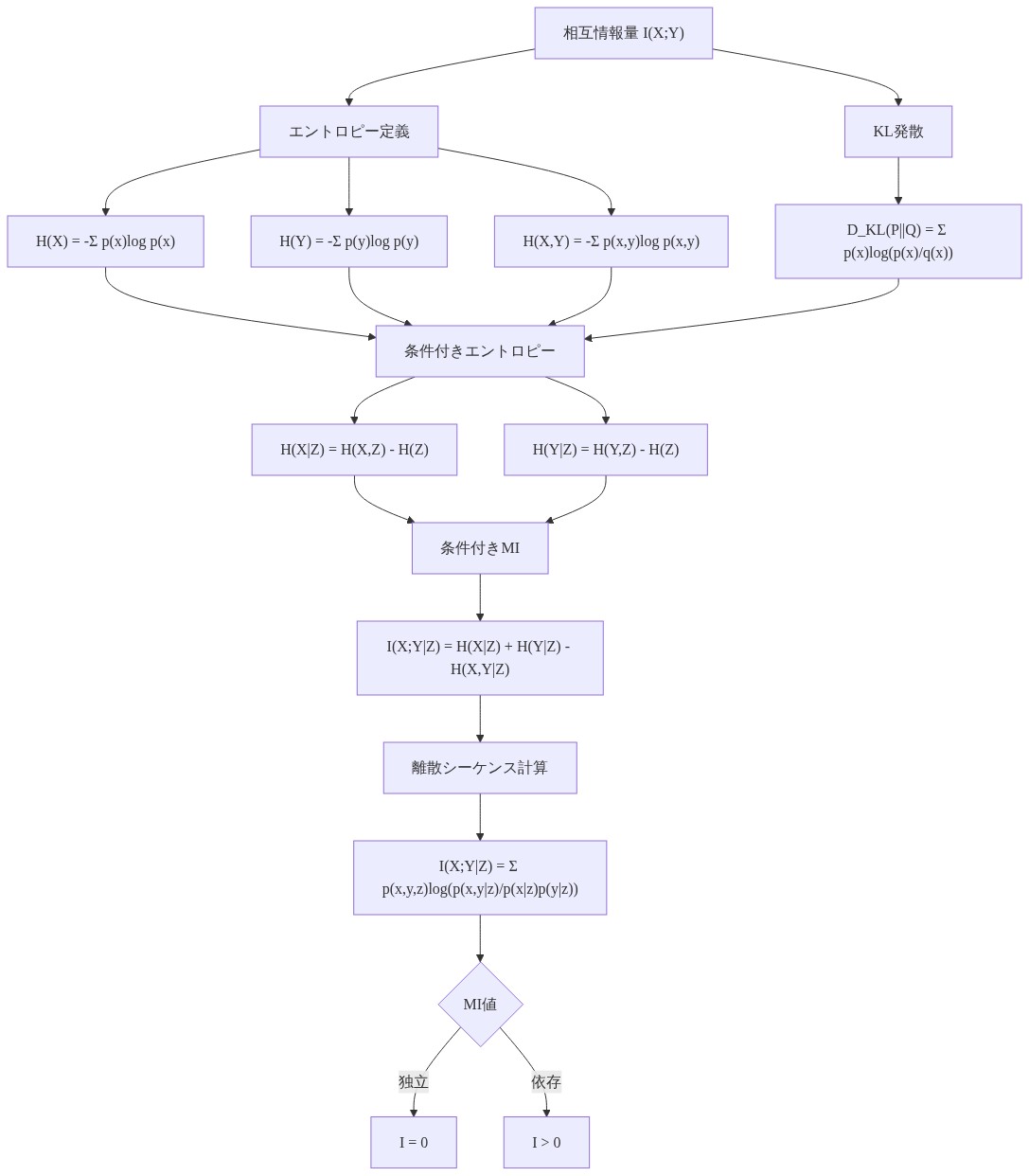
- 図4:条件付き相互情報量の理論的基礎(情報理論の標準的定義に基づく)*

- 図5:Neural MI Estimatorの3段階実装プロセス*
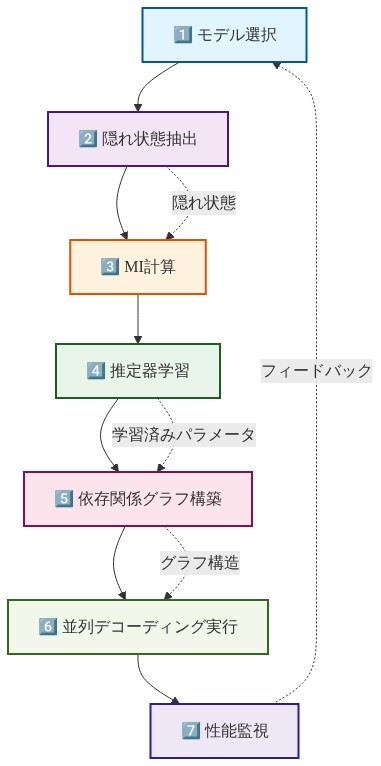
- 図12:エンドツーエンドのデプロイメントワークフロー*