
季節トレンド分解の再検討:時系列予測の強化に向けて
現代的予測における分解の必然性
従来の時系列予測では、ニューラルネットワークが生の系列からトレンド、季節性、周期的パターン、ノイズを同時に学習する必要があります。この同時最適化は二つの明確な課題をもたらします。第一に最適化の困難性です。モデルは異なる時間特性を持つ複数の成分にわたって競合する目的関数のバランスを取らなければなりません。第二に解釈可能性の低下です。学習された表現が複数の信号源を混在させるため、個別の成分を識別することが困難になります。
季節トレンド分解はこれらの課題に対して、予測前に明示的な成分分離を行うことで対処します。理論的基礎は古典的な加法分解モデルに基づいています。
$$Y_t = T_t + S_t + R_t$$
ここで$Y_t$は観測系列、$T_t$はトレンド成分、$S_t$は周期$p$の季節変動(すなわち$S_{t+p} = S_t$)、$R_t$は残差変動を表します。この分解は成分が加法的であり、かつ近似的に独立しているという仮定の下で有効です。この仮定は特定のデータセットに対して検証が必要です。
成分別モデリングの数学的正当性は異なるスペクトル特性に由来します。トレンド成分は低周波数に集中した電力を示します。季節成分は季節周期に対応する調和周波数でピークを示します。残差は白色ノイズに近似するか、不均一分散を示します。予測アーキテクチャをこれらの特性に適合させることで効率性の向上が得られます。再帰型ネットワークは逐次的依存性を通じてトレンドの勢いを捉えます。周期的畳み込みカーネルまたは位相認識の位置エンコーディングを備えた注意機構は季節構造を活用します。確率的層は残差の不確実性を定量化します。
-
具体例*:小売需要データは典型的に週次の季節性(顧客の買い物パターン)、基礎となる成長トレンド(事業拡大)、および不規則なショック(天候イベント、プロモーションキャンペーン)を示します。生の系列を処理する単一のLSTMは、火曜日が需要の上昇を示す(季節性)、基礎需要が四半期ごとに増加する(トレンド)、12月24日が異常値である(残差)ことを同時に学習する必要があります。分解はこれらを分離します。トレンド成分は多項式またはスプライン近似に適した単調増加を明らかにします。季節成分は周期的パターン学習に適した一貫した週次ピークを示します。残差は点予測ではなく不確実性定量化を必要とする異常値を捉えます。
-
仮定*:この分析は加法分解が適切であることを前提としています。乗法分解($Y_t = T_t \times S_t \times R_t$)はトレンドレベルに応じて季節振幅がスケーリングされる場合に適用されます。これは経済データで一般的です。対数変換は乗法形式を加法形式に変換しますが、再構成時にバイアスを導入します。ドメイン知識が分解の選択を導く必要があります。
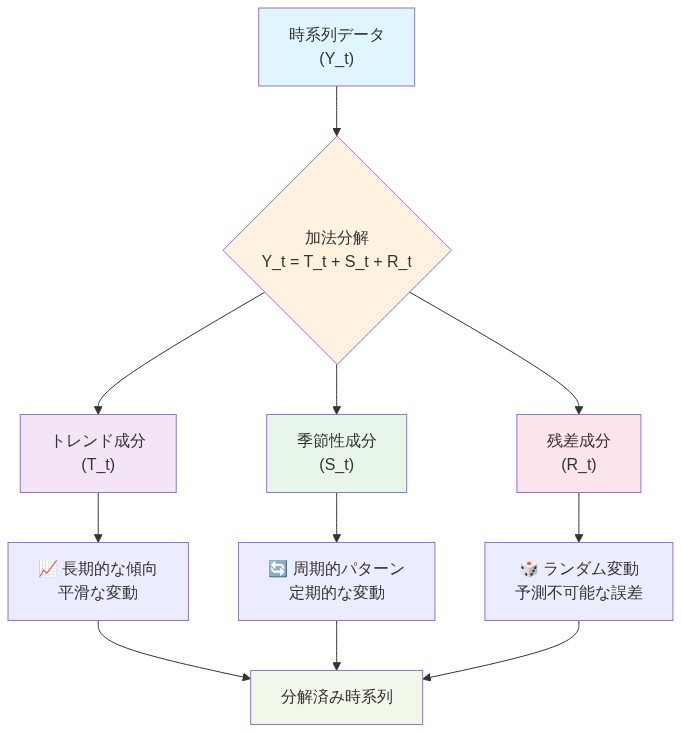
- 図2:加法分解モデル(Y_t = T_t + S_t + R_t)の構造と分解フロー*
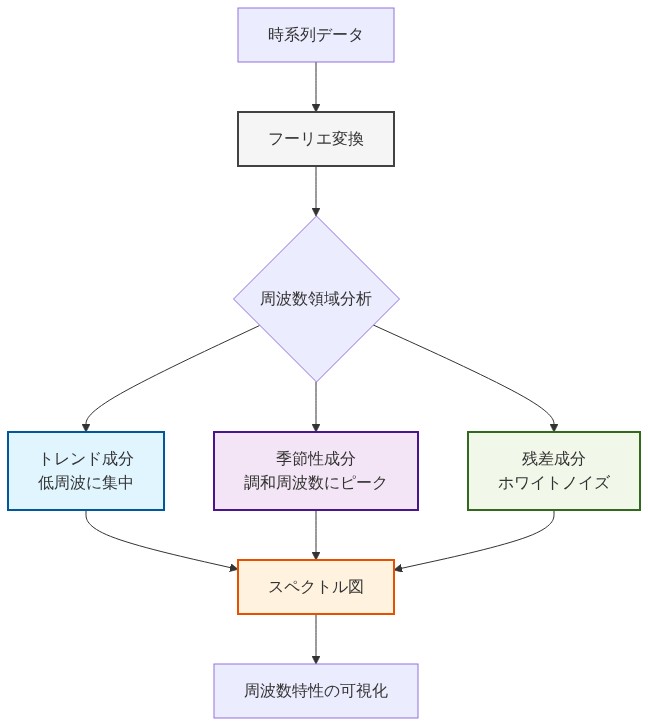
- 図4:各コンポーネントの周波数特性(スペクトル分析)*
成分別予測のためのアーキテクチャ強化
成分別アーキテクチャは分解された各要素の数学的構造を活用します。
-
*トレンド予測**は長距離依存性と滑らかな進化の捕捉を必要とします。拡張されたコンテキストウィンドウ(例えば金融データの場合252営業日)を備えたトランスフォーマーアーキテクチャは、方向転換を示す遠い過去の時点への注意を可能にします。拡張畳み込みを備えた時間畳み込みネットワークも同様にマルチスケール時間パターンを捉えます。アーキテクチャの選択はトレンド特性に依存します。滑らかでゆっくり進化するトレンドは多項式回帰または指数平滑化から利益を得ます。構造的ブレークを持つトレンドは予測と統合された変化点検出を必要とします。
-
*季節成分予測**は周期性への帰納的バイアスから利益を得ます。季節周期に一致するカーネルサイズを備えた時間畳み込みネットワーク(例えば週次パターンの場合7、年間周期の月次パターンの場合12)は明示的な周期性制約を提供します。位相情報を表現する位置エンコーディングを備えた注意機構(位置が絶対時間ではなく曜日または月を符号化する場合)は自然に季節構造を捉えます。相関したトレンドを持つが独立した季節パターンを持つ多変量系列(例えば共有容量制約を持つが製品固有の需要周期を持つ製造業)の場合、クロス注意機構は選択的な情報共有を可能にします。トレンド成分は製品全体で情報を共有します。季節成分は独立したままです。
-
*残差予測**は異なる課題を提示します。残差は典型的に不均一分散ノイズ(時間とともに変化する分散)とアウトライア感度を示します。点予測アーキテクチャ(標準LSTM、CNN)は不十分です。確率的アーキテクチャ(混合密度ネットワークが混合分布のパラメータを出力、正規化フローが柔軟な不確実性定量化を可能にする、または分位点回帰ネットワーク)は較正された不確実性推定を提供します。再構成は成分予測が合計されるとき、一貫した多変量予測を生成することを保証する必要があります。境界アーティファクト(分解ウィンドウ境界での不連続性)は重複ウィンドウまたは滑らかなテーパリングを通じた慎重な処理を必要とします。
-
仮定*:この分析は成分の独立性を前提としています。トレンド季節相互作用(例えば加法分解にもかかわらずトレンドレベルとともに増加する季節振幅)はより洗練されたモデルを必要とします。残差は白色ノイズ仮定に違反する自己相関を示す可能性があり、残差予測のためのARIMAまたは状態空間モデルを必要とします。
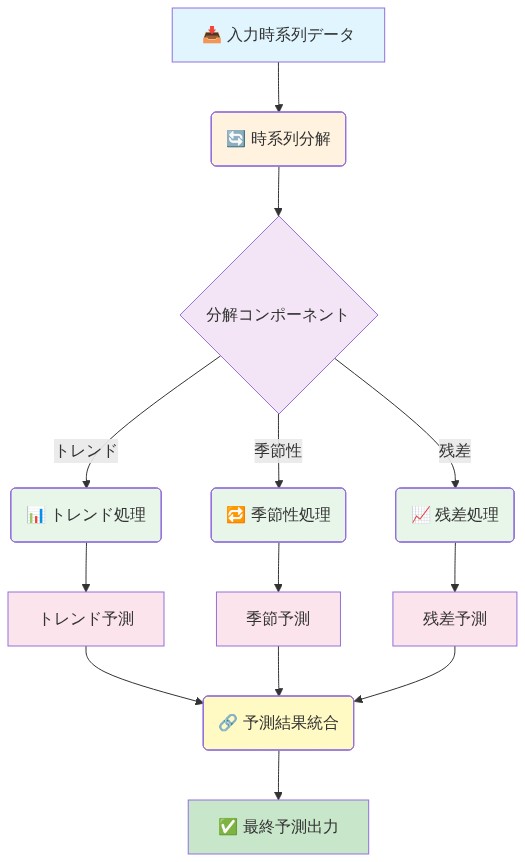
- 図6:分解ベース予測システムのエンドツーエンドフロー*
訓練戦略と損失関数設計
成分別予測は個別の成分精度と全体的な再構成忠実度のバランスを取る訓練手順を必要とします。標準的な平均二乗誤差(MSE)損失による素朴な独立訓練は、成分予測が元の系列に合計されなければならないという制約を無視します。
$$\hat{Y}_t = \hat{T}_t + \hat{S}_t + \hat{R}_t$$
複合損失関数による同時訓練はこの制約に対処します。
$$\mathcal{L}{total} = \alpha \mathcal{L}{trend} + \beta \mathcal{L}{season} + \gamma \mathcal{L}{residual} + \lambda \mathcal{L}_{reconstruction}$$
ここで$\mathcal{L}_{reconstruction} = \text{MSE}(\hat{Y}_t, Y_t)$は予測成分合計と真実値の間の不一致にペナルティを与えます。重み付けパラメータ$\alpha, \beta, \gamma, \lambda$はパフォーマンスに大きく影響します。再構成を過度に強調するとモデルはエラーを成分全体に人為的に分散させるよう強制します。成分損失を過度に強調すると加法制約に違反する非現実的な系列が生成されます。検証パフォーマンスに基づいて$\lambda$を調整する適応的重み付けスキームは堅牢なソリューションを提供します。例えば、再構成誤差が成分誤差を3倍上回る場合、$\lambda$を増加させてより厳密な結合を強制します。
-
*分解のタイミング**は重要な時間的整合性の考慮をもたらします。静的分解(季節分解アルゴリズム(例えばSTL、X-13ARIMA-SEATS)を履歴データセット全体に適用する)は先読みバイアスのリスクがあります。これらのアルゴリズムはしばしば平滑化操作を通じて現在の成分値を推定するために将来のデータを使用します。訓練ウィンドウ内のローリング分解は時間的整合性を維持します。各時間ステップで利用可能なデータのみを分解し、その後結果の成分に対して予測器を訓練します。これは計算オーバーヘッドと変化する分解パラメータからの潜在的な不安定性を導入しますが、情報漏洩を防ぎます。
-
*転移学習戦略**はデータが制限されたドメインで価値があります。大規模な分解時系列コーパス(例えばM4競技データ、公開金融データセット)上で成分別エンコーダを事前訓練し、その後ターゲットデータセットで微調整します。トレンドエンコーダは滑らかな軌跡表現を学習します。季節エンコーダは周期的パターンを学習します。残差エンコーダは不確実性定量化を学習します。このアプローチは正確な成分予測のためのデータ要件を削減します。
-
仮定*:この分析は分解パラメータが訓練期間とテスト期間全体で安定したままであることを前提としています。構造的ブレーク(例えばCOVID-19パンデミックが小売需要に与える影響)はこの仮定に違反し、適応的分解または異なるレジームのための別個のモデルを必要とします。
スケーリング仮定を超えた経験的検証
分解の有効性は普遍的なスケーリング則に従う、または全ドメインに均一に適用されると仮定することはできません。本番環境への展開に先立って厳密な実験的検証が必要です。
-
*成分レベルの評価指標**は集計指標(MAPE、RMSE)を超えています。
-
トレンド指標:変曲点検出精度、トレンド方向一致度(予測トレンド方向が実際と一致する期間の割合)
-
季節指標:振幅保存(予測季節範囲と実際の季節範囲の比)、位相一貫性(位相シフトを考慮した予測季節パターンと実際の相関)
-
残差指標:較正(予測区間が指定された信頼水準で真実値を含む)、異常値検出率
-
*アブレーション研究**はパフォーマンス向上が分解から生じるのか、それとも増加したモデル容量から生じるのかを分離します。以下を比較します。(1)成分別アーキテクチャを備えた分解ベースの予測、(2)同等の総モデル容量を備えた単一型予測、(3)成分全体で均一なアーキテクチャを備えた分解。(1)が(2)と(3)を上回る場合のみ、利益を分解構造に帰することができます。
-
*クロスドメイン検証**はコンテキスト依存性を明らかにします。弱い季節性を持つが強いトレンドを持つ金融系列(例えば株価指数)は、顕著な週次および年次周期を持つ小売需要よりも分解から利益を得ません。予測期間は有効性を調整します。短期予測(1~7日)は残差パターンと最近の勢いに大きく依存します。長期予測(90日以上)は正確なトレンドと季節外挿に依存します。複数の期間にわたる比較ベンチマーク(例えば1日先、7日先、30日先、90日先)は分解が追加の複雑性に対する真の利点を提供する場所を特徴付けます。
-
仮定*:この分析は評価指標があなたのビジネス目的に適切であることを前提としています。MAPEはゼロに近い値を持つ系列に対して誤解を招く可能性があります。方向精度は取引アプリケーションの大きさよりも重要である可能性があります。区間較正は在庫計画にとって重要である可能性があります。
本番システムにおける分解の運用化
分解を研究から本番環境に変換することは、慎重なシステム設計を必要とする実践的な制約をもたらします。
-
計算オーバーヘッド*:分解アルゴリズムは特にハイフリーケンシーデータ(ティックレベルの金融データ)または大規模多変量データセット(数百の相関系列)に対してレイテンシを追加します。新しいデータが到着するにつれて段階的に更新するオンライン分解方法(例えばオンラインSTL変種)はスケーラビリティのトレードオフを提供します。レイテンシは削減されますが、限定された履歴コンテキストのため分解品質が低下する可能性があります。
-
*モデルサービングアーキテクチャ**は多段階パイプラインに対応する必要があります。
- 分解:最近の履歴ウィンドウに分解アルゴリズムを適用
- 成分予測:特殊なモデルを使用して各成分の予測を生成
- 再構成:成分予測を合計して最終予測を生成
コンテナ化されたマイクロサービスはモジュール性を提供します。各段階は独立して実行されます。ただし、サービス間通信からのレイテンシが導入されます。単一型サービングはレイテンシを削減しますが、モジュール性を犠牲にします。ハイブリッドアプローチ(1つのサービスでの分解と再構成、別のサービスでの成分予測)はこれらのトレードオフのバランスを取ります。
-
*監視と可観測性**は複雑になります。予測誤差は以下から生じる可能性があります。(1)分解の失敗(不正確なトレンド季節分離)、(2)成分モデルの不正確性、または(3)再構成アーティファクト。成分レベルの指標と集計パフォーマンスは対象を絞ったデバッグを可能にします。ダッシュボードを実装して、トレンド予測精度、季節パターン一貫性、残差較正、および全体的な再構成誤差を追跡します。成分レベルの異常(例えば季節振幅偏差20%以上)が最終予測に伝播する前にアラートを発します。
-
*再訓練戦略**は新しい分解推定値の鮮度と一貫性の利点のバランスを取る必要があります。分解パラメータ(トレンド平滑性、季節周期)は安定性を維持するために低頻度(月次または四半期)で更新する必要があります。成分予測器は新しいデータが到着するにつれてより頻繁に(週次または日次)再訓練する必要があります。このハイブリッドアプローチ(頻繁な成分予測器更新と低頻度の分解パラメータ更新)は適応性と安定性の間の合理的なトレードオフを提供します。
-
解釈可能性とステークホルダー検証*:分解はビジネスステークホルダーレビューを可能にする解釈可能な出力を提供します。トレンド、季節、残差成分を示す可視化により、ドメイン専門家は分解が予期されたパターンを捉えているかどうかを検証できます。この透明性はモデルガバナンスと規制業界での規制遵守をサポートします。
-
仮定*:この分析は分解アルゴリズムが決定論的であるか、制御されたランダム性を持つことを前提としています。確率的分解方法は実行全体で異なる成分推定値を生成する可能性があり、再現性とモデルバージョン管理を複雑にします。

- 図12:本番環境での分解ベース予測システムアーキテクチャ*
重要な要点と次のアクション
分解ベースの予測は、生の系列に均一なモデルを適用するのではなく、成分特性にアーキテクチャの選択を適合させることにより、多変量時系列予測を改善します。メカニズムはトレンド、季節性、残差の明示的な分離を通じて機能し、各成分に対して特殊な予測戦略を可能にします。
- 成功の要件*:
-
成分別アーキテクチャ:トレンドの場合はトランスフォーマーまたは拡張CNN(長距離依存性捕捉)、季節性の場合は周期的CNNまたは位相認識注意(不確実性定量化を備えた混合密度ネットワーク、正規化フロー、または分位点回帰ネットワークの残差)
-
適応的重み付けを備えた複合損失関数:成分別エラーと再構成忠実度のバランス、検証パフォーマンスに基づいて調整する適応的重み付けを実装、先読みバイアスを防ぐために訓練ウィンドウ内でローリング分解を適用
-
あなたのドメインと予測期間全体での経験的検証:成分レベルの指標とアブレーション研究は真のパフォーマンスドライバーを分離、クロスドメイン検証はコンテキスト依存性を明らかにする、普遍的な適用可能性を仮定しない
-
本番対応インフラストラクチャ:成分レベルの監視を備えたモジュール型サービングアーキテクチャ、ハイブリッド再訓練スケジュール(頻繁な成分更新、低頻度の分解更新)、ステークホルダーレビューのための解釈可能な分解出力
- 次のアクション*:
-
複数の予測期間(1日先、7日先、30日先、90日先)にわたる代表的なデータに対してベースライン予測システムに対して分解ベースのアプローチをベンチマークします。
-
成分レベルの指標(トレンド変曲点精度、季節振幅保存、残差較正)を実装し、利益が分解構造から生じるのか、それとも増加したモデル容量から生じるのかを分離するアブレーション研究を実施します。
-
成分レベルの可観測性と分解品質、成分予測精度、再構成忠実度を追跡するモニタリングダッシュボードを備えたモジュール型サービングアーキテクチャを設計します。
-
強い季節性と明確なトレンド季節分離を示すドメインを優先して分解の利点を最大化し、進める前に加法分解仮定があなたのデータに対して成立することを検証します。