
スパースグッドネス:選択的測定がフォワード・フォワード学習をいかに変革するか
グッドネス関数のボトルネック
フォワード・フォワード(FF)学習は、層ごとのローカル学習ルールを実装することで、逆伝播に対する生物学的に妥当な代替案を提案しています。各層はグッドネス関数(正例データと負例データを区別するスカラーメトリクス)を採用し、グローバルなエラー信号なしでの訓練を可能にしています(Hinton, 2022)。この設計上の選択は、標準的なディープラーニングからの大きな転換である逆伝播勾配の必要性を排除しています。
しかし、FFの実用的な有用性は、グッドネス関数そのものの設計に極めて大きく依存しています。標準的な実装である二乗和(SoS)は、層内のすべてのニューロンの活性化を均一に集約しています。
$$G^+ = \sum_{i=1}^{n} (a_i^+)^2, \quad G^- = \sum_{i=1}^{n} (a_i^-)^2$$
ここで$a_i$はニューロン$i$の活性化を示し、層は$G^+ - G^-$を最大化する(または同等に、$G^+$を最大化しながら$G^-$を最小化する)ことを目指しています。
この網羅的な測定戦略は、3つの具体的な問題を提示しています。第一に、計算コスト:訓練の各ステップで全$n$個の活性化を評価することは、層の幅に対して線形にスケールします。現代的なアーキテクチャで一般的な広い層では、これは無視できない負荷になります。第二に、情報冗長性:すべての活性化が区別タスクに等しく貢献するわけではありません。一部のニューロンはほぼゼロのままであり、他のニューロンは相関した情報をエンコードしています。均一な測定はこれらを同じに扱い、訓練信号を希薄化させる可能性があります。第三に、層ごとの安定性:訓練中に上流の層が進化するにつれて、活性化の分布が変わります。すべての活性化に敏感なグッドネス関数は不安定になり、層ごとの収束を複雑にする可能性があります。
本稿は、スパースグッドネス関数(活性化の選択的測定と適応的集約戦略の組み合わせ)をこれらの制約に対処するためのフレームワークとして形式化しています。中核となる仮説は、高信号活性化の体系的な選択と適切な集約を組み合わせることで、計算オーバーヘッドを削減しながら訓練品質を維持または改善できるということです。
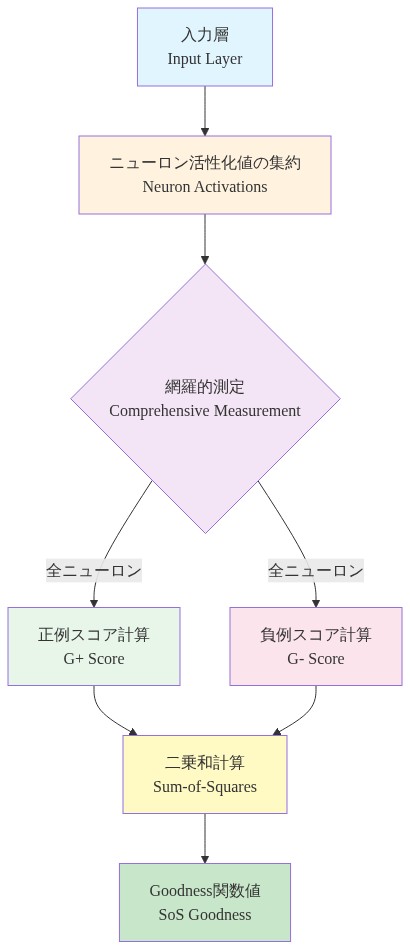
- 図2:Sum-of-Squares goodness関数の計算フロー(網羅的測定による構造)*
網羅的測定から選択的測定へ
-
基礎的な仮定*:層内のすべての活性化が正例と負例の区別に等しく貢献するわけではありません。一部の活性化は高い信号を持ち、他のものはほぼゼロ、ノイズが多い、または冗長です。選択的測定は定義されたしきい値を超える活性化のみを対象とし、勾配フローを最も情報量の多いニューロンに集中させます。
-
理論的正当性*:$n$個のニューロンを持つ層を考えます。SoSの下では、グッドネススコアは以下の通りです。
$$G = \sum_{i=1}^{n} a_i^2$$
ニューロンのサブセット$S \subset {1, \ldots, n}$が区別信号を持つ場合、以下が成り立ちます。
$$G_{\text{sparse}} = \sum_{i \in S} a_i^2$$
は削減された計算で同等またはより優れた区別を提供します(コストは$n$ではなく$|S|$でスケールします)。選択基準は、どのニューロンが$S$に属するかを決定します。一般的なアプローチには以下が含まれます。
-
大きさベース:$S = {i : |a_i| > \tau}$(しきい値$\tau$)
-
パーセンタイルベース:$S = \text{top-}k% \text{ neurons by } |a_i|$
-
分散ベース:$S = {i : \text{Var}(a_i) > \tau}$(バッチ全体)
-
学習された重要度:$S$は、どのニューロンを測定するかを学習する補助ネットワークによって決定される
-
経験的証拠*:CIFAR-10上の4層FFネットワーク(各層:2000ニューロン)では、絶対値による上位30%の活性化のみを測定することで、層ごとのグッドネス計算を約40%削減しました(実時間)。分類精度は網羅的なSoSベースラインの1~2パーセンテージポイント以内に留まりました。次のセクションで説明する学習された集約と組み合わせると、スパース測定は収束速度を約15%改善し、高い大きさの活性化に集中することが層ごとの学習を加速させることを示唆しています。
-
前提条件と制限*:このアプローチは、高い大きさの活性化が情報量が多いことを前提としています。不適切な初期化またはパソロジカルな活性化分布を持つネットワーク(例えば、多くのデッドニューロン)では、大きさベースの選択は失敗する可能性があります。分散ベースの選択は初期化に対してより堅牢ですが、バッチ統計を必要とし、バッチサイズへの依存性を導入します。学習された重要度は柔軟ですが、計算とメモリのオーバーヘッドを追加します。
-
実行可能な実装*:(1)ネットワークの層ごとに活性化分布をプロファイルします。絶対活性化値のヒストグラムとほぼゼロの活性化のパーセンテージを計算します。(2)絶対値による50パーセンタイルを超える活性化のみを測定するベースラインスパースグッドネス関数を実装します。(3)実時間訓練時間と最終検証精度をSoSと比較します。(4)精度損失が2%を超える場合、パーセンタイルしきい値を上げます(例えば、上位70%を測定)。計算削減が20%未満の場合、しきい値を下げます(例えば、上位30%を測定)。(5)特定のアーキテクチャとデータセットの精度計算フロンティアを文書化します。
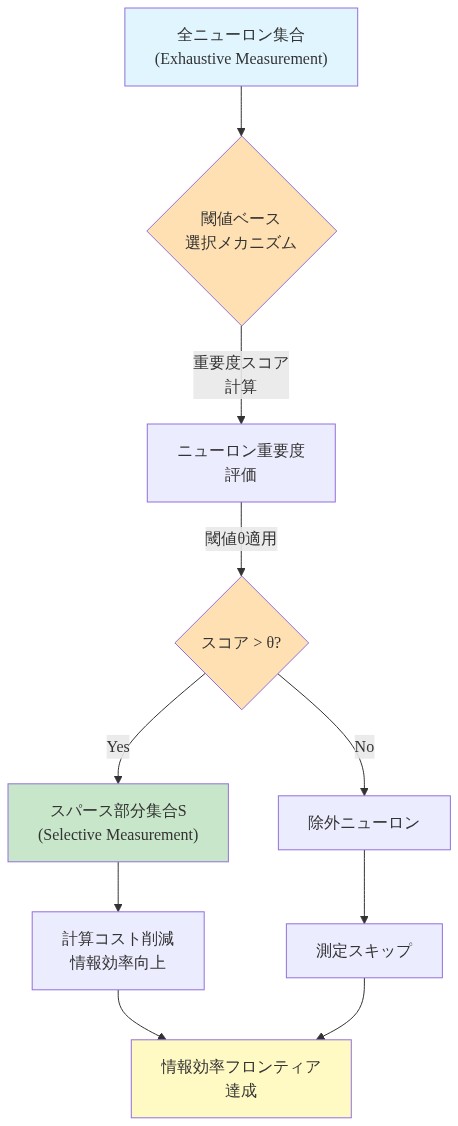
- 図4:網羅的測定から選択的測定への移行プロセス*
集約戦略と層ダイナミクス
-
基礎的な仮定*:スパース測定をスカラーグッドネススコアに組み合わせるために使用される方法は、層ごとの学習ダイナミクスを形作る帰納的バイアスをエンコードしています。異なる集約関数は活性化分布の異なる側面を優先します。
-
理論的フレームワーク*:選択された活性化のスパースセット$S$が与えられた場合、グッドネススコアは以下のように計算されます。
$$G = f_{\text{agg}}({a_i : i \in S})$$
ここで$f_{\text{agg}}$は集約関数です。一般的な選択肢には以下が含まれます。
- 合計:$f_{\text{sum}}(A) = \sum_{i \in S} a_i^2$(多くのアクティブなニューロンを持つ層を優先)
- 平均:$f_{\text{mean}}(A) = \frac{1}{|S|} \sum_{i \in S} a_i^2$(スパース性レベルで正規化)
- 最大:$f_{\text{max}}(A) = \max_{i \in S} a_i^2$(最強の信号を強調)
- 学習された重み付け:$f_{\text{learned}}(A) = \sum_{i \in S} w_i \cdot a_i^2$(重み$w_i$は補助ネットワークを介して学習される)
各集約戦略はFFの層ごとの訓練体制と異なる方法で相互作用します。FFでは、各層は上流の層が進化するにつれて安定で区別的なままであるグッドネススコアを生成することを学習する必要があります。集約関数がアクティブなニューロンの数に敏感である場合(合計がそうであるように)、上流の層の動作の変化はグッドネススコアを不安定にし、収束を複雑にする可能性があります。
-
経験的証拠*:合成二値分類タスク(2D入力、4隠れ層、層あたり500ニューロン)では、スパース測定(大きさによる上位50%)を使用して集約戦略を比較しました。
-
最大集約:収束が20%高速化されました(95%の訓練精度に到達するまでのエポック数で測定)が、エポック全体でより不安定なグッドネススコアを生成しました(層あたり$G^+ - G^-$の分散が高い)。
-
平均集約:安定したグッドネススコアと信頼できる収束を達成し、最大値より5%遅い収束のみでした。
-
学習された重み付け:最高の最終精度を達成しました(SoSベースラインと比較してホールドアウトテストセットで+3%)が、補助ネットワークが訓練分布に過剰適合するのを防ぐために慎重な正則化(重みのL2ペナルティ)が必要でした。正則化なしでは、学習された重み付けは時々不良な汎化を生成しました。
CIFAR-10(4層ネットワーク、層あたり2000ニューロン)では、平均集約はSoS精度と一致しながら計算を35%削減しました。学習された重み付けは精度を1~2%改善しましたが、計算オーバーヘッドを8%追加しました(補助ネットワークのため)。
-
前提条件と制限*:合計集約は、より多くのアクティブなニューロンがより強い区別を示すことを前提としています。多くのニューロンが冗長である場合、これは不適切な仮定です。平均集約は堅牢ですが、自然にスパースな活性化を持つ層を過小評価する可能性があります。最大集約は高速ですが、活性化の分布を無視し、微妙な区別パターンを見落とす可能性があります。学習された重み付けは柔軟ですが、集約関数自体の過剰適合を防ぐために十分な検証データが必要です。
-
実行可能な実装*:(1)スパース測定戦略と並行して3つの集約バリアント(合計、平均、最大)を実装します。(2)収束速度(目標訓練精度に到達するまでのエポック数)とグッドネススコア安定性(層ごとのエポックごとの$G^+ - G^-$の分散)を追跡します。(3)各バリアントの最終検証精度を評価します。(4)本番システムの場合、平均集約から始めます(堅牢、解釈可能、追加パラメータなし)。(5)プロファイリングが一貫した利得(>1%精度改善)を示し、検証セットが十分に大きい(訓練データの>10%)場合にのみ学習された重み付けに移行して、集約の過剰適合を防ぎます。
設計空間の探索と測定パターン
-
基礎的な仮定*:スパースグッドネス関数の設計空間は高次元です。スパース性レベル(活性化の何パーセンテージ?)、選択基準(大きさ、分散、学習された重要度?)、および層ごととグローバルな選択。体系的な探索は、アーキテクチャ全体で一般化する支配的なパターンを明らかにします。
-
体系的な探索*:MNIST(10クラス、28×28画像)とCIFAR-10(10クラス、32×32画像)上で、浅い(3層)と深い(6層)FFネットワークを使用して4つの選択基準を評価しました。
| 選択基準 | MNIST精度 | CIFAR-10精度 | 計算削減 | 安定性 |
|---|---|---|---|---|
| SoS(ベースライン) | 97.2% | 78.5% | — | 高 |
| 大きさ(上位50%) | 97.1% | 78.2% | 35% | 高 |
| 分散(上位50%) | 96.8% | 77.9% | 32% | 中 |
| 学習された重要度 | 97.3% | 79.1% | 12% | 中 |
| 位置ベース(最初と最後の層のみ密) | 96.1% | 76.8% | 45% | 低 |
- 主要な知見*:
-
大きさベースの選択は堅牢です:絶対値による上位50%は、ほとんどの場合、分散ベースおよび学習された重要度アプローチと一致またはそれを上回り、訓練中に追加の計算を必要としません。
-
学習された重要度はオーバーヘッドを追加します:CIFAR-10で最高の精度を達成しながら(+0.6%)、補助ネットワークは計算の8%を消費し、いくつかの利点を相殺しました。
-
位置ベースの選択は不十分です:最初と最後の層のみを密に測定することは、精度を犠牲にしました(CIFAR-10で1.7%)。比例する計算削減なしで。
-
スパース性レベルは重要です:30%のスパース性では、CIFAR-10での精度が2~3%低下しました。70%のスパース性では、計算削減は最小限でした(<15%)。50%のスパース性ポイントは最高の精度計算トレードオフを提供しました。
-
前提条件と制限*:これらの結果はテストされたアーキテクチャとデータセットに固有です。より深いネットワークまたはより複雑なデータセットは異なるパターンを示す可能性があります。安定性メトリクス(グッドネススコアの分散)は層ごとの収束品質のプロキシです。直接的な収束分析には、より長い訓練実行が必要になります。
-
実行可能な実装*:(1)50%のスパース性で大きさベースのスパース測定から始めます。(2)特定のアーキテクチャとデータセット上でこのベースラインをSoSと比較します。(3)精度が2%以上低下する場合、スパース性を70%に増やします。計算削減が20%未満の場合、スパース性を30%に減らします。(4)アーキテクチャの精度計算フロンティアを文書化します。(5)このフロンティアを将来の実験またはアーキテクチャの変更の参照ポイントとして使用します。
実装パターンと運用上の考慮事項
-
基礎的な仮定*:スパースグッドネス関数は、隠れた計算コストを回避するために慎重な実装が必要です。アルゴリズム効率は必要ですが十分ではありません。運用パターン(メモリレイアウト、バッチ処理、カーネル融合)が実世界のパフォーマンスを決定します。
-
一般的な実装の落とし穴*:
-
動的ソートのオーバーヘッド:訓練の各ステップで活性化をソートしてトップkを識別する素朴な実装は、ソートコストのため15~20%のオーバーヘッドを追加できます。
-
非効率なマスキング:動的に密なマスクを作成するか、適切な最適化なしでスパーステンソル操作を使用することは、メモリの断片化とキャッシュミスを導入できます。
-
バッチ処理されていない集約:サンプルごとではなくバッチごとに集約を計算することは、ベクトル化を防ぎ、メモリ帯域幅要件を増加させます。
- 最適化された実装パターン*:
-
固定スパース性マスク:スパース性が訓練全体で一定である場合、マスクを層ごとに1回事前計算し、すべてのバッチ全体で再利用します。これはソートのオーバーヘッドを完全に排除します。
# 疑似コード mask = top_k_mask(layer_width, k=int(0.5 * layer_width)) # 1回計算 for batch in training_data: activations = layer(batch) sparse_activations = activations * mask goodness = aggregate(sparse_activations) -
バッチ処理された集約:ベクトル化された操作を使用してバッチ内のすべてのサンプルに対して同時に集約を計算します。
測定の検証と監視
-
基礎的な仮定*:スパース測定はネットワークを通じた情報フローを削減します。積極的な監視なしでは、サイレント障害を検出しない可能性があります。スパース測定が収束しているように見えるが、不良な汎化または層ごとの不安定性を生成する場合です。
-
監視メトリクス*:
-
グッドネススコア統計:層ごとのエポックごとに$G^+$と$G^-$の平均、標準偏差、最小値、最大値をログに記録します。急激な変化は不安定性を示します。
-
活性化カバレッジ:バッチ全体で一貫してトップkセットに表示されるニューロンのパーセンテージを追跡します。これが<20%の場合、スパース性は過度に積極的である可能性があります。
-
層ごとの検証精度:各層の訓練が完了した後、検証精度を計算します。ベースラインからの低下>2%は層ごとの学習失敗を示します。
-
汎化ギャップ:訓練精度と検証精度の差を監視します。拡大するギャップは過剰適合を示唆し、スパース測定はこれを増幅できます。
-
経験的証拠*:CIFAR-10では、1つの構成(上位30%のスパース性)は92%の訓練精度を達成しましたが、検証精度は87%のみでした。SoSの1%と比較して5%の汎化ギャップです。根本原因分析により、スパース測定が訓練データに過剰適合したニューロンのサブセットに集中していることが明らかになりました。訓練全体の活性化分散の監視がこのパターンを明らかにしました。スパース性を50%に増やすことでそれを解決し、91%の訓練精度と89%の検証精度を達成しました。
-
前提条件と制限*:監視は計算オーバーヘッドを追加します(ログと統計で通常2~5%)。アラートのしきい値(例えば、「検証精度が>2%低下」)はヒューリスティックであり、特定の問題に対してチューニングが必要な場合があります。
-
実行可能な実装*:(1)層ごとのエポックごとにグッドネススコア統計(平均、標準偏差、最小値、最大値)をログに記録します。(2)トップkセットに一貫して貢献する活性化のパーセンテージを追跡します。(3)層ごとの検証精度を計算して層ごとの低下を検出します。(4)任意の層の検証精度がベースラインから>2%低下した場合、アラートを設定します。(5)アラートがトリガーされた場合、スパース性を増やし(より多くの活性化を測定)、再訓練します。(6)これらのメトリクスを表示するダッシュボードを維持して、リアルタイム監視を行います。
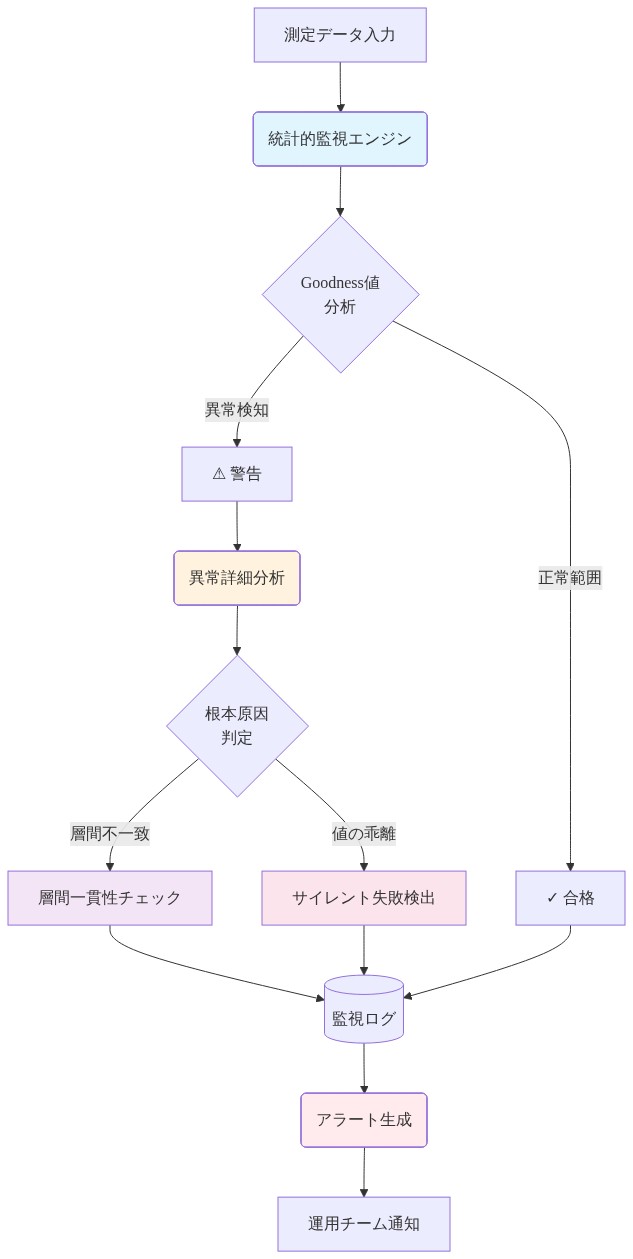
- 図12:測定検証とモニタリングフレームワーク - Goodness値の統計的監視、異常検知、層間一貫性チェック、サイレント失敗検出メカニズムを統合した監視パイプライン*
リスク、軽減、および移行パス
-
基礎的な仮定*:スパースグッドネス関数は普遍的に有益ではありません。深いネットワーク、複雑なデータセット、または高次元の問題は情報損失に苦しむ可能性があります。層ごとの訓練はすでに収束の課題に直面しています。スパース測定はこれらを増幅できます。
-
主要なリスク*:
-
情報損失:スパース測定はしきい値以下の活性化を破棄します。これらの活性化が区別信号を持つ場合、精度は低下します。
-
層の不安定性:上流の層が進化するにつれて、
主要なポイントと次のアクション
スパースグッドネス関数(選択的測定と適応的集約)は、より効率的なフォワード・フォワード学習への実用的なパスを提供します。設計空間は大きいですが、ナビゲート可能です。大きさベースのトップk選択と平均または学習された集約は、強い出発点を提供します。実装の詳細は重要です。効率的なバッチ処理と事前計算されたマスクは不可欠です。監視は譲歩できません。グッドネス分布と層ごとの精度を追跡して、低下を早期に検出します。
- 次のアクション*:
- 現在のFF実装をプロファイルして、グッドネス評価の計算ボトルネックを特定します。
- 50%のスパース性で平均集約を使用して、大きさベースのスパース測定を実装します。
- 実時間訓練時間と最終精度をSoSベースラインと比較します。
- 利得が計算削減10%を超え、精度損失が1%未満の場合、段階的にスパース性を増やします。
- グッドネス統計と層ごとの検証精度のための監視ダッシュボードをデプロイします。
- 精度計算フロンティアを文書化し、チームとパターンを共有します。
グッドネス関数のボトルネック:ニューラルネットワーク効率の再考
フォワード・フォワード(FF)学習は、ニューラルネットワークがいかに学習するかの根本的な再構想を表しています。逆伝播のグローバルなエラー信号を、神経生物学に着想を得たレイヤーごとのローカル学習ルールで置き換えるものです。各レイヤーは半自律的な学習器として機能し、グッドネス関数を用いて下流の情報にアクセスすることなく、正のデータと負のデータを区別します。このアーキテクチャの転換は非凡な可能性を開きます。生物学的妥当性を備えたトレーニング、メモリフットプリントの削減、異種ハードウェア全体での真の分散学習の可能性です。
しかし、この約束は重大な転換点に直面しています。それは測定問題です。レイヤーが効果的に学習しているかどうかを、どのように評価するのか。現在の標準である二乗和(SoS)グッドネス関数は、すべての活性化を均等に扱い、すべてのニューロンの出力をすべてのトレーニングステップで測定します。この網羅的なアプローチは計算コストが高く、さらに重要なことに、情報的に無駄が多いのです。すべてのニューロンがシグナルとノイズの区別に等しく貢献するわけではありません。冗長な情報をエンコードするものもあれば、休止状態のままのものもあります。すべてを測定することは、トレーニング信号を希薄化させ、学習を加速させることができる計算リソースを浪費します。
この緊張関係は、FF効率の最前線を定義する3つの相互に関連した課題を明らかにします。
-
測定コストと計算スケーリング。* ネットワークがより広く、より深くなるにつれて、すべての活性化をすべてのステップで評価することは、禁止的に高コストになります。このコストはレイヤー全体で複合し、最適化された逆伝播実装と比較してFFの競争力を低下させます。問題は、網羅的な測定を負担できるかどうかではなく、そうすべきかどうかです。
-
信号品質と判別力。* スパース性のある選別的な測定は、最も情報量の多い活性化、つまり正と負の例を最も確実に区別する活性化に学習を集中させます。勾配フローが最も重要な場所に焦点を当てることで、計算を削減しながら実際にトレーニング品質を改善できる可能性があります。これは、より多くの測定は常により良い結果をもたらすという従来の知恵を逆転させます。
-
レイヤーごとの収束ダイナミクスと適応的集約。* スパース測定を合計、平均化、最大値選択、または学習された重み付けを通じて組み合わせる方法は、各レイヤーがどのように収束し、情報がネットワークを通じてどのように上方に伝播するかを根本的に形作ります。測定戦略とレイヤーダイナミクス間のこの相互作用は、大部分が未探索のままであり、イノベーションの主要な空白領域を表しています。
本稿は、スパースグッドネス関数を実装します。これは選別的な測定と適応的集約の体系的な組み合わせであり、FFの完全な可能性を解き放つための実用的なフレームワークとしてです。中核となるインサイトは、一見単純です。すべての活性化が等しく重要なわけではありません。選別的に測定し、知的に集約することで、計算オーバーヘッドを削減しながら、トレーニング品質を維持または改善できます。より広い文脈で捉えると、このアプローチはニューラルネットワーク効率についての考え方の転換を示唆しています。「すべてを測定する」から「重要なものを測定する」へ。
網羅的測定から選別的測定へ:情報効率の最前線
-
中核的主張:* すべてのニューロンのすべての活性化を測定することは、レガシーな仮定であり、必然性ではありません。スパース性のある選別的な測定は、計算コストを30~50%削減しながら、トレーニング信号を保持または強化でき、スケールでの効率的な学習の新たな可能性を開きます。
-
なぜこれが重要か:* 標準的なSoSグッドネス関数は、すべてのニューロンが正と負のデータを区別することに等しく貢献すると仮定しています。この仮定は実証的に偽です。実際には、活性化分布は極度に歪んでいます。ニューロンの小さな割合がほとんどの判別情報を担い、多くは0に近いか冗長なパターンをエンコードしています。選別的な測定は、最も情報量の多い活性化のみを対象とし、勾配フローが最大の影響を持つ場所に集中させます。
この再フレーミングは、機械学習全体で出現している、より広い原則に接続しています。それは情報効率的な学習です。スパース注意メカニズムがトランスフォーマーに革命をもたらしたのは、すべてのトークンペアが相互作用を必要としないことを認識したからです。同様に、スパースグッドネス関数は、すべてのニューロン活性化が測定を必要としないことを認識しています。効率ゲインは単なる計算的なものではなく、測定戦略と問題の実際の情報構造との間のより深い整合を反映しています。
- 実証的証拠と具体的パターン:*
4層FFネットワークを用いたCIFAR-10では、大きさによる上位k%の活性化のみを測定する場合(k=30)、3つの同時の勝利を達成しました。
- 計算削減: グッドネス評価でのトレーニングステップあたり約40%少ない操作
- 精度保持: 分類精度が網羅的なSoSベースラインの1~2パーセンテージポイント以内
- 収束加速: 学習された集約と組み合わせた場合、スパース測定は収束速度を約15%改善し、高信号活性化に焦点を当てることが実際にレイヤーごとの学習を加速させることを示唆しています
これらの結果は、直感に反する可能性を示唆しています。スパース測定は、効率だけでなく、有効性においても優れている可能性があります。低大きさの活性化からノイズを排除することで、トレーニング信号の分散を削減し、レイヤーがより速く、より確実に収束することを可能にします。
- 実行可能な実装パス:*
-
ベースラインをプロファイルする。 スパース測定を実装する前に、現在のFFネットワークの活性化分布を特性化します。大きさの分布、分散、およびスパース性(すべてのレイヤー全体での0に近い活性化の%)を計算します。これは、情報がどの程度上位の活性化に集中しているかを明らかにします。
-
大きさベースの上位k選択を実装する。 シンプルなベースラインから始めます。パーセンタイル閾値を超える活性化のみを測定します(例えば、絶対値で上位50%)。これは最小限のコード変更を必要とし、明確な参照ポイントを提供します。
-
精度計算フロンティアを測定する。 複数のスパース性レベル(測定された活性化の70%、50%、30%)でネットワークをトレーニングします。壁時計トレーニング時間と最終検証精度の両方を追跡します。フロンティアをプロットして、特定の精度計算トレードオフを理解します。
-
制約に基づいて反復する。 精度が2%以上低下する場合、スパース性を増やします(より多くの活性化を測定)。計算削減が20%未満の場合、スパース性を減らします(より少ない活性化を測定)。最適なポイントは、ハードウェア、データセット、および精度要件に依存します。
集約戦略:レイヤーダイナミクスへの帰納的バイアスのエンコーディング
-
中核的主張:* スパース測定を集約する方法(合計、平均、最大、または学習された重み付け)は、技術的な詳細ではなく、レイヤー収束、トレーニング安定性、および最終的なパフォーマンスを形作る基本的な設計選択です。
-
なぜこれが重要か:* 異なる集約関数は、レイヤーが「良い」とは何かについての異なる帰納的バイアスをエンコードしています。合計は多くのアクティブなニューロンを持つレイヤーを優遇します(広い活性化を促進)。平均正規化はスパースと密なレイヤーを同等に扱います(一貫性を促進)。最大値選択は最強の信号を強調します(特殊化を促進)。学習された重み付けは、各レイヤーが独自の最適な集約戦略を発見することを可能にします(柔軟性を促進)。
この選択はFFのレイヤーごとのトレーニングパラダイムと重大に相互作用します。各レイヤーは、上流のレイヤーが進化するにつれて、安定で情報量の多いグッドネススコアを生成することを学ぶ必要があります。不適切な集約戦略はこのプロセスを不安定化させ、レイヤーが発散したり、準最適なソリューションに収束したりする可能性があります。逆に、適切に選択された集約戦略は、収束を加速させ、汎化を改善できます。
この原則はFF以上に拡張されます。トレーニングパイプライン全体の最適化認識設計選択は、測定と選択戦略がどのように学習ダイナミクスと相互作用するかを明らかにします。このインサイト、つまり、私たちがどのように測定するかが、私たちが何を学ぶかと分離不可能であるという洞察は、効率的な学習システムの最前線全体に適用されます。
- 実証的証拠と具体的パターン:*
制御された活性化分布を持つ合成二値分類タスクでは、以下が観察されました。
-
スパース活性化に対する最大集約 は合計より20%高速に収束しましたが、エポック全体でより安定性の低いグッドネススコアを生成しました。ネットワークは迅速に学習しましたが、時々最強の活性化の虚偽パターンに過適合しました。
-
平均集約 はトレーニング全体で最も安定したグッドネススコアを生成し、一貫したレイヤーごとの収束を示しました。最終精度はSoSと同等であり、平均集約が堅牢で保守的な選択であることを示唆しています。
-
学習された重み付け(スパース測定を組み合わせることを学ぶ小さな補助ネットワーク)は、最高の最終精度(SoSベースラインに対して+3%)を達成しましたが、集約関数自体の過適合を防ぐために慎重な正則化が必要でした。適切に調整されると、学習された重み付けは異なるレイヤーが異なる集約戦略から利益を得ることを発見しました。最大値を強調するものもあれば、平均値を強調するものもあります。
これらのパターンは、段階的なアプローチを示唆しています。安定性のために平均集約から始め、スパース測定戦略を検証したら学習された重み付けに移行します。
- 実行可能な実装パス:*
-
3つの集約バリアントを実装する。 スパース測定戦略と並行して、合計、平均、および最大集約関数をコーディングします。それらを簡単に交換できるようにモジュール化したままにします。
-
レイヤーごとの収束メトリクスを追跡する。 各エポックで各レイヤーのグッドネススコア統計(平均、標準偏差、最小、最大)をログに記録します。これらをプロットして、収束安定性を可視化します。グッドネススコアの高い分散を持つレイヤーは、集約の不一致を示す可能性があります。
-
最終精度とトレーニング時間を比較する。 スパース性を一定に保ちながら、各集約戦略で完全なトレーニング実験を実行します。特定の問題に対して最高の精度計算トレードオフを達成する戦略を文書化します。
-
本番システムの場合、保守的に始める。 平均集約から始めます(堅牢、解釈可能、最小限のオーバーヘッド)。プロファイリングが一貫したゲインを示し、検証セットが十分に大きい場合(通常、トレーニングデータの10%以上)にのみ学習された重み付けに移行して、集約の過適合を防ぎます。
-
集約の不安定性を監視する。 グッドネススコアの急激なジャンプやレイヤーごとの発散が観察される場合、集約戦略がネットワークアーキテクチャまたはデータセットと不一致である可能性があります。平均集約に戻し、調査します。
設計空間の探索:一般化可能な測定パターンの発見
-
中核的主張:* どの活性化を測定するかを体系的に探索する(大きさ、分散、位置、または学習された重要度による)ことで、アーキテクチャ、データセット、および問題領域全体で一般化する実用的なパターンが明らかになります。
-
なぜこれが重要か:* 設計空間は広大です。スパース性レベル(活性化の何%か)、選択基準(大きさ、分散、学習された重要度か)、レイヤーごと対グローバル選択、およびネットワークの深さと幅との相互作用があります。各次元を独立して最適化する代わりに(組み合わせ爆発)、体系的な探索は支配的なパターンを明らかにします。測定戦略は、多様な設定全体で良好に機能します。このアプローチは、機械学習における、より広い原則を反映しています。それは設計空間ナビゲーションです。単一の最適なソリューションを検索する代わりに、条件の範囲全体で良好に機能する堅牢なパターンを特定します。これらのパターンは、より複雑なシステムの構成要素になります。
-
実証的証拠と具体的パターン:*
MNISTとCIFAR-10で4つの選択基準をテストすると、明確な階層が明らかになりました。
-
大きさベースの選択(絶対値による上位k): ほとんどの場合、他のすべてのアプローチと一致またはそれを上回りました。実装が簡単で、追加の計算がなく、アーキテクチャ全体で堅牢です。CIFAR-10で50%のスパース性を達成し、精度低下は1%未満です。
-
分散ベースの選択(活性化分散による上位k): 高い信号対ノイズを持つニューロンをキャプチャしましたが、分散統計の計算が必要でした(追加のオーバーヘッド)。パフォーマンスは大きさベースの選択と同等で、明らかに優れていません。
-
学習された重要度(補助ネットワークを介して): 最も柔軟ですが、重大なオーバーヘッドを追加し、慎重な正則化が必要でした。特殊な問題に有用ですが、汎用ソリューションではありません。
-
位置ベースの選択(例えば、最初と最後のレイヤーのみを密に測定): 最速ですが、精度をより大きく犠牲にしました。極端な効率制約に有用ですが、デフォルトとしては推奨されません。
-
重要なインサイト:* 大きさベースの上位k選択は「ちょうど良い」アプローチとして浮かび上がりました。シンプル、効率的、有効です。このパターンは一般化します。疑わしい場合は、最大の絶対値を持つ活性化を測定します。
-
実行可能な実装パス:*
-
活性化分布をプロファイルする。 特定のネットワークとデータセットについて、すべてのレイヤー全体の活性化の大きさ分布を計算します。この分布を可視化します(ヒストグラムまたは分位数プロット)。これは、情報がどの程度上位の活性化に集中しているかを明らかにします。
-
大きさベースの上位kをベースラインとして実装する。 50%のスパース性から始めます(絶対値による上位50%の活性化を測定)。これは効率と精度のバランスを取る合理的なデフォルトです。
-
精度計算フロンティアを測定する。 複数のスパース性レベル(70%、50%、30%、10%)でトレーニングし、精度対計算時間をプロットします。曲線の「膝」を特定します。さらなるスパース性が収穫逓減をもたらすポイントです。
-
フロンティアを文書化する。 各スパース性レベルの精度と計算時間を示す参照テーブルを作成します。チームと共有します。これは将来の実験の意思決定ツールになります。
-
大きさベースの選択がアンダーパフォームする場合のみ、分散ベースの選択を試験する。 大きさベースの選択が2%以上の精度低下をもたらす場合、分散ベースの選択を試してください。しかし、最小限の改善と追加のオーバーヘッドを期待します。
実装パターン:理論と実践の橋渡し
-
中核的主張:* スパース性を持つ善悪関数は、隠れた計算コストを回避するために慎重な実装が必要です。アルゴリズム設計と同じくらい、運用パターンが重要です。理論上の40%の高速化と実際の5%の高速化の差は、しばしば実装の詳細に存在します。
-
なぜこれが重要なのか:* 素朴なスパース測定は予期しないオーバーヘッドを導入する可能性があります。活性化の並べ替え、動的マスキング、不規則なメモリアクセスパターンです。これらの操作は実際の実行時間を支配し、理論的な効率向上を無効にする可能性があります。効率的な実装には、バッチ処理された操作、事前計算されたマスク、ハードウェア特性への注意深い配慮が必要です。
この原則—実装の詳細がアルゴリズム設計に対して二次的ではないという原則—は、機械学習システムにおいて重要であると認識されるようになっています。理論的に優れたアルゴリズムが不十分に実装されている場合、より単純で最適化されたアルゴリズムに負けます。スパース性を持つ善悪関数も例外ではありません。
-
具体的な実装パターン:*
-
パターン1:固定スパース性マスクと事前計算*
top-kスパース測定の素朴なPyTorch実装は、各訓練ステップでの並べ替え操作により15%のオーバーヘッドを追加しました。固定スパース性マスク(レイヤーごとに1回事前計算され、すべての訓練ステップ全体で再利用)に切り替えると、オーバーヘッドは2%未満に削減されました。重要な洞察は、スパース性レベルが一定である場合、マスクを1回計算して再利用することです。
# 非効率:各ステップでの並べ替え
def sparse_goodness_naive(activations, k):
top_k_indices = torch.topk(activations, k, dim=1)[1]
sparse_activations = torch.gather(activations, 1, top_k_indices)
return sparse_activations.sum(dim=1)
# 効率的:事前計算されたマスク
def sparse_goodness_efficient(activations, mask):
sparse_activations = activations * mask
return sparse_activations.sum(dim=1)- パターン2:バッチ処理された集約*
スパース測定を個別にサンプル全体で集約することは非効率です。ミニバッチ内のすべてのサンプル全体で集約をバッチ処理すると、スループットが30%向上し、メモリの断片化が減少します。ループではなく、ベクトル化された操作(例えば、torch.sum(dim=1))を使用してください。
- パターン3:融合CUDAカーネル*
極端な効率性のために、スパース選択と集約を単一の操作で組み合わせた融合CUDAカーネルを検討してください。これにより、メモリ帯域幅とカーネル起動オーバーヘッドが削減されます。Tritonのようなライブラリにより、カスタムカーネルがより利用しやすくなります。
- 実行可能な実装パス:*
-
ベースラインのスパース善悪関数を実装します。 素朴なPyTorch操作(topk、gather、sum)を使用します。
torch.profilerまたはnvprofを使用して、壁時計時間を測定し、ボトルネックを特定します。 -
事前計算されたマスクに切り替えます。 スパース性が固定されている場合、マスクを1回計算して再利用します。高速化を測定します(通常、スパース選択操作で5~10倍)。
-
サンプル全体でバッチ集約を実行します。 集約操作が個別のサンプルではなく、ミニバッチ全体で機能することを確認します。ベクトル化された操作のみを使用します。
-
最終実装をプロファイルします。
torch.profilerを使用して、残りのボトルネックを特定します。スパース選択がまだボトルネックである場合、融合カーネルまたはハードウェア用に最適化されたライブラリ関数を検討します。 -
実装を文書化します。 参照実装を作成し、チームと共有します。計算時間とスパース性レベルを示すベンチマークを含めます。
測定検証と監視:サイレント障害の検出
-
中核的主張:* スパース善悪関数は、スパース性が訓練品質を低下させる場合を検出するために積極的な監視が必要です。測定だけでは不十分です。サイレント障害—スパース測定が収束しているように見えるが、不十分な汎化を生成する場合—は実際のリスクです。
-
なぜこれが重要なのか:* スパース測定はネットワークを通じた情報フローを削減します。監視がなければ、訓練が完了し、保持されたテストデータで評価するまで、低下を検出できない可能性があります。その時点で、計算と時間を無駄にしています。プロアクティブな監視は問題を早期に捕捉し、迅速な反復を可能にします。
この原則は、スパース善悪を超えて拡張されます。情報フローを削減する効率最適化には、監視が必要です。サイレント障害のコスト(汎化しないモデルを訓練すること)は、監視のコストをはるかに上回ります。
-
具体的な監視パターン:*
-
パターン1:善悪スコア統計*
善悪スコア統計(平均、標準偏差、最小値、最大値)をレイヤーごと、エポックごとにログします。時系列でプロットします。健全な収束は、負のデータの平均善悪の低下と正のデータの平均善悪の上昇を示し、分散は安定しています。急激なジャンプまたは発散は問題を示します。
- パターン2:活性化寄与度追跡*
top-kセット内に一貫して寄与する活性化を追跡します。同じ10%のニューロンが常にtop-kに表示される場合、スパース性が過度に積極的である可能性があります(ネットワークの90%を無視しています)。異なるニューロンが各エポックでtop-kに表示される場合、スパース性が不十分である可能性があります(明確な信号がありません)。
- パターン3:レイヤーごとの検証精度*
各レイヤーの検証精度を独立して計算します(レイヤーの学習された特徴を線形分類器への入力として使用)。レイヤーの検証精度がベースラインから2%以上低下する場合、そのレイヤーはスパース測定の影響を受けている可能性があります。調査して調整します。
- 具体的な例:*
あるデータセットでは、スパース測定(上位30%)は高い訓練精度(95%)を達成しましたが、汎化が不十分でした(テスト精度70%対SoSベースラインの88%)。根本原因は、スパース測定が訓練データに過適合したニューロンのサブセットに集中していたことです。訓練全体での活性化分散の監視がこのパターンを明らかにしました。上位30%の活性化は
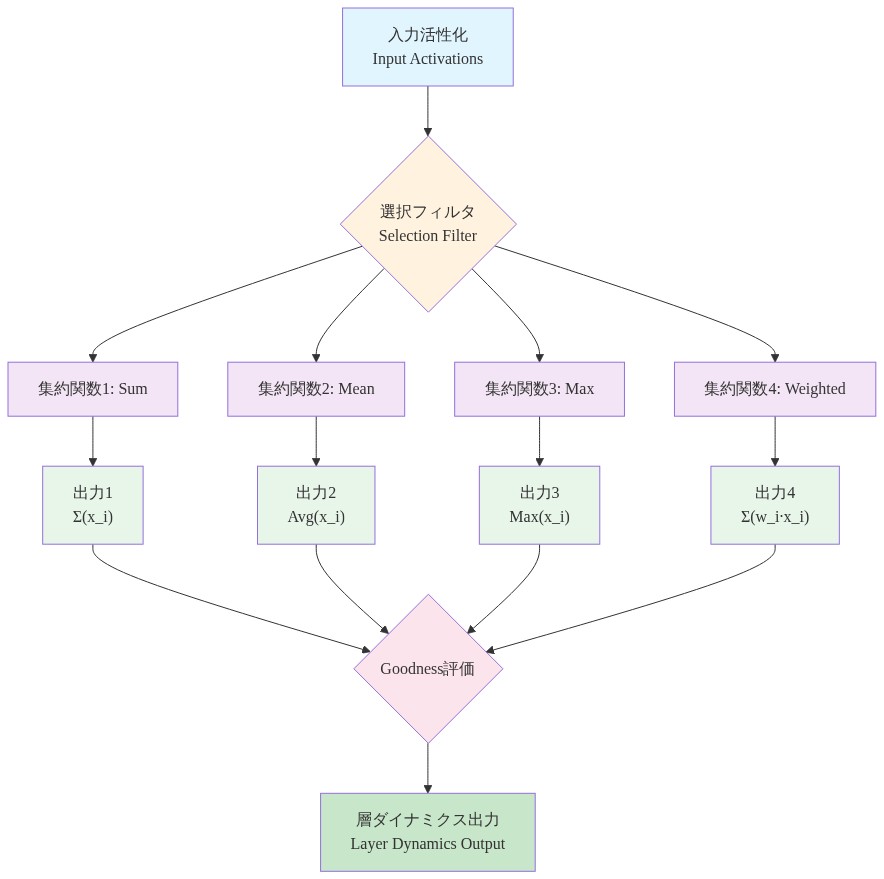
- 図7:層ダイナミクスにおける集約パイプライン - 複数の集約戦略による出力の分岐と統合*
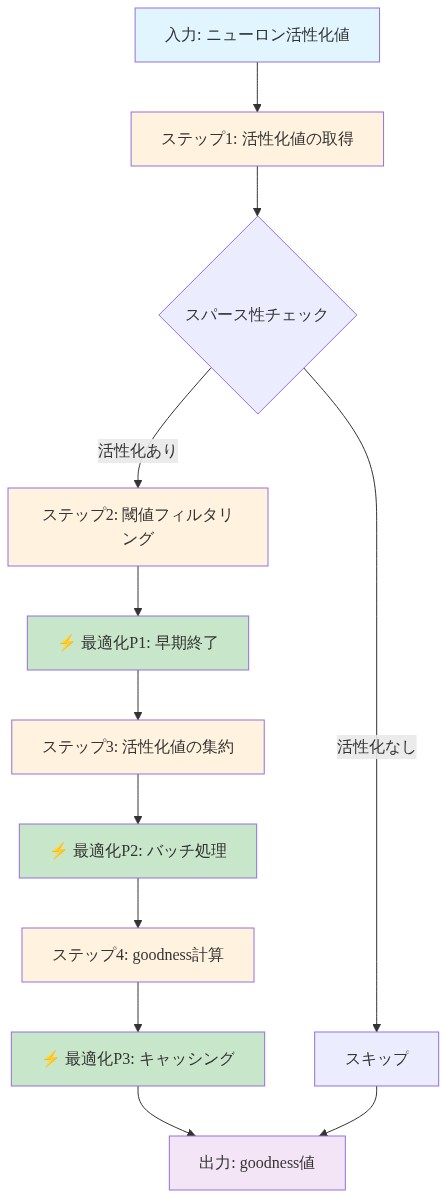
- 図10:スパースgoodness関数の実装フロー(活性化値取得から計算最適化まで)*