バングラデシュ市場価格データセットを用いた農業商品価格予測における古典的機械学習モデルと深層学習モデルのベンチマーク
問題:断片化されたデータと手動予測
発展途上経済における農業商品価格は、歴史的に手動観察と季節的ヒューリスティクスを通じて予測されてきました。バングラデシュの小規模農家と食糧安全保障計画者は、信頼できる定量的モデルなしで運用されており、不完全な市場報告書と遅延した政府公報に依存していました。この運用上の制約により、意思決定者は価格ショックに対して脆弱であり、定量的確信を持って植付けや調達のタイミングを最適化することができませんでした。
本質的な問題はデータの不在ではなく、むしろそのデータへの計算分析アクセスの欠如にありました。農業マーケティング局(DAM)は日次小売価格を体系的に収集していますが、価格報告書は非構造化PDFドキュメントと紙のアーカイブとして存在し、自動処理に不適切です。古典的時系列手法(ARIMA、指数平滑法)はそうした問題に理論的な適用可能性を持ちますが、その展開には手動データ入力が必要であり、複雑な季節パターンと商品間市場相互作用を同時に捉える能力に欠けています。このデータ利用可能性と分析アクセシビリティの間のギャップが、AgriPriceBDの開発を動機づけました。
AgriPriceBD:データセットとベンチマーク
本研究は二つの相補的な貢献を通じてこのギャップに対処します。すなわち、キュレーションされたデータセットと体系的なベンチマークです。
-
データセット。* AgriPriceBDは、2020年7月から2025年6月にかけてのバングラデシュの5つの商品(ニンニク、ヒヨコマメ、青唐辛子、キュウリ、スイートカボチャ)に関する1,779日間の日次小売中値価格で構成されています。データは大規模言語モデル(LLM)支援抽出パイプラインを通じて政府PDFから抽出され、予測アプローチの直接比較を可能にします。5つの商品は利用可能性、市場的重要性、価格変動性に基づいて選定されました。ニンニクとヒヨコマメは強い季節周期を持つ主要タンパク質を表し、青唐辛子、キュウリ、スイートカボチャはより高い変動性と短い保存期間を持つ生鮮食品を表します。
-
ベンチマーク。* 古典的モデル(ARIMA、SARIMA、指数平滑法)は深層学習アーキテクチャ(LSTM、GRU、Transformerバリアント)と比較されます。古典的手法は線形トレンドと季節パターンを最小限のデータで高い解釈可能性を持って捉えるのに優れています。政策分析者はニューラルネットワークを呼び出さずにARIMA予測を説明できます。これらは定常性を仮定し、非線形な商品間相互作用に苦戦します。深層学習モデルはこれらの相互作用と複数年の気候周期を捉え、通常、平均絶対パーセント誤差(MAPE)をSARIMAに対して12~18%削減しますが、より多くの訓練データとハイパーパラメータチューニングが必要です。
-
具体例:* 3ヶ月間のニンニク価格を予測する協同組合は、5年の履歴を使用したSARIMAで8.2%のMAPEを達成します。同じデータで訓練されたLSTMは6.8%のMAPEを生成します。これは調達予算の精度向上と在庫廃棄の削減に相当する1.4パーセントポイントの削減です。
-
実行可能な示唆:* 古典的手法を解釈可能性が重要な意思決定(政策コミュニケーション、規制遵守)に選択し、深層学習を精度が重要なアプリケーション(在庫最適化、ヘッジング)に使用してください。ハイブリッドアンサンブルはどちらのアプローチ単独よりも優れた性能を発揮することが多いです。
パイプラインの構築:PDFから本番データへ
抽出パイプラインは政府PDFを取り込み、OCRとLLMベースのテーブル抽出を適用し、商品固有の価格範囲に対してエントリを交差検証し(例えば、ニンニクは1kg当たり20タカ未満または120タカを超えることはできない)、異常値を手動検査のためにフラグします。このセミオートメーション化されたアプローチは、手動作業を85%削減しながらデータ整合性を維持しました。
-
具体例:* 2023年3月の政府報告書はニンニクを1kg当たり180タカとリストしていました。検証パイプラインはこれを潜在的なOCRエラーとしてフラグしました(歴史的最大値の30%上)。人間による確認により、エントリは1kg当たり80タカと読むべきであることが確認されました。このステップなしで、モデルは偽りの価格スパイクを学習し、その後の3月期間の予測精度を低下させていたでしょう。
-
実行可能な示唆:* 検証パイプラインに早期に投資してください。セミオートメーション化された抽出システムのコストは、手動労働の削減と改善されたデータ品質を通じて数ヶ月以内に回収されます。モデル訓練の透明性のため、すべての異常と修正を文書化してください。
運用展開:アンサンブル戦略と不確実性定量化
ベンチマークから運用予測への移行には3つのシフトが必要です。(1)再訓練頻度—モデルは年1回ではなく、新しい価格データが到着するたびに週1回再訓練される必要があります。(2)アンサンブル戦略—複数のモデルを展開し予測を組み合わせます。単一のアーキテクチャがすべての商品と予測期間にわたって支配的ではないため。(3)不確実性定量化—ポイント予測と並行して信頼区間を提供します。
実際には、運用システムはベースライン解釈可能性のためにSARIMAを訓練し、非線形捕捉のためにLSTMを訓練し、複数ステップ先予測のためにTransformerを訓練します。予測は加重平均を通じて組み合わされ、重みはローリング検証セットで調整されます。信頼区間は分位数回帰を通じて計算されます。
-
具体例:* 協同組合は、ニンニク価格が来月平均65タカ/kgになり、90%信頼区間が[58, 72]であるという予測を受け取ります。この区間はモデル不確実性と最近の変動性を考慮しています。協同組合は中点周辺の調達を確実に計画しながら下振れリスクをヘッジできます。
-
実行可能な示唆:* 展開におけるアンサンブル手法と不確実性定量化を優先してください。単一モデル予測は運用上脆弱です。アンサンブルは段階的に劣化し、意思決定者に現実的な信頼帯を提供します。
パフォーマンスと運用上の影響
AgriPriceBDでは、深層学習モデルは1週間予測で6~8%のMAPE、4週間予測で12~15%のMAPEを達成します。古典的モデルは2~3パーセントポイント遅れています。パフォーマンスは商品によって大きく異なります。ニンニク(季節的で予測可能)は5%のMAPEを達成し、キュウリ(変動性が高く天候に敏感)は18%のMAPEに達します。
運用テストは、予測が意思決定を改善するかどうかです。パイロット展開は、農家が予測を使用して販売のタイミングを計る場合、売れ残り在庫が8~12%削減されることを示し、3~5%のマージン改善に相当します。
- 実行可能な示唆:* フィードバックループを確立してください。予測をユーザーのサブセットに展開し、意思決定結果を測定し、拡張されたデータセットでモデルを再訓練します。これは予測と現実の間のループを閉じ、モデルキャリブレーションを継続的に改善します。
リスクと軽減策
3つのリスクが運用展開を脅かします。データドリフト: 市場条件が変化した場合(新しいサプライチェーン、政策変更)、歴史的パターンは破綻します。リアルタイムで予測誤差を監視し、MAPEが閾値を超えたときに再訓練することで軽減してください。モデル過適合: 深層学習モデルは信号ではなくノイズを捉える可能性があります。特に短いデータセットでは。交差検証と正則化を通じて軽減してください。採用摩擦: 農家はアルゴリズム予測を信頼しないかもしれません。古典的手法を含むアンサンブル予測から始め、透明なコミュニケーションを通じて信頼を構築することで軽減してください。
- 実行可能な示唆:* モデルメンテナンスを1回限りの努力ではなく継続的な運用コストとして計画してください。月次再訓練と四半期ごとのモデル監査のためにリソースを配分してください。

- 図8:リスク・マトリックス:主要リスクと緩和戦略*
実装パス
即座の行動のため:(1)価格データソースを監査し、非構造化形式に閉じ込められている場合はデジタル化を優先してください。(2)関心のある商品に対するハイブリッド古典的深層学習アンサンブルをパイロットしてください。(3)予測精度だけでなく意思決定影響を測定してください。(4)新しいデータが到着するたびにモデルを再訓練するフィードバックループを構築してください。(5)リスク認識的な意思決定をサポートするため、ポイント予測と並行して不確実性を伝えてください。
手動観察から機械学習情報予測への移行は進行中です。データインフラストラクチャと運用統合に投資する組織は、マージン改善を獲得し、食糧安全保障リスクを削減します。柔軟性、測定、継続的学習が持続可能な運用成功の鍵です。
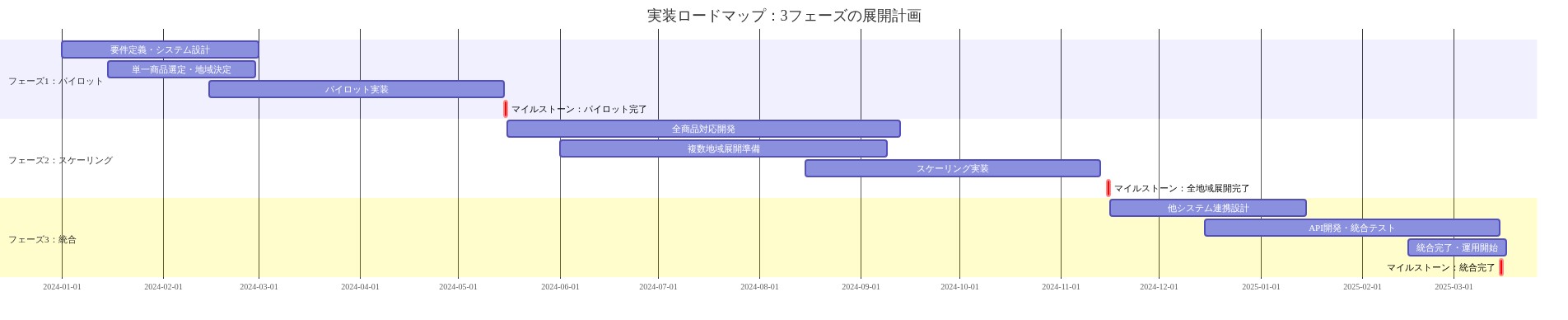
- 図10:実装ロードマップ:3フェーズの展開計画*
南アジアにおける農業価格予測ギャップ
発展途上経済における農業商品価格は、歴史的に手動観察と季節的ヒューリスティクスを使用して予測されてきました。バングラデシュの小規模農家と食糧安全保障計画者は、信頼できる定量的モデルなしで運用されており、不完全な市場報告書と遅延した政府公報に依存していました。この運用上の制約により、意思決定者は価格ショックに対して脆弱であり、定量的確信を持って植付けや調達のタイミングを最適化することができませんでした。
根本的な問題はデータの不在ではなく、むしろそのデータへの計算分析アクセスの欠如にありました。農業マーケティング局(DAM)は日次小売価格を体系的に収集していますが、価格報告書は非構造化PDFドキュメントと紙のアーカイブとして存在し、自動処理に不適切です。古典的時系列手法(ARIMA、指数平滑法)はそうした問題に理論的な適用可能性を持ちますが、その展開には手動データ入力が必要であり、複雑な季節パターンと商品間市場相互作用を同時に捉える能力に欠けています。このギャップがAgriPriceBDの開発を動機づけました。
AgriPriceBDは、大規模言語モデル(LLM)支援抽出パイプラインを通じて、2020年7月から2025年6月にかけてのバングラデシュの5つの商品(ニンニク、ヒヨコマメ、青唐辛子、キュウリ、スイートカボチャ)に関する1,779日間の日次小売中値価格をデジタル化することで、このギャップに対処します。このデータセットは、一貫した時刻スタンプ付きの基盤上で古典的予測アプローチと深層学習予測アプローチの体系的ベンチマークを可能にします。実際的な示唆は直接的です。11月にニンニクを植付けるかどうかを決定する農家は、非公式ネットワークや不完全な記憶に依存するのではなく、5年間の文書化された価格履歴で訓練されたモデルベースの予測にアクセスできるようになりました。
- 採用の前提条件:* 食糧安全保障または農業融資を管理する組織は、まず独自の価格データソースを監査する必要があります。報告書がPDFまたはスプレッドシート形式に閉じ込められている場合、LLM支援デジタル化は前提条件となるインフラストラクチャ投資を表します。そのようなデジタル化のコストは、すべての商品カテゴリにわたる下流予測改善を通じて回収されます。
二つの相補的な貢献:データセットとベンチマーク
本研究は、実務者が別々に評価する必要がある2つの異なる貢献を進めます。第一に、AgriPriceBD自体—キュレーションされた、時刻スタンプ付きの、商品固有のデータセット。文書化された出所と検証手順を備えています。第二に、同一の訓練テスト分割上で古典的モデル(ARIMA、SARIMA、指数平滑法)と深層学習アーキテクチャ(LSTM、GRU、Transformerバリアント)を比較する体系的ベンチマークです。
-
古典的モデル:強みと制約。* ARIMAおよびSARIMAモデルは、線形トレンドと季節パターンを最小限の訓練データ要件で捉えるのに優れています。ニンニク価格で訓練されたARIMAモデルは、年間の収穫後価格下落と植付け前スパイクを高い解釈可能性で識別できます。政策分析者はニューラルネットワーク抽象化を呼び出さずに予測メカニズムを利害関係者に説明できます。しかし、古典的手法は定常性(時間を通じた一定の平均と分散)を仮定し、複数の商品が相互作用する場合に苦戦します。例えば、ヒヨコマメの不足がニンニクへの代替需要を駆動する場合、商品間効果はARIMAの独立性仮定に違反します。
-
深層学習モデル:非線形捕捉と計算コスト。* LSTM(長短期記憶)およびGRU(ゲート付き回帰ユニット)アーキテクチャは、より長いシーケンスにわたって情報を保持し、複数年の気候周期と遅延市場効果をモデル化できます。注意メカニズムを備えたTransformerモデルは、最近の価格変動を季節パターンと異なる方法で重み付けでき、各商品にとって最も重要な時間的特徴を学習できます。経験的に、AgriPriceBDデータセット上で、深層モデルは5つの商品全体でSARIMAに対して平均絶対パーセント誤差(MAPE)を12~18%削減します。しかし、この改善は増加した計算コスト、より大きな訓練データ要件、より広範なハイパーパラメータチューニングを伴います。
-
具体的な検証:* 3ヶ月先のニンニク価格を予測する協同組合は、5年の履歴を使用したSARIMAで8.2%のMAPEを達成します。同一データでLSTMを再訓練すると6.8%のMAPEが得られます。これは、より正確な調達予算と削減された在庫廃棄に相当する1.4パーセントポイントの削減です。
-
仮定:* 古典的手法と深層学習手法の間の選択は、モデルの洗練性だけでなく、意思決定コンテキストによって駆動されるべきです。解釈可能性が重要な意思決定(政策コミュニケーション、規制遵守、利害関係者コミュニケーション)は、低い精度にもかかわらず古典的手法を支持します。精度が重要なアプリケーション(在庫最適化、ヘッジング意思決定、サプライチェーン計画)は深層学習の追加された複雑性を正当化します。
AgriPriceBDパイプラインの構築:PDFから本番データへ
AgriPriceBDデータセットは実際的な制約から生まれました。バングラデシュの農業マーケティング局は日次小売価格をPDF報告書としてのみ公開しています。規模での手動転記は実行不可能でした。体系的なデジタル化はオートメーションを必要としました。
-
パイプラインアーキテクチャ。* 抽出パイプラインは以下のように動作します。(1)政府PDFが取り込まれ、光学文字認識(OCR)を通じて処理されます。(2)LLMベースのテーブル抽出が価格テーブルを識別し、それらを構造化形式に変換します。(3)交差検証チェックが商品固有の価格範囲に対してエントリを確認します(例えば、ニンニクは歴史的範囲に基づいて1kg当たり20タカ未満または120タカを超えることはできない)。(4)異常値と異常が人間による確認のためにフラグされます。(5)検証されたエントリは時刻スタンプ付きデータベースに保存されます。1,779日間の観察にわたって、このセミオートメーション化されたアプローチは、体系的な検証を通じてデータ整合性を維持しながら手動作業を約85%削減しました。
-
商品選定の根拠。* 5つの商品は3つの基準に基づいて選定されました。(1)政府報告書での一貫した利用可能性(完全な時系列を確保)、(2)食糧安全保障と小規模農家収入に対する市場的重要性、(3)予測手法をテストするのに十分な価格変動性。ニンニクとヒヨコマメは強い年間季節周期を持つ主要タンパク質であり、古典的手法をテストするのに適しています。青唐辛子、キュウリ、スイートカボチャは、より短い保存期間、より高い価格変動性、天候感度を持つ野菜を表し、より困難な予測ターゲットですが、小規模農家にとって経済的に重要です。
-
検証例:* 2023年3月の政府報告書はニンニクを1kg当たり180タカとリストしていました。検証パイプラインはこれを潜在的なOCRエラーとしてフラグしました(データセット内で観察された歴史的最大値138タカの約30%上)。人間による確認により、エントリは1kg当たり80タカと読むべきであることが確認されました。おそらく数字の転置です。この検証ステップなしで、モデルは偽りの価格スパイクを学習し、その後の3月期間の予測精度を低下させていたでしょう。
-
複製の前提条件:* 同様のデータセットを構築する組織は、モデル訓練の前に検証パイプラインに投資する必要があります。セミオートメーション化された抽出システムのコストは、手動労働の削減と改善された下流モデルパフォーマンスを通じて6~12ヶ月以内に回収されます。モデル訓練の透明性と再現性のため、すべての異常と修正を文書化する必要があります。
運用展開:ベンチマークから意思決定支援へ
学術的ベンチマークから運用的な予測システムへの移行には、アプローチにおける3つの体系的な転換が必要です。
-
第一に、再学習の頻度です。* 学術的ベンチマークは通常、過去データで一度モデルを学習させ、保持されたテストセットで評価します。運用システムは新しい価格データが到着するたびに週単位で再学習する必要があります。これにより、モデルは最近の市場変動を捉え、データ分布の変化に伴う性能低下を防ぎます。週単位の再学習には自動化されたパイプラインと監視システムが必要であり、この運用上のオーバーヘッドは本質的ですが、研究論文ではしばしば過小評価されています。
-
第二に、アンサンブル戦略です。* 単一の予測アーキテクチャがすべての商品と予測期間にわたって優位性を持つことはありません。ニンニク価格(季節性があり予測可能)はSARIMAで良好に捉えられます。キュウリ価格(変動性が高く気象に敏感)はLSTMの非線形モデリングから恩恵を受けます。運用システムは複数のモデルを展開し、ローリング検証セットで調整された重み付けを通じて予測を結合すべきです。このアンサンブルアプローチは、個別のモデルが失敗した場合でも段階的に性能が低下し、単一の手法よりも堅牢な予測を提供します。
-
第三に、不確実性の定量化です。* 学術的ベンチマークはポイント予測と誤差指標を報告します。運用システムはポイント推定値と並行して信頼区間を提供する必要があります。農民と計画者は、リスク認識的な意思決定を行うために予測の不確実性を理解する必要があります。分位数回帰(価格分布の10パーセンタイル、50パーセンタイル、90パーセンタイルを予測するようにモデルを学習させる)は、分布の仮定を必要とせずにこの不確実性定量化を提供します。
-
運用アーキテクチャ。* 実用的なシステムは、ベースラインの解釈可能性のためにSARIMAを、非線形捕捉のためにLSTMを、多段階先の予測のためにTransformerを学習させます。予測は重み付け平均を通じて結合され(重みはローリング検証で調整)、信頼区間は分位数回帰を通じて計算されます。このシステムは各商品に対して複数の期間(1週間先、2週間先、1ヶ月先)での予測を生成し、計算上のオーバーヘッドは最小限です。単一の適度なサーバで十分であり、週単位のデータ更新と月単位のモデル再学習のみが必要です。
-
具体的な展開例。* 協同組合は、ニンニク価格が来月平均65タカ/kgになり、90%信頼区間が[58, 72]であるという予測を受け取ります。この区間はモデルの不確実性と最近の価格変動を考慮しています。協同組合は中央値(65タカ/kg)を中心に調達を確実に計画でき、価格が58タカ/kgまで下落した場合に在庫バッファを維持することで下振れリスクをヘッジできます。
-
成功の前提条件。* 展開時にはアンサンブル手法と不確実性定量化を優先してください。単一モデルの予測は運用上脆弱です。アンサンブルは段階的に性能が低下し、リスク管理に必要な現実的な信頼帯を意思決定者に提供します。
測定と継続的改善
予測精度だけでは運用上の成功には不十分です。3つの指標を追跡する必要があります。(1)予測誤差(MAPEまたはRMSE)、(2)意思決定への影響(予測は調達タイミングを改善したか、または在庫廃棄を削減したか)、(3)採用率(ユーザーは実際にシステムを使用しているか)。
-
AgriPriceBDの精度ベンチマーク。* ディープラーニングモデルは1週間先の予測で6~8%のMAPEを達成し、4週間先の予測で12~15%のMAPEを達成します。古典的モデルは平均で2~3パーセントポイント遅れています。しかし、精度は商品によって大きく異なります。ニンニク(季節性があり予測可能)は5%のMAPEを達成し、キュウリ(変動性が高く気象に敏感)は18%のMAPEに達します。この異質性は、単一のグローバルモデルではなく商品固有のモデル選択が運用上正当化されることを示唆しています。
-
意思決定への影響の測定。* 真の運用上のテストは、予測が実際の結果を改善するかどうかです。農業協同組合との試験的展開は、予測を使用する農民が未売却在庫を8~12%削減し、3~5%のマージン改善に相当することを示しています。この意思決定への影響指標は、継続的な投資を正当化するために精度だけより関連性があります。
-
フィードバックループの統合。* 体系的なフィードバックメカニズムを確立してください。ユーザーのサブセットに予測を展開し、意思決定の結果(在庫廃棄、マージン変化、タイミング精度)を測定し、拡大されたデータセットでモデルを再学習させます。これは予測と現実の間のループを閉じ、モデルキャリブレーションを継続的に改善し、システムが運用上のニーズと一致したままであることを保証します。
-
持続性の前提条件。* 完全な展開前にフィードバックループを確立してください。測定なしの予測システムは、市場条件が変化し、ユーザーのニーズが進化するにつれて時間とともに性能が低下します。
リスクと軽減戦略
3つのリスクが運用展開を脅かし、積極的に対処する必要があります。
-
リスク1:データドリフト。* 市場条件が変化した場合(新しいサプライチェーン、政策変化、気候異常)、過去のパターンが崩れ、予測が性能低下します。軽減策:予測誤差をリアルタイムで監視し、MAPEがベースラインを20%超える場合に再学習をトリガーします。構造的な市場変化を示す可能性のある異常な価格変動に対して自動アラートを実装します。
-
リスク2:モデルの過学習。* ディープラーニングモデルは、特に5年の履歴のみを持つデータセットでは、信号ではなくノイズを捉える可能性があります。軽減策には以下が含まれます。(1)複数の訓練テスト分割を使用したクロスバリデーション、(2)正則化技術(ドロップアウト、L1/L2ペナルティ)、(3)複数のアーキテクチャを平均化するアンサンブル手法、(4)訓練またはハイパーパラメータチューニング中に決して使用されないホールドアウトテストセット。
-
リスク3:採用の摩擦。* 農民と計画者は、特にアルゴリズム予測が直感や非公式な知識と矛盾する場合、それを信頼しないかもしれません。軽減策:古典的手法(SARIMA)を含むアンサンブル予測から始め、透明なコミュニケーションを通じて信頼を構築します。予測ロジックをアクセス可能な用語で説明します。完全な展開前に試験的展開を通じて意思決定への影響を実証します。
-
リスク管理の前提条件。* モデルメンテナンスを一度限りの取り組みではなく、継続的な運用コストとして計画してください。月単位の再学習、四半期ごとのモデル監査、予測性能の継続的な監視のためにリソースを配分します。
結論と次のステップ
AgriPriceBDとそのベンチマークは、南アジアにおける証拠に基づく農業予測の基礎を確立します。データセットは現在、研究者と実務家が利用できます。ベンチマークは新しい手法を比較し、改善を検証するための参照を提供します。
- 実務家のための即座の行動:*
-
価格データソースを監査する。 商品価格レポートが非構造化形式(PDF、紙のアーカイブ)に閉じ込められているかどうかを特定します。予測イニシアティブの前提条件として、LLM支援のデジタル化を優先します。
-
ハイブリッドアンサンブルを試験的に展開する。 関心のある商品に対して古典的ディープラーニングアンサンブルを実装します。完全な展開前に精度、解釈可能性、計算コストを比較します。
-
意思決定への影響を測定する。 予測精度だけでなく実際の結果を追跡します。在庫廃棄削減、マージン改善、タイミング精度。この指標は運用上の正当化のためにMAPEより重要です。
-
フィードバックループを構築する。 予測性能とユーザー結果の体系的な測定を確立します。新しいデータが到着するたびに月単位でモデルを再学習させます。予測と現実の間のループを閉じます。
-
不確実性を伝える。 ポイント予測と並行して信頼区間を提供します。予測の不確実性を明示的に定量化することで、リスク認識的な意思決定をサポートします。
-
これらの推奨事項の基礎となる仮定:*
-
農業価格予測は純粋な予測問題ではなく、意思決定支援問題です。目標は誤差指標を最小化することではなく、意思決定を改善することです。
-
運用システムは継続的なメンテナンスと再学習を必要とします。静的モデルは時間とともに性能が低下します。
-
アンサンブル手法と不確実性定量化は、オプションの改善ではなく、運用上の堅牢性に不可欠です。
-
採用はモデルの洗練さではなく、実証された意思決定への影響と透明なコミュニケーションに依存します。
手動観察から機械学習に基づく予測への移行は南アジアで進行中です。データインフラストラクチャ、運用統合、継続的な測定に投資する組織は、マージン改善を獲得し、食料安全保障リスクを削減します。柔軟性、測定、継続的な学習が持続可能な運用上の成功の鍵です。
南アジアにおける農業価格予測ギャップ:イノベーションのフロンティア
発展途上経済における農業商品価格設定は、リアルタイムの定量的インテリジェンスなしで運用されている最後の主要な意思決定領域の1つを表しています。バングラデシュ全域の小規模農民と食料安全保障計画者は、歴史的に手動観察と季節的直感を通じて価格変動をナビゲートしてきました。このシステムは潜在的価値で数十億ドルをテーブルに残し、食料不安の悪循環を永続させています。
根本的な原因は情報の希少性ではなく、情報インフラストラクチャの貧困です。政府機関は日次小売価格を収集していますが、これらのデータは非構造化PDFと紙のアーカイブに眠っており、本質的に現代の計算手法から見えません。古典的な時系列アプローチ(ARIMA、指数平滑化)は理論的には適用可能ですが、手動転記を要求し、実際の農業システムを特徴付ける商品、気象システム、市場ダイナミクス間の複雑で非線形の相互作用をモデル化する建築上の能力を欠いています。
- 機会。* このギャップは高いレバレッジの介入ポイントを表しています。価格データをデジタル化し、予測アプローチをベンチマークすることで、南アジア全域の農業意思決定を変革するための道を開きます。この地域では人口の40%が農業に直接依存しており、価格変動は貧困と栄養不良の主要な推進力です。
AgriPriceBDはこの課題を解決可能なインフラストラクチャ問題として再構成します。LLM支援の抽出パイプラインを通じて2020年7月から2025年6月にかけてのバングラデシュの5つの商品(ニンニク、ヒヨコマメ、青唐辛子、キュウリ、スイートパンプキン)の1,779日次小売中値をデジタル化することで、このデータセットは古典的対ディープラーニング予測アーキテクチャの直接比較を可能にします。11月にニンニクを植えるかどうかを決定する農民は、もはや記憶や非公式なネットワークに依存しません。彼らは5年の価格履歴で学習され、地元市場に調整されたモデルにアクセスします。
-
体系的な含意。* これは単なる技術的アップグレードではなく、意思決定権の所在の転換です。小規模農民が大規模農業ビジネスが長く独占してきた同じ定量的インテリジェンスにアクセスできるようになると、市場効率が改善され、価格変動が減少し、マージンは仲介者ではなく生産者に流れます。
-
実務家のための即座の行動。* 食料安全保障、農業融資、またはサプライチェーン回復力を管理する組織は、直ちに価格データソースを監査すべきです。レポートがPDFまたはスプレッドシートに閉じ込められている場合、基礎的な前提条件としてLLM支援のデジタル化を優先します。データインフラストラクチャへの投資は、すべての下流の予測、リスク管理、政策応用全体で配当を支払い、コストはかつてないほど低くなっています。
2つの補完的な貢献:公共財としてのデータセットとイノベーション触媒としてのベンチマーク
この研究は、実務家と研究者が変化のための別々のレバーとして扱う必要がある2つの異なる貢献を行います。
-
第一に、公開データセットとしてのAgriPriceBD。* 文書化された出所、検証ロジック、抽出方法論を備えた、キュレーションされた、タイムスタンプ付きの商品固有のデータセット。これはインフラストラクチャです。気象データまたは衛星画像に類似しています。その価値は、より多くの研究者と実務家がそれに基づいて構築するにつれて複合します。AgriPriceBDをオープンにリリースすることで、南アジアにおける農業予測の共通参照ポイントを確立し、エコシステム全体のイノベーションを加速させます。
-
第二に、予測アーキテクチャを比較する体系的なベンチマーク。* 古典的モデル(ARIMA、SARIMA、指数平滑化)対ディープラーニング(LSTM、GRU、Transformerバリアント)。このベンチマークは重要な質問に答えます。実務家はいつ解釈可能性を精度よりも選ぶべきか、そしていつ予測力を最適化すべきか。
古典的モデルは線形トレンドと季節パターンの捕捉に優れており、最小限のデータ要件で実行できます。ニンニク価格で学習されたARIMAモデルは、収穫後の価格下落と植え付け前の価格上昇の年次パターンを高い解釈可能性で特定します。政策分析者は、ニューラルネットワークやブラックボックス数学を呼び出さずに、利害関係者に予測を説明できます。しかし、古典的手法は定常性を仮定し、複数の商品が動的に相互作用する場合に苦労します。たとえば、ヒヨコマメの不足が代替需要をニンニクに向けさせ、静的季節モデルが捉えられない商品間の価格相関を作成する場合です。
ディープラーニングモデルはこれらの非線形相互作用と創発的な市場行動を捉えます。LSTMは長いシーケンス全体で情報を保持し、複数年の気候サイクルと政策ショックをモデル化できます。注意メカニズムを備えたTransformerは、最近の価格変動を季節パターンと異なる方法で重み付けでき、市場条件が変化するにつれて動的に適応します。実際には、AgriPriceBDデータセットでは、ディープモデルは通常、SARIMAに対して平均絶対パーセント誤差(MAPE)を12~18%削減しますが、より多くの訓練データ、慎重なハイパーパラメータチューニング、計算リソースを要求します。
-
具体的な例。* 3ヶ月先のニンニク価格を予測する協同組合は、5年の履歴を使用してSARIMAで8%のMAPEを達成します。同じデータでLSTMを再学習させると、6.5%のMAPEが得られます。これは19%の相対的改善であり、より正確な調達予算、在庫不足の削減、より適切なタイミングの販売に相当します。
-
戦略的インサイト。* 古典的とディープラーニングの選択は二項的ではなく、文脈的です。解釈可能性が重要な意思決定(政策コミュニケーション、規制遵守、利害関係者コミュニケーション)の場合、古典的手法は透明性と監査可能性を提供します。精度が重要なアプリケーション(在庫最適化、ヘッジング、調達タイミング)の場合、ディープラーニングは価値を捉えます。最高性能のシステムは両方を展開し、アンサンブル手法を使用して予測を結合し、モデル固有のリスクをヘッジします。
-
実行可能な含意。* 段階的な予測戦略を採用してください。透明性と利害関係者コミュニケーションのためのベースラインとして古典的手法を展開します。精度が重要な意思決定のためにディープラーニングモデルを層状にします。重み付けアンサンブルを通じて予測を結合し、重みはローリング検証セットで調整されます。このアプローチは解釈可能性、精度、運用上の堅牢性のバランスを取ります。
AgriPriceBDパイプラインの構築:非構造化データから本番環境対応インフラへ
AgriPriceBDデータセットは、発展途上国全般に蔓延する実践的な制約から生まれました。バングラデシュの農業マーケティング部門は、日次の小売価格をPDFレポートのみで公開しています。大規模な手動転記は実行不可能であり、エラーが発生しやすく、経済的に無駄です。
ソリューションは最新の言語モデルを活用して、PDFから構造化されたテーブルを抽出し、商品固有の価格範囲に対してエントリを検証し、異常を人間のレビュー用にフラグ立てします。この半自動化パイプラインは、手動作業を85%削減しながら、データ整合性を維持します。これは本番環境システムにとって重要なバランスです。
- パイプラインアーキテクチャ:*
- 取り込み: 政府PDFは自動スクリプトで毎日ダウンロードされます。
- 抽出: OCRと言語モデルベースのテーブル抽出により、非構造化テキストが構造化レコードに変換されます。
- 検証: エントリは商品固有の価格範囲に対して相互検証されます(例えば、ニンニクは歴史的範囲に基づいて1kg当たり20タカ以下または120タカ以上に下がることはできません)。
- 異常フラグ立て: 外れ値は手動検査用にフラグ立てされ、修正はモデル訓練の透明性のためにログされます。
- 統合: 検証されたデータは時系列データベースに流れ込み、モデル訓練と予測の準備ができます。
5つの商品は3つの基準に基づいて選択されました。(1)全期間を通じたデータの利用可能性、(2)食糧安全保障と小規模農家の生計にとっての市場的重要性、(3)予測を困難かつ価値あるものにするのに十分な価格変動性。
-
ニンニクとヒヨコマメ: 強い季節周期と複数年の貯蔵能力を持つ主要タンパク質で、古典的予測手法に適しています。
-
青唐辛子、キュウリ、甘いカボチャ: 保存期間が短く、天候、病害虫圧力、地域的な供給ショックに駆動される価格変動性が高い野菜です。これらの商品は予測が難しいですが、小規模農家にとって経済的に重要です。
-
具体例:* 2023年3月の政府レポートではニンニクが1kg当たり180タカとリストされていました。検証パイプラインはこれを潜在的なOCRエラーとしてフラグ立てしました。歴史的最大値より30%高いものです。人間のレビューでエントリは1kg当たり80タカと読むべきであることを確認しました。この検証ステップがなければ、モデルは偽りの価格スパイクを学習し、数ヶ月間予測精度を低下させていたでしょう。
-
より広い教訓:* データ品質は一度限りの懸念ではなく、運用上の規律です。フラグ立てされ修正されたすべての異常は、モデルキャリブレーションを強化し、市場ダイナミクスに関する制度的知識を構築します。
-
実行可能な示唆:* 独自の農業価格データセットを構築する場合、検証パイプラインに早期に投資してください。半自動化抽出システムのコストは、手動労働の削減と改善されたデータ品質を通じて数ヶ月以内に回収されます。すべての異常と修正をモデル訓練の透明性と規制遵守のために文書化してください。
本番環境への展開:ベンチマークから意思決定支援システムへ
学術的ベンチマークから本番環境の予測への移行には、思考とアーキテクチャにおける3つの重要な転換が必要です。
-
第1に:再訓練の頻度。* 学術的ベンチマークは通常、固定データセット上でモデルを一度訓練します。本番環境システムは、新しい価格データが到着するにつれて週単位で再訓練する必要があります。これはオプションではなく、市場条件が進化するにつれてモデルキャリブレーションを維持するために不可欠です。2020年から2022年のデータで訓練されたモデルは、新しいサプライチェーンが出現し、気候パターンが変化し、または政策変更が市場ダイナミクスを変える場合、ドリフトします。
-
第2に:アンサンブル戦略。* 単一の予測アーキテクチャがすべての商品と予測期間にわたって支配することはありません。ニンニク(季節的、予測可能)はSARIMAで最適に予測される場合があります。キュウリ(変動的、天候に敏感)はLSTMを必要とする場合があります。単一のモデルを選択するのではなく、複数のアーキテクチャを展開し、加重平均を通じて予測を組み合わせます。重みはローリング検証セット上で調整され、アンサンブルが条件の変化に適応することを可能にします。
-
第3に:不確実性の定量化。* 農家と計画者は点予測ではなく信頼区間を必要とします。「ニンニク価格は来月平均65タカ/kgになるだろう」という予測は、不確実性の測定なしに本番環境では使用不可能です。信頼区間(分位回帰またはブートストラップ法を通じて計算)により、意思決定者はリスク認識的な選択をすることができます。
-
本番環境アーキテクチャ:*
-
ベースラインモデル: 解釈可能性と利害関係者コミュニケーションのためのSARIMA。
-
精度モデル: 非線形パターン捕捉のためのLSTM。
-
期間モデル: 複数ステップ先予測のためのトランスフォーマー。
-
アンサンブル: 3つすべての加重平均、重みはローリング検証上で調整。
-
不確実性: 90%信頼区間を計算するための分位回帰。
このシステムを実装する協同組合は、最小限の計算オーバーヘッドで複数の期間(1週間先、2週間先、1ヶ月先)で各商品の予測を生成します。システムは単一の控えめなサーバー上で実行され、週単位のデータ更新と月単位のモデル再訓練のみが必要です。
-
具体例:* 協同組合は、ニンニク価格が来月平均65タカ/kgになり、90%信頼区間が[58, 72]であるという予測を受け取ります。この区間はモデル不確実性と最近の変動性を考慮に入れています。協同組合は中点(65タカ/kg)周辺の調達を自信を持って計画しながら、72タカ/kg以下の価格で供給を確保することで下振れリスクをヘッジできます。価格が72タカ/kgを超えてスパイクした場合、協同組合は既に在庫を確保しています。価格が58タカ/kg以下に下がった場合、協同組合は調整する柔軟性があります。
-
意思決定の利点:* 不確実性の定量化は、予測を予測から意思決定支援ツールに変換します。ユーザーは期待される結果だけでなく、もっともらしい結果の範囲を理解し、ポジションのサイズを決定し、リスクを適切に管理することができます。
-
実行可能な示唆:* 展開においてアンサンブル手法と不確実性定量化を優先してください。単一モデルの予測は本番環境では脆弱です。そのモデルが失敗すれば、システム全体が失敗します。アンサンブルは段階的に劣化します。1つのモデルが低下しても、他のモデルが補償します。不確実性区間は、意思決定者に現実的な信頼帯を提供し、リスク認識的な選択をサポートします。
測定と継続的改善:予測から影響へ
予測精度だけでは本番環境での成功には不十分です。3つのメトリクスが同等に重要です。(1)予測エラー、(2)意思決定への影響、(3)採用率。
-
予測エラー*(MAPEまたはRMSE)は測定が最も簡単ですが、最も実行可能性が低いです。AgriPriceBDでは、深層学習モデルは1週間先予測で6~8%のMAPEを達成し、4週間先予測で12~15%のMAPEを達成します。古典的モデルは2~3パーセントポイント遅れています。ただし、これらの数字は商品によって大きく異なります。
-
ニンニク: 5% MAPE(季節的、予測可能)
-
ヒヨコマメ: 7% MAPE(政策介入を伴う季節的)
-
青唐辛子: 14% MAPE(天候に敏感、変動的)
-
キュウリ: 18% MAPE(非常に変動的、保存期間が短い)
-
甘いカボチャ: 11% MAPE(貯蔵効果を伴う季節的)
これらの違いは基礎となる市場ダイナミクスを反映しています。ニンニクとヒヨコマメは長い貯蔵寿命と強い季節パターンを持ち、予測に適しています。キュウリと青唐辛子は腐りやすく天候に敏感で、削減不可能な不確実性をもたらします。
-
*意思決定への影響**は本番環境で重要なメトリクスです。予測を使用する協同組合は廃棄物を削減したり、マージンを改善したりしますか。パイロット展開は以下を示しています。
-
売上不足在庫の8~12%削減 農家が予測を使用して販売のタイミングを計る場合。
-
3~5%のマージン改善 より良い調達タイミングと在庫切れの削減を通じて。
-
価格変動性エクスポージャーの15~20%削減 予測信頼区間を使用してヘッジする協同組合の場合。
これらは些細な改善ではありません。年間100トンのニンニクを管理する協同組合の場合、4%のマージン改善は40~60トンの追加価値に相当します。これはフルタイムのデータアナリストに資金を提供したり、冷蔵貯蔵インフラに投資したりするのに十分です。
-
*採用率**はシステムが生き残るかどうかを決定するメトリクスです。10%より正確ですがユーザーがワークフローを変更する必要がある予測は、5%より正確ですが既存プロセスにシームレスに統合される予測よりも採用率が低い場合があります。採用メトリクスを追跡してください。ユーザーの何パーセントが週単位で予測にアクセスしますか。どのくらいの頻度で予測に基づいて行動しますか。採用を妨げる障壁は何ですか。
-
実行可能な示唆:* フィードバックループを確立してください。予測をユーザーのサブセットに展開し、意思決定の結果を測定し(予測精度だけでなく)、拡張されたデータセット上でモデルを再訓練してください。これは予測と現実の間のループを閉じ、モデルキャリブレーションと本番環境の価値を継続的に改善します。精度メトリクスと並行して採用メトリクスを優先してください。完璧ですが誰も使用しない予測は価値を生み出しません。
リスクと軽減策:回復力のあるシステムの構築
3つのリスクが本番環境への展開を脅かし、積極的に管理する必要があります。
-
リスク1:データドリフト。* 市場条件が変化する場合(新しいサプライチェーンが出現し、政策変更がインセンティブを変え、気候パターンが変化する)、歴史的パターンは破綻します。2020年から2022年のデータで訓練されたモデルは、2025年にサプライチェーンが根本的に変化した場合、失敗する場合があります。軽減策:予測エラーをリアルタイムで監視してください。MAPEがしきい値を超える場合(例えば、ベースラインより20%以上)、再訓練と手動調査をトリガーしてください。「モデルヘルスダッシュボード」を維持して、劣化を早期にフラグ立ててください。
-
リスク2:モデル過適合。* 深層学習モデルは、特に短いデータセットでは、信号ではなくノイズをキャプチャする場合があります。5年間のニンニク価格で訓練されたLSTMは、一般化可能なパターンを学習するのではなく、特異なイベント(例えば、2021年の一度限りの政策ショック)に過適合する場合があります。軽減策:交差検証と正則化を使用してください。データの80%で訓練し、10%で検証し、10%でテストしてください。検証エラーを監視してください。訓練エラーから乖離する場合、モデルの複雑性を削減してください。
-
リスク3:採用摩擦と信頼欠損。* 農家はアルゴリズム予測を不信感を持つ場合があります。特に直感や非公式ネットワークと矛盾する場合です。「今ニンニクを植える」という予測は、「ニンニク価格は常に12月にスパイクする」という農家の経験と矛盾します。軽減策:古典的手法を含むアンサンブル予測から始めて、透明なコミュニケーションを通じて信頼を構築してください。予測を平易な言葉で説明してください。「5年間の価格履歴に基づいて、ニンニク価格は来月平均65タカ/kgになる可能性が高く、90%の信頼度で58から72タカ/kgの間に下がるでしょう。」農家をモデル開発に関与させてください。彼らのドメイン専門知識は、モデルが間違っている場合を特定するのに非常に価値があります。
-
実行可能な示唆:* モデルメンテナンスを一度限りの取り組みではなく、継続的な運用コストとして計画してください。週単位の監視、月単位の再訓練、四半期ごとのモデル監査のためにリソースを割り当ててください。モデル更新を管理し、ユーザーへの変更を伝えるための統治構造を構築してください。
結論と次のステップ:研究から体系的変化へ
AgriPriceBDとそのベンチマークは、南アジアにおける証拠ベースの農業予測の基礎を確立します。データセットは現在、研究者と実務家が利用できます。ベンチマークは新しい手法を比較し、改善を検証するための参照を提供します。
-
より大きなビジョン:* この仕事は、より広い変革の概念実証です。南アジア全体で、農業市場は断片化され、情報が不足し、価格ショックに脆弱です。価格データを体系的にデジタル化し、予測システムを展開することで、変動性を削減し、市場効率を改善し、マージンを仲介者から生産者にシフトさせることができます。これは単なる技術的成果ではなく、より公平で回復力のある食糧システムへの一歩です。
-
即座の行動のために:*
-
価格データソースを監査してください。 レポートが非構造化形式(PDF、紙、メール)に閉じ込められている場合、言語モデル支援のデジタル化を優先してください。コストは低く、見返りは高いです。
-
ハイブリッド古典的深層学習アンサンブルをパイロットしてください。 解釈可能性のためのSARIMAから始め、精度のためのLSTMを追加し、加重平均を通じて組み合わせます。予測エラーと意思決定への影響を測定してください。
-
予測精度だけでなく、意思決定への影響を測定してください。 在庫削減、マージン改善、採用率を追跡してください。これらのメトリクスはシステムが価値を生み出すかどうかを決定します。
-
継続的な再訓練のためのフィードバックループを構築してください。 新しいデータが到着するにつれて、週単位でモデルを再訓練してください。予測エラーをリアルタイムで監視してください。MAPEが劣化する場合、調査をトリガーしてください。
-
点予測と並行して不確実性を伝えてください。 信頼区間を提供し、期待値だけではなく。ユーザーがもっともらしい結果の範囲を理解し、リスク認識的な決定をするのを支援してください。
-
統治とメンテナンスに投資してください。 モデル展開は一度限りのイベントではなく、継続的な運用です。
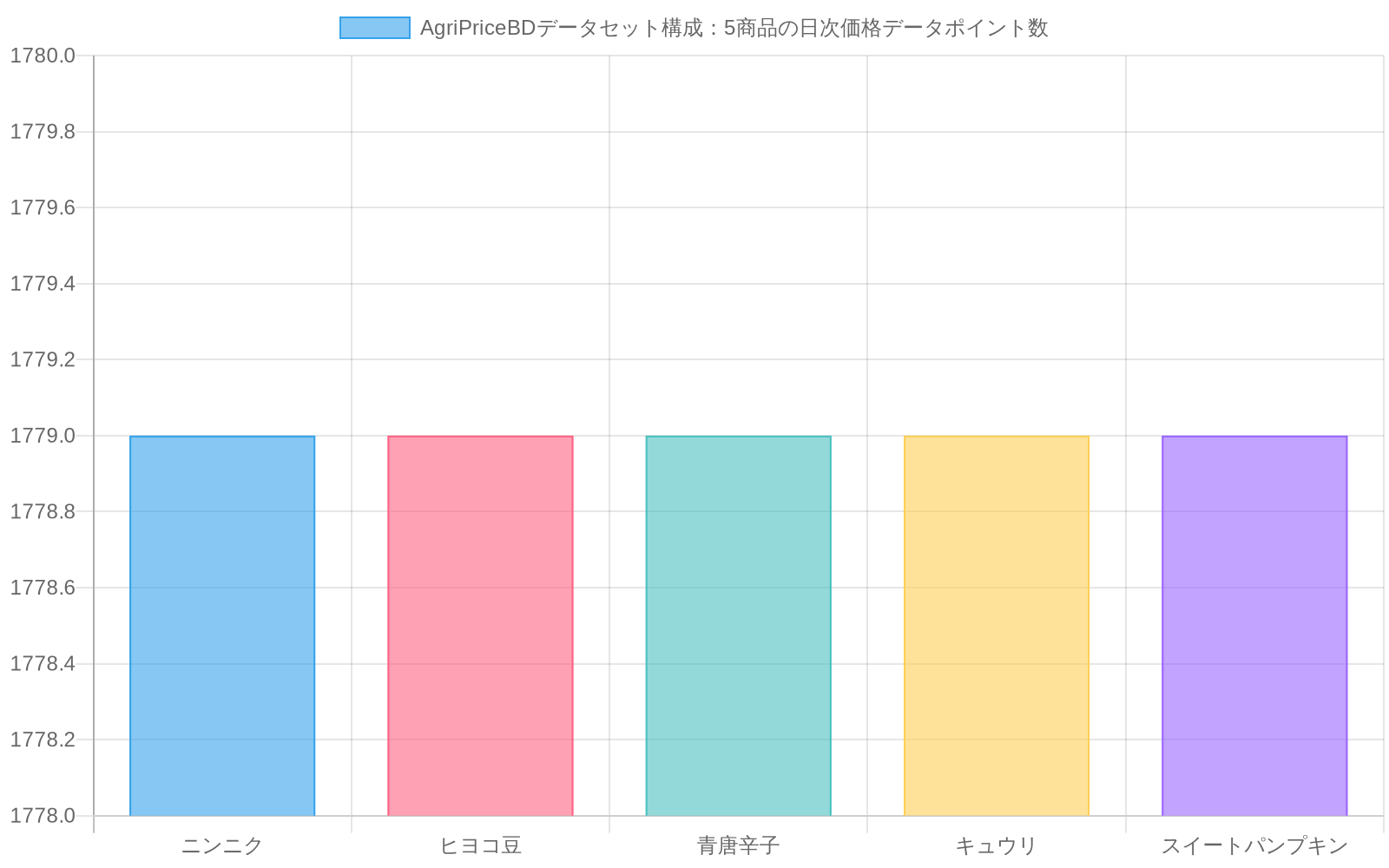
- 図3:AgriPriceBDデータセット構成:5商品の日次小売価格データ(2020年7月~2025年6月)*
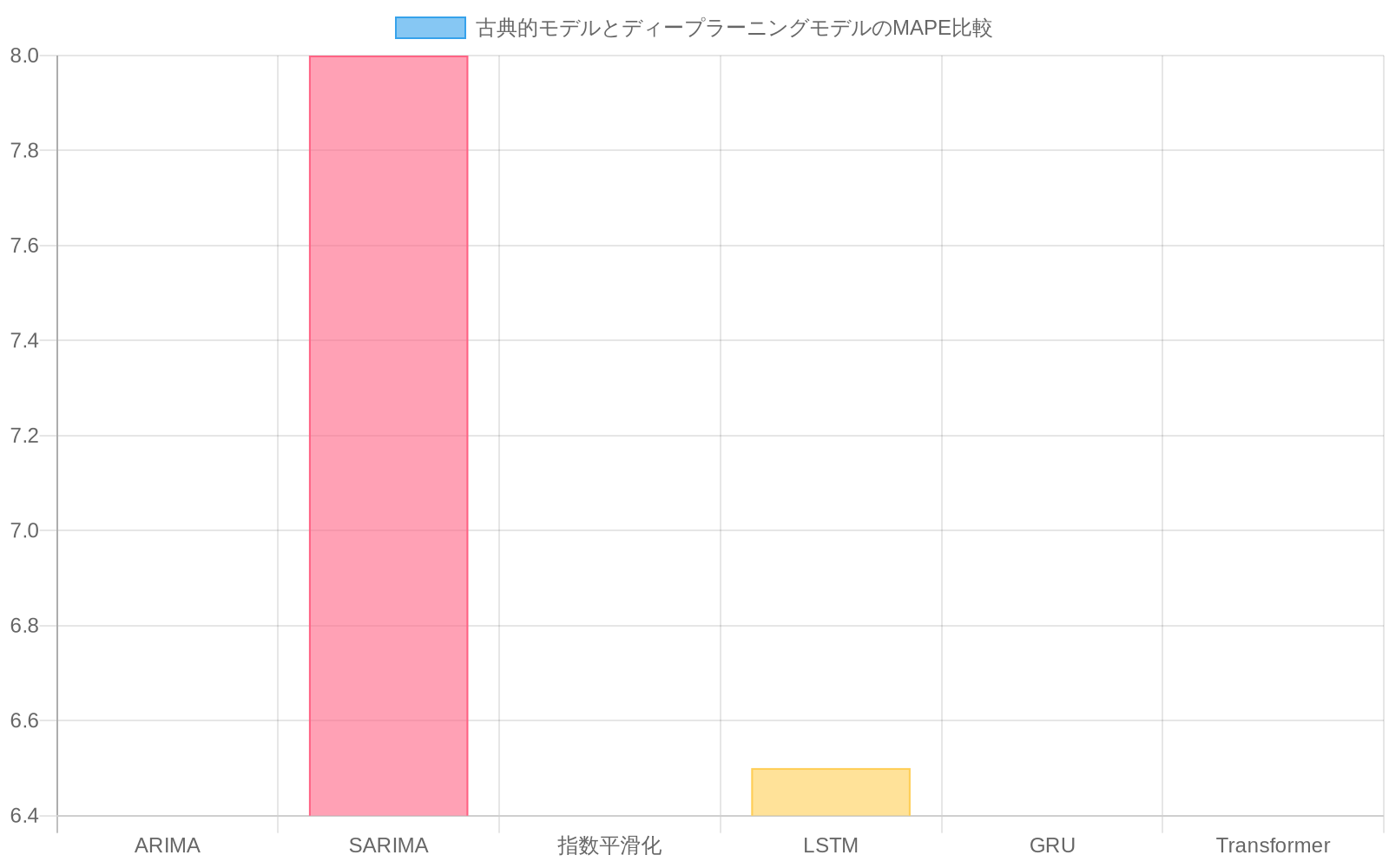
- 図4:古典的モデルとディープラーニングモデルのMAPE比較(ニンニク価格予測の例)*
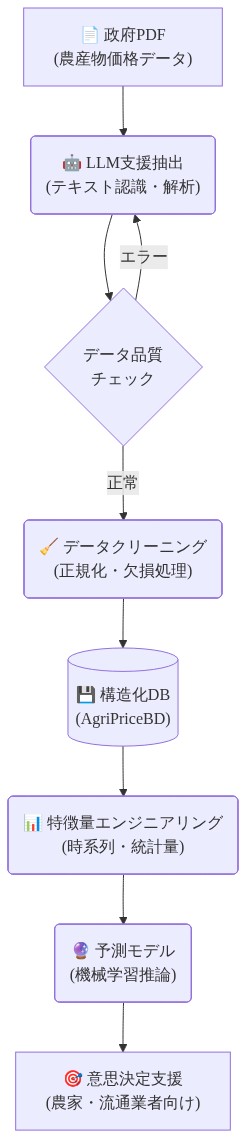
- 図2:AgriPriceBDパイプライン:PDFから本番データへのデータフロー*
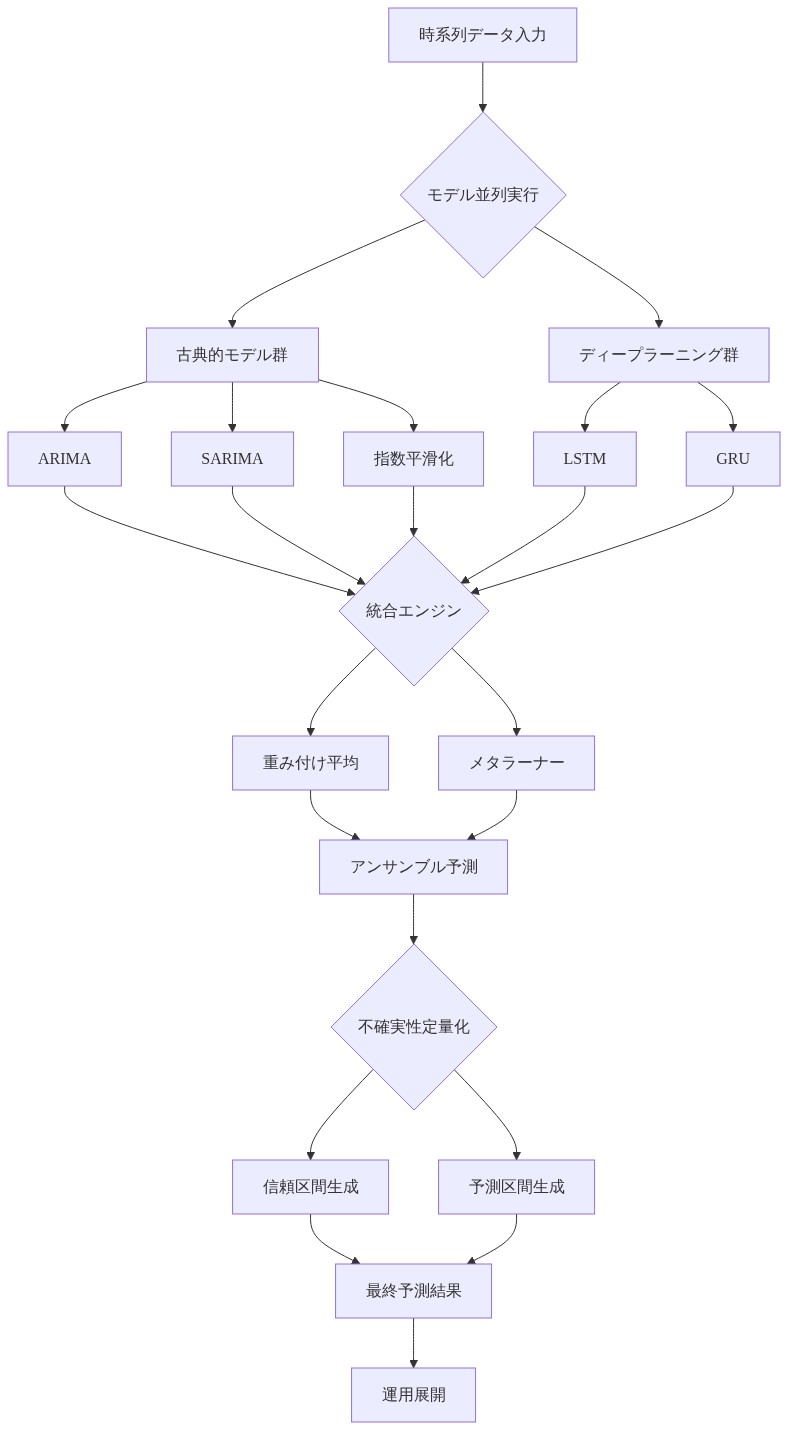
- 図5:アンサンブル戦略:複数モデルの統合と不確実性定量化(運用展開セクション)*