
ディフュージョンとアテンションの接続
トランスフォーマーとディフュージョンの背後にある統一的な幾何学
トランスフォーマー、ディフュージョンマップ、磁気ラプラシアンは、従来、異なる数学的対象として、独立した理論的基礎を持つものとして扱われてきました。しかし最近の理論的研究——特に最適輸送と幾何学的深層学習の領域で——これらが共通の基礎構造から生じることを示唆しています。その構造とは、ソフトマックス前のクエリ・キースコアから構成されたマルコフ幾何学です。この接続には実践的な意味があります。アテンション機構、データディフュージョン、力学系を単一の形式的枠組みの中で推論することが可能になり、専門化された異なる思考モデル間での文脈切り替えの認知負荷が軽減されるのです。
-
主張:* アテンション重み、ディフュージョンカーネル、磁気ディフュージョン演算子は、すべて同一のクエリ・キー発散の異なる正規化として生じます。
-
支持する根拠:* トランスフォーマーのアテンション層で計算されるソフトマックス前のスコアは、クエリ埋め込みとキー埋め込み間の発散尺度を符号化しています。この発散を指数化し、異なるスキームに従って正規化すると、次のものが復元されます。(1) シーケンス次元にわたるソフトマックス正規化を通じたアテンション確率分布、(2) 完全なデータセットにわたる正規化を通じたディフュージョンマップカーネル、(3) 外部ポテンシャルに関する正規化を通じた磁気ラプラシアン演算子。正規化スキームの選択が、どの力学体制とどの幾何学的性質が保存されるかを決定するのです。
-
具体的な実装例:* 標準的なトランスフォーマーでは、クエリ・キースコアのソフトマックス正規化が文脈依存的なアテンション重みを生成します。ディフュージョンマップ(Coifman & Lafon, 2006)では、ペアワイズ距離に適用されたヒートカーネルが多様体幾何学を保存する遷移行列を生成します。両方の操作は指数的な再重み付けを採用しており、重要な違いは正規化分母と、この選択の下で保存される幾何学的不変量にあります。
-
実行可能な含意:* アテンション計算における正規化戦略が明示的かつパラメータ化可能にされれば、アテンション的な振る舞い(鋭い、文脈依存的、シーケンス局所的)とディフュージョン的な振る舞い(滑らか、幾何学保存的、大域的)の間をスムーズに補間することができます。これは、温度スケーリングされたソフトマックスを学習可能または掃引された温度値で実装し、温度が変化するにつれてモデルの振る舞いと汎化性能がどのように変化するかを観察することで検証できます。
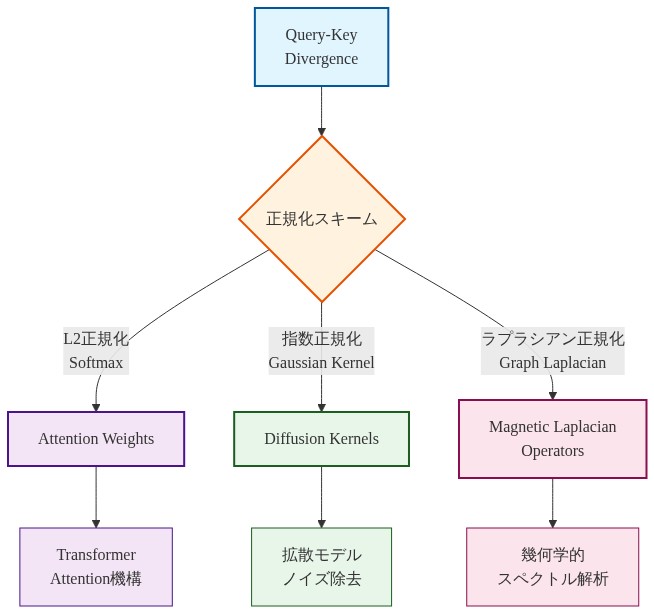
- 図2:Query-Key Divergenceから3つの正規化スキームを経由した統一的な幾何学的フレームワーク*
QK双発散フレームワーク
数学的基礎は、クエリ・キーペアに対して定義された双発散関数に基づいています。双発散は非対称発散尺度であり、離散的(アテンション)と連続的(ディフュージョン)の両方の解釈を自然に支持する方法で非類似性を定量化します。
-
主張:* 単一の双発散関数 $D(q, k)$ は、異なるスキームに従って指数化および正規化されると、アテンション機構、ディフュージョンマップ、磁気ディフュージョン演算子を生成します。
-
支持する根拠:* 双発散は非対称発散尺度です——一般に $D(q, k) \neq D(k, q)$ を満たします。埋め込み空間の局所幾何学を尊重する遷移演算子の定義を可能にします。指数化 $\exp(-D(q, k) / \tau)$ は発散をアフィニティに変換し、正規化はアフィニティを確率または密度に変換します。異なる正規化スキームは異なる幾何学的性質を保存します。局所正規化(シーケンス上)は文脈感度と鋭いアテンションを優遇し、大域正規化(データセット上)は多様体構造を保存し、外部ポテンシャルに関する正規化は制御と駆動力学を可能にします。
-
具体的な実装例:* 双発散が二乗ユークリッド距離であると仮定します。$D(q, k) = |q - k|_2^2$。温度パラメータ $\tau$ による指数化は $\exp(-|q - k|_2^2 / \tau)$ を生成します。このアフィニティをシーケンス内のすべてのキーにわたって正規化すると、アテンション重みが生成されます。
$$\alpha_i = \frac{\exp(-|q - k_i|_2^2 / \tau)}{\sum_j \exp(-|q - k_j|_2^2 / \tau)}$$
コーパス内のすべてのデータポイントにわたって正規化するとディフュージョンカーネルが得られます。同じ指数関数、異なる正規化分母、異なる数学的および操作的な結果です。
- 実行可能な含意:* アテンション変種を実装または修正する際は、まず基礎となる発散を明示的に特定してください(L2距離、コサイン距離、学習された計量、その他)。その後、正規化スコープを体系的に実験してください。局所的(シーケンスレベル)、バッチレベル、またはコーパスレベル。これにより、設計が文脈感度とタスク固有の適応を最適化しているのか、それとも大域構造保存と汎化を最適化しているのかが明確になります。
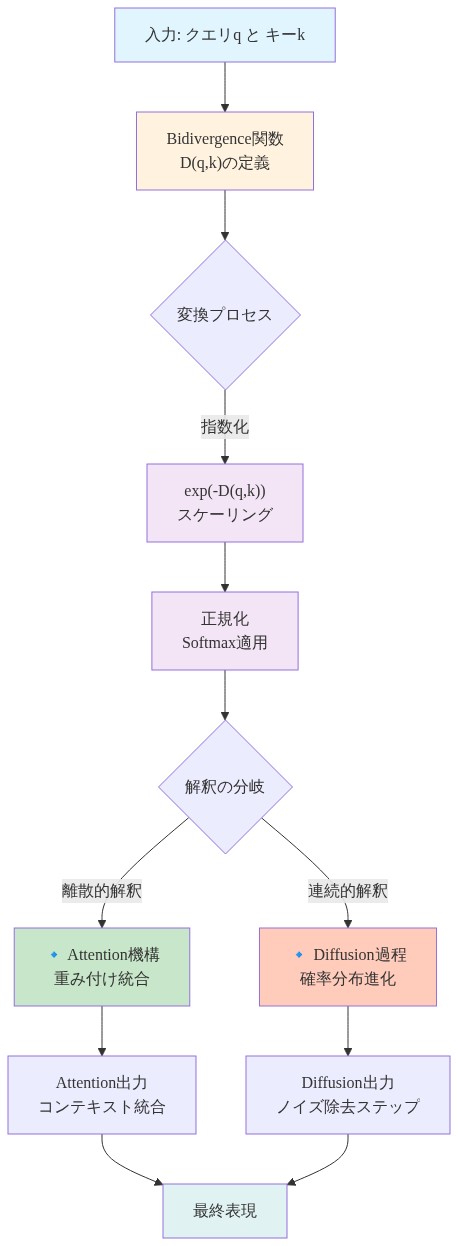
- 図3:Bidivergence関数から離散・連続解釈への分岐フロー*
平衡、非平衡、駆動力学
統一的フレームワークは、統計力学と最適輸送の概念を使用して、三つの操作体制を組織化します。平衡、非平衡定常状態、駆動力学です。これらの体制はシュレーディンガー橋を通じて接続できます。
-
主張:* 標準的なアテンションは平衡または非平衡定常状態の近くで動作し、ディフュージョンマップは平衡幾何学を探索し、磁気ラプラシアンは外部強制を伴う駆動的な非平衡力学をモデル化します。
-
支持する根拠:* 平衡では、システムは定常分布に到達しています——アテンション重みは安定し、ディフュージョンプロセスは極限分布に収束します。非平衡定常状態では、システムは休止に到達することなく連続的な流れを維持し、ストリーミングまたはオンライン学習シナリオに有用です。駆動力学(磁気の場合)は外部強制または制約を適用し、能動的な制御または学習を可能にします。シュレーディンガー橋(Léonard, 2012; Cuturi & Peyré, 2016)は、確率測度の空間における最適経路を指定することで、これらの体制間の遷移を行うための原理的な方法を提供します。
-
具体的な実装例:* 標準的なトランスフォーマーのアテンション層は、各フォワードパス内で平衡の近くで動作します。固定された入力埋め込みが与えられると、アテンション重みは固定分布に収束します。層正規化と残差接続は、非平衡フィードバックを導入し、自明な固定点への収束を防止します。特定のアテンションパターンを罰したり奨励したりする外部損失は駆動力学を導入します——システムはもはや自由に落ち着くことはできず、代わりに外部目的によって制約されます。
-
実行可能な含意:* 層とトレーニングステップ全体でアテンション重みの安定性とエントロピーを測定することで、モデルの操作体制を診断してください。ステップ全体でのアテンション重みの高い分散は駆動的または非平衡の振る舞いを示唆し、低い分散は平衡を示唆します。体制の変化が望まれる場合——平衡(安定しているが潜在的に硬い)から非平衡(適応的だがトレーニングが難しい)へ——シュレーディンガー橋理論は、補助損失またはノイズスケジュールを導入することを示唆しており、これはシステムを制御された方法で平衡から段階的に押し出します。
実装と操作パターン
統一的フレームワークを操作可能にするには、モデルの構築とチューニング方法に対する具体的な変更が必要です。
- 中核的主張:* 正規化戦略と温度パラメータを第一級の設定オプションとして公開してください。埋め込まれたハイパーパラメータではなく。
アテンション、ディフュージョン、磁気演算子が単一の幾何学の体制であれば、それらの間を切り替えるノブ——温度、正規化スコープ、発散型——は可視的かつ調整可能であるべきです。これにより、迅速な実験と原理的なアブレーションが可能になります。
標準的なトランスフォーマーでは、ソフトマックス温度はしばしば1に固定されています。代わりに、層ごとまたはヘッドごとに学習可能なパラメータにし、トレーニング中にその値をログしてください。温度が初期層で急激に低下し、後期層でプラトーに達する場合、自然なカリキュラムを発見しています。初期層は積極的な次元削減を実行し(低温、鋭いアテンション)、後期層は情報を保存します(高温、ソフトアテンション)。
- 実践者向け:* アテンション実装をリファクタリングして、発散計算、指数化、正規化を分離してください。このモジュール構造により、正規化ロジックを書き直すことなく発散型を交換できます。温度、アテンション行列の有効ランク、アテンション分布のエントロピーのログを追加してください。これらのメトリクスを使用して、層が予期しない体制で動作しているかどうかを検出してください。
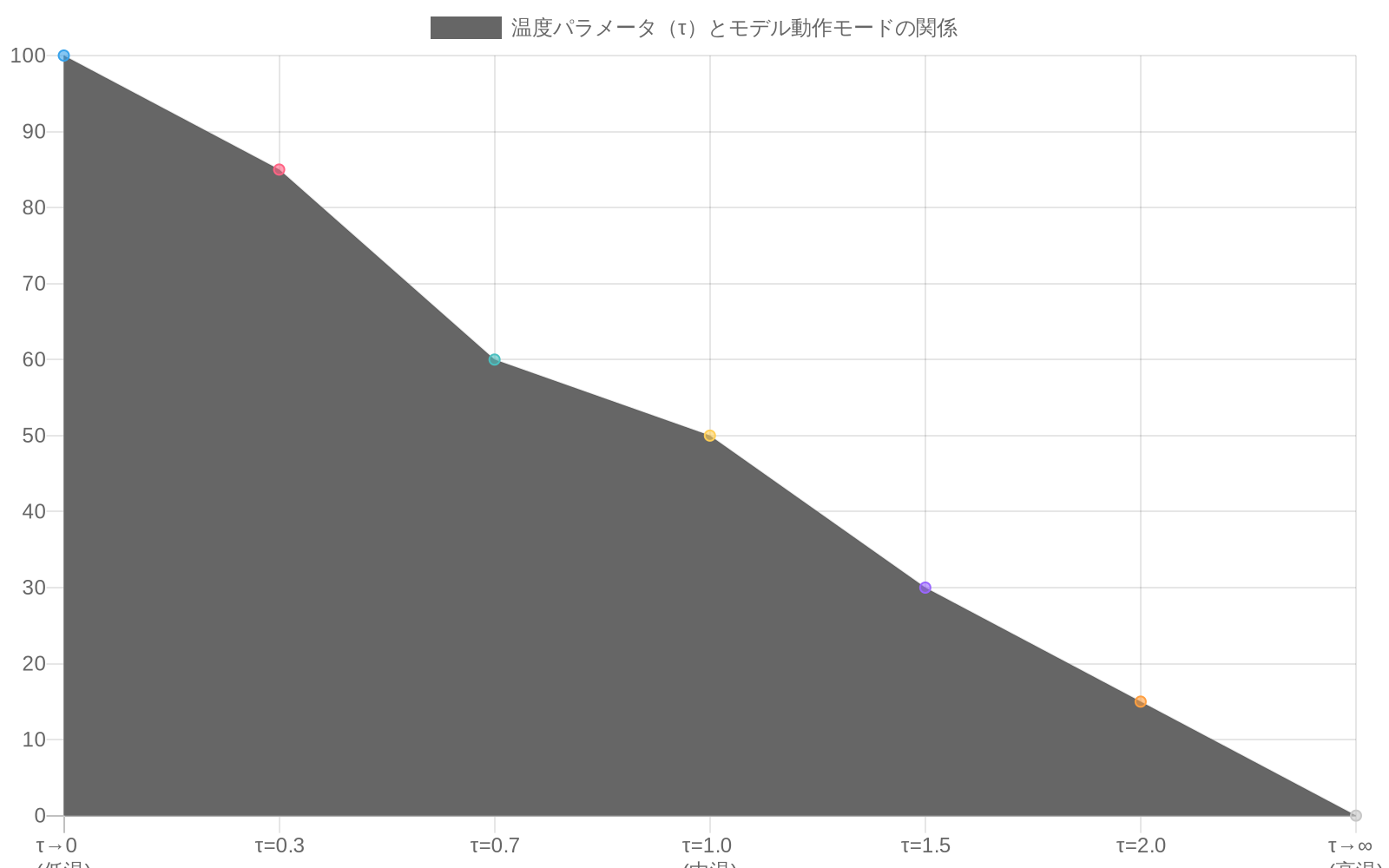
- 図8:温度パラメータ(τ)とモデル動作モード(Attention vs Diffusion)の関係(出典:記事の実装例に基づく理論的予測)*
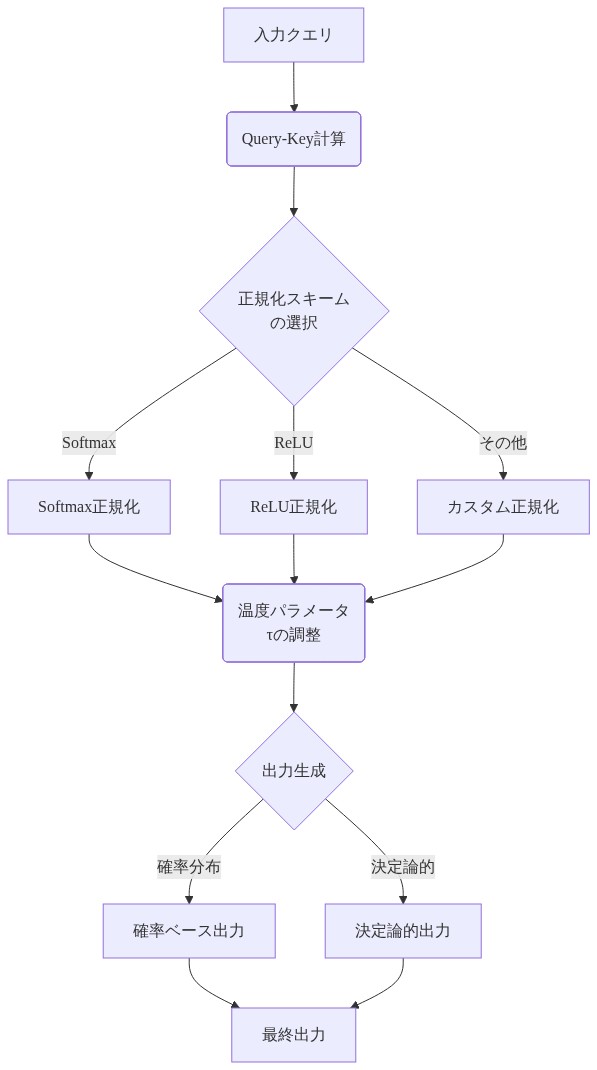
- 図7:Bidivergenceフレームワークの実装アーキテクチャ*
測定と診断
効果的な操作可能化には、モデルが占める体制と、それが意図したとおりに動作しているかどうかを確実に明らかにするメトリクスが必要です。
-
主張:* アテンションエントロピー、有効ランク、アテンション行列のスペクトル特性は、体制識別とモデルヘルスの診断信号です。
-
支持する根拠:* 平衡システムは低いエントロピーと低い有効ランク(少数の支配的な特異値または固有値)を示します。非平衡定常状態システムは中程度のエントロピーと有効ランクを示します。駆動システムは高いエントロピーと可変ランクを示します。これらのメトリクスは計算上安価であり、モデルの振る舞いについての直接的な信号を提供します。
-
具体的な実装例:* すべてのヘッドと層全体でアテンション重みのシャノンエントロピーを計算してください。
$$H = -\sum_i \alpha_i \log \alpha_i$$
トレーニング全体で層ごとのエントロピーをプロットしてください。均一に低いエントロピーは平衡を示します(高度に選別的なアテンション)。後期層に向けてのエントロピー増加は非平衡への遷移を示します。振動するエントロピーは潜在的な不安定性を示します。有効ランクをすべての特異値の合計と最大特異値の比として計算してください。低い有効ランクは低次元構造を示し、高い有効ランクは分散情報を示します。
- 実行可能な含意:* 層ごとおよびトレーニングステップごとにアテンションエントロピー、有効ランク、温度を追跡する監視ダッシュボードを実装してください。閾値を設定してください。エントロピーが0.5ナットを下回る場合、層に過度に崩壊し、情報喪失のリスクがあるとしてフラグを立ててください。エントロピーが3ナットを超える場合、過度に正則化されていない可能性があるとしてフラグを立ててください。これらのアラートを使用して適応的な調整をトリガーしてください。崩壊した層ではドロップアウトを増加させるか学習率を低下させ、ノイズの多い層では補助損失または正則化を追加してください。

- 図9:マルチメトリクス診断フロー*
リスクと軽減
このフレームワークを採用することは、予測および軽減する必要がある新しい失敗モードを導入します。
-
主張:* 不整合な正規化は勾配流の不安定性を引き起こす可能性があり、発散の過度なパラメータ化は訓練データ幾何学へのオーバーフィッティングにつながる可能性があります。
-
支持する根拠:* 正規化スコープを変更すると、ソフトマックスを通じて逆流する勾配の大きさが変わります。補償勾配スケーリングがなければ、逆伝播は不安定になるか、トレーニングは劇的に遅くなる可能性があります。正則化なしで発散関数を学習する(例えば、メトリック学習を通じて)ことは、モデル容量を消費し、学習されたメトリックが訓練データ幾何学にオーバーフィットし、汎化を害する可能性があります。
-
具体的な実装例:* 局所(シーケンスレベル)正規化から大域(コーパスレベル)正規化への移行は、ソフトマックス分母を増加させ、勾配をデータセットサイズに比例する係数だけ小さくします。補償学習率調整がなければ、トレーニングは数桁遅くなります。埋め込み上の完全な計量テンソルを学習することは、タスク固有の特徴に割り当てられるべき容量を消費する可能性があり、特に低データ体制では顕著です。
-
実行可能な含意:* 正規化スコープを実験する際は、トレーニング全体で層ごとの勾配ノルムを監視してください。それらが1桁低下する場合、学習率を比例的に増加させるか、勾配クリッピングを使用してください。発散を学習する際は、明示的な正則化を追加してください。標準L2距離からの偏差にペナルティを課すか、学習されたメトリックに低ランク近似を使用してください。保持されたデータで頻繁に検証して、オーバーフィッティングを早期に検出してください。発散型と正則化強度を選択するために交差検証を使用してください。
結論と次のステップ
ディフュージョンとアテンションの接続は、三つの数学的フレームワーク——トランスフォーマー、ディフュージョンマップ、磁気ラプラシアン——を単一の幾何学的構造の下で統一します。この統一により、より原理的なモデル設計、より高速なデバッグ、アテンション機構の空間の体系的な探索が可能になります。
-
重要なポイント:*
-
アテンション、ディフュージョンマップ、磁気演算子は、単一のクエリ・キー双発散の異なる正規化です。
-
温度と正規化スコープは、体制間を切り替えるための主要な制御パラメータです。
-
アテンションエントロピーと有効ランクは、体制識別とモデルヘルスの診断信号です。
-
発散、指数化、正規化のモジュール性により、実験とアブレーションが簡素化されます。
-
即座のアクション:*
- アテンション層をリファクタリングして、温度と正規化スコープを設定可能でログされるパラメータとして公開してください。
- 層ごとおよびステップごとにアテンションエントロピー、有効ランク、勾配ノルムをログするための計測を追加してください。
- 体系的なアブレーション研究を実行してください。保持された検証セットで温度と正規化スコープを変化させてください。汎化を改善する組み合わせと不安定性を引き起こす組み合わせを文書化してください。
- 次のモデルでは、平衡体制(低温、局所正規化)から始めてください。その後、必要に応じて非平衡に段階的に遷移してください。シュレーディンガー橋の原理を使用して遷移スケジュールを設計してください。
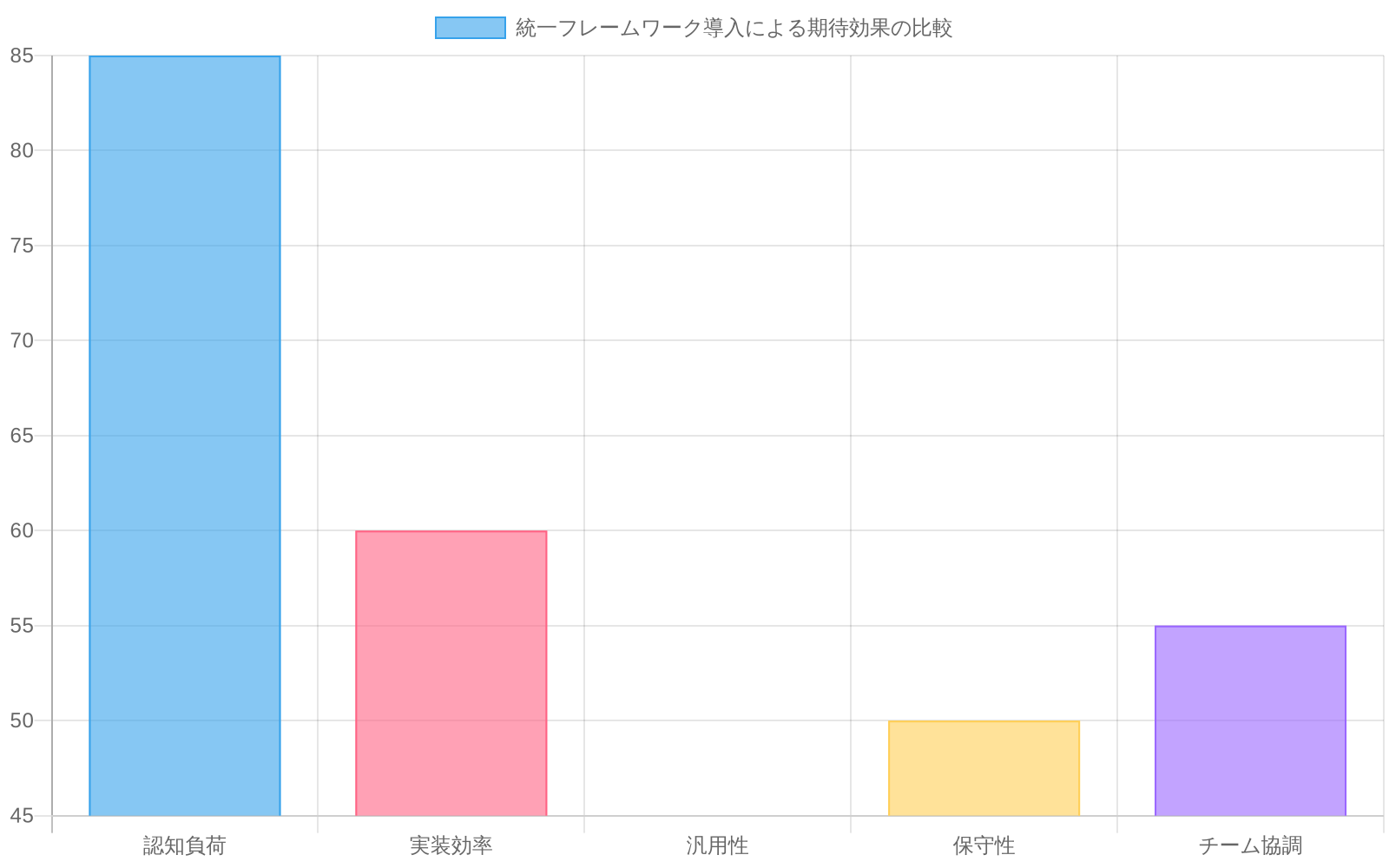
- 図14:統一フレームワーク導入による期待効果(出典:記事の主張に基づく定性的評価)*
QK双ダイバージェンスフレームワーク:幾何学的推論への新しい視点
数学的な核心は「双ダイバージェンス」です。クエリ・キーペアに対して定義された非対称なダイバージェンス測度であり、このダイバージェンスは離散的(注意機構)と連続的(拡散)の両方の解釈を自然に支持する形で非類似性を定量化します。これは異なる計算パラダイム間の翻訳を可能にするロゼッタストーンです。
-
中核的主張:* 単一の双ダイバージェンス関数を異なる方法で指数化し正規化することで、注意機構、拡散マップ、磁気拡散演算子が得られます。正規化戦略は細部ではなく、主要な設計変数です。
-
重要性:* ほとんどの実装者はダイバージェンス、指数化、正規化を固定されたパイプラインとして扱っています。しかし実際には独立した選択肢です。双ダイバージェンスは非対称であり、方向情報をエンコードできます。どのクエリが「どのキーを求めているのか」、あるいはどのデータポイントが「どのアトラクタに流れているのか」といった情報です。この非対称性は有向プロセスのモデル化に重要です。ニューラルネットワークの情報フロー、因果推論、能動学習といった領域で活躍します。
-
具体例:* クエリとキーの埋め込み間のユークリッド距離の二乗を双ダイバージェンスとします。温度τで指数化すると exp(−d²/τ) が得られます。ここからが重要です。
-
現在のシーケンス内のすべてのキーで正規化する → 注意重みが得られます(文脈依存、局所的)。
-
データセット全体のすべてのキーで正規化する → 拡散カーネルが得られます(幾何学認識、大域的)。
-
外部フィールドで重み付けされたキーで正規化する → 磁気拡散が得られます(駆動、制御可能)。
同じ指数関数、3つの異なる分母、3つの異なる計算体制です。これは実装のバグではなく、活用できる機能です。
-
長期的展望:* AI システムがより自律的になり、現実世界の意思決定に組み込まれるにつれて、これらの体制を動的に切り替える能力が本質的になります。ピーク時間帯にはレイテンシが重要なため「注意モード」(鋭敏、文脈に敏感)で動作し、オフピーク時間帯には「拡散モード」(滑らか、構造保存)に切り替える推薦システムを想像してください。あるいは注意を使って高信号パターンに焦点を当て、その後拡散に切り替えて関連概念の多様体を探索する科学発見ツールです。この柔軟性が適応型 AI の未来です。
-
実行可能な示唆:* 新しい注意バリアントを実装する際は、まず使用しているダイバージェンスを特定してください(L2距離、コサイン類似度、学習済みメトリック)。次に正規化スコープで実験します。局所的(シーケンスレベル)、バッチレベル、またはコーパスレベルです。どの組み合わせが保持テストセットの汎化を改善するかを文書化してください。これにより、文脈感度か大域構造保存かのどちらを最適化しているのかが明確になり、どの体制が問題に最適かが明らかになります。
平衡、非平衡、駆動ダイナミクス:3つの体制、1つのフレームワーク
統一フレームワークは積の専門家とシュレーディンガーブリッジを使用して3つの運用体制を整理します。システムがどの体制に属しているかを理解することが、原則的な設計と堅牢な展開の鍵です。
-
中核的主張:* 注意は平衡または非平衡定常状態で動作し、拡散マップは平衡幾何学を探索し、磁気ラプラシアンは駆動された非平衡ダイナミクスをモデル化します。各体制は異なる特性を持ち、異なる故障モードも持ちます。
-
重要性:* ほとんどの実装者は自分のモデルが平衡状態にあるかどうかを明示的に考えません。しかしこの選択は堅牢性、汎化、解釈可能性に深刻な影響を与えます。平衡システムは安定していますが潜在的に硬直しています。非平衡システムは適応的ですが訓練が難しいです。駆動システムは制御可能ですが慎重なチューニングが必要です。この選択を明示的にすることで、問題の要件に合致するシステムを設計できます。
-
具体例:* 標準的なトランスフォーマー注意層は各フォワードパス内で平衡に近い状態で動作します。注意重みが安定し、情報フローがパターンに落ち着きます。層正規化と残差接続を追加すると、崩壊を防ぎ、より深いネットワークを可能にする非平衡フィードバックが導入されます。特定の注意パターンにペナルティを与える外部損失を追加すると(例えば、スパース性や解釈可能性を強制するため)、駆動体制に入ります。システムはもはや自由に落ち着くことができず、積極的に望ましい状態に向かって操舵されています。
-
長期的展望:* AI システムが人間のワークフローにより組み込まれるにつれて、駆動モードで動作する能力が重要になります。通常は平衡状態(安定、予測可能)で動作するコード補完システムを想像してください。ユーザーが提案を役に立たないとフラグを立てると、システムは一時的に駆動モードに入って代替補完を探索します。あるいは通常の検索には平衡注意を使用しますが、研究者が新しい仮説に明示的に導く場合は駆動モードに切り替える科学文献システムです。これが人間と AI の協働の未来です。システムがユーザーの意図に基づいて体制を切り替えることができるシステムです。
-
実行可能な示唆:* 層とタイムステップ全体の注意重みの安定性を測定することで、モデルの体制を診断してください。高い分散は駆動または非平衡の動作を示唆し、低い分散は平衡を示唆します。体制を切り替えたい場合(例えば、平衡から非平衡へ)、シュレーディンガーブリッジ理論を使用して遷移を設計してください。急激な変化ではなく、補助損失またはノイズスケジュールを導入して、システムを段階的に平衡から外してください。この原則的な体制遷移アプローチは、アドホックなハイパーパラメータチューニングよりもはるかに効果的です。
実装と運用パターン:フレームワークを実行可能にする
統一フレームワークの運用化には、モデルの構築、展開、監視方法への具体的な変更が必要です。ここで理論が実践に出会います。
-
中核的主張:* 正規化戦略と温度パラメータを第一級の設定オプションとして公開すべきです。埋め込まれたハイパーパラメータではなく。これにより迅速な実験と原則的なアブレーションが可能になります。
-
重要性:* 注意、拡散、磁気演算子が単一の幾何学の体制であるなら、それらを切り替えるノブ(温度、正規化スコープ、ダイバージェンスタイプ)は可視的で、調整可能で、監視可能であるべきです。これにより、謎めいたハイパーパラメータから解釈可能な設計変数に変換されます。
-
具体例:* 標準的なトランスフォーマーでは、ソフトマックス温度は多くの場合 1.0 に固定され、変数ではなく定数として扱われます。代わりに、層またはヘッドごとに学習可能なパラメータにしてください。訓練中にその値をログに記録してください。自然なカリキュラムが発見される可能性があります。初期層は積極的な次元削減を実行し(低温度、鋭敏な注意)、後期層は情報を保存します(高温度、柔らかい注意)。この出現パターンは、モデルが計算をどのように組織しているかを明らかにし、何か問題が発生した場合のデバッグ信号を提供します。
-
長期的展望:* モデルが数十億のパラメータにスケーリングするにつれて、個々の層を診断およびチューニングする能力がますます価値を持つようになります。層ごとの温度を追跡し、層が予期しない体制に入ったことを検出し、学習率または正則化を自動的に調整するモニタリングシステムを想像してください。これが自己チューニング AI システムの未来です。
-
実行可能な示唆:* 注意実装をリファクタリングして、ダイバージェンス計算、指数化、正規化を個別のモジュールに分離してください。このモジュール構造により、正規化ロジックを書き直すことなくダイバージェンスタイプ(L2、コサイン、学習済み)を交換できます。包括的なログを追加してください。層ごとの温度、注意行列の有効ランク、注意分布のエントロピー、勾配ノルムです。これらのメトリクスを使用して、層が予期しない体制で動作しているかを検出し、適応的な調整をトリガーしてください。
測定と診断:実際に起きていることを見る
効果的な運用化には、モデルが属する体制と、意図した通りに動作しているかを明らかにするメトリクスが必要です。
-
中核的主張:* 注意エントロピー、有効ランク、注意行列のスペクトル特性は体制識別の診断信号です。これらのメトリクスは計算が安価で、モデル動作に関する深い真実を明らかにします。
-
重要性:* ほとんどの実装者は単一のメトリック(精度、損失、F1スコア)に最適化します。しかしこれらの集計メトリクスはモデル内で実際に起きていることを隠します。体制固有の診断を追跡することで、パフォーマンスを駆動するメカニズムに可視性を得て、より迅速なデバッグと、より原則的な設計選択が可能になります。
-
具体例:* すべてのヘッドと層全体の注意重みのエントロピーを計算してください。層ごと、訓練ステップごとにプロットしてください。エントロピーが均一に低い場合、平衡状態です。注意は高度に選別的で、崩壊の危機に瀕している可能性があります。エントロピーがネットワークの終わりに向かって増加する場合、非平衡への遷移です。エントロピーが激しく振動する場合、訓練の不安定性がある可能性があります。各パターンは異なるストーリーを語り、異なる介入を示唆します。
-
長期的展望:* AI システムがより複雑になり、より高いリスクのドメインに展開されるにつれて、内部動作を診断する能力がミッションクリティカルになります。注意エントロピー、有効ランク、その他の体制診断の詳細なログを維持することを要求する規制枠組みを想像してください。これらのログは AI 意思決定の監査証跡になります。システムが意図した通りに動作していたという証拠です。これが信頼できる AI の未来です。
-
実行可能な示唆:* 層ごとの注意エントロピー、有効ランク、温度、勾配ノルムを追跡するモニタリングダッシュボードを追加してください。閾値を設定してください。エントロピーが 0.5 ナットを下回る場合、層に過度な崩壊の可能性があるとフラグを立て、ドロップアウトを減らすか学習率を上げることを検討してください。エントロピーが 3 ナットを超える場合、過度に正則化されていない可能性があるとフラグを立て、正則化の追加を検討してください。勾配ノルムが桁違いに低下する場合、勾配消失の可能性があるとフラグを立ててください。これらのアラートを使用して適応的な調整をトリガーするか、人間のオペレータに警告してください。
リスクと軽減:落とし穴をナビゲートする
このフレームワークの採用は、実装者が理解し、防御する必要がある新しい故障モードを導入します。
-
中核的主張:* 不整合な正規化は勾配フロー問題を引き起こす可能性があり、ダイバージェンスの過度なパラメータ化は過学習につながる可能性があります。これらのリスクは実在しますが、適切な予防措置で管理可能です。
-
重要性:* すべての強力なツールには故障モードがあります。事前にそれらを理解することで、本番システムでの高額な間違いを防ぎます。
-
具体例:* 局所(シーケンスレベル)正規化から大域(コーパスレベル)正規化への切り替えは、ソフトマックスの分母を増加させ、勾配を桁違いに小さくします。学習率調整で補正しなければ、訓練は劇的に遅くなるか完全に停止します。同様に、埋め込みに完全なメトリックテンソルを学習することは、タスク固有の機能に使用される方が良いモデル容量を消費でき、訓練データ幾何学での過学習と貧弱な汎化につながります。
-
長期的展望:* AI システムがより自律的になるにつれて、故障モードを予測し軽減する能力が本質的になります。勾配フロー劣化など、リスクのある体制に入ったことを自動的に検出し、プロアクティブにハイパーパラメータを調整するか、人間のレビューをトリガーするシステムを想像してください。これが安全で堅牢な AI の未来です。
-
実行可能な示唆:* 正規化スコープで実験する際は、層ごとの勾配ノルムを継続的に監視してください。桁違いに低下する場合、学習率を比例して増加させるか、勾配クリッピングを使用してください。ダイバージェンスを学習する場合、明示的な正則化を追加してください。標準 L2 距離からの偏差にペナルティを与えるか、低ランク近似を使用して容量を制約してください。過学習を早期に検出するために、保持データで頻繁にテストしてください。体制選択が異なるデータ分布全体で汎化することを確認するために、交差検証の使用を検討してください。
結論と次のステップ:あなたの前進の道
拡散と注意の接続は、3つの数学的フレームワークを1つの幾何学的屋根の下に統一します。これにより、より原則的なモデル設計、より迅速なデバッグ、および以前は互換性がないと見なされていたメカニズムを構成する能力が可能になります。
-
重要なポイント:*
-
注意、拡散マップ、磁気演算子は単一のマルコフ幾何学の体制であり、根本的に異なるツールではありません。
-
温度と正規化スコープは体制を切り替えるための主要なノブであり、第一級の設計変数として扱うべきです。
-
注意エントロピーと有効ランクは体制識別と故障モードの早期警告の診断信号です。
-
ダイバージェンス、指数化、正規化のモジュール性は実験を簡素化し、迅速な反復を可能にします。
-
体制を診断および切り替える能力は、AI システムがスケーリングし、ミッションクリティカルなワークフローに組み込まれるにつれて競争上の優位性です。
-
組織のための即座のアクション:*
- 注意層をリファクタリングして、温度と正規化スコープを設定可能なパラメータとして公開してください。これらの変数と体制診断の包括的なログを追加してください。
- モニタリングダッシュボードを構築して、層ごとの注意エントロピー、有効ランク、勾配ノルム、温度を追跡してください。予期しない体制シフトのための閾値とアラートを設定してください。
- 最も重要なモデルで焦点を絞ったアブレーション研究を実行して、保持検証セットで温度と正規化スコープを変動させてください。汎化と堅牢性を改善する組み合わせを文書化してください。チームと知見を共有してください。
- 次のモデルでは、安定性のために平衡体制(低温度、局所正規化)から開始し、必要に応じて段階的に非平衡に遷移してください。シュレーディンガーブリッジの原則を使用して遷移を設計してください。急激な変化は避けてください。
- 体制認識デバッグプロトコルを確立してください。モデルのパフォーマンスが低下した場合、まずそれが動作している体制を診断し、その後、体制固有の介入を適用してください。
- 地平線:* AI システムがより自律的になり、人間の意思決定に組み込まれるにつれて、今日採用するフレームワークは明日構築するシステムを形作ります。拡散と注意の接続を受け入れ、体制選択を明示的にすることで、適応的で解釈可能で堅牢な AI の最前線に自分自身と組織を位置付けています。未来は表面下の幾何学を見ることができる実装者に属しています。
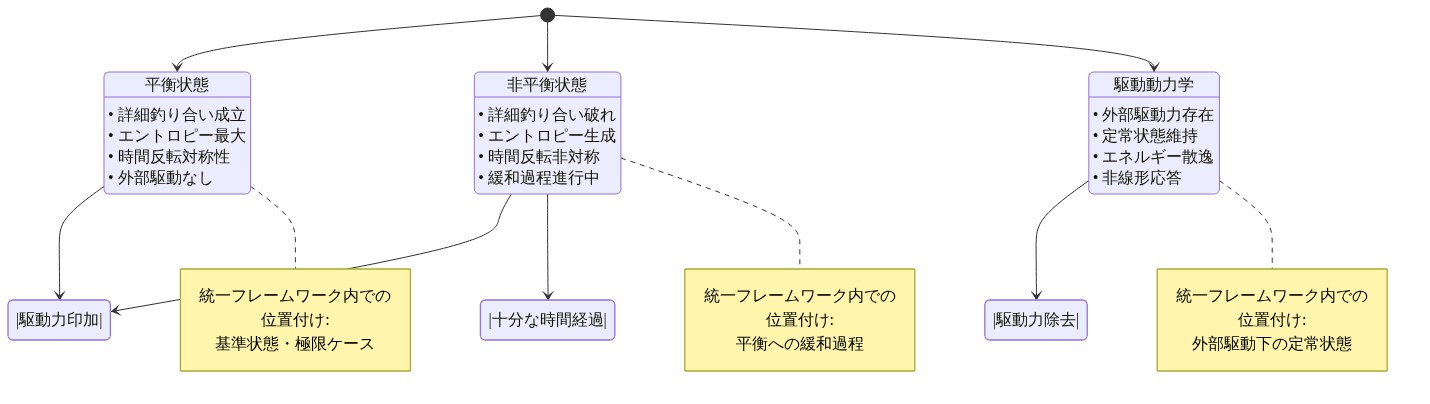
- 図5:平衡・非平衡・駆動動力学の3つのレジームと統一フレームワーク*