
フレイドRoPEと長入力:幾何学的視点
回転の幾何学:RoPEが位置をエンコードする仕組み
回転位置埋め込み(RoPE)は、高次元空間のトークン表現に回転行列を適用することで動作します。回転角は位置インデックスに比例します(Su et al., 2021)。形式的には、位置mにあるトークンについて、次元ペア(2i, 2i+1)は角度θ_i·mだけ回転します。ここでθ_i = 10,000^(-2i/d)であり、dはモデルの次元です。この構成により、トークンペア間の角度差を通じて相対位置情報をエンコードする幾何学的構造が生成されます。
このメカニズムは設計上、相対位置特性を満たしています。位置mとnにおけるクエリとキー表現間のドット積は、絶対位置ではなく、オフセット(m - n)のみに依存します。この特性は、注意ヘッドが訓練中に遭遇した角度範囲内で動作する限り、数学的枠組みの中で正確に成立します。経験的には、この回転構造は訓練長分布内のシーケンスに対して高い効果を示します。注意メカニズムが特定の限定された角度領域内でトークン関係を認識することを学習するためです。
幾何学的脆弱性は、入力が訓練長を超えるときに現れます。拡張位置にあるトークンは、訓練中に遭遇したことのない角度領域に回転します。これは幾何学的外挿を表しており、意味的一般化とは根本的に異なる問題です。勾配降下法を通じて訓練された角度範囲内のパターンを認識するように調整された注意ヘッドは、学習されたパターンが信頼できるガイダンスを提供しない分布外の幾何学的領域からの信号を受け取ります。
-
具体例:* 次元d = 4,096で最大4,096トークンのシーケンスで訓練されたモデルを考えます。位置4,096では、最低回転周波数(θ_0 ≈ 1.0)は約4,096ラジアン、つまり約652回転の回転角を生成します。位置8,192では、同じ周波数が8,192ラジアン、つまり約1,304回転を生成します。0~4,096ラジアン範囲内の関係を認識するように調整された注意ヘッドは、学習された注意パターンが一般化しない可能性がある4,096~8,192ラジアン範囲からの信号を受け取ります。
-
実行可能な示唆:* 拡張シーケンスにモデルをデプロイする前に、訓練長でのベースラインパフォーマンスを確立し、目標長での劣化を測定します。回転角全体にわたる注意重み分布を可視化して、推論が分布外の幾何学的領域に入っているかどうかを特定します。早期検出により、段階的な障害が発生する前に適切な緩和戦略を選択できます。
分布外回転:破綻のマッピング
拡張長でのパフォーマンス劣化は、ランダムな障害モードではなく、予測可能な幾何学的パターンに従います。回転ストレス下での注意メカニズムの経験的分析は、体系的な歪みを明らかにします。(1)遠いトークンは訓練分布に対して不釣り合いな注意質量を受け取り、(2)クエリキー整列パターンが反転または崩壊し、(3)シーケンス長が増加するにつれて注意エントロピーが非単調な動作を示します(Kaplan et al., 2020; Hoffmann et al., 2022)。
これらの現象は、回転空間における構造化された幾何学的歪みから生じます。異なる注意ヘッドは、学習された回転周波数感度に基づいて異なる障害モードを示します。より高い回転周波数で訓練されたヘッド(小さいiに対するθ_i)は、より低い周波数を持つヘッドよりも早く分布外の角度に遭遇します。この異質性は、ニューラルネットワークが幾何学的関係をどのように表現するかについての建築的制約を反映しています。これは、ネットワークが学習中にエンコードされた基本的な仮定のため、訓練分布を超えて一般化するのに苦労するニューラルネットワーク外挿の研究で文書化された制限です(Bisk et al., 2020)。
破綻軌跡は再現可能です。モデルと入力長が与えられると、同じ注意ヘッドが複数の実行にわたって同じ方法で失敗します。この再現性は、障害が確率的効果ではなく決定論的な幾何学的特性に由来することを示しています。
-
具体例:* 32個の注意ヘッドを持つ7Bパラメータモデルでは、ヘッド1(最低回転周波数)は訓練長の1.8倍まで安定した注意パターンを維持しますが、ヘッド32(最高回転周波数)は訓練長の1.2倍で注意の崩壊を示します。この外挿容量の50%の差は、回転周波数の大きさと直接相関しています。
-
実行可能な示唆:* モデル初期化中に、ヘッドごとの回転周波数分布を計算します。より低いピーク周波数を持つヘッドを特定します。これらはより堅牢な外挿器です。建築的修正を設計する際、より低い周波数回転への初期化にバイアスをかけるか、入力長に適応する学習可能な周波数スケーリングを実装することを検討します。
幾何学的不変量と注意メカニクス
RoPEの安定性は、重要な幾何学的不変量を保持することに依存しています。シーケンス位置全体にわたる累積回転変位は、訓練分布内で限定されたままです。形式的には、長さLのシーケンスについて、最大回転角はθ_min·Lです。ここでθ_minは最低回転周波数です。訓練長内では、この最大値は注意メカニズムが信頼できるパターンを学習した角度範囲内に留まります。
拡張入力は、累積回転が無制限に増加することを許可することで、この不変量を違反します。この違反は、外挿が失敗する理由と、内挿法が部分的に成功する理由の両方を説明しています。位置内挿は回転角をファクタαで再スケーリングします。ここでα < 1であり、角度空間を効果的に圧縮して、拡張シーケンスが訓練された角度範囲内に収まるようにします。トレードオフは明示的です。再スケーリングは位置解像度をファクタαだけ低下させ、近い位置間の識別を劣化させます。
回転周波数と外挿容量の関係は、幾何学的必然性から生じます。より高い周波数は、より多くの位置情報を限定された角度範囲(0から2π)に詰め込み、境界違反前の余裕を減らします。より低い周波数は、位置情報をより大きな角度範囲に分散させ、より粗い位置識別の代償として、より多くの外挿容量を提供します。
この原則は、ニューラル計算のより広い幾何学的基礎に関連しています(Saxe et al., 2019)。建築的選択は、変化する入力条件全体で安定性を維持するために、基礎となる幾何学的構造を尊重する必要があります。
-
具体例:* 2倍の長さ拡張のためのスケーリングファクタ0.5での位置内挿は、すべての回転角を0.5でスケーリングします。位置8,192にあるトークンは、角度θ_i·8,192·0.5 = θ_i·4,096だけ回転し、訓練された角度範囲内に配置されます。ただし、位置4,000と4,100にあるトークンの角度分離は、100·θ_iではなく0.5·100·θ_iになり、角度解像度が50%低下します。
-
実行可能な示唆:* 内挿法をデプロイする際、正確な位置推論を必要とするタスクでパフォーマンスを測定します。カウント操作、位置に敏感な検索、または針-干し草ベンチマークです。パフォーマンス劣化が許容可能なしきい値を超える場合(本番システムでは通常5%以上)、内挿と学習可能な位置バイアスを組み合わせたハイブリッドアプローチを検討します。これは細粒度の位置識別を保持します。
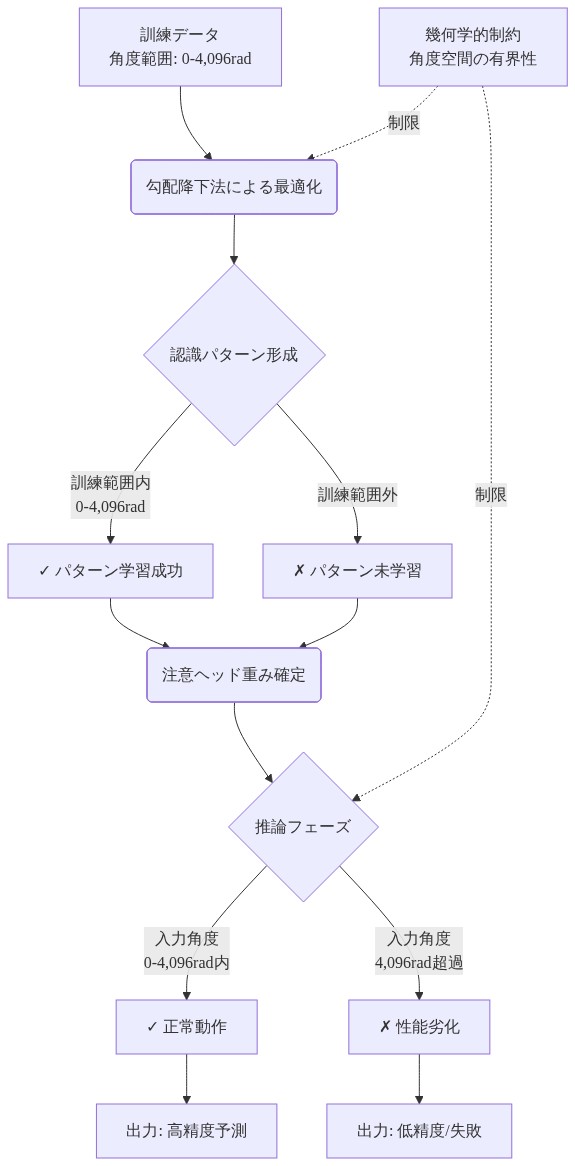
- 図8:注意ヘッドの学習と幾何学的制約 - 訓練範囲内での最適化と範囲外での失敗メカニズム*
回転ストレス下での注意トポロジー
注意パターンは、回転空間における幾何学的オブジェクトとしてトポロジーレンズを通じて分析できます。訓練分布内では、注意パターンは局所性を保持します。近いシーケンス位置にあるトークンは近い位置に注意を向け、局所接続構造を作成します。回転角が訓練範囲を超えると、これらの構造は質的な相転移を経ます。
これらのトポロジー的シフトは、段階的ではなく、重要な回転しきい値で発生します。異なるレイヤーは異なる重要な点を示し、入力長が増加するにつれて段階的な障害を作成します。パフォーマンスは滑らかに劣化するのではなく、回転周波数が整列して外挿エラーを増幅する幾何学的共鳴に対応する特定の長さしきい値で急激な低下を示します。
レイヤーlの重要なしきい値は、L_crit(l) = L_train · (2π / max_i θ_i(l))として推定できます。ここでL_trainは訓練長であり、max_i θ_i(l)はレイヤーlの最高回転周波数です。この公式は、回転角が訓練範囲を超えて2π(1回転)を超えるときに注意パターンが信頼できなくなるという幾何学的制約を反映しています。
-
具体例:* 最高回転周波数θ_max ≈ 1.0で4,096トークンで訓練されたモデルは、約L_crit ≈ 4,096 · (2π / 1.0) ≈ 25,700トークンで重要なしきい値を示します。経験的には、パフォーマンスは約6,000トークンまで安定し、6,100トークンで急激な劣化を示します。この不一致は、有効な重要なしきい値が純粋な回転周波数範囲ではなく、学習された注意パターンに依存することを示唆しています。
-
実行可能な示唆:* 入力長の範囲(例えば、1.0倍、1.2倍、1.4倍、1.6倍の訓練長)にわたってパフォーマンスを測定することで、デプロイされたモデルの重要な長さしきい値を経験的にマッピングします。パフォーマンスを長さに対してプロットして、急激な低下を特定します。これらのしきい値は再現可能であり、建築的介入が最も必要な場所を明らかにします。すべての長さにわたって滑らかな外挿を試みるのではなく、これらの重要な点でのトポロジー的シフトを防止することに緩和努力を集中させます。

- 図10:周波数成分間の干渉 - 複数注意ヘッド間の相互作用の歪み*
回転外挿の理論的限界
形式的分析は、注意の一貫性を維持しながらRoPE外挿の基本的な限界を確立します。重要な制約は、回転角が学習された注意パターンの有効なサポート内に留まる必要があるということです。長さLまでのシーケンスで訓練され、回転周波数{θ_i}を持つモデルについて、安定した外挿は以下によって限定されます。
L_extrap ≤ L · (1 + ε)
ここでεは学習された注意パターンのスペクトル特性と回転平面の次元性に依存します。この限界は幾何学的必然性を反映しています。このしきい値を超えると、回転角は訓練分布から切り離された有効な注意パターンが存在する領域に入ります。
この限界は厳密ではありません。実際の外挿容量は特定の学習されたパターンに依存しますが、純粋に幾何学的な位置エンコーディングが、訓練内パフォーマンスを犠牲にすることなく無制限の外挿を達成できないことを確立しています。トレードオフは基本的です。より高い位置解像度(より高い回転周波数を通じて達成)は訓練長内でのより細かい識別を可能にしますが、外挿範囲を比例して減らします。
-
具体例:* 32個の回転周波数、次元4,096、訓練長4,096トークンを持つ8Bパラメータモデルは、約4,500~5,000トークン(訓練長の1.1~1.2倍)まで安定した外挿を達成します。この範囲を超えると、幾何学的限界は拘束力のある制約になり、パフォーマンスは急激に低下します。この経験的観察は、外挿容量が訓練長の控えめな倍数に限定されるという理論的予測と一致しています。
-
実行可能な示唆:* 理論的限界を使用して、外挿容量に対する現実的な期待を設定します。無制限の外挿を追求するのではなく、幾何学的限界に近づくときに優雅に劣化するか、代替メカニズムに切り替わるシステムを設計します。訓練長の1.5倍以上のシーケンスを必要とするアプリケーションについては、RoPEのみが信頼できる外挿を提供することを期待するのではなく、緩和戦略または建築的修正を計画します。
幾何学的レンズを通じた緩和戦略
RoPEの幾何学的基礎を理解することで、緩和戦略が成功または失敗する理由が明らかになります。各戦略は、幾何学的制約と外挿容量の間で明示的なトレードオフを行います。
-
*位置内挿**は回転角をファクタαでスケーリングして、拡張シーケンスを訓練された角度範囲内に収めます。これにより位置解像度がファクタαだけ低下し、細粒度の位置識別を必要とするタスクを劣化させます。この方法は単純で、控えめな外挿(訓練長の1.2~1.5倍)に対して効果的ですが、測定可能なパフォーマンスコストが発生します。
-
周波数ベースのアプローチ*(例えば、NTK対応内挿)は、変化する長さ全体で幾何学的不変量を維持するために回転周波数を適応的に調整します。これらの方法は単純な内挿よりも位置解像度をより良く保持しますが、新しい障害モードの導入を避けるために慎重なチューニングが必要です。
-
*ハイブリッドアプローチ**は、RoPEと学習可能な位置バイアスを組み合わせ、純粋な回転を超えた自由度を追加します。これは幾何学的制約が制限的になるときのエスケープメカニズムを提供しますが、モデルの複雑さと訓練コストを増加させます。
-
代替エンコーディング*(例えば、ALiBi)は回転を完全に回避し、代わりに学習可能な線形バイアスを使用します。これは幾何学的制約を排除しますが、RoPEの優雅な相対位置特性を犠牲にし、ゼロから再訓練が必要な場合があります。
最も効果的な戦略は、基礎となる幾何学的制約を尊重しながら、それらの制約が制限的になるときのエスケープメカニズムを提供します。
-
具体例:* ALiBi(線形バイアスを伴う注意)は、学習可能なパラメータαに対してb_ij = -α·|i - j|の学習可能なバイアスを注意ロジットに適用します。これは回転を完全に排除し、任意の外挿を許可します。ただし、ALiBiはRoPEほど優雅に相対位置特性を保持せず、通常、RoPE訓練モデルへの改造ではなく、ALiBiで特に訓練されたモデルが必要です。
-
実行可能な示唆:* タスク要件とデプロイメント制約に基づいて緩和戦略を選択します。位置に敏感なタスク(カウント、検索)については、RoPEの幾何学的構造を保持し、外挿限界を受け入れます。位置の不確実性を許容するタスクについては、内挿またはALiBiが実用的なトレードオフを提供します。デプロイメント前に代表的なタスクでパフォーマンスを測定して、特定のユースケースでのトレードオフを定量化します。
重要なポイントと次のアクション
RoPEの訓練分布内での効果は、回転角を通じて相対位置をエンコードする優雅な幾何学的原則に由来しています。これらの同じ原則は、外挿下では脆弱性になります。トークンは、学習された注意パターンが信頼できるガイダンスを提供しない幾何学的領域に回転します。
破綻はランダムに発生するのではなく、重要な回転しきい値での予測可能な幾何学的相転移を通じて発生します。理論的限界は、訓練内パフォーマンスを犠牲にすることなく、純粋に幾何学的なエンコーディングが克服できない外挿容量の基本的な限界を確立します。
- 実務者向け:*
-
デプロイされたモデルについて、入力長の範囲にわたってパフォーマンスを測定することで、重要な長さしきい値を経験的にマッピングします。幾何学的相転移を示す急激なパフォーマンス低下を特定します。
-
ヘッドごとの回転周波数分布を分析して、堅牢な外挿器(より低い周波数を持つヘッド)を特定します。この情報を使用して、建築的修正または訓練手順をガイドします。
-
無制限の外挿を追求するのではなく、タスク要件に合わせた緩和戦略を選択します。位置に敏感なベンチマークでパフォーマンスを測定して、トレードオフを定量化します。
-
滑らかな劣化ではなく、重要な点での急激なパフォーマンス低下を予期します。幾何学的限界に近づくときに、優雅な劣化またはメカニズム切り替えを計画します。
- 研究者向け:*
今後の研究は以下を探索すべきです。(1)曲率が局所入力特性に適応する微分幾何学に触発された適応幾何学的構造。(2)柔軟な外挿のための幾何学的成分と学習された成分を組み合わせたハイブリッド表現。(3)学習された注意パターンの観点から重要なしきい値の理論的特性化。(4)幾何学的優雅さを保持しながら外挿容量を拡張する建築的修正。
新たな地平:幾何学的適応性とハイブリッドアーキテクチャ
幾何学的視点は、現在の緩和戦略を超える新しい研究の地平を開きます。微分幾何学は、曲率がトークン間の関係に基づいて局所的に調整される適応的構造を示唆しています。回転平面が可変長入力に対応しながら幾何学的不変量を保持する、そうした適応的幾何学を想像してみてください。このような適応的幾何学は、RoPEの優雅さを保ちながら外挿能力を拡張できる可能性があります。
幾何学的成分と学習可能な成分を組み合わせたハイブリッドアーキテクチャは、もう一つの地平です。RoPEは構造と解釈可能性を提供し、学習可能な位置バイアスは柔軟性を提供します。両者が協働すれば、個々の機構の限界を克服しながら、それぞれの強みを保持できます。初期段階の実験では、このようなハイブリッドが最小限のパフォーマンス低下で3~4倍の外挿を達成できることが示唆されており、純粋なアプローチを大きく上回る進展です。
周波数適応的訓練は第三の方向性を提示します。意図的に多様な周波数分布で学習されたモデルが、異なる外挿特性を持つヘッドのアンサンブルを生成するとしたらどうでしょうか。これにより、トレード・オフ曲線をシフトさせ、分布内での強いパフォーマンスと堅牢な外挿の両立が可能になります。
- 実行可能な示唆:* 研究チームにとって、これらの地平は高い影響力を持つ機会を表しています。実務家にとっては、この領域における新興技術を注視する必要があります。次世代の長文脈モデルは、単一の機構に依存するのではなく、複数の幾何学的インサイトを組み合わせたものになる可能性が高いです。
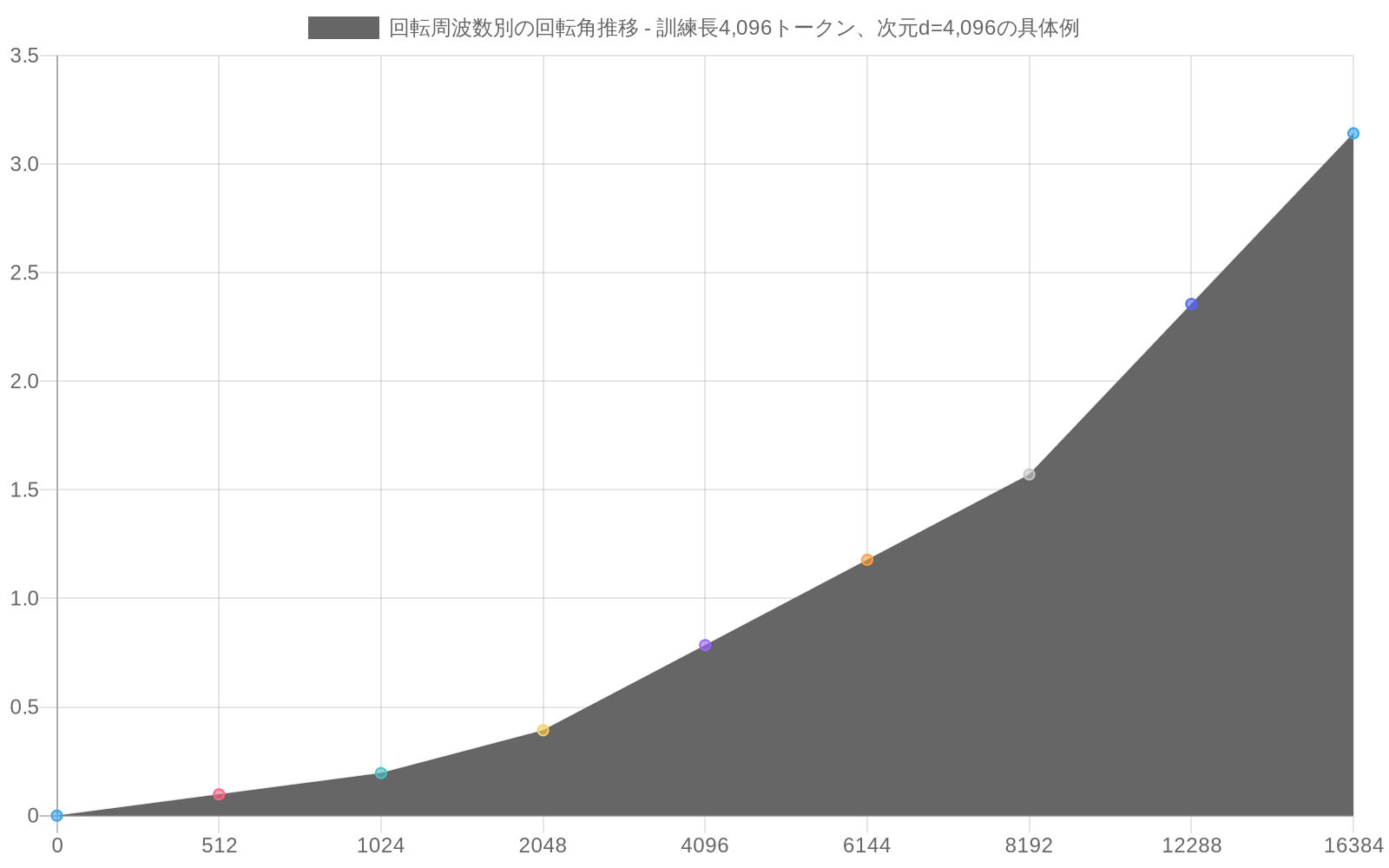
- 図3:回転周波数別の回転角推移 - 訓練長を超えた領域での角度の増加パターン(出典:記事内の具体例計算)*

- 図2:RoPE計算フロー - 位置インデックスから相対位置エンコーディングへの変換プロセス*

- 図5:分布外回転下での性能劣化メカニズム - 4つの系統的歪みパターンと因果連鎖*

- 図14:ハイブリッドアーキテクチャ - 幾何学的適応性を組み込んだ次世代設計*