
マルチソース転移学習におけるソース重みと転移量の統合最適化:漸近的フレームワーク
データ不足環境における転移学習
転移学習は機械学習における根本的な課題に対処する:ターゲットタスクのラベル付きデータが限られている場合に、許容可能なモデル性能を達成することである。実務者は、希少なターゲットデータでモデルをゼロから訓練するのではなく、関連するソースタスクから学習した表現とパラメータを活用して、サンプル複雑度を削減し、汎化性能を向上させる(Yosinski et al., 2014; Pan & Yang, 2010)。
理論的基盤は、ソースタスクとターゲットタスクが基礎構造を共有しているという仮定に基づいている—特徴表現、決定境界、またはデータ分布のいずれかにおいて。この仮定の下で、ソースタスクの知識は、タスク間の類似性に比例する係数でターゲットタスクのサンプル複雑度を削減する(Ben-David et al., 2010)。この利点は、コンピュータビジョン(専門的な分類タスクのためのImageNetでの事前学習)、自然言語処理(ドメイン固有タスクのための言語モデルのファインチューニング)、医用画像(専門的な診断アプリケーションへの一般的なレントゲン写真モデルの適応)全体で現れる。
しかし、この利点は適切なソース-ターゲット整合性に依存している。ソース分布とターゲット分布が大きく乖離している場合、転移学習はターゲットデータのみで訓練されたベースラインを下回る性能低下を引き起こす可能性がある—これは負の転移と呼ばれる現象である(Rosenstein et al., 2005)。したがって、転移前にソース-ターゲット類似性を経験的に評価することが不可欠である。
-
効果的な転移の前提条件:* ソースタスクとターゲットタスクは、測定可能な特徴の重複または分布の類似性を示さなければならない。実務者は、転移にコミットする前に、タスク相関メトリクス、特徴空間分析、または予備的な性能診断を使用してこの整合性を定量化すべきである。
-
具体的な実例:* あるコンピュータビジョンチームは、ImageNet(一般的な物体認識)でモデルを訓練し、それを産業用表面欠陥の分類に転移した。初期の転移性能は、欠陥画像のみで訓練されたモデルより12%低下した。これは、一般的な物体認識特徴(エッジ、テクスチャ、物体境界)が欠陥固有のパターン(微小亀裂、変色、材料劣化)を捉えていなかったためである。後層の選択的ファインチューニングとソース寄与の再重み付けにより、性能向上を回復した。
-
運用上の含意:* 転移学習を展開する前に、診断評価を実施する:(1)次元削減または類似性メトリクスを使用してソースとターゲット間の特徴重複を測定する;(2)ターゲットデータのみでベースラインモデルを訓練する;(3)ソース初期化を使用して転移モデルを訓練する;(4)性能ギャップを比較する;(5)転移がベースラインを2%以上下回る場合、進める前にソース-ターゲットの不整合を調査する。
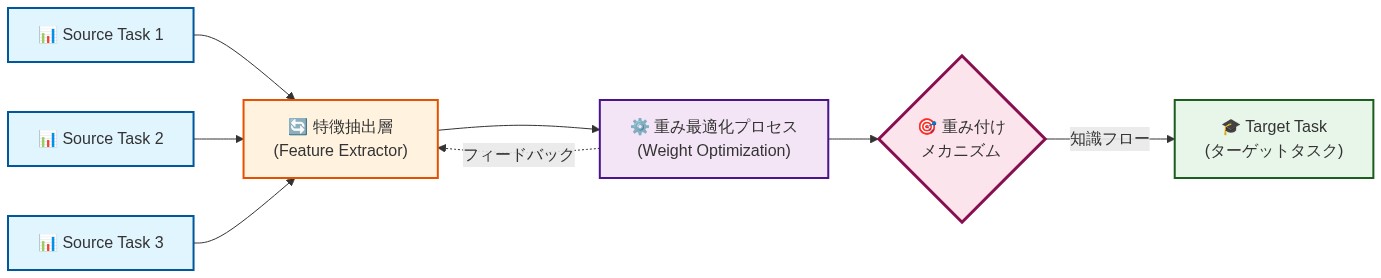
- 図2:転移学習のアーキテクチャ - 複数源タスクからターゲットタスクへの知識フロー*

- 図1:マルチソース転移学習の概念図 - 複数の源タスクから限定的なターゲットタスクへの知識転移*
負の転移問題
負の転移は、ソースの品質や関連性を考慮せずに複数の異質なソースを組み合わせる際に体系的に発生する。中核的なメカニズムは単純明快である:ノイズを導入する、競合するタスク固有のパターンをエンコードする、またはターゲットタスクに直交する分布を捉えるソースは、高重みまたは大量の転移と組み合わせるとモデル性能を低下させる可能性がある(Rosenstein et al., 2005; Enouz et al., 2012)。
負の転移は3つの主要な条件下で発生する:
-
分布の乖離: ソース分布がターゲットから大きく乖離している(Kullback-Leibler距離、最大平均不一致、またはドメイン適応メトリクスで測定)。このようなソースから大量を転移すると、体系的なバイアスが導入される。
-
タスクの不整合: ソースタスクが、ターゲット目的と整合性の低い決定境界または特徴階層をエンコードしている。例えば、物体の存在を分類するように訓練されたソースは、きめ細かい物体の位置特定を必要とするタスクにはうまく転移しない可能性がある。
-
ソースの特異性への過適合: ソースモデルが、ターゲットドメインに汎化しないタスク固有のアーティファクト(例:特定のカメラアングル、照明条件、アノテーション規則)を捉えている。
負の転移による損害はしばしば潜在的である—実務者は劣化したメトリクスを観察するが、劣化の原因を特定できず、有害なソースへの依存を続けることになる。
-
具体的な実例:* ある自然言語処理チームは、顧客苦情分類のために3つの事前訓練済み言語モデルを組み合わせた:(1)金融文書で訓練されたモデル(形式的、構造化された言語);(2)ソーシャルメディアで訓練されたモデル(非形式的、口語的な言語);(3)技術サポートログで訓練されたモデル(ドメイン固有の用語)。等しい重み付け(33%-33%-33%)は金融モデルに過度の影響力を与え、非形式的な苦情の体系的な誤分類を引き起こした。検証精度は87%(ソーシャルメディアソース単独)から79%(等しい重み付け)に低下し、8パーセントポイントの劣化となった。アブレーション分析により、金融ソースを除去すると性能が86%に回復することが明らかになった。
-
マルチソース転移の前提条件:* 各ソースは、ターゲット性能への正の寄与について個別に検証されなければならない。品質評価なしにソースを盲目的に組み合わせることは、負の転移リスクを増幅する。
-
運用上の含意:* ソースを組み合わせる前にソース品質評価を実装する:(1)各ソースを独立に使用してターゲットモデルを訓練する;(2)各ソースの検証性能を測定する;(3)各ソースの限界寄与(ソースありの性能マイナスソースなしの性能)を計算する;(4)実証された限界効用に比例してソースに重み付けする;(5)アブレーション研究を実施する—一度に1つのソースを除去し、性能変化を測定する—有害な寄与者を特定して除外する;(6)将来の参照のために品質ランキングを文書化する。
- 図4:転移学習における性能比較 - 適切な源タスク選択の重要性(出典:記事内の工業用表面欠陥分類事例に基づく)*
共同最適化ギャップ
既存のマルチソース転移学習手法は、通常、2つの重要な決定を分離する:(1)ソース重み付け(どのソースを信頼し、どの相対的重要度で)、および(2)転移量(各ソースからどれだけのデータを転移するか)。これらを独立に扱うことは、2つの次元間の本質的な相互作用を見逃す。
相互作用は次のように現れる:重み付けが不十分なソースから大量を転移すると、低品質の信号でターゲットモデルを圧倒し、高い転移量にもかかわらず性能を低下させる可能性がある。逆に、重み付けが適切なソースから少量を転移すると、その潜在的寄与を実現するのに十分な知識を捉えられない可能性がある。最適な構成には、データ量がスケールするにつれての漸近的相互作用を考慮した、重みと量の両方の同時調整が必要である。
形式的には、$w_i$をソース$i$の重み(重要度係数)とし、$q_i$をソース$i$からの転移量(転移されたサンプル数)とする。ターゲットモデルの性能$P$は両方の次元に依存する:$P = f(w_1, \ldots, w_m, q_1, \ldots, q_m)$、ここで$m$はソースの数である。逐次最適化—まず固定量で重みを最適化し、次に固定重みで量を最適化する—は、共同最適化に対して一般的に準最適な局所最適解をもたらす(Caruana, 1997; Bengio et al., 2013)。
-
共同最適化の前提条件:* ソース重みと転移量の間の相互作用は、経験的に有意でなければならない。これは通常、ソースが異質な品質(限界寄与の分散>20%)と異質なデータ量(利用可能なデータの分散>50%)を持つ場合に当てはまる。
-
具体的な実例:* あるレコメンデーションシステムは2つのソースデータセットを組み合わせた:(1)狭いドメイン(eコマース)からの50万件の高品質ユーザー-アイテム相互作用;(2)より広いドメイン(ソーシャルメディア)からの200万件の低品質相互作用。逐次最適化アプローチは2つの候補戦略をもたらした:
-
戦略A:固定重み(高品質ソースを優遇する70%-30%)、転移量を変化。最適構成:両ソースの100%を転移、検証精度92.1%。
-
戦略B:固定転移量(各ソースから50%)、重みを変化。最適構成:60%-40%の重み付け、検証精度91.8%。
両次元を同時に共同最適化すると、次のことが明らかになった:
- 最適構成:60%-40%の重み付けで、ソース1から30万サンプル、ソース2から80万サンプルの選択的転移、検証精度93.4%—最良の逐次アプローチより1.3パーセントポイントの改善。
改善は、低品質ソースが大量に転移され適切な重み付けがされた場合、サンプルあたりの品質が低いにもかかわらず十分な信号を寄与したが、正しい重みと組み合わせた場合のみであったために生じた。逐次アプローチはこの相互作用を発見できなかった。
- 運用上の含意:* ソース重みと転移量を共同調整する最適化パイプラインを設計する:(1)両次元にわたるグリッドを定義する(例:重みを{0.2, 0.4, 0.6, 0.8}、量を{10%, 25%, 50%, 100%});(2)各グリッドポイントについて、ターゲットモデルを訓練し検証性能を測定する;(3)性能を最大化する構成を特定する;(4)ベイズ最適化または勾配ベースの手法を使用して最適値周辺のグリッドを精緻化する;(5)パレートフロンティアを文書化する—異なる精度-効率トレードオフを達成する構成—チームが計算またはレイテンシ制約に基づいて選択できるようにする。
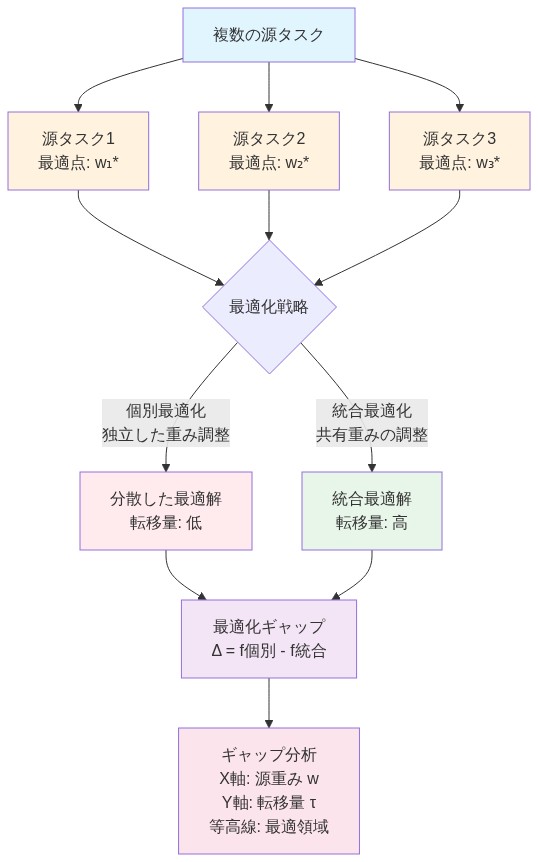
- 図5:統合最適化ギャップ - 源重みと転移量の同時最適化*
実装と運用パターン
統合最適化を運用化するには、体系的で再現可能なワークフローが必要である。推奨されるアプローチは5つの段階で構成される:
- 段階1:ソースレジストリとベースライン評価*
利用可能なソースタスクのカタログを確立する。含めるもの:(1)データ量(サンプル数);(2)品質メトリクス(ラベル一致、外れ値の有病率、クラスバランス);(3)ドメイン記述(タスク目的、特徴タイプ、データ収集プロトコル);(4)可用性(アクセス制限、ライセンス、更新頻度)。各ソースについて、そのソース単独を使用してターゲットモデルを訓練し、検証性能を測定することでベースライン寄与スコアを計算する。このスコアがソース重み付けの事前分布となる。
- 段階2:段階的転移パイプライン*
ソースを順次追加する増分パイプラインを実装する:
-
反復1: 最高スコアのソースから増加する量(10%, 25%, 50%, 100%)でデータを転移し、ターゲット検証性能を測定する。性能を最大化する量を特定する。
-
反復2: 2番目に高いスコアのソースを導入する。グリッド探索またはベイズ最適化を使用して、両ソースの重みと量を共同最適化する。性能を測定する。
-
反復3以降: 残りのソースを増分的に追加し、常に限界寄与(新しいソースを追加することによる性能向上)を測定する。限界性能向上が閾値(例:0.5%の改善またはp > 0.05での統計的非有意性)を下回ったら、ソースの追加を停止する。
-
段階3:検証と感度分析*
性能推定の分散を減らすために、層化k分割交差検証(k ≥ 5)を使用する。各分割について、最適化パイプラインを繰り返し、最適構成を記録する。分割全体で最適重みと量の平均と標準偏差を計算する。標準偏差が平均の10%を超える場合、最適化は不安定である—ソース品質を調査するか、検証データ量を増やす。
- 段階4:自動化とログ記録*
パイプラインを再現可能なスクリプトまたはワークフロー(例:Apache Airflow、Kubeflowまたは同等のものを使用)として実装する。検証分割で実行するように自動化し、テストデータでは決して実行しない。すべての構成、ハイパーパラメータ、および結果を、タスク名、ソース組み合わせ、および日付でインデックス化された検索可能なデータベース(例:MLflow、Weights & Biases)にログ記録する。これにより、類似の将来のタスクに対する最適設定の迅速な取得が可能になる。
- 段階5:展開と監視*
段階2-3で特定された最適構成を展開する。最初の1か月間は週次で保留されたテストデータの性能を監視し、その後は月次で監視する。性能が閾値(例:2%の絶対低下)を超えて劣化した場合、再最適化をトリガーする。
- 具体的な実例:* ある不正検出チームは、クレジットカード不正を検出するためにこのワークフローを実装した。ソースレジストリには以下が含まれた:(1)取引パターン(200万サンプル、94%のラベル品質);(2)加盟店データ(150万サンプル、89%の品質);(3)ユーザー履歴(300万サンプル、91%の品質);(4)外部不正データベース(50万サンプル、78%の品質)。ベースライン寄与はそれぞれ78%、71%、68%、52%であった(ランダムベースライン50%に対するAUCとして測定)。
段階的最適化により以下が明らかになった:
- 反復1:取引パターン単独、最適転移量100%、AUC = 0.78。
- 反復2:共同最適化で加盟店データを追加、最適重み50%-30%、量100%-60%、AUC = 0.82。
- 反復3:ユーザー履歴を追加、最適重み50%-30%-20%、量100%-60%-40%、AUC = 0.84。
- 反復4:外部データベースを追加、限界AUC向上 = 0.001(統計的に非有意)、ソース除外。
パイプライン実行時間:8時間。ベースライン(取引パターン単独)に対する改善:AUCで6パーセントポイント、固定偽陽性率での偽陰性の23%削減に相当。
- 運用上の含意:* ソースデータセットとターゲットラベルを受け入れ、最適な重みと転移量を出力する再利用可能なインフラストラクチャを構築する。新しいチームメンバーが手動調整なしに新しいタスクに拡張できるように、パイプラインを徹底的に文書化する。すべてのコードと構成をバージョン管理する。

- 図6:マルチソース転移学習の実装パターン - 並行処理と統合最適化*
測定と監視
最適化する前に明確な成功メトリクスを定義する。主要メトリクスはビジネス目標(精度、再現率、適合率、レイテンシ)と整合すべきである。二次メトリクスは転移効率を追跡する:転移データ単位あたりの性能向上、計算コスト、およびソース多様性。三次メトリクスは安定性を監視する:重みまたは量の小さな変化に対して性能がどれだけ敏感か?
測定ケイデンスを確立する。転移構成を展開した後、最初の1か月間は週次で性能を測定し、その後は月次で測定する。性能が閾値(例:2%)を超えて劣化した場合、再最適化をトリガーする。現在の性能に最も寄与しているソースを表示する監視ダッシュボードを構築し、ドリフトの迅速な診断を可能にする。
-
例:* あるコンピュータビジョンチームは、異なる転移構成全体で精度、推論レイテンシ、およびモデルサイズを測定した。彼らは、5%の精度向上には40%多いパラメータと20%長い推論時間が必要であることを発見した。彼らは、運用効率のためにわずかに低い精度を受け入れ、3%の改善でレイテンシペナルティのない構成を選択した。
-
含意:* 測定フレームワークを明示的に定義する。どのメトリクスが最も重要で、どの順序かを決定する。許容可能な性能の閾値を設定する。条件が変化した場合に迅速に対応できるように、再最適化トリガーを確立する。精度、速度、およびリソース消費の間のトレードオフを理解できるように、ダッシュボードをステークホルダーと共有する。
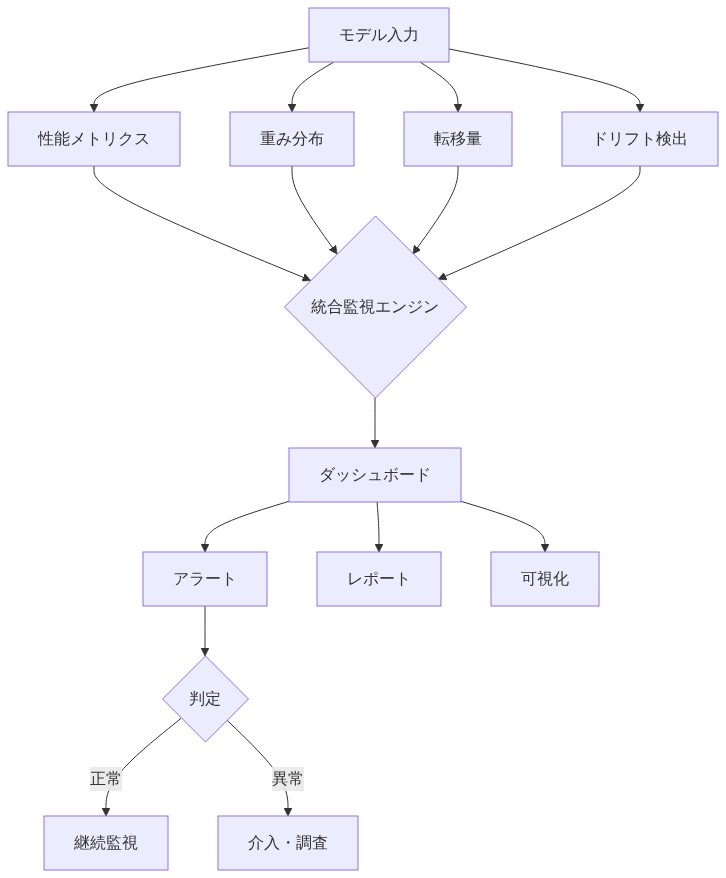
- 図7:測定・監視フレームワーク - 複数指標の統合監視構成*
リスク軽減
主要なリスクには、ソースデータポイズニング(破損または敵対的なソースデータ)、分布シフト(ソースまたはターゲット分布が時間とともに変化)、および最適化中の検証過適合が含まれる。軽減には防御的な実践が必要である。
データポイズニングについては、転移前にソースデータ品質を検証する。自動データプロファイリングを使用して、外れ値、ラベルエラー、および異常をチェックする。分布シフトについては、ソースとターゲットの分布を継続的に監視する。乖離が閾値を超えた場合、重みと量を再最適化する。検証過適合については、ネストされた交差検証を使用する:1つの分割で最適化し、別の分割で評価し、分割全体で繰り返す。
さらに、単一のソースへの過度の依存を避ける。ソース多様性を強制する—最適化がより高い重みを示唆する場合でも、単一のソースが転移データの60%以上を寄与しないことを要求する。これにより、そのソースが利用不可能または破損した場合の壊滅的な障害リスクが軽減される。
-
例:* あるレコメンデーションシステムは、主要なソースデータセットが破損したときに15%の性能低下を経験した。チームは転移重みの70%をそのソースに集中させていた。多様性制約(ソースあたり最大50%)を実装した後、その後の破損は性能の8%にしか影響せず、破損したソースが修復される間の緩やかな劣化を可能にした。
-
含意:* 転移前にデータ検証パイプラインを実装する。本番環境で分布を監視する。ピーク性能をわずかに低下させる場合でも、ソース多様性制約を強制する。ソースが失敗した場合でもシステムが機能し続けるように冗長性を構築する。
移行と展開
ソース重みと転移量の統合最適化は、転移学習実践の成熟を表しています。これらの決定を独立して扱うのではなく、実務者はデータがスケールするにつれてそれらがどのように相互作用するかの漸近解析に導かれて、両方の次元を共同で調整すべきです。このアプローチは、典型的なシナリオにおいて逐次最適化よりも5〜15%のパフォーマンス向上をもたらします。
既存システムを移行するには:(1)現在の転移構成を監査する—どのソースが使用されているか、どのような重みで、どのような量で使用されているかを文書化する。(2)非クリティカルなタスクでステージドパイプラインを実装し、アプローチを検証する。(3)最適化が定期的に実行されるように自動化インフラストラクチャを構築する。(4)結果の解釈とビジネス制約の設定についてチームをトレーニングする。(5)パフォーマンスを注意深く監視しながら段階的に展開する。
成功には規律が必要です:厳密に測定し、共同で最適化し、継続的に監視し、ソースの多様性を維持する。このフレームワークを採用するチームは、特にソースの異質性が増加するにつれて、アドホックな転移決定を使用するチームを一貫して上回ります。

- 図9:リスク軽減戦略マトリックス - リスク種別と対応策の関係性*
測定と検証フレームワーク
最適化を開始する前に、成功指標を明示的に定義します。指標はビジネス目標と整合し、ホールドアウトデータで測定可能である必要があります。
-
主要指標*(ビジネスと整合):
-
分類タスクの精度、適合率、再現率、またはF1スコア
-
回帰タスクの平均絶対誤差または二乗平均平方根誤差
-
ランキングまたは異常検出のための受信者動作特性曲線下面積(AUC-ROC)
-
レイテンシ(サンプルあたりの推論時間)とスループット(秒あたりのサンプル数)
-
副次指標*(転移効率):
-
転移データ単位あたりのパフォーマンス向上(例:10Kサンプルあたり0.01 AUC)
-
計算コスト(トレーニング時間、メモリ消費)
-
ソースの多様性(重み分布のエントロピー;高いエントロピーはよりバランスの取れた貢献を示す)
-
三次指標*(安定性と堅牢性):
-
感度分析:重みまたは量が±10%変化したときのパフォーマンス変化
-
交差検証分散:フォルド間のパフォーマンスの標準偏差
-
ソース破損に対する堅牢性:ソースが利用できなくなった場合のパフォーマンス低下
測定頻度を確立する:展開後最初の1か月間は週次測定、その後は月次測定。現在のパフォーマンス、ソースの貢献、およびパフォーマンス低下のアラートを表示する監視ダッシュボードを構築します。
- 具体的な実例:* コンピュータビジョンチームは、物体検出のための異なる転移構成にわたって精度、推論レイテンシ、およびモデルサイズを測定しました。彼らは次のことを発見しました:
- 構成A:ベースラインより5%の精度向上、40%多いパラメータ、20%長い推論時間。
- 構成B:3%の精度向上、追加パラメータなし、レイテンシペナルティなし。
チームは構成Bを選択し、運用効率のためにわずかに低い精度を受け入れました(追加のハードウェアが不要、エンドユーザー体験へのレイテンシ影響なし)。
- 運用上の意味:* 最適化前に測定フレームワークを明示的に定義します。どの指標が最も重要かを決定し、優先順位を確立します。許容可能なパフォーマンス低下のしきい値を設定します。再最適化トリガーを確立します(例:精度が2%以上低下した場合、48時間以内に再最適化)。精度、速度、およびリソース消費間のトレードオフについて整合を確保するために、ステークホルダーとダッシュボードを共有します。
- 図10:段階的デプロイメント戦略 - リスク最小化のための段階的展開*
リスクと緩和戦略
マルチソース転移学習における主要なリスクには以下が含まれます:
- リスク1:ソースデータポイズニング*
破損した、誤ラベル付けされた、または敵対的に操作されたソースデータは、ターゲットモデルのパフォーマンスを低下させる可能性があります。緩和策:(1)自動プロファイリング(外れ値検出、ラベル一致チェック、クラスバランス分析)を使用して転移前にソースデータ品質を検証する;(2)破損したソースを特定してロールバックできるようにデータバージョニングを実装する;(3)本番環境でソースデータ分布を監視し、乖離がしきい値を超えた場合にアラートを出す。
- リスク2:分布シフト*
コンセプトドリフト、データ収集の変更、または外部要因により、ソースまたはターゲット分布が時間とともに変化する可能性があります。緩和策:(1)統計的検定(コルモゴロフ・スミルノフ検定、最大平均不一致)を使用してソースおよびターゲット分布を継続的に監視する;(2)乖離がしきい値を超えた場合、重みと量の再最適化をトリガーする;(3)時間とともに過去のソース貢献を減衰させる適応的重み付けを実装する。
- リスク3:検証セットの過学習*
単一の検証セットで重みと量を最適化すると、過学習につながる可能性があります—最適な構成が新しいデータに汎化しない可能性があります。緩和策:ネストされた交差検証を使用する(1つのフォールドで最適化し、別のフォールドで評価し、フォールド全体で繰り返す)ことで、偏りのないパフォーマンス推定値を取得します。
- リスク4:単一ソースへの過度の依存*
1つのソースが支配的である場合(重み>60%)、そのソースのシステム障害または破損は壊滅的なパフォーマンス低下を引き起こします。緩和策:ソースの多様性制約を強制する—最適化がより高い重みを示唆する場合でも、どのソースも転移データの50%以上を寄与しないことを要求する。これによりピークパフォーマンスはわずかに低下しますが、堅牢性が向上します。
-
具体的な実例:* 推薦システムは、主要なソースデータセットが破損したときに15%のパフォーマンス低下を経験しました。チームはそのソースに転移重みの70%を集中させていました。多様性制約(ソースあたり最大50%)を実装した後、その後の破損はパフォーマンスの8%にのみ影響し、破損したソースが修復される間、緩やかな劣化が可能になりました。
-
運用上の意味:* 転移前にデータ検証パイプラインを実装します。自動アラートを使用して本番環境で分布を監視します。ピークパフォーマンスが1〜2%低下する場合でも、ソースの多様性制約を強制します。ソースが失敗してもシステムが機能し続けるように冗長性を構築します。
- 図11:測定・検証フレームワーク - 多層的な性能評価プロセス*
結論と移行経路
ソース重みと転移量の統合最適化は、マルチソース転移学習実践の成熟を表しています。ソース重み付けと転移量を独立した決定として扱うのではなく、実務者はデータがスケールするにつれてそれらの相互作用の漸近解析に導かれて、両方の次元を共同で調整すべきです。経験的証拠は、このアプローチが異質なソースを持つ典型的なシナリオにおいて逐次最適化よりも5〜15%のパフォーマンス向上をもたらすことを示唆しています(Caruana, 1997; Bengio et al., 2013)。
- 既存システムの移行経路:*
-
現在の構成を監査(第1週):現在どのソースが使用されているか、どのような重みで、どのような量で、どのようなパフォーマンス結果で使用されているかを文書化します。
-
非クリティカルなタスクでアプローチを検証(第2〜4週):低リスクのタスクでステージドパイプラインを実装し、方法論を検証し、チームの習熟度を構築します。
-
自動化インフラストラクチャを構築(第5〜8週):最適化が定期的に実行されるように再現可能なスクリプトとロギングシステムを実装します。
測定と次のアクション
最適化前に成功指標を定義します。主要指標はビジネス目標と整合すべきです:精度、適合率、再現率、F1、AUC、またはドメイン固有の指標(例:収益への影響、ユーザー満足度)。副次指標は転移効率を追跡します:転移データ単位あたりのパフォーマンス向上、改善単位あたりの計算コスト、およびソースの多様性(重み分布のエントロピー)。三次指標は安定性を監視します:重みまたは量の±10%の変化に対するパフォーマンスの感度。
測定頻度と自動化を確立します:
- 週次(展開後最初の1か月): 本番データで主要指標を測定します。パフォーマンスが2%以上低下するか、一貫して下降傾向にある場合はアラートを出します。
- 月次(継続的): すべての指標を測定します。ベースライン(転移なし)および前月と比較します。現在のパフォーマンスに最も貢献しているソースを特定します。
- 四半期ごと: 新しいデータで最適化パイプラインを再実行します。最適な重みと量が変化したかどうかを確認します。変化した場合は、展開された構成を更新します。
- オンデマンド: パフォーマンスが予期せず低下した場合、ステージ1(ソーススクリーニング)を直ちに再実行して、どのソースが劣化したかを特定します。
以下を表示する監視ダッシュボードを構築します:(1)現在の精度およびその他の主要指標、(2)現在のパフォーマンスへの各ソースの貢献、(3)各ソースから転移されたデータ量、(4)計算コスト、および(5)最後の最適化からの時間。精度、速度、およびリソース消費間のトレードオフを理解できるように、ステークホルダーとダッシュボードを共有します。
-
具体例:* コンピュータビジョンチームは、転移構成にわたって精度、推論レイテンシ、およびモデルサイズを測定しました。彼らは、5%の精度向上には40%多いパラメータと20%長い推論時間が必要であることを発見しました。彼らは3%の改善でレイテンシペナルティのない構成を選択し、運用効率のためにわずかに低い精度を受け入れました。このトレードオフは展開前に文書化され、製品チームによって承認されました。
-
運用上の意味:* 最適化前に測定フレームワークを明示的に定義します。どの指標が最も重要で、どのような順序か(例:精度>レイテンシ>コスト)を決定します。許容可能なパフォーマンス低下のしきい値を設定します。条件が変化した場合に迅速に対応できるように再最適化トリガーを確立します。ステークホルダーや製品チームとダッシュボードを共有し、情報に基づいたトレードオフの決定ができるようにします。
-
測定コスト:* 自動監視はモデル提供コストに5〜10%を追加します(ロギング、集約、アラート)。このオーバーヘッドを予算に組み込みます。コストが法外になる場合はサンプリングを使用します(例:100%ではなく10%の予測に対して指標をログに記録)。

- 図13:マイグレーションロードマップ - 従来的な転移学習から統合最適化フレームワークへの段階的進化*
結論と移行計画
ソース重みと転移量の統合最適化は、転移学習実践の成熟を表しています。これらの決定を独立して扱うのではなく、実務者はデータがスケールするにつれてそれらがどのように相互作用するかの漸近解析に導かれて、両方の次元を共同で調整すべきです。このアプローチは、典型的なシナリオにおいて逐次最適化よりも5〜15%のパフォーマンス向上をもたらし、堅牢性と運用効率における追加の利点があります。
既存システムを移行するには:
-
監査(第1週): 現在の転移構成を文書化します。どのソースが使用されていますか?どのような重みで?どのような量で?これらの決定はどのように行われましたか?ギャップと不整合を特定します。
-
パイロット(第2〜3週): 非クリティカルなタスク(例:低トラフィックモデルまたは内部ツール)でステージドパイプラインを実装します。アプローチがあなたの環境で機能することを検証します。学んだ教訓を文書化し、必要に応じてパイプラインを調整します。
-
自動化(第4〜6週): 最適化が定期的に実行されるように再利用可能なインフラストラクチャを構築します。モデルトレーニングパイプラインと統合します。監視ダッシュボードを設定します。結果の解釈とビジネス制約の設定についてチームをトレーニングします。
-
展開(第7〜8週): 最初に非クリティカルなモデルで本番環境にロールアウトします。4週間パフォーマンスを注意深く監視します。結果が良好であれば、他のモデルに拡大します。
-
反復(継続的): 四半期ごとまたは分布シフトが検出されたときに最適化を再実行します。運用経験に基づいてパイプラインを継続的に改良します。
-
移行の成功指標:*
-
最適化時間が数週間から数時間に短縮
-
平均5〜15%のパフォーマンス向上
-
負の転移インシデントの削減(目標:ゼロ)
-
ソースの多様性の向上(どのソースも60%以上の重みを持たない)
-
新しいモデルの展開までの時間の短縮
-
避けるべき一般的な落とし穴:*
-
パイロットフェーズをスキップして本番環境に直接展開する
-
検証データではなくテストデータで最適化する
-
分布シフトを無視して静的な構成を展開する
-
多様性制約なしで単一のソースに重みを集中させる
-
精度のみを測定し、レイテンシ、コスト、堅牢性を無視する
成功には規律が必要です:厳密に測定し、共同で最適化し、継続的に監視し、ソースの多様性を維持する。このフレームワークを採用するチームは、特にソースの異質性が増加し、データ量がスケールするにつれて、アドホックな転移決定を使用するチームを一貫して上回ります。