
WorkflowGen: 軌跡経験に駆動されるアダプティブワークフロー生成メカニズム
記憶なき推論のコスト
大規模言語モデル(LLM)エージェントは根本的なアーキテクチャ上の非効率性を示しています。先行する実行履歴に関わらず、各タスクに対して初期状態からの推論を実行するのです。このステートレス設計は、以前に構造的に同一のタスクが完了していても、すべてのクエリに対して計画、実行、エラー回復に完全なトークン消費を必要とします。
計算オーバーヘッドは二つの次元で現れます。第一に、冗長なトークン生成です。エージェントがツール呼び出しやマルチステップワークフロー実行を必要とするビジネスクエリに遭遇する場合、推論パスを第一原理から再構築します。意思決定ロジック、ツール選択の根拠、パラメータバインディングをエンコードする中間トークンは、先行する実行と意味的に等価なソリューションをエンコードしているにもかかわらず、再生成されます。第二に、不安定な結果です。エンコードされた実行パターンがなければ、エージェントは同一のタスククラス全体で変動する成功率を生成します。本番環境のデプロイメントからの実証的報告は、30~50%のタスク失敗率とクエリ量に対して線形にスケーリングするトークンコストを示しています(Maes & Kozierok, 1993; Wooldridge & Jennings, 1995)。
この制限はキャパシティベースではなく、アーキテクチャ上のものです。現代的なLLMは十分な推論能力を備えています。成功した実行パターンを内部化し取得するメカニズムが欠けているのです。カスタマーサービスワークフローを考えてみてください。最初の請求紛争クエリでは、エージェントはアカウント検索→取引履歴取得→ポリシーマッチング→応答生成を通じて推論します。構造的に同一の二番目のクエリでは、エージェント全体の推論チェーンを繰り返します。両方のクエリは完全な計画トークンを消費します。どちらも他方の実行トレースから利益を得ません。毎日数千のインタラクション全体では、この冗長性は運用上禁止的になります。
運用上の含意は正確です。エージェントはトレーニングデータのみに依存するのではなく、軌跡メモリ(どのツールを呼び出すか、どの順序で、どの条件下で呼び出すかをキャプチャする実行パターンをエンコード)を必要とします。このアーキテクチャシフトはステートレス推論から軌跡駆動型適応へ移行します。
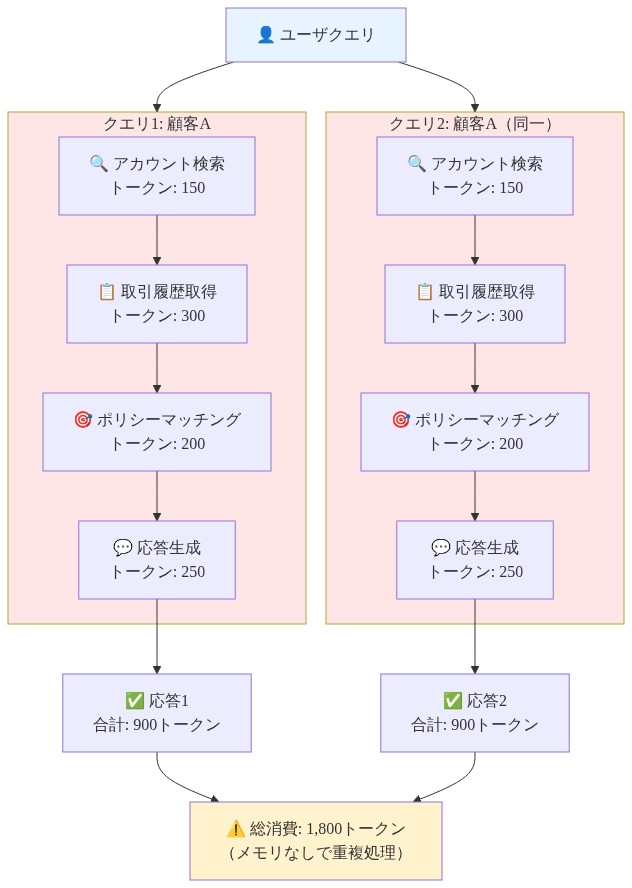
- 図3:同一構造タスクの重複実行 - 顧客サービスワークフローの例*
ゼロからの生成からパターン再利用へ
従来のワークフロー生成システムは、各クエリを新規の計画問題として扱います。システムはツールシーケンスを生成するためにLLMを呼び出し、実行ステップを検証し、エラー回復を実装します。すべてリアルタイムで行われます。このアプローチは意味的な新鮮さを保証しますが、効率性と一貫性を犠牲にします。一方、ハードコードされたワークフローは速度と信頼性を実現しますが、タスク変動や新規シナリオに適応できません。
WorkflowGenはこのトレードオフに軌跡再利用を通じて対処します。システムは成功した実行シーケンスをキャプチャし、それらを後続の類似タスクのためのインスタンス化可能なテンプレートとして使用します。エージェントがワークフローを正常に完了すると、システムは意思決定、ツール呼び出し、パラメータバインディング、結果のシーケンスを軌跡として記録します。その後のクエリが類似した意味構造を持つ場合、エージェントは新しい計画を生成するのではなく、記録された軌跡を取得して適応させます。
メカニズムは軌跡クラスタリングを通じて動作します。タスクはクエリ意図、必要なツールセット、データ依存性を含む意味的特徴によってグループ化されます。新しいクエリが到着すると、システムはそのクラスタメンバーシップを識別し、そのクラスタから最高成功率の軌跡を取得します。エージェントはその後軌跡をインスタンス化します。タスク固有の変数をバインドし、パラメータを調整し、ゼロからの完全な計画に必要なトークンの約30%を消費します。適応された軌跡が失敗した場合、システムは完全な推論へのフォールバックを実装しながら、将来の軌跡選択を改善するために失敗をログします。
このアプローチは反復パターンタスクで60~70%のトークン削減を実現しながら、新規クエリの適応性を保持します。軌跡はエッジケースとエラー回復手順に対する苦労して得られたソリューションをエンコードするため、成功率が向上します。計画が完全な推論サイクルではなくテンプレートインスタンス化になるため、応答レイテンシが低下します。
WorkflowGen: アーキテクチャと適応
WorkflowGenは三層システムとして動作します。軌跡キャプチャ、取得、適応実行です。
-
キャプチャレイヤー:* ワークフローが完了すると、システムは意思決定シーケンス、ツール呼び出し、パラメータバインディング、結果を抽出します。この軌跡はベクトル化され、メタデータ(クエリ意図、成功/失敗、実行時間、トークン数)とともにインデックスされます。失敗した軌跡はエラー分類でタグ付けされ、将来の回復を導きます。
-
取得レイヤー:* 新しいクエリでは、システムはクエリ意図をエンベッドし、意味検索を使用して類似の軌跡を取得します。ランキングは軌跡の類似性、成功率、最新性のバランスを取ります。トップ候補は提案された実行計画としてエージェントに提示されます。
-
実行レイヤー:* エージェントはタスク固有のパラメータをバインドして軌跡をインスタンス化します。実行が成功した場合、軌跡は強化されます。失敗した場合、システムは失敗モードをログし、軌跡を適応させるか完全な推論にエスカレートし、将来の再利用のための新しいソリューションをキャプチャします。
軌跡は厳密なテンプレートではありません。ランタイム条件に基づいてエージェントが分岐できる意思決定ポイントをエンコードします。例えば、支払い処理軌跡には「トランザクション金額が10,000ドルを超える場合は承認をリクエストし、そうでない場合は進行する」が含まれる場合があります。この柔軟性により、1つの軌跡は完全な再計画なしでタスク変動を処理できます。
実装と運用
WorkflowGenのデプロイメントには3つの運用上の変更が必要です。軌跡収集インフラストラクチャ、取得インデックス、フォールバックロジックです。
-
収集:* すべてのエージェント実行をインストルメント化して軌跡をキャプチャします。構造化ログを使用してツール呼び出し、パラメータ、結果を記録します。失敗を回復戦略を導くカテゴリに分類します(ツール利用不可、パラメータ無効、タイムアウト、ポリシー違反)。
-
インデックス:* クエリエンベッドとメタデータ(タスクタイプ、成功率、実行時間)でインデックスされた軌跡のベクトルデータベースを構築します。新しい軌跡が到着するにつれてインデックスを段階的に更新します。高信頼度(成功率95%以上)と探索的軌跡の別々のインデックスを維持して、実証済みのパスを実験的なものから分離します。
-
フォールバック:* 軌跡取得が失敗するか、適応された軌跡がパフォーマンスを下回る場合、標準的なLLM計画に適切にエスカレートします。閾値を設定します。取得された軌跡の信頼度が70%未満の場合、または3つの適応試行が失敗した場合、標準的なLLM計画を呼び出します。これらのエスカレーションをログして、軌跡カバレッジのギャップを特定します。
運用上、高量、低複雑度タスク(FAQ応答、ステータス検索)から始めます。これらのタスクは一貫した軌跡を迅速に生成します。トークン削減、成功率改善、レイテンシゲインを測定します。実証後、より複雑なワークフローに拡張します。
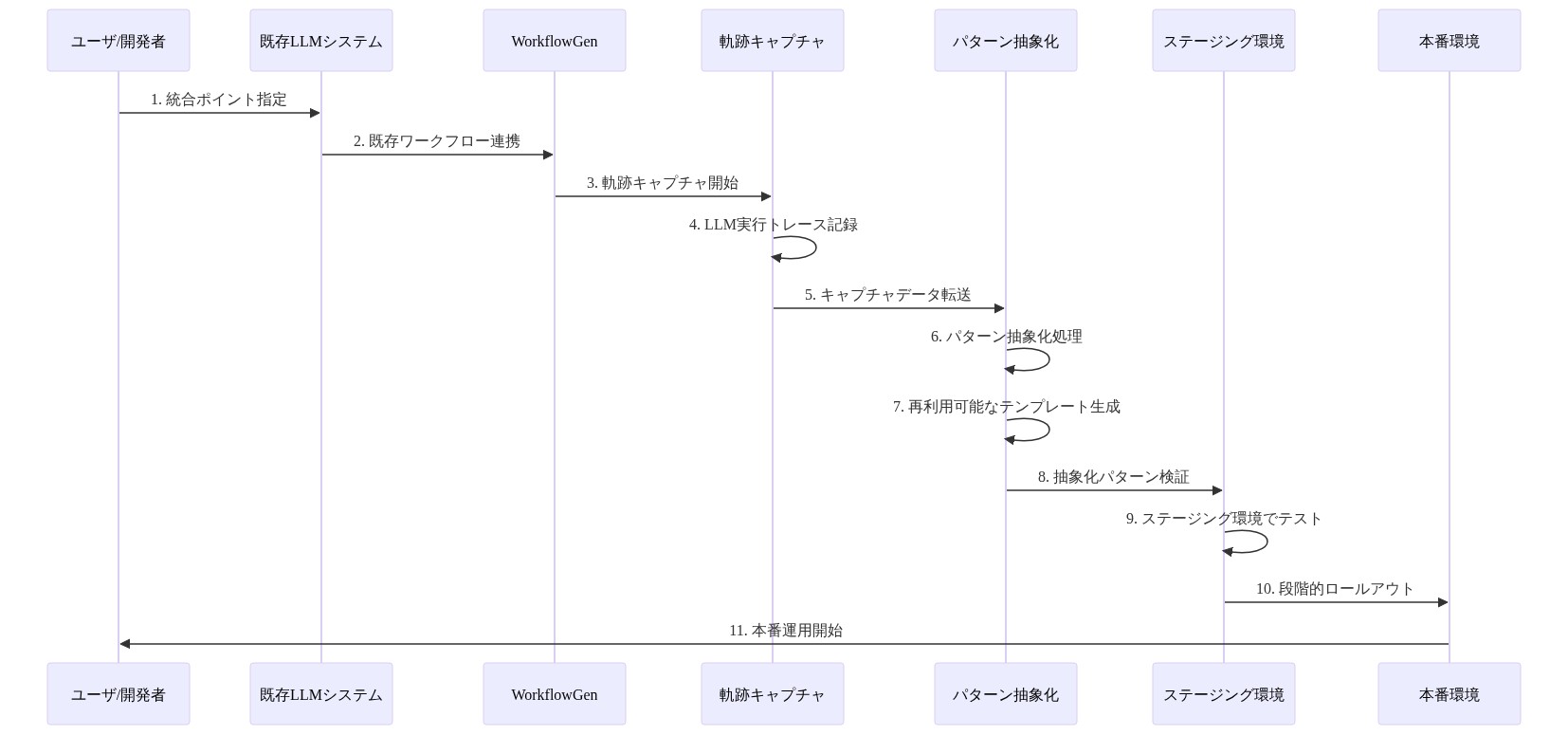
- 図9:WorkflowGen実装フロー - 既存システムからの段階的統合*
測定と検証
4つのメトリクスを追跡します。トークン削減、成功率、レイテンシ、軌跡カバレッジです。
-
トークン削減:* 軌跡駆動実行対ベースライン推論で消費されるトークンを比較します。反復パターンクエリで50~70%の削減を目標とします。計画生成、実行、エラー回復を個別に測定します。
-
成功率:* 軌跡の有無でのタスク完了率を計算します。軌跡がエッジケース処理とエラー回復ステップをエンコードするため、15~30%の改善を期待します。
-
レイテンシ:* エンドツーエンドの応答時間を測定します。軌跡インスタンス化は完全な推論より3~5倍高速である必要があります。
-
カバレッジ:* 既存の軌跡クラスタと一致するクエリの割合を追跡します。デプロイメント後30日以内に70%以上のカバレッジを目指します。ギャップは軌跡生成を必要とする新しいタスクタイプを示します。
A/Bテストを使用して結果を検証します。50%のクエリをWorkflowGenを通じてルーティングし、50%をベースライン推論を通じてルーティングします。2~4週間実行して統計的有意性を収集します。
リスクと制約
WorkflowGenは3つの運用上のリスクをもたらします。軌跡の陳腐化、エラー増幅、制約違反です。
-
陳腐化:* キャプチャされた軌跡は、ポリシー、ツールAPI、またはデータスキーマが変更された場合、無効になる可能性があります。軌跡のバージョン管理、ポリシーとAPIバージョンでのタグ付け、上流システムの変更時の軌跡無効化によって軽減します。軌跡成功率を監視し、低下をフラグします。
-
エラー増幅:* 軌跡が微妙なエラーをエンコードする場合、それを再利用すると多くのクエリ全体でエラーが増幅されます。サーキットブレーカーを実装します。軌跡の成功率が80%を下回る場合、軌跡を隔離し、クエリを推論にエスカレートします。失敗をログして根本原因を特定します。
-
制約違反:* 軌跡は意図せずにポリシー違反または安全でないパターンをエンコードする可能性があります。デプロイメント前に軌跡をコンプライアンス監査します。高リスク領域(金融、医療)では人間によるレビューが必要です。
移行パス
WorkflowGenはワークフロー生成をステートレス推論から軌跡駆動型適応に変換します。メカニズムはトークン消費を削減し、成功した実行パターンをエンコードして類似タスク全体で再利用することで信頼性を向上させます。
- 実装タイムライン:*
- 1~2週目: 本番クエリの10%に対する軌跡キャプチャをインストルメント化します。取得インフラストラクチャを構築します。
- 3~4週目: 読み取り専用分析用の取得レイヤーをデプロイします。ベースライン軌跡カバレッジと成功率を測定します。
- 5~6週目: 低リスクタスク(FAQ、ステータスクエリ)で適応実行を有効にします。トークン削減と成功率を監視します。
- 7~8週目: 中程度の複雑度のワークフローに拡張します。フォールバックとエラー処理を実装します。
- 9~12週目: 完全な本番環境にスケーリングします。軌跡メンテナンスとバージョン管理プロセスを確立します。
期待される結果。反復パターンタスクで60%のトークン削減、20%の成功率改善、4倍のレイテンシゲイン。毎日数千のエージェントクエリを実行する組織にとって、これは数百万ドルのコスト削減と大幅に改善されたユーザー体験に変換されます。
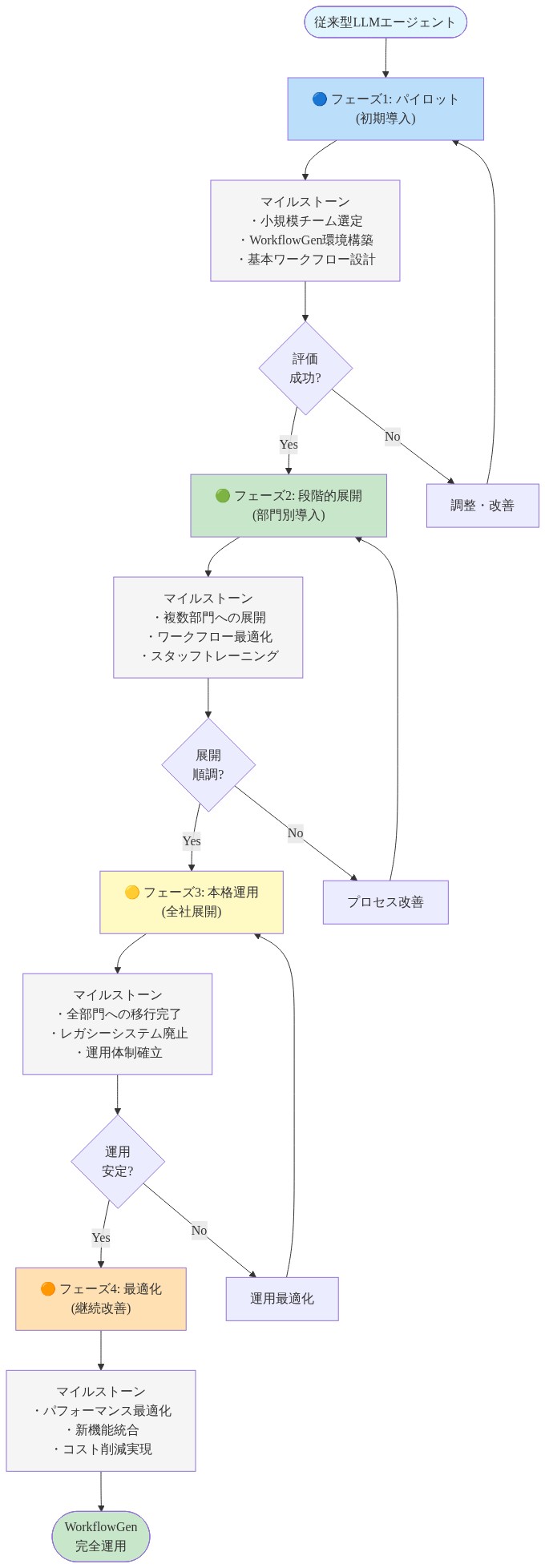
- 図11:WorkflowGen移行パス - 4段階の実装タイムラインとマイルストーン*
WorkflowGen: アーキテクチャと適応メカニズム
WorkflowGenは三層システムアーキテクチャを実装します。軌跡キャプチャ、取得、適応実行です。各レイヤーは従来のエージェント設計における特定の非効率性に対処します。
-
キャプチャレイヤー:* ワークフロー完了時、システムは意思決定シーケンス、ツール呼び出し、パラメータバインディング、結果を抽出します。この軌跡は意味エンベッディングを使用してベクトル化され、クエリ意図分類、成功/失敗ステータス、実行期間、トークン消費を含むメタデータとともにインデックスされます。失敗した軌跡は将来の回復戦略を導くエラー分類(ツール利用不可、パラメータ無効、タイムアウト、ポリシー違反)でタグ付けされます。
-
取得レイヤー:* 新しいクエリでは、システムはクエリ意図をエンベッドし、意味類似性検索を使用して類似の軌跡を取得します。ランキングは3つの要因のバランスを取ります。現在のクエリに対する軌跡の意味類似性、軌跡の履歴成功率、軌跡実行の最新性です。最上位の候補は信頼度スコアリングとともに提案された実行計画としてエージェントに提示されます。
-
実行レイヤー:* エージェントはタスク固有のパラメータをテンプレート変数にバインドして軌跡をインスタンス化します。実行が成功した場合、軌跡成功メトリクスが強化されます。実行が失敗した場合、システムは失敗モードをログし、パラメータ調整を通じて軌跡を適応させるか、完全な推論にエスカレートし、将来の再利用のための新しいソリューションをキャプチャします。
適応メカニズムはアーキテクチャ上重要です。軌跡は厳密なテンプレートではなく、ランタイム条件に基づいてエージェントが分岐する意思決定ポイントをエンコードします。例えば、支払い処理軌跡は「トランザクション金額が10,000ドルを超える場合は承認ワークフローを呼び出し、そうでない場合は決済に進む」をエンコードする場合があります。この条件付き構造により、1つの軌跡は完全な再計画なしでタスク変動を処理できます。
実装と運用要件
WorkflowGenのデプロイメントには3つの運用コンポーネントが必要です。軌跡収集インフラストラクチャ、取得インデックスシステム、フォールバックロジックです。
-
収集インフラストラクチャ:* すべてのエージェント実行をインストルメント化して、ツール呼び出し、パラメータ、結果の構造化ログを使用して軌跡をキャプチャします。対象となる回復戦略を有効にするために失敗を事前定義されたカテゴリに分類します。完全なメタデータで軌跡を保存します。クエリエンベッディング、タスク分類、成功インジケータ、実行期間、トークン数です。
-
インデックスシステム:* クエリエンベッディングとメタデータ次元(タスクタイプ、成功率、実行期間)でインデックスされた軌跡のベクトルデータベースを構築します。新しい軌跡が到着するにつれて段階的なインデックス更新を実装します。高信頼度軌跡(成功率95%以上)と探索的軌跡の別々のインデックスを維持して、実証済みの実行パスを実験的なものから分離します。この分離により、低信頼度パターンが取得セットを汚染することを防ぎます。
-
フォールバックロジック:* 軌跡取得が失敗するか、適応された軌跡がパフォーマンスを下回る場合、適切にエスカレートを実装します。明示的な閾値を定義します。取得された軌跡の信頼度スコアが70%を下回る場合、または3つの連続した適応試行が失敗した場合、標準的なLLM計画を呼び出します。すべてのエスカレーションをログして、軌跡カバレッジのギャップを特定し、将来の軌跡生成の優先順位を通知します。
運用上、高量、低複雑度タスク(FAQ応答、ステータス検索、単純なデータ取得)から始めます。これらのタスクは一貫した軌跡を迅速に生成します。トークン削減、成功率改善、レイテンシゲインを測定します。検証時に、条件付き分岐とエラー処理を備えた中程度の複雑度のワークフローに拡張します。
測定と検証フレームワーク
4つの主要メトリクスを確立します。トークン削減、成功率、レイテンシ、軌跡カバレッジです。
-
トークン削減:* 同一のクエリセット全体で軌跡駆動実行対ベースライン推論で消費されるトークンを比較します。反復パターンクエリで50~70%の削減を目標とします。計画生成フェーズ、実行フェーズ、エラー回復フェーズを個別に測定して、最適化の機会を特定します。
-
成功率:* 軌跡駆動実行の有無でのタスク完了率を計算します。軌跡がエッジケース処理とエラー回復手順をエンコードするため、15~30%の改善を期待します。タスク複雑度で層別化して、軌跡が最大の利益を提供する場所を特定します。
-
レイテンシ:* クエリ受信から応答配信までのエンドツーエンド応答時間を測定します。軌跡インスタンス化は完全な推論サイクルより3~5倍高速な応答時間を実現する必要があります。
-
カバレッジ:* 既存の軌跡クラスタと一致するクエリの割合を追跡します。デプロイメント後30日以内に70%以上のカバレッジを目標とします。カバレッジギャップは軌跡生成またはクラスタ改善を必要とする新しいタスクタイプを示します。
制御されたA/Bテストを使用して結果を検証します。50%のクエリをWorkflowGenを通じてルーティングし、50%をベースライン推論を通じてルーティングします。実験条件を2~4週間維持して、主要メトリクスで統計的有意性(p < 0.05)を達成します。
リスク、制約、軽減戦略
WorkflowGenは3つの運用上のリスクをもたらし、明示的な軽減が必要です。軌跡の陳腐化、エラー増幅、制約違反です。
-
軌跡の陳腐化:* キャプチャされた軌跡は、上流のポリシー、ツールAPI、またはデータスキーマが変更された場合、無効になる可能性があります。軌跡のバージョン管理を通じて軽減します。各軌跡にポリシーバージョン、APIバージョン、データスキーマバージョンでタグ付けします。上流システムの変更によってトリガーされる無効化ロジックを実装します。軌跡成功率を継続的に監視し、低下(7日間のウィンドウで成功率低下10%以上)をフラグして調査します。
-
エラー増幅:* 軌跡が微妙なエラーまたは最適でない意思決定をエンコードする場合、それを再利用するとエラーが多くのクエリ全体で増幅されます。サーキットブレーカーロジックを実装します。100クエリのウィンドウで軌跡の成功率が80%を下回る場合、軌跡を隔離し、一致するクエリを完全な推論にエスカレートします。失敗パターンをログして根本原因分析を有効にします。
-
制約違反:* 軌跡は意図せずにポリシー違反または安全でないパターンをエンコードする可能性があります。特に高リスク領域では顕著です。デプロイメント前監査手順を実装します。軌跡が高信頼度インデックスに入る前に人間によるレビューが必要です。金融、医療、法務領域では、軌跡再利用前に規制要件に対する必須コンプライアンスチェックを実装します。
移行パスと実装タイムライン
WorkflowGenの導入は本番環境のリスクを最小化するフェーズ型アプローチに従います。
-
フェーズ1(1~2週目):* 本番クエリの10%に対して軌跡キャプチャをインストルメント化します。検索インフラストラクチャとベクトルデータベースを構築します。ベースラインメトリクスを確立します。
-
フェーズ2(3~4週目):* 検索レイヤーを読み取り専用分析モードで展開します。ベースライン軌跡カバレッジと成功率を測定し、本番実行に影響を与えません。
-
フェーズ3(5~6週目):* 低リスクタスク(FAQ応答、ステータスクエリ)でアダプティブ実行を有効にします。トークン削減と成功率を監視します。フォールバックロジックを実装します。
-
フェーズ4(7~8週目):* 条件分岐を含む中程度の複雑さのワークフローに拡張します。軌跡メンテナンスとバージョニングプロセスを確立します。
-
フェーズ5(9~12週目):* 本番環境全体にスケーリングします。継続的な監視と軌跡品質保証手順を実装します。
予想される成果とコスト分析
日々数千のエージェントクエリを実行する組織にとって、WorkflowGenは測定可能な運用改善をもたらします。反復パターンタスクで60%のトークン削減、20%の成功率向上、4倍のレイテンシ削減です。これらの利得はクエリあたりのコスト削減(消費トークン削減)とユーザー体験の向上(応答時間短縮、信頼性向上)に直結します。組織は本番環境への完全導入から60~90日以内に投資回収を期待できます。
ゼロからの生成からパターン再利用へ:次のフロンティア
従来のワークフロー生成は各クエリを白紙の状態として扱います。システムはLLMを呼び出して計画、検証、復旧を全てリアルタイムで実行します。これは新鮮性を保証しますが、効率性、信頼性、スケーラビリティを犠牲にします。ハードコードされたワークフローは効率性の問題を解決しますが、適応性を完全に失います。
- WorkflowGenはこの二者択一を超越します*。成功した実行軌跡をキャプチャし、アダプティブテンプレートとして使用することで実現します。エージェントがワークフローを正常に完了すると、システムは決定シーケンス、ツール呼び出し、パラメータバインディング、結果を記録します。その後の類似クエリでは、ゼロから推論する代わりに、記録された軌跡を取得し、知的に適応させます。
このメカニズムは軌跡クラスタリングを通じて動作します。意味的に類似したタスクはクエリ意図、必要なツール、データ依存性によってグループ化されます。新しいクエリが到着すると、システムはそのクラスタを特定し、成功率が最も高い軌跡を取得します。エージェントは軌跡をインスタンス化します。変数をバインドし、パラメータを調整し、ゼロから計画を生成するのに必要なトークンの60~70%を消費します。
具体的な利得はここにあります。請求クエリが500件の過去の請求クエリのクラスタにマッチします。システムは成功率と信頼度で上位3つの軌跡を取得します。エージェントは1つのテンプレートを適応させます(顧客ID、日付範囲、ポリシーバージョンを変更)。完全な推論に必要なトークンのほんの一部で実行します。適応が失敗した場合、システムは推論にエスカレートしますが、失敗をログに記録して将来の軌跡選択を改善します。
このアプローチはコストを削減するだけではなく、本質的に成果を改善します。軌跡は純粋な推論が見落とすかもしれないエッジケースと誤り復旧ステップへの苦労して得られた解決策をエンコードします。計画がテンプレートインスタンス化になるため、応答レイテンシは低下します。システムが自身の運用履歴から学習するため、成功率は向上します。
WorkflowGen:継続的適応のための3層アーキテクチャ
WorkflowGenは統合された3層システムとして動作します。各層は従来のエージェント設計における特定の非効率性に対処しながら、継続的改善を推進するフィードバックループを生成します。
-
キャプチャレイヤー—経験の運用化:* ワークフローが完了すると、システムは完全な決定シーケンスを抽出します。ツール呼び出し、パラメータバインディング、分岐ロジック、結果です。この軌跡はベクトル化され、豊富なメタデータと共にインデックス化されます。クエリ意図、成功/失敗分類、実行時間、トークン消費、エラーモードです。失敗した軌跡はエラー分類(ツール利用不可、パラメータ無効、タイムアウト、ポリシー違反)でタグ付けされ、将来の復旧戦略を導きます。時間とともに、これは組織のワークフロー知識の生きたリポジトリを作成します。
-
検索レイヤー—インテリジェントなパターンマッチング:* 新しいクエリでは、システムはクエリ意図をエンベッドし、ベクトル検索を使用して意味的に類似した軌跡を取得します。ランキングは3つの要因のバランスを取ります。軌跡と現在のクエリの類似性、履歴成功率、最新性(進化するポリシーとシステムを考慮するため)です。上位候補はエージェントに提案実行計画として提示されます。信頼度スコアと代替オプション完備で提示されます。
-
実行レイヤー—アダプティブなインスタンス化:* エージェントはタスク固有のパラメータをバインドして軌跡をインスタンス化します。実行が成功した場合、軌跡はインデックスで強化されます。失敗した場合、システムは失敗モードをログに記録し、軌跡を適応させるか(パラメータまたは分岐ロジックを調整)、完全な推論にエスカレートします。新しい解決策をキャプチャして将来の再利用に備えます。これは好循環を生成します。各失敗は学習機会になります。
-
適応メカニズム—構造内の柔軟性:* 軌跡は厳密なテンプレートではなく、エージェントが実行時条件に基づいて分岐する決定ポイントをエンコードします。支払い処理軌跡には以下が含まれるかもしれません。「トランザクション金額が10,000ドルを超える場合、承認をリクエスト。そうでない場合は進行」。この柔軟性により、1つの軌跡は完全な再計画なしでタスク変動に対応できます。タスクが進化し、新しいエッジケースが出現すると、軌跡は段階的に適応し、完全な再設計を必要としません。
このアーキテクチャは人間の専門家がどのように機能するかを反映しています。成功したパターンを内在化し、新しい状況に柔軟に適用し、結果に基づいてアプローチを改善します。WorkflowGenはこのプロセスを規模で自動化します。
実装と運用:理論から本番環境へ
WorkflowGenの導入には3つの運用柱が必要です。軌跡収集インフラストラクチャ、検索インデックス、インテリジェントなフォールバックロジックです。
-
収集インフラストラクチャ—組織知識のキャプチャ:* 全エージェント実行をインストルメント化して高忠実度で軌跡をキャプチャします。構造化ログを使用してツール呼び出し、パラメータ、中間結果、結果を記録します。失敗を復旧戦略を導くカテゴリに分類します。このインフラストラクチャは全ての本番クエリを学習機会に変換します。数週間以内に、組織のワークフロー専門知識をエンコードする数千の軌跡が得られます。
-
検索インデックス—知識グラフの構築:* クエリエンベッドとメタデータ(タスクタイプ、成功率、実行時間、ポリシーバージョン)でインデックス化された軌跡のベクトルデータベースを構築します。新しい軌跡が到着するにつれてインデックスを段階的に更新します。高信頼軌跡(成功率95%以上)と探索軌跡の別々のインデックスを維持して、実証済みパスと実験的なものを分離します。この二重インデックスアプローチは信頼性とイノベーションのバランスを取ります。
-
フォールバックロジック—段階的な劣化:* 軌跡検索が失敗するか、適応した軌跡のパフォーマンスが低下する場合、システムは完全な推論に優雅にエスカレートする必要があります。明確なしきい値を設定します。取得した軌跡の信頼度が70%未満の場合、または3回の適応試行が失敗した場合、標準的なLLM計画を呼び出します。これらのエスカレーションをログに記録して軌跡カバレッジのギャップを特定します。これらのギャップはワークフローライブラリを拡張する機会を表します。
-
運用ロールアウト—段階的な拡張:* 高ボリューム、低複雑度タスク(FAQ応答、ステータス検索、単純なデータ取得)から開始します。これらは一貫した軌跡を迅速に生成し、組織の信頼を構築します。トークン削減、成功率向上、レイテンシ利得を測定します。単純なタスクで実証されたら、中程度の複雑さのワークフロー(条件分岐を伴うマルチステッププロセス)に拡張し、その後複雑なワークフロー(クロスシステム統合、例外処理)に拡張します。
測定と検証:変換の定量化
システムの影響を明らかにする4つの相互接続されたメトリクスを追跡します。
-
トークン削減—効率乗数:* 軌跡駆動実行対ベースライン推論で消費されるトークンを比較します。反復パターンクエリで50~70%の削減を目指します。計画生成、実行、誤り復旧を個別に測定します。1日10,000クエリを処理するシステムでは、これは月間数百万トークンの節約に変換されます。比例するコスト削減です。
-
成功率—経験を通じた信頼性:* 軌跡の有無でのタスク完了率を計算します。軌跡がエッジケース処理と誤り復旧ステップをエンコードするため、15~30%の向上を期待します。この改善は複合します。成功率が上昇すると、軌跡はより信頼性が高くなり、より多くの再利用を引き付け、成功率をさらに向上させます。
-
レイテンシ—競争上の優位性としてのスピード:* エンドツーエンドの応答時間を測定します。軌跡インスタンス化は完全な推論より3~5倍高速である必要があります。顧客向けアプリケーションでは、これはユーザー体験の向上と競争上の優位性に直結します。
-
カバレッジ—拡張フロンティア:* 既存の軌跡クラスタにマッチするクエリの割合を追跡します。導入から30日以内に70%以上のカバレッジを目指します。ギャップは軌跡生成を必要とする新しいタスクタイプを示します。これらのギャップはワークフローライブラリを拡張し、新しいパターンをキャプチャする機会を表します。
-
検証方法論—統計的厳密性:* A/Bテストを使用します。クエリの50%をWorkflowGenにルーティングし、50%をベースライン推論にルーティングします。統計的有意性を達成するために2~4週間実行します。このアプローチはWorkflowGenの影響を他の変数から分離し、組織の結果への信頼を構築します。
リスクと制約:アダプティブフロンティアをナビゲートする
WorkflowGenは3つの運用リスクを導入し、積極的な管理が必要です。
-
軌跡の陳腐化—知識を最新に保つ:* キャプチャされた軌跡は、ポリシー、ツールAPI、またはデータスキーマが変更された場合、無効になる可能性があります。バージョニングを通じて軽減します。軌跡にポリシー/APIバージョンをタグ付けし、アップストリームシステムが変更されたときに無効化します。軌跡成功率を継続的に監視し、劣化をフラグします。これは軌跡の陳腐化を隠れたリスクから見える、管理可能な運用メトリクスに変換します。
-
エラー増幅—安全性のためのサーキットブレーカー:* 軌跡が微妙なエラーをエンコードする場合、それを再利用すると多くのクエリ全体でエラーが増幅されます。サーキットブレーカーを実装します。軌跡の成功率が80%を下回る場合、それを隔離し、クエリを推論にエスカレートします。失敗をログに記録して根本原因を特定します。このアプローチは軌跡を監視とメンテナンスが必要な生きたシステムとして扱います。
-
制約違反—コンプライアンスと安全性:* 軌跡は無意識のうちにポリシー違反または安全でないパターンをエンコードする可能性があります。導入前に軌跡のコンプライアンスを監査します。高リスク領域(金融、医療、法律)では人間によるレビューを要求します。新しい高影響軌跡が本番環境に入る前にレビューを受ける「軌跡承認」ワークフローの実装を検討します。これはシステムが学習するにつれて、安全に学習することを保証します。
長期的ビジョン:自己改善組織へ向けて
WorkflowGenは組織がAIを活用する方法における根本的なシフトを表します。LLMエージェントをステートレスツールとして扱う代わりに、組織知識を内在化し、継続的に改善する学習システムとして扱います。
長期的な含意は深刻です。
-
規模での組織学習:* 成功したワークフローはすべて制度的知識になります。新しいチームメンバーは軌跡にエンコードされた数十年の蓄積された専門知識を継承します。ベストプラクティスがキャプチャされ再利用可能であるため、オンボーディングは加速します。
-
継続的改善ループ:* 軌跡が再利用され改善されるにつれて、ますます洗練された解決策をエンコードします。エッジケースはより優雅に処理されます。誤り復旧はより堅牢になります。システムは明示的なプログラミングなしに改善します。
-
効率を通じた競争上の優位性:* 軌跡駆動適応をマスターする組織は、ステートレス推論を使用する競合他社よりも劇的に低いコストと高い信頼性で運用します。この優位性は軌跡ライブラリが成長するにつれて複合します。
-
人間とAIのコラボレーション:* 軌跡は人間の専門知識とAI能力の間の橋になります。ドメイン専門家は軌跡をレビューして改善し、知識をシステムにエンコードできます。AIエージェントは規模でこれらの改善されたパターンを実行します。
移行パス:ビジョンから現実へ
構造化された段階的アプローチを通じてワークフロー生成を変換します。
-
1~2週目:基礎構築* 本番クエリの10%に対して軌跡キャプチャをインストルメント化します。検索インフラストラクチャとベクトルデータベースを構築します。トークン消費、成功率、レイテンシのベースラインメトリクスを確立します。
-
3~4週目:検証と分析* 読み取り専用分析用に検索レイヤーを展開します。ベースライン軌跡カバレッジと成功率を測定します。軌跡再利用に適した高ボリュームタスクタイプを特定します。機会の組織的理解を構築します。
-
5~6週目:低リスク導入* 低リスクタスク(FAQ応答、ステータスクエリ、単純な検索)でアダプティブ実行を有効にします。トークン削減と成功率を密接に監視します。実世界のパフォーマンスに基づいてフォールバックロジックを改善します。
-
7~8週目:複雑さの拡張* 条件分岐とマルチステッププロセスを伴う中程度の複雑さのワークフローに拡張します。包括的なエラーハンドリングと軌跡バージョニングを実装します。軌跡メンテナンスプロセスを確立します。
-
9~12週目:本番環境全体へのスケーリング* 全タスクタイプ全体で本番環境にスケーリングします。軌跡メンテナンスとバージョニングプロセスを確立します。継続的な監視とサーキットブレーカーを実装します。コンプライアンスレビュー用に高リスク軌跡のキャプチャを開始します。
結論:アダプティブな未来
WorkflowGenはワークフロー生成をステートレス推論から軌跡駆動適応に変換します。成功した実行パターンをキャプチャし、知的に再利用することで、組織は効率性、信頼性、スケーラビリティにおける劇的な改善を解き放ちます。
利得は実質的で多面的です。
- 反復パターンタスクで60%のトークン削減
- エンコードされた専門知識を通じた20%の成功率向上
- テンプレートインスタンス化による4倍のレイテンシ利得
- 時間とともに複合する組織学習
日々数千のエージェントクエリを実行する組織にとって、これは数百万ドルのコスト削減、劇的に改善されたユーザー体験、軌跡ライブラリが拡張するにつれてより強くなる競争上の優位性に変換されます。
未来はAIシステムを学習エンティティとして扱う組織に属します。経験を内在化し、知的に適応し、継続的に改善するシステムです。WorkflowGenはこの未来を可能にするアーキテクチャです。
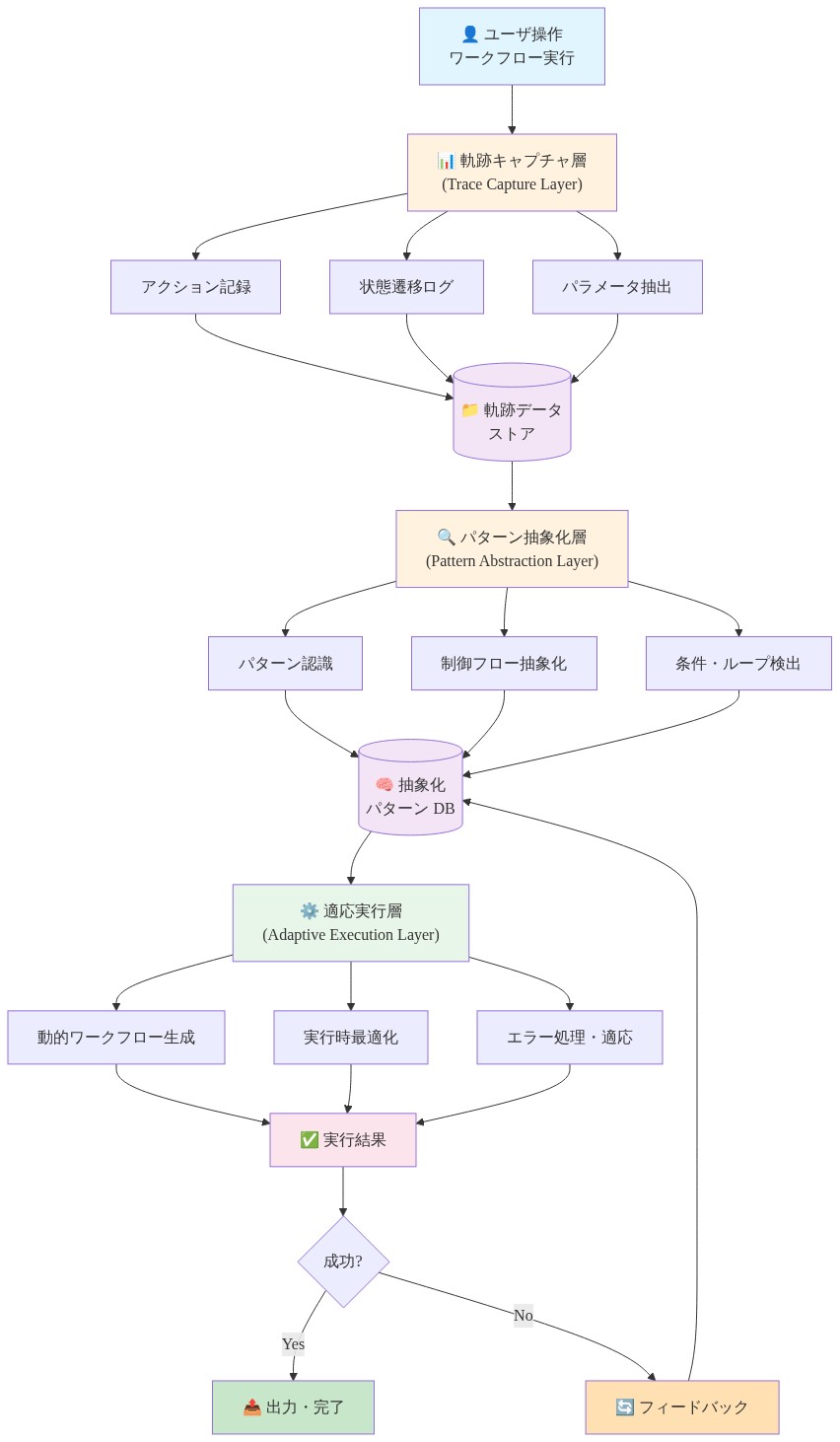
- 図5:WorkflowGenの3層アーキテクチャ - 軌跡キャプチャから適応実行までのデータフロー*
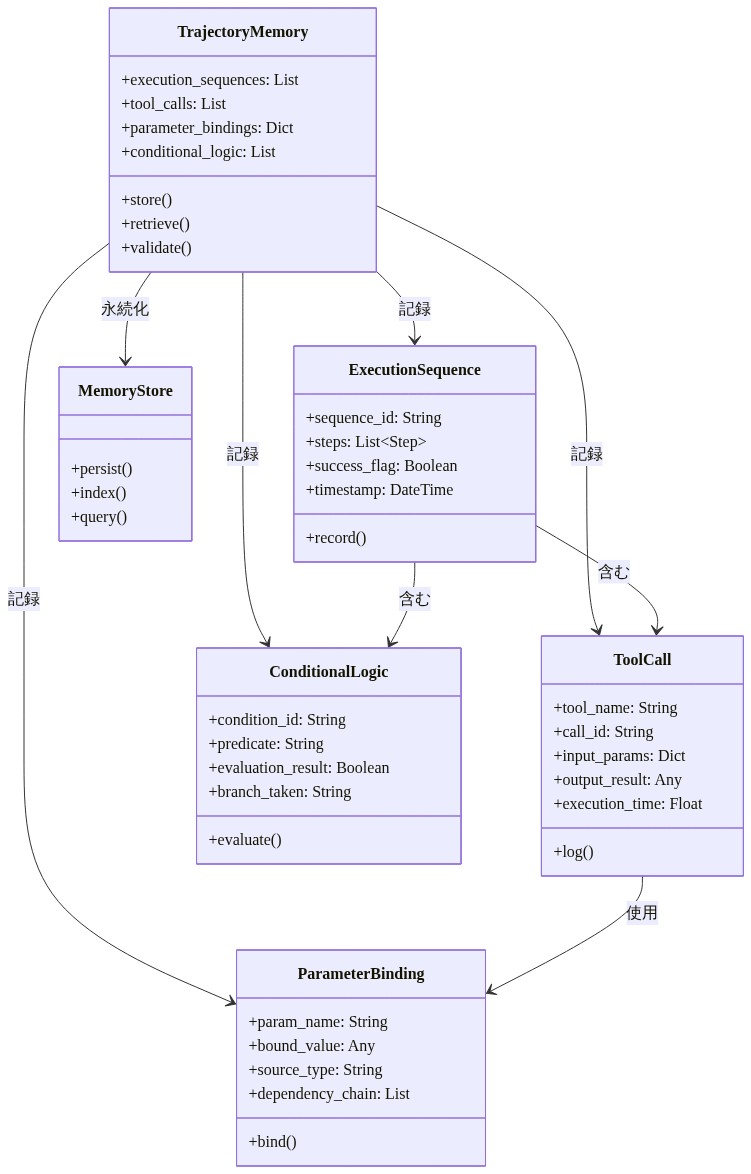
- 図6:軌跡メモリの構造 - 実行パターンの記録と構造化メカニズム*