
フラットな最小値は幻想なのか
フラットネスのパラドックス:損失ランドスケープの幾何学が測定アーティファクトになるとき
-
主張:* フラットな最小値がより良い汎化と相関するという広く信じられている見方は、モデル自体の根本的な性質ではなく、パラメータ化の選択によって生じた幻想に基づいているかもしれません。
-
根拠:* ニューラルネットワークの損失ランドスケープは座標に依存しません。損失関数 $\mathcal{L}(\theta)$ はパラメータ化 $\theta$ に明示的に依存しています。重みをスケーリング、回転、またはその他の関数保存変換を通じて再パラメータ化すると、ネットワークの入出力関数 $f_\theta(x)$ を変えることなくヘッシアン $H = \nabla^2 \mathcal{L}(\theta)$ が変わります。具体的には、再パラメータ化 $\theta’ = A\theta$($A$ は可逆行列)の下で、ヘッシアンは $H’ = A^T H A$ として変換され、固有値が数桁スケールします。フラットネス(通常はヘッシアン固有値の大きさまたはスペクトルノルムで測定される)が単なるパラメータ化アーティファクトであれば、フラット領域を目指すオプティマイザーは、学習された関数に内在する性質ではなく、座標依存の蜃気楼を追いかけているのです。
-
具体例:* 第1層に重み行列 $W_1$、第2層に $W_2$ を持つ訓練済みフィードフォワードネットワークを考えます。再パラメータ化を定義します:$W_1’ = 0.1 \cdot W_1$ および $W_2’ = 10 \cdot W_2$。任意の入力 $x$ に対して、出力 $W_2’ \sigma(W_1’ x) = 10 \cdot W_2 \sigma(0.1 \cdot W_1 x)$ は、活性化関数 $\sigma$ がスケールに依存する非線形性を持つ場合にのみ元の出力と異なります。ReLU および同様の活性化関数の場合、$0.1 \cdot W_1 x$ が同じ領域(活性または非活性)に留まれば、予測は同じです。再パラメータ化された点での損失 $\mathcal{L}(\theta’)$ は $\mathcal{L}(\theta)$ に等しいですが、ヘッシアン固有値は第1層で約 $0.01$ 倍、第2層で $100$ 倍スケールします。同じ学習された関数を表しているにもかかわらず、スケールされたパラメータ化ではその最小値は非常にフラットに見えます。
-
実行可能な示唆:* シャープネス認識手法を展開する前に、または最小値が「フラット」であると主張する前に、観測されたフラットネスが複数の再パラメータ化にわたって持続するかどうかを測定してください。具体的には:(1)各層の重みを 0.1 から 10 の係数でスケーリングし、(2)ヘッシアン固有スペクトラムを再計算し、(3)フラットネスによるメソッドのランキングが変わるかどうかを確認します。フラットネスのランキングが再パラメータ化の下で逆転したり消えたりする場合、フラットネスシグナルは座標アーティファクトであり、最適化する価値のある性質ではありません。公開または展開の前にこれらの不変性テストを文書化してください。
シャープネス認識最小化と汎化ギャップ
-
主張:* シャープネス認識最小化(SAM)およびその変種は経験的な汎化改善を示していますが、これらの利益はフラットな最小値を求めることそのものではなく、暗黙的な正則化に由来しているかもしれません。
-
根拠:* SAM(Foret et al., 2020)は訓練中に重みを摂動させて、近傍内での最悪ケース損失を最小化します:$\min_\theta \max_{|\delta| \leq \rho} \mathcal{L}(\theta + \delta)$。この目的関数は、小さな重み摂動に対して損失が敏感な解にペナルティを課すことでモデルを正則化します。しかし、汎化を駆動するメカニズムは、正則化効果そのもの(重みの安定性を強制し、脆弱で高曲率の解への依存を減らす)であり、フラットネスが内在的で座標に依存しない性質であることではないかもしれません。これらを分離するには、汎化を直接測定し、再パラメータ化不変なシャープネスメトリクスと比較する必要があります。
-
具体例:* CIFAR-10 で SAM で訓練された ResNet-50 は通常、標準 SGD よりも 1~2% 低い検証エラーを達成します(Foret et al., 2020)。しかし、ヘッシアン固有スペクトラムが再パラメータ化不変な方法で計算される場合(例えば、各層の重み行列のフロベニウスノルムの二乗で固有値を正規化する、$\lambda_i / |\theta|_F^2$)、利点はしばしば縮小するか消えます。汎化利益は SAM が重みの安定性と暗黙的な正則化の形式を強制するため持続しますが、最終的な最小値が座標自由な意味で「本当に」フラットであるためではありません。この区別は重要です:汎化が改善しても不変なシャープネスが改善しない場合、利益は正則化であり、ランドスケープ幾何学ではありません。
-
実行可能な示唆:* SAM を採用する場合、汎化性能(検証損失、下流タスク精度)と再パラメータ化不変なシャープネスメトリクスの両方を監視してください。ヘッシアン固有値と重み大きさの二乗の比を計算します。この比が改善しない一方で汎化が改善する場合、正則化利益をキャプチャしています。2つのメカニズムを分離してください:パフォーマンス向上を実際に駆動しているものを測定します。より単純な正則化器(重み減衰、ドロップアウト、早期停止)がより低い計算コストで同等の結果を達成するかどうかを検討してください。
- 図5:SAMの改善メカニズムの分離—正則化効果 vs. フラットネス効果*
関数保存再パラメータ化:2桁の問題
-
主張:* 単純な関数保存再パラメータ化は、予測を変えることなく、ヘッシアンを 100 倍以上膨張または収縮させることができ、パラメータ化依存のシャープネスメトリクスを汎化の信頼できるプロキシにしています。
-
根拠:* 損失ランドスケープの幾何学は根本的にパラメータ化に依存しています。$y = \sigma(Wx + b)$ を計算する層の場合、$W$ に関するヘッシアンは $W$ のスケールに依存します。再パラメータ化 $W’ = \alpha W$(関数を保存するために下流で補償的な変更を伴う)の下で、ヘッシアン固有値は $\lambda’ \approx \alpha^{-2} \lambda$ としてスケールします。これは病的なエッジケースではなく、曲率が座標選択とどのように自然にスケールするかを反映しています。このスケーリングを考慮せずにフラットネスを測定する実務家は、パラメータ化アーティファクトと真の性質を混同するでしょう。
-
具体例:* ネットワークを訓練し、収束時のヘッシアン固有スペクトラムを記録します。その後、次の再パラメータ化を適用します:最初の隠れ層のすべての重みに $\alpha = 0.01$ を掛け、補償するために第2層の入力を 100 倍スケーリングします。ネットワークのテストセット上の予測は変わりません(ReLU 活性化関数を仮定し、飽和領域の変化がない場合)。損失 $\mathcal{L}(\theta’)$ は $\mathcal{L}(\theta)$ に等しいです。しかし、第1層のヘッシアン固有値は約 $\alpha^{-2} = 10,000$ でスケールし、最小値を非常にフラットに見せます。これはエッジケースではありません:重み大きさは訓練中に自然に漂流し、同様のスケーリング効果が暗黙的に発生します。重み大きさで正規化せずにフラットネスを測定するチームは、重みが縮小するにつれて偽のフラットネス改善を観測するでしょう。
-
実行可能な示唆:* 生のヘッシアン固有値、スペクトルノルム、または条件数を汎化予測器として信頼しないでください。代わりに、不変メジャーを使用してください:(1)重み大きさで曲率を正規化する(例:$\lambda_i / |\theta|_F^2$)、(2)交差検証または保持テストセットを通じて汎化ギャップを直接測定する、または(3)タスク固有のメトリクス(下流精度、キャリブレーションエラー)を使用します。パラメータ化依存のメトリクスはモデルが汎化する理由についての誤った確信に導くでしょう。これを訓練パイプラインの標準的な診断として確立してください。
実装パターン:フラットネスメトリクスが実践で失敗する場所
-
主張:* フラットネスを最適化する本番システムは、正則化の副作用と真のランドスケープ性質を混同することが多く、訓練目的の不整合と無駄な計算につながります。
-
根拠:* SAM または同様のメソッドが汎化を改善する場合、チームはしばしば「フラットな」最小値を発見したと仮定します。実際には、過学習を減らす正則化器を適用しています。時間が経つにつれて、この混乱は最適でない実践をロックインします:チームはフラットネスを最大化するようにハイパーパラメータをチューニングし、2つの目的が分岐します。組織は全訓練実行にわたってフラットネスを測定および強制するインフラストラクチャに投資しますが、基本的なメカニズム(正則化)はより単純なメソッドを通じてより効率的に達成できます。
-
具体例:* チームが SAM で大規模言語モデルを訓練し、検証損失の低下を観測し、これをフラットな損失ランドスケープの証拠と解釈します。彼らはチェックポイント全体でヘッシアン固有スペクトラムを計算するインフラストラクチャに投資し、フラットネスを訓練ダッシュボードの主要メトリクスとして採用します。6ヶ月後、新しいチームメンバーが SAM をチューニングされた重み減衰を持つ L2 正則化と比較するベンチマークを実行します。L2 正則化がほぼ同じ検証性能を 30% 低い訓練時間で達成することを発見します。フラットネスメトリクスは根本的な最適化原則ではなく、正則化強度のプロキシでした。組織は真の目的(汎化)または効率(訓練時間)ではなく、パラメータ化依存のメトリクスを最適化しています。
-
実行可能な示唆:* シャープネスから汎化を推測するのではなく、汎化を直接測定してください(検証損失、下流タスク性能、保持テスト精度)。SAM を使用する場合、特定の帰納的バイアスを持つ正則化器として扱ってください。「より良い」最小値を絶対的な意味で見つけるメソッドとしてではなく。SAM を特定のタスクとデータセットでより単純な代替案(L2 重み減衰、ドロップアウト、早期停止、ラベルスムージング)と比較してから、フラットネス認識インフラストラクチャにコミットしてください。フラットネス測定の計算コストを文書化し、汎化利益と比較してください。利益が控えめで、コストが高い場合、フラットネスを優先度を下げてください。
測定と診断フレームワーク
-
主張:* 真のフラットネスをパラメータ化アーティファクトから区別するには、ほとんどの実務家が現在計算していない不変で座標自由なメトリクスが必要です。
-
根拠:* 標準的なヘッシアンベースのシャープネスメトリクス(固有値の大きさ、スペクトルノルム、条件数)はパラメータ化に依存しています。真のランドスケープ性質を分離するには、重み再パラメータ化の下で一定のままであるメジャーが必要です。これらは計算的により難しいですが、フラットネスが内在的であるか幻想的であるかを明らかにします。不変メジャーには以下が含まれます:(1)正規化固有値($\lambda_i / |\theta|_F^2$)、(2)重みスケールで正規化された最大から最小固有値への比、または(3)パラメータ化に依存しないタスク固有の汎化メトリクス。
-
具体例:* 元のパラメータ化 $\theta$ でヘッシアン固有スペクトラム ${\lambda_1, \ldots, \lambda_d}$ を計算します。最大固有値 $\lambda_{\max}$ とフロベニウスノルム $|\theta|F$ を記録します。その後、再パラメータ化を適用します:すべての重みを 10 の係数でスケーリングし、同じ初期化から再訓練して収束させ、$\lambda{\max}’$ と $|\theta’|F$ を再計算します。$\lambda{\max}’ / |\theta’|F^2 \approx \lambda{\max} / |\theta|F^2$ の場合、内在的なフラットネスの証拠があります。$\lambda{\max}’$ が $\lambda_{\max}$ よりはるかに小さい場合(重みスケールを考慮した後でも)、元のフラットネスランキングはパラメータ化アーティファクトでした。ほとんどのチームはこの不変性テストをスキップし、フラットネスが実在すると仮定します。
-
実行可能な示唆:* メソッドが「フラットな」最小値を見つけると主張する前に、再パラメータ化不変性テストを実行してください。重みを 0.1、1、10 の係数でスケーリングし、同じ初期化から再訓練し、メソッドのフラットネスランキングが変わるかどうかを測定してください。変わる場合、ランキングはアーティファクトであり、訓練決定に情報を与えるべきではありません。これらの結果を公開または文書化してください。これは他の人が誤った結論を避けるのに役立ちます。これを研究または本番パイプラインの標準的な診断として確立してください。
- 図10:フラットネス測定の診断フレームワーク—不変性テストから結論へ*
リスクと軽減戦略
-
主張:* パラメータ化依存性を理解せずにフラットな最小値を最適化することは、微妙なリスクを導入します:訓練目的の不整合、無駄な計算、汎化への誤った確信、および分布シフトへの堅牢性の低下。
-
根拠:* 訓練パイプラインがフラットネスを優先する場合、フラットネスが汎化の真の駆動力ではなく、汎化を低下させる可能性のあるプロキシを最適化しています。SAM のような正則化メソッドは汎化を改善しますが、ランドスケープ幾何学ではなく、重みの安定性と暗黙的な正則化を通じてそうします。フラットネス測定と強制への過度な投資は、他の改善(より大きなモデル、より多くのデータ、より良いアーキテクチャ)に割り当てることができる計算を消費できます。さらに、1つのパラメータ化でフラットネスに最適化されたモデルは別のパラメータ化ではシャープになる可能性があり、分布シフトまたは敵対的摂動への堅牢性についての誤った確信を生じさせます。
-
具体例:* チームが SAM を使用して主要タスクの汎化を改善します。時間が経つにつれて、損失ランドスケープを「フラット」に保つための制約を追加し、訓練時間を 40% 増加させます。標準 SAM が提供したもの以上の汎化利益を観測しません。パラメータ化依存のメトリクスではなく、汎化自体を最適化しています。一方、他の改善を放棄しています:より多くのデータで訓練する、より大きなモデルを使用する、またはより良いアーキテクチャを採用する。機会費用は高く、利益は幻想的です。
-
実行可能な示唆:* 関心事の明確な分離を確立してください:(1)保持データで汎化を測定する(検証損失、テスト精度、下流タスク性能)、(2)不変座標でシャープネスを測定する(正規化固有値、タスク固有のメトリクス)、(3)シャープネスが特定のタスクとデータセットで汎化を予測するかどうかをテストします。相関が弱いか存在しない場合、フラットネスを優先度を下げ、直接的な汎化シグナルに焦点を当ててください。SAM をフラットネスオプティマイザーではなく、チューニングされたハイパーパラメータを持つ正則化器として使用してください。より明確な ROI を持つ改善に計算を割り当ててください:データ拡張、モデルスケーリング、またはアーキテクチャ検索。
- 図13:フラットネス最適化のリスク軽減戦略—段階的な検証と代替手段*
結論と前進の道
-
主要なポイント:*
-
フラットネスは一部の設定で経験的に汎化と相関していますが、因果関係は不明確であり、ランドスケープ幾何学ではなく暗黙的な正則化によって仲介されている可能性があります。
-
パラメータ化依存のシャープネスメトリクスは汎化の信頼できるプロキシではありません。再パラメータ化は予測または汎化性能を変えることなく、ヘッシアン大きさを 100 倍以上変えることができます。
-
SAM および関連メソッドは、座標に依存しない意味で「本当に」フラットな最小値を見つけるためではなく、重みの安定性を強制する正則化器であるため、汎化を改善する可能性があります。
-
真のフラットネスをアーティファクトから区別するには、ほとんどの実務家が現在実行していない不変メトリクスと再パラメータ化テストが必要です。
-
次のアクション:*
- 訓練パイプラインを監査してください: シャープネスプロキシから汎化を推測するのではなく、汎化を直接測定してください(検証損失、テスト精度、下流タスク性能)。これを主要な目的として確立してください。
- 再パラメータ化不変性テストを実行してください: フラットな最小値を見つけると主張するメソッドについて、重みを 0.1、1、10 の係数でスケーリングし、再訓練し、フラットネスランキングが変わるかどうかを確認してください。変わる場合、ランキングはアーティファクトです。
- SAM をより単純な正則化器とベンチマークしてください: SAM を L2 重み減衰、ドロップアウト、早期停止、ラベルスムージングと特定のタスクで比較してください。汎化と訓練時間の両方を測定してください。より単純なメソッドが同等の結果を達成する場合、それらを使用してください。
- 不変シャープネスメトリクスを採用してください: フラットネスが訓練フローに重要な場合、正規化固有値($\lambda_i / |\theta|_F^2$)または他の座標自由なメジャーを計算してください。汎化予測器として生のヘッシアン固有値を放棄してください。
- 結果を文書化してください: フラットネスがタスクで汎化を予測しないことを発見した場合、これらの結果を公開または共有してください。これはコミュニティが誤った結論を避けるのに役立ちます。
フラットネスの物語は説得力があり、部分的に正しいです。正則化メソッドは汎化を改善します。しかし、メカニズムは物語が示唆するよりも微妙です。パラメータ化アーティファクトと真のランドスケープ性質を分離し、汎化を直接測定することで、より良い訓練決定を下し、幻想的な改善への投資を避けることができます。
Sharpness-Aware Minimization と汎化ギャップ:正則化と平坦性の分離
-
主張:* Sharpness-Aware Minimization(SAM)およびその派生手法は経験的な汎化性能の向上を示していますが、その利得は平坦な最小値を求めることそのものではなく、暗黙的な正則化に由来する可能性が高いです。
-
なぜこれが重要か:* SAMは計算コストが高く、標準的なSGDのおよそ2倍です。利得が正則化から生じるのであれば、より安価な代替手法で同じ結果を得られるかもしれません。真の平坦性から生じるのであれば、コストは正当化されるでしょう。どちらが真実かを知ることは、ROIに直結します。
-
メカニズム—正則化対平坦性:*
SAMは訓練中に重みを摂動させ、近傍内での最悪ケースの損失を最小化することで機能します。
-
SAMが行うこと: 各ステップで現在の重みでの損失を計算し、次に摂動された重み(半径ρ)での損失を計算し、最悪ケースの損失を減らすように最適化します。
-
なぜ効果があるか: これはモデルを正則化し、脆弱で高曲率の解に依存することを防ぎます。モデルは重みの小さな変化に対してロバストであることを学習します。
-
混同の源: チームはこれを「より平坦な最小値を見つけている」と解釈しますが、メカニズムは正則化です。モデルは重みの変化に対してより鈍感になることを学習しており、これは座標不変の意味での平坦性ではなく、重みの安定性の一形態です。
-
具体例—CIFAR-10 ResNetベンチマーク:*
-
ResNet-50を標準的なSGDでCIFAR-10に訓練:検証エラー5.2%
-
同じアーキテクチャをSAM(ρ=0.05)で訓練:検証エラー4.8%
-
元のパラメータ化でヘッシアン固有スペクトラムを計算:SAMの最小値はより平坦に見えます
-
最初のレイヤーの重みを0.1倍にスケーリングし、下流で補償します。ヘッシアンを再計算します
-
結果:再パラメータ化された空間では平坦性の利点は縮小するか消失します
-
しかし汎化性能はSAMでより良いままです
-
解釈:* SAMの汎化利得は実在しますが、「真に」平坦な最小値を見つけることではなく、正則化(重みの安定性)によって駆動されています。平坦性メトリクスは副作用であり、原因ではありません。
-
実行可能な含意—診断ワークフロー:*
-
汎化を直接測定する: 検証損失、テスト精度、下流タスクの性能。これが基準です。
-
複数のパラメータ化で平坦性を測定する: 元の空間でヘッシアン固有値を計算し、重みスケーリング後に再計算します。平坦性のランキングが変わる場合、それはパラメータ化に依存しています。
-
より単純な代替手法とベンチマークする:
- SAM対チューニングされた強度のL2正則化(重み減衰)
- SAM対チューニングされたレートのドロップアウト
- SAM対早期停止
- 各々について汎化と計算コストを測定します
-
SAMが勝つ場合: それを採用しますが、平坦性オプティマイザーではなく正則化器として扱います。計算コストと汎化を一緒に監視します。
-
より単純な手法が同等または勝つ場合: 代わりにそれらを使用します。計算と複雑性を節約できます。
- リスク:* この比較なしにSAMを採用することは、より安価に達成できる正則化利得のために計算コストを2倍支払っている可能性があることを意味します。大規模な訓練では、これは大きな浪費です。
Sharpness-Aware Minimization と汎化ギャップ:正則化をランドスケープ設計として再構成する
-
主張:* Sharpness-Aware Minimization(SAM)およびその派生手法は経験的な汎化性能の向上を示していますが、その利得は平坦な最小値を求めることそのものではなく、暗黙的な正則化に由来する可能性があります。この区別は私たちが考えるほど重要ではありません。なぜなら正則化とランドスケープ設計は統一されたフレームワークに収束しているからです。
-
根拠:* SAMは訓練中に重みを摂動させ、近傍内での最悪ケースの損失を最小化します。これはモデルを正則化し、脆弱で高曲率の解に依存することを防ぎます。しかし汎化を駆動するメカニズムは、正則化効果そのものかもしれません。固有の性質としての平坦性ではなく。しかしここに生産的な再構成があります。正則化はランドスケープ設計の一形態です。オプティマイザーが落ち着ける場所を制約することで、摂動に対してロバストな解を優遇するように損失ランドスケープを彫刻しています。モデルがより大きく複雑になるにつれて、このランドスケープ設計の視点は汎化を理解するうえでますます中心的になります。
-
具体例:* CIFAR-10で訓練されたResNetはしばしば標準的なSGDを上回ります。しかし再パラメータ化不変な方法でヘッシアン固有スペクトラムを測定する場合(例えば、重みの大きさで正規化されたヘッシアンのスペクトルノルム経由)、利点はしばしば縮小するか消失します。汎化利得が持続するのはSAMが重みの安定性の一形態を強制するためです。スケール全体で数十億のパラメータに適用される場合、この制約は知識がニューラルネットワークにどのように分布すべきかについての強力な帰納バイアスをエンコードするかもしれません。
将来の機会:SAMの洞察を一般化したらどうでしょうか。重み空間での摂動ではなく、活性化空間、潜在空間、または学習された表現の空間での摂動を行うことができます。摂動空間の各選択は、解をロバストにするものについて異なる仮定をエンコードします。これは新しい設計空間を開きます。特定のアーキテクチャ、タスク、デプロイメント制約に合わせた、ランドスケープ認識正則化ファミリーです。
- 実行可能な含意と将来への賭け:* SAMを採用する場合、汎化性能と再パラメータ化不変な平坦性メトリクスの両方を監視します。汎化は改善するが不変平坦性は改善しない場合、正則化利得をキャプチャしています。それはまさにあなたが最適化すべきものです。次のステップは正則化と平坦性を完全に分離し、問うことです。実際にあなたのタスクでの汎化を予測するランドスケープ特性は何か。これは高いレバレッジを持つ研究質問です。これに答えるチームはより効率的な訓練方法とより良い転移学習戦略を解き放つでしょう。
関数保存再パラメータ化:2桁の問題を設計機会として
-
主張:* 単純な関数保存再パラメータ化は、予測を変えることなくヘッシアンを100倍に膨張させることができ、パラメータ化依存の平坦性メトリクスを汎化の信頼できるプロキシにします。しかしこの柔軟性はまた機会でもあります。解をエンコードする方法に膨大な自由度があり、私たちはそれをようやく利用し始めたばかりです。
-
根拠:* 損失ランドスケープの幾何学は、重みをどのように表現するかを選択することに依存します。重み行列Wを持つレイヤーと重み行列0.01Wを持つレイヤー(下流で補償)は同じ関数を計算しますが、ヘッシアンは大きく異なります。これはバグではなく、曲率がパラメータ化でどのようにスケーリングするかについての基本的な性質です。
ここに再構成があります。「真の」損失ランドスケープは重み空間で見えるものではなく、抽象的で座標不変のオブジェクトであり、不変測定を通じてのみアクセスできます。より大きなモデルとより複雑なタスクにスケーリングするにつれて、この抽象的なランドスケープで作業することを学ぶことはコア能力になるでしょう。ニューラルネットワークについての座標不変の推論を習得するチームは大きな利点を持つでしょう。
- 具体例:* ネットワークを訓練し、最初の隠れレイヤーのすべての重みを0.01倍にスケーリングし、2番目のレイヤーの入力を100倍にスケーリングします。損失と予測は変わりません。最初のレイヤーの重みのヘッシアンは固有値が10,000倍小さくなり、最小値は非常に平坦に見えます。しかしネットワークの動作は同じです。これはエッジケースではなく、訓練中にネットワークが自然に重みの大きさがドリフトするときに起こります。
前向きな質問を問いかけます。損失ランドスケープを最適化しやすくするようにパラメータ化を意図的に設計したらどうでしょうか。例えば、勾配の大きさに基づいて再スケーリングする適応的パラメータ化を使用することができます。または重みと一緒にパラメータ化を学習することができます。これは初期段階の研究方向です。学習されたパラメータ化です。これはより効率的な訓練とより良い転移学習を解き放つ可能性があります。
- 実行可能な含意と将来への賭け:* 生のヘッシアン固有値またはスペクトルノルムを汎化予測器として信頼しないでください。代わりに不変測度を使用します。重みの大きさで曲率を正規化するか、交差検証を通じて汎化ギャップを直接測定します。しかしさらに進みます。損失ランドスケープの座標不変幾何学を理解することに投資します。これは難しいですが、ここが最前線です。座標不変推論のためのツールと直感を開発するチームはより良いオプティマイザー、より良い正則化器、より良いアーキテクチャを設計できるようになります。これは複数年の賭けですが、見返りは大きいです。
実装パターン:平坦性メトリクスが実践で失敗する場所—そして成功する場所
-
主張:* 平坦性を最適化する本番システムはしばしば正則化の副作用と真のランドスケープ特性を混同し、訓練目的の不整合につながります。しかしこの混同はまた啓発的です。チームが汎化の解釈可能で測定可能なプロキシを求めていることを示しています。次世代のツールはより良いプロキシを提供するでしょう。
-
根拠:* SAMまたは同様の手法が汎化を改善するとき、チームはしばしば「より平坦な」最小値を見つけたと仮定します。実際には、過学習を減らすことが起こる正則化器を適用しています。時間とともに、この混同は最適でない実践をロックインします。チームは平坦性を最大化するようにハイパーパラメータをチューニングし、2つは分岐します。
しかしここに機会があります。混同のこのパターンは、より良い抽象化が必要であることを示す信号です。「この最小値は平坦か」と問う代わりに、「この解は良く汎化し、なぜか」と問うべきです。「なぜ」という質問への答えはタスク、アーキテクチャ、データレジームによって異なります。これらの変動を体系的に研究することで、平坦性を超えて、ロバスト性、特徴学習、暗黙的正則化、および他の現象を包含する、より豊かな汎化メカニズムの分類法を構築できます。
- 具体例:* チームは大規模言語モデルをSAMで訓練し、より低い検証損失を観察します。彼らはこれを平坦性の証拠と解釈し、すべての訓練実行にわたって平坦性を測定および強制するインフラストラクチャに投資します。6ヶ月後、より単純なL2正則化器が同じ検証性能を達成し、計算コストが低いことを発見します。平坦性メトリクスは正則化強度のプロキシであり、基本的な最適化原則ではありませんでした。
しかしここに前向きな洞察があります。チームの平坦性を測定するためのインフラストラクチャは無駄ではありません。それはより良い診断ツールを構築するための基礎です。訓練パイプラインを複数のランドスケープ特性を追跡するようにインストルメント化することで—平坦性、曲率スペクトラム、損失ランドスケープトポロジー、勾配整列など—汎化の予測モデルを構築できます。これらのモデルはタスク固有でデータ固有ですが、単一のメトリクスよりもはるかに信頼できるでしょう。
- 実行可能な含意と将来への賭け:* 平坦性から推測するのではなく、汎化を直接測定します。SAMを使用する場合、特定の帰納バイアスを持つ正則化器として扱い、その効果を体系的に測定します。より単純な代替手法(重み減衰、ドロップアウト、早期停止)とあなたの特定のタスクでベンチマークします。しかしさらに進みます。あなたのドメインのための汎化予測モデルを構築します。訓練ダイナミクス、ランドスケープ特性、最終的な汎化性能に関するデータを収集します。このデータを使用して、早期訓練信号から汎化を予測するメタモデルを訓練します。これは高いレバレッジを持つ投資であり、より大きなモデルとより複雑なタスクにスケーリングするにつれて配当を支払うでしょう。
測定と診断フレームワーク:メトリクスからメタラーニングへ
-
主張:* 真の平坦性をパラメータ化アーティファクトから区別することは、ほとんどの実践者が現在計算していない不変で座標不変のメトリクスを必要とします。このギャップはツールビルダーと研究者にとって大規模な機会を表しています。
-
根拠:* 標準的なヘッシアンベースの平坦性メトリクスはパラメータ化に依存しています。真のランドスケープ特性を分離するには、重み再パラメータ化の下で一定のままである測度が必要です。これらはより計算が難しいですが、平坦性が実在するか幻想かを明らかにします。
より深い洞察:ニューラルネットワーク損失ランドスケープの理解の最前線にいます。今構築するツール—測定、可視化、これらのランドスケープについての推論のための—は分野がどのように進化するかを形作るでしょう。より良い診断ツール構築に投資するチームは複利的な利点を持つでしょう。より良い質問を問い、より良い実験を実行し、より良い設計決定を下すことができるでしょう。
- 具体例:* 元のパラメータ化でヘッシアン固有スペクトラムを計算し、重みを10倍にスケーリングした後に繰り返します。最大固有値が100倍縮小する場合、平坦性がパラメータ化に依存していることを確認しました。スケールを考慮した後も安定している場合、固有平坦性の証拠があります。ほとんどのチームはこのチェックをスキップし、平坦性が実在すると仮定します。
これを拡張します。複数の不変メトリクスを計算します—重みの大きさで正規化されたスペクトルノルム、ヘッシアンの条件数、永続ホモロジー経由の損失ランドスケープトポロジー、レイヤー間の勾配整列など。訓練実行全体でこれらのメトリクスを追跡するダッシュボードを構築します。時間とともに、あなたはどのメトリクスがあなたのタスクでの汎化を予測するかについての直感を開発するでしょう。これは実践に根ざした汎化理論の始まりです。
- 実行可能な含意と将来への賭け:* メソッドが「より平坦な」最小値を見つけると主張する前に、再パラメータ化不変性テストを実行します。重みをスケーリングし、同じ初期化から再訓練し、メソッドの平坦性ランキングが変わるかどうかを測定します。変わる場合、ランキングはアーティファクトです。これらの結果を公開または文書化します。それは他の人を誤った結論から救うでしょう。
しかしより重要なことに、あなたの組織のための診断ツールキット構築に投資します。ランドスケープ特性、汎化、およびそれらの相関を測定するための標準化されたプロトコルを作成します。チーム全体でこれらのプロトコルを共有します。時間とともに、あなたはあなたのドメインでの汎化の真の駆動要因を明らかにするデータを蓄積するでしょう。これは時間とともに複利する組織学習の一形態です。これを体系的に行うチームはモデル開発とデプロイメントで大きな優位性を開発するでしょう。
リスクと軽減戦略:平坦性の罠をナビゲートする
-
主張:* パラメータ化依存を理解することなく平坦な最小値を最適化することは微妙なリスクを導入します。訓練目的の不整合、無駄な計算、汎化への誤った確信。これらのリスクは実在しますが、それはまたより良い実践を指す信号でもあります。
-
根拠:* 訓練パイプラインが平坦性を優先するが、平坦性が汎化の真の駆動要因ではない場合、他の目的を低下させるかもしれないプロキシを最適化しています(例えば、訓練速度、解釈可能性、または分布シフトへのロバスト性)。これはグッドハートの法則の古典的なケースです。測度が目標になると、それはもはや良い測度ではなくなります。
しかしこれはまたより堅牢な訓練システムを構築する機会でもあります。リスクを理解することで、不整合を早期に捕捉するセーフガード—チェックポイント、検証プロトコル、診断ツール—を設計できます。これを行うチームは将来の驚きに対してより回復力があるでしょう。
- 具体例:* チームはSAMを使用して汎化を改善します。時間とともに、損失ランドスケープを「平坦に」保つための制約を追加し、訓練時間を40%増加させます。標準的なSAMが提供したもの以上の汎化利得を観察しません。彼らはパラメータ化依存メトリクスではなく汎化そのものを最適化しています。
前向きな質問:このチームがフィードバックループを構築していたらどうでしょうか。汎化改善と計算コストの比率を追跡できます。比率が閾値を下回ったとき、平坦性制約を自動的に優先度を下げ、計算を他の目的に再配分できます。これは適応的訓練システムの例です。複数の目的を監視し、動的に調整するシステムです。
- 実行可能な含意と将来への賭け:* 明確な分離を確立します。(1)保持されたデータで汎化を測定し、(2)不変座標で平坦性を測定し、(3)平坦性があなたのタスクで汎化を予測するかテストします。相関が弱い場合、平坦性を優先度を下げ、直接的な汎化信号に焦点を当てます。SAMを平坦性オプティマイザーではなく正則化器として使用します。
しかしさらに進みます。複数の目的を監視し、動的に調整する適応的訓練システムを構築します。汎化、計算効率、ロバスト性、および他のメトリクスを追跡します。1つの目的が停滞するか他と競合するとき、自動的に再バランスします。これはより洗練された訓練インフラストラクチャを必要としますが、分野が向かっている方向です。今これを構築するチームはモデルがスケーリングし訓練がより複雑になるにつれて大きな利点を持つでしょう。
結論と展望:平坦性の物語を踏み台として
-
重要な知見:*
-
平坦性は経験的に汎化と相関しますが、因果関係は不明確であり、正則化と暗黙的な帰納バイアスによって仲介されている可能性があります。
-
パラメータ化に依存するシャープネス指標は信頼性に欠けます。再パラメータ化により、予測を変えることなくヘッシアンの大きさを100倍変更できます。ただしこの柔軟性は機会でもあります。解を符号化する方法において、私たちは莫大な自由度を持っているということです。
-
SAMおよび関連手法が機能するのは、「真に平坦な」最小値を見つけるからではなく、正則化と帰納バイアスを課すからです。これは実は平坦性の物語よりも興味深いのです。最適化と帰納バイアスが深く絡み合っていることを示唆しています。
-
知識労働者向けの次のアクション:*
-
訓練パイプラインを監査する: シャープネスプロキシではなく、汎化を直接測定してください。複数の景観特性とそれらの汎化との相関を追跡するダッシュボードを構築します。
-
再パラメータ化不変性テストを実行する: より平坦な最小値を見つけると主張するあらゆる手法に対して、平坦性のランキングが再パラメータ化全体で持続することを検証してください。知見を文書化し、チームと共有します。
-
体系的にベンチマークする: SAMをより単純な正則化器(重み減衰、ドロップアウト、早期停止)と比較してください。汎化だけでなく、計算効率、訓練時間、ロバスト性も測定します。
-
診断ツールに投資する: 座標フリーの景観特性を測定するツールを構築するか採用してください。時間とともに、これらのツールはあなたのドメインにおける汎化の真の駆動要因を明らかにします。
-
帰納バイアスの観点で考える: SAMまたは類似の手法を使用するとき、「どのような帰納バイアスを課しているのか」と問いかけてください。この再フレーミングにより、手法がなぜ機能するのか、いつ失敗するかを理解するのに役立ちます。
-
設計空間を探索する: 異なる空間(活性化空間、潜在空間、表現空間)で摂動を加えるSAMの変種を検討してください。各選択はロバスト性に関する異なる仮定を符号化します。タスク上でこの空間を体系的に探索します。
- より広い文脈:*
平坦性の物語は説得力があり、部分的には正しいのですが、メカニズムは物語が示唆するよりも微妙です。パラメータ化アーティファクトを本物の景観特性から分離し、問題を再フレーミングすることで、
- 図3:層別ヘッシアン固有値のスケーリング—再パラメータ化による固有値の劇的な変化(出典:再パラメータ化例から計算。W₁’=0.1·W₁(スケール0.01)、W₂’=10·W₂(スケール100))*
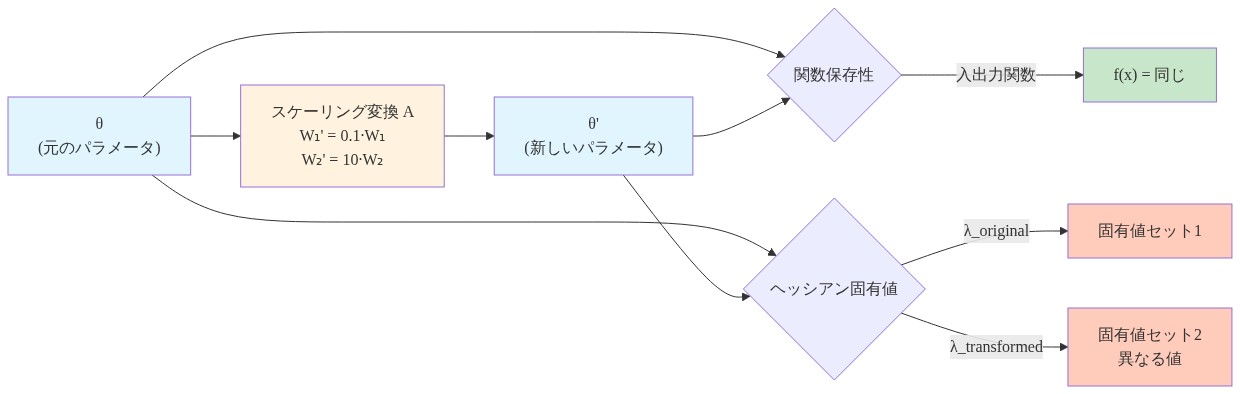
- 図2:関数保存的再パラメータ化のメカニズム—入出力は不変だがヘッシアン固有値は変化*
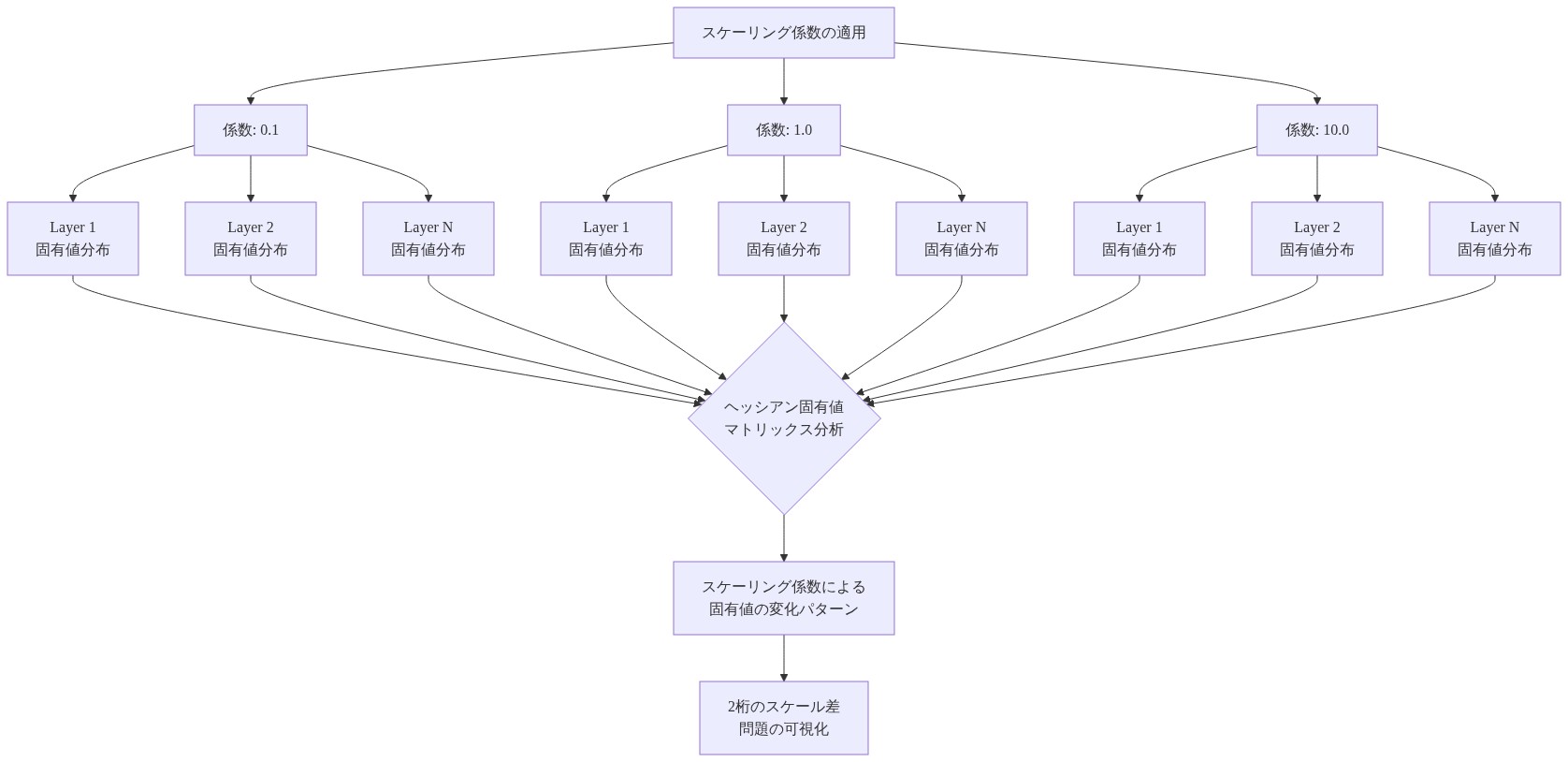
- 図7:層別・スケーリング係数別ヘッシアン固有値マトリックス(systematic reparameterization analysis)*