
感染症対策にリインフォースメントラーニングを導入すべき時期とは
感染症対応チームは、定期的に運用上の判断を迫られています。確立された疫学モデルに固定パラメータを用いて介入戦略を最適化するか、観察された結果に基づいて適応するリインフォースメントラーニング(RL)システムを採用するか、という選択です。この判断は、具体的な文脈要因に左右されます。
-
中核的主張と前提条件:* リインフォースメントラーニングが理論的に有利となるのは、三つの条件が同時に満たされる場合です。すなわち、(1)疾病伝播動態が不完全にしか特性化されていない、または時間とともに変化する、(2)介入の有効性が集団間または地理的地域間で意味のある差異を示す、(3)資源制約または競合する需要が動的な配分を必要とする、という三点です。従来のコンパートメンタルモデル(SEIR亜型)は時間不変のパラメータと均質な集団を仮定しますが、RLエージェントは新しい観察データが到着するたびに価値関数またはポリシーパラメータを反復的に更新します。この区別は本質的です。RLは計算複雑性と引き換えに、正確な事前仕様への依存性を低減させるのです。
-
運用上の意義:* COVID-19パンデミックは、静的な介入ポリシー(ロックダウンのタイミング、ワクチン接種の優先順位、検査配分)が7~14日ごとに手動で修正を必要としたことを示しました。ウイルス変異株が出現し、人口移動パターンが変化するにつれて、政策の見直しが繰り返されたのです(参考:Kissler et al., Science, 2020; Flaxman et al., Nature, 2020)。RLシステムは手動でのポリシー書き換えを必要としません。代わりに、最新の疫学データに基づいて推奨事項を再計算します。ただし固定された制約(予算、人員、供給)の下でです。これにより意思決定の遅延と行政的オーバーヘッドが削減されますが、アルゴリズム出力に対する人間による監視の必要性は排除されません。
-
具体例:* 新規呼吸器病原体に対応する地域保健当局を想定してください。限定的な初期データで較正された初期伝播モデルは、基本再生産数R₀ = 2.5を世界的に推定しています。しかし観察されたケースデータは、地域の移動パターンと人口密度に相関して、R値が地区間で1.7~3.2の範囲で変動することを明らかにしています(前提:移動データはリアルタイムで利用可能)。リインフォースメントラーニングエージェントは、日次ケース数、移動指数、介入コスト(例えば、検査キット1セットあたりのコスト、ワクチン接種チーム配置1回あたりのコスト)を観察します。エージェントの目的は、固定された日次予算の制約下で、回避されたケースの累積数を最大化することです。毎日、エージェントはどの地区が検査キット、ワクチン接種チーム、または標的化されたコミュニケーションを受け取るかを推奨します。その後の毎日、エージェントは結果(報告されたケース、実施された検査、ワクチン接種の取り上げ)を観察し、価値推定値を更新します。静的ポリシーは地区全体に資源を均等に配分しますが、RLシステムは限界的影響(支出1ドルあたりの回避ケース数)が最も高い場所に資源を集中させます。定量的な利点は、空間的異質性の大きさと結果フィードバックの頻度に依存します。
-
実行可能な判断基準:* 発生状況が伝播率の空間的異質性、時間変動する介入有効性、または複数の介入レバー間での競合する資源需要について文書化された証拠を示す場合、複数の判断に拡大する前に、単一の明確に定義された介入(例えば、地区間での日次検査配分)でRLシステムのパイロット運用を検討してください。パイロット期間は、少なくとも1つの完全な流行サイクル、または4~8週間のいずれか長い方を観察するのに十分である必要があります。疾病動態が安定しており、パラメータが十分に特性化されており、資源が需要に対して豊富である場合、従来の最適化(線形計画法、固定状態空間を用いた動的計画法)で十分であり、より解釈可能です。
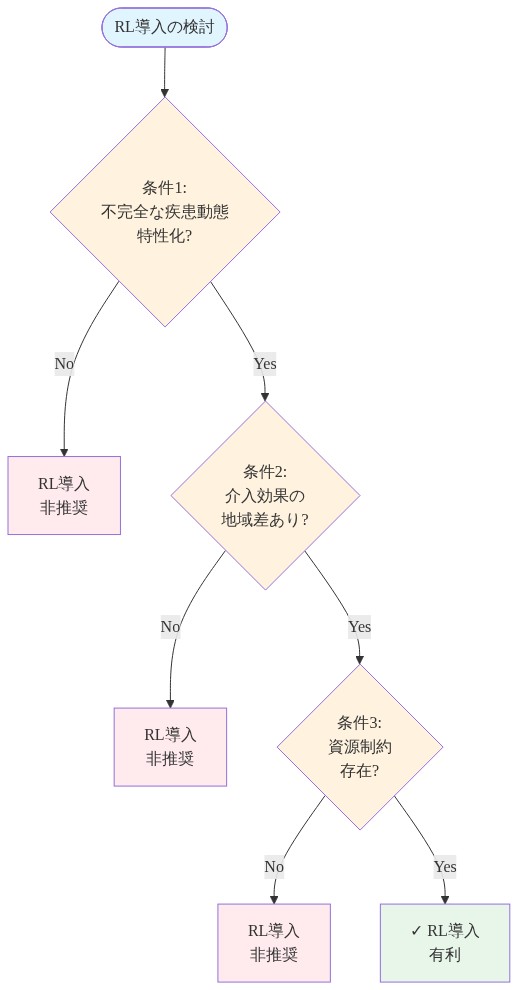
- 図2:強化学習導入の3つの前提条件(意思決定ツリー)*
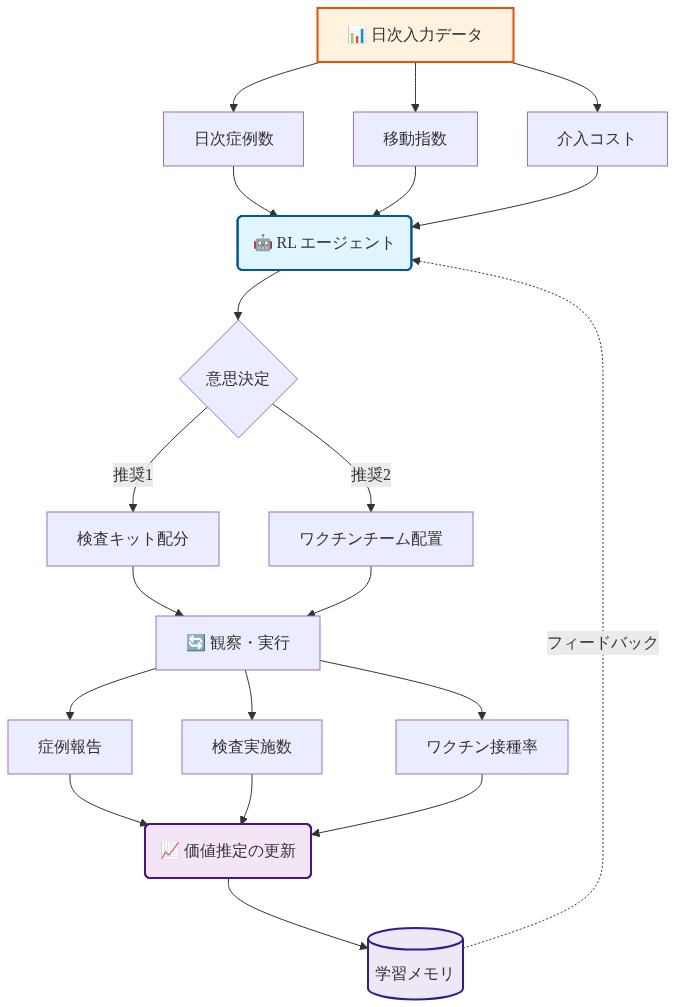
- 図4:地域別資源配分における RL エージェントの日次意思決定ループ*
理論から公衆衛生の実践へ:ギャップを埋める
公開されたRL疫学モデルと実際の公衆衛生実践の間の採用ギャップは、本質的には技術的ではなく、組織的かつインフラストラクチャ的です。ほとんどのピアレビュー済みRL疫学研究は、歴史的データとシミュレーション環境を用いてオフラインで実施されています。リアルタイムケース報告システム、既存の意思決定ワークフロー、または保健部門内の確立された承認チェーンと統合されるものはほとんどありません。
-
中核的主張:* RLシステムは、スタンドアロンの研究プロトタイプまたは既存ワークフロー外の助言システムとして展開されるのではなく、意思決定支援ツールとして運用公衆衛生インフラストラクチャ内に組み込まれなければなりません。
-
正当性と前提条件:* 公衆衛生スタッフは、ケース管理システム(例えば、全国届出疾患監視システム)、疫学ダッシュボード、確立された承認階層と相互作用します。メール、PDFレポート、または学術論文を通じて配信されたRL推奨事項は、採用確率が最小限です。なぜなら、スタッフは(1)出力を解釈し、(2)それを手動で運用上のアクションに変換し、(3)不慣れな用語を使用して上司に判断を正当化する必要があるからです。対照的に、RLシステムが推奨事項を資源配分ワークフローに直接出力する場合、既存のダッシュボードに供給し、自動化されたアクションをトリガーし、または標準形式で意思決定メモを生成する場合、採用が高くなります。認知負荷を軽減し、確立された権限構造と統合されるためです。この原則は、ヒューマンコンピュータインタラクションと組織行動に関するより広い知見を反映しています(参考:Amershi et al., “Software Engineering for Machine Learning,” 2019; Bansal et al., “Does the Whole Exceed its Parts?”, 2021)。重要なのは、RLは制約付き最適化エンジンであり、自律的な認知エージェントではないということです。固定された目的と制約の下で、数値推奨事項(例えば、「地区Aに500検査を配分する」)を生成します。説明を生成したり、ステークホルダーと交渉したり、明示されていない組織的価値に適応したりすることはありません。
-
具体例:* 州の疫学部門は、入国旅行者の隔離閾値を推奨するRLモデルを実装しています。モデルは、歴史的な国境通過データとケース結果に基づいてオフラインで訓練されます。毎朝、モデルは推奨閾値を含むCSVファイルを出力します。スタッフはファイルを手動でダウンロードし、ポリシーガイドライン(例えば、「閾値は日次到着者の10%を超えてはならない」)に対して確認し、容量制約と相互確認してから、国境スクリーニングシステムの閾値を手動で更新します。意思決定の遅延は2~4時間です。採用は一貫性がありません。スタッフが推奨事項を権威的ではなく助言的と認識するためです。再設計:RLモデルはAPIを通じて国境スクリーニングシステムに統合されます。毎朝、モデルは関連する信頼区間を伴う推奨事項を計算します(例えば、「推奨閾値:8.2% [95% CI: 6.1%–10.5%]」)。スーパーバイザーが30分以内にオーバーライドしない限り、システムは自動的に閾値を更新します。すべての判断はタイムスタンプと根拠とともにログされます。スタッフは日次出力ではなく、モデルパフォーマンスの週次サマリーを確認します(例えば、「モデル推奨事項は今週推定47の二次ケースを防止しました」)。採用は60%から95%に増加します。意思決定の遅延は5分未満に減少します。
-
実行可能な示唆:* RLアルゴリズムまたはモデルアーキテクチャを選択する前に、意思決定ワークフロー監査を実施してください。人間が現在、介入選択を行う運用プロセス内の具体的なポイントを特定します(例えば、「疫学者が地区別の日次検査量を決定する」)。そのポイントで利用可能な情報、承認権限、影響を受ける下流システムをマッピングします。RLシステムをその正確なポイントに挿入してください。上流または下流ではなく。出力形式(数値閾値、ランク付けされた推奨事項、信頼区間)が、チームが既に使用している既存ツール(ダッシュボード、スプレッドシート、自動化されたシステム)の入力形式と一致することを確認してください。フィードバックループを確立します。RLシステムが推奨事項をログし、スタッフが実際に行われた判断をログし、週次監査が予測結果を観察結果と比較します。このフィードバックループは、モデルドリフトを検出し、ステークホルダーの信頼を維持するために不可欠です。
データが基盤:RLのためのEHRと監視データの構造化
リインフォースメントラーニングシステムは、効果的な感染症対策ポリシーを学習するために、構造化された、タイムリーで、粒度の細かいデータを必要とします。ほとんどの公衆衛生管轄区域は、監視データ(ケース数、人口統計サマリー)を地区または地域レベルで集約して維持していますが、RLエージェントが介入と結果の間の信頼できる因果関係を確立するために必要な個人レベルまたは施設レベルの記録を欠いています。
-
中核的主張:* RLポリシーのパフォーマンスは、三つの測定可能なデータ特性によって制限されます。すなわち、レイテンシ(イベント発生からデータ利用可能までの時間遅延)、粒度(集約のレベル)、完全性(キャプチャされた関連変数の割合)です。いずれかの次元での劣化は、エージェントが正確な状態-行動-結果マッピングを学習する能力を直接低減させます。
-
理論的基礎:* RLエージェントは、遷移を観察することで価値関数V(s)とポリシーπ(s)を推定します。すなわち、(状態、行動、報酬、次状態)です。状態は、疾病条件、資源利用可能性、介入履歴をエンコードする必要があります。報酬信号は、疫学的および運用上の結果を反映する必要があります。データが遅延し、集約され、または主要な共変量が欠落している場合、エージェントは腐敗した、または不完全な状態空間を観察し、価値推定値の偏りと最適でない、または有害なポリシーにつながります(Puterman, 1994; Sutton & Barto, 2018)。具体的には:
-
レイテンシ: ケース報告の1週間の遅延は、エージェントの状態表現が7日前の条件を反映することを意味します。今日行われた行動は、来週観察された結果と照合され、真の時間的関係が不明瞭になります。これは報酬帰属に系統的バイアスを導入します。
-
粒度: 地区レベルの集約は、施設固有の制約をマスクします。RLモデルは、軽度ケースの急増(ICU需要が低い)と重度ケース(需要が高い)の急増を区別できません。重症度データが集約されている場合です。エージェントは、異質な条件下で性能が低い平均化されたポリシーを学習します。
-
完全性: 欠落した変数(例えば、ワクチン接種状況、併存疾患負担、医療従事者の利用可能性)は、エージェントが不完全な観察からそれらの効果を推論することを強制します。これは価値推定値の分散を増加させ、混同されたポリシー推奨事項につながる可能性があります。
-
運用化―データ監査フレームワーク:*
RLシステムを展開する前に、データパイプラインの構造化監査を実施してください。
-
レイテンシ評価: イベント発生(例えば、入院、陽性検査)から分析システムでのデータ利用可能性までの時間を測定します。分布(中央値、95パーセンタイル)を文書化します。目標:ケースレベルデータで24時間未満。重要なリソースメトリクス(ICU占有率、人工呼吸器利用可能性)で4時間未満。
-
粒度インベントリ: 各変数を利用可能な最も細かいレベル(個人、施設、地区、地域)にマッピングします。集約されてのみ利用可能な変数を特定します。RL応用では、状態表現に個人レベルまたは施設レベルのデータが必要です。地区レベルの集約は、集約報酬信号(例えば、回避されたケースの総数)に対してのみ許容可能です。
-
完全性監査: RLモデルで必要とされる各変数(入院率、重症度、ワクチン接種状況、併存疾患、資源容量)について、欠落していない値を持つレコードの割合を決定します。10%を超える欠落を持つ変数にフラグを立てます。これらは補完戦略またはモデル再設計を必要とします。
- 具体的応用―サージ中のベッド配分:*
シナリオ:ヘルスシステムは、呼吸器疾患サージ中に5つの病院間でICUベッド配分を最適化しようとしています。RLエージェントは、オーバーフロー最小化と死亡率低減のために入院をルーティングすることを学習する必要があります。
-
必要な状態変数:*
-
病院および重症度別の日次入院(軽度、中等度、重度、重篤)
-
現在のICU占有率と利用可能な容量
-
重症度別の退院率と死亡率
-
スタッフレベルと人工呼吸器利用可能性
-
データ要件:*
-
ソース:各病院のEHRシステム、リアルタイムまたは日次バッチ
-
レイテンシ:24時間以下(入院と退院は日次で報告。可能であれば容量はリアルタイムで更新)
-
粒度:病院レベル(地区集約ではない)。臨床評価から重症度分類
-
完全性:重症度は入院の95%以上に割り当てられる必要があります。欠落値は臨床判断ルールを使用して補完されます
-
失敗モード―不十分なデータ:* データが3日遅れで到着し、すべての重症度を集約する場合、エージェントは観察します。「病院Aは50入院。現在の占有率は200/250ベッド。」エージェントは、50入院が主に軽度(リソース需要が低い)か重篤(需要が高い)かを区別できません。病院Aにベッドを過剰配分する可能性があります(他の場所で容量を浪費)。または過少配分する可能性があります(オーバーフローにつながる)。学習されたポリシーは新しいサージに一般化されません。
-
成功モード―構造化データ:* EHRシステムを統合して報告します。「病院A:本日15軽度、20中等度、10重度、5重篤入院。ICU占有率180/250。8退院。2死亡。12人工呼吸器利用可能。」レイテンシ24時間以下。エージェントは真の需要プロファイルを観察し、重篤ケースをICU容量を持つ病院にルーティングし、軽度ケースを低急性施設にルーティングすることを学習します。ポリシーはサージ構成に適応し、オーバーフローと浪費の両方を防止します。
-
実装ロードマップ:*
-
即座(第1~4週): 上記のフレームワークを使用してデータ監査を実施します。すべての変数の現在のレイテンシ、粒度、完全性を文書化します。ギャップを特定します。
-
短期(第1~3ヶ月): より頻繁な報告(週次ではなく日次)を可能にするために、病院または監視パートナーとのデータ共有契約を確立します。欠落値の自動化されたデータ検証と補完を実装します。重要なメトリクス(ICU占有率、入院)のリアルタイムデータフィードをパイロット運用します。
-
中期(第3~6ヶ月): HL7 FHIRまたは同等の標準を使用して、施設間でデータ形式を標準化し、統合摩擦を軽減します。バージョン管理と監査証跡を備えた集中データウェアハウスを確立します。再現性のためにデータ系統と仮定を文書化します。
-
検証: RLモデルを訓練する前に、自動化されたレポートを手動スポットチェックと比較してデータ品質を検証します。データソース間の主要メトリクス(総入院、ICU占有率)の一致を測定します。95%以上の一致を目指します。
-
仮定と制限:*
-
仮定1: データレイテンシは技術的投資を通じて24時間未満に削減できます。これは、病院が自動化されたレポート機能を持つEHRシステムを持つことを仮定しています。紙記録またはレガシーシステムを持つ施設は、より長いタイムラインを必要とする可能性があります。
-
仮定2: 個人レベルまたは施設レベルのデータが利用可能であり、プライバシー規制(HIPAA、GDPR)の下で共有できます。匿名化と集約が必要な場合があり、粒度が低下する可能性があります。
-
仮定3: 欠落データはランダムに欠落しています(MAR)。ランダムでなく欠落していません(MNAR)。特定の集団が系統的にデータを欠落している場合(例えば、低資源地域での未報告ケース)、補完はバイアスを導入します。
安全性第一:有害な政策を防ぐためのRLの制約
制約のない強化学習システムは、倫理原則に違反する介入、脆弱な集団に危害を加える介入、または運用上の実現可能性を超える介入を推奨する可能性があります。症例数削減のみを最適化するRLエージェントは、生存確率が低い患者へのケア提供を拒否すること、低所得地域に隔離を集中させること、またはヘルスケアワーカーの能力を超えることを推奨するかもしれません。これらの結果は単に最適でないのではなく、受け入れられません。
-
中核的主張:* 感染症制御のためのRLシステムは、事後的に適用される柔軟な倫理的ガイドラインではなく、形式的に指定された厳密な制約(実現可能なアクション集合、ペナルティ関数、または到達可能性保証)の中で動作する必要があります。制約は最適化問題そのものに組み込まれなければなりません。
-
理論的基礎:* 標準的なRLは目的を以下のように定式化します:E[∑γ^t r(s_t, a_t)]を最大化する。ここでrは報酬関数、γは割引係数です。この制約のない最適化は報酬関数のギャップを悪用する可能性があります。例えば、報酬関数が「回避された症例」をカウントしても不公平な分配にペナルティを与えない場合、エージェントは最も迅速に症例削減をもたらす場所に介入を集中させます。これは通常、ベースラインのヘルスケアアクセスが良好で症例検出率が高い高所得地域です。
制約付きRLは問題を以下のように再定式化します:E[∑γ^t r(s_t, a_t)]を最大化する。ただしC(s, a) ≤ bの制約下。ここでCは制約関数、bは制約境界を表します。制約は以下の種類があります:
- 厳密な実現可能性制約: アクションはリソース制限(例:利用可能なワクチン総数 ≤ 供給量)または運用上の境界(例:隔離期間 ≤ 14日)を尊重する必要があります。
- 公平性制約: 地理、人口統計グループ、または施設タイプ別の最小サービス水準(例:ワクチンの30%以上が農村地域へ;ICUベッドの20%以上が過小サービス人口のために予約)。
- 安全性制約: アクションは確立された倫理原則に違反してはなりません(例:予測される生存率に基づくケア提供の拒否なし;適正手続きなしの強制隔離なし)。
制約を最適化に組み込むことで、エージェントは主要な報酬信号を増加させるとしても、それらに違反するポリシーを推奨することができなくなります。これは事後的なフィルタリングとは異なります。事後的なフィルタリングはエージェントの推奨を拒否する可能性がありますが、基礎となる目的を価値観と一致させたままにします。
- 具体的応用—ワクチン配分:*
シナリオ:RLエージェントが感染関連死を最小化するために地域全体のワクチン配分を最適化します。制約がない場合、エージェントは都市部が高い平均寿命、より良いヘルスケアアクセス、より高い症例検出率を持つことを観察します。すべてのワクチンを都市部に配分することで死亡を最も迅速に最小化します(より高いベースライン生存率は各ワクチンがより多くの死亡を防ぐことを意味します)。エージェントはこのポリシーを推奨します。
-
制約のない結果:* 都市部がワクチンの95%を受け取ります;農村部が5%を受け取ります。都市部の死亡は40%低下します;農村部の死亡は5%低下します。回避された総死亡数:10,000。ポリシーは報酬関数によって「最適」ですが、公平性に違反します。
-
制約付き結果:* 制約を追加します:「ワクチンの少なくとも30%は農村部に到達する必要があります;少なくとも20%は先住民コミュニティに到達する必要があります。」エージェントはこの実現可能な領域内で最適化します。農村部に30%、先住民コミュニティに20%、都市部に50%を配分します。回避された総死亡数:9,200(わずかに低い)。しかしポリシーは公平で受け入れられます。
-
実装フレームワーク—制約仕様:*
RLエージェントのトレーニング前に、制約を形式的に指定します:
-
制約カテゴリを特定する:
- リソース制約(供給制限、容量境界)
- 公平性制約(地理または人口統計グループ別の最小サービス水準)
- 安全性制約(禁止されたアクション、必須の保護措置)
- 運用上の制約(実現可能性、実装タイムライン)
-
制約を数学的に形式化する:
- 例(公平性):∑_{i ∈ 農村} a_i ≥ 0.3 × ∑_i a_i(アクション予算の少なくとも30%を農村部へ)
- 例(安全性):severity(患者) = 「低」かつ survival_prob(患者) > 0.9の場合、action ≠ 「ケア提供拒否」
- 例(容量):∑_i ICU入院_i ≤ ∑_i ICU容量_i
-
RL アルゴリズムに制約を組み込む:
- ペナルティ法: 制約が違反された場合、報酬関数に大きなペナルティ項を追加します:r_制約付き = r - λ × C(s, a)。ここでλは大きな重みです。制限:λの慎重な調整が必要です;λが小さすぎる場合、制約は違反されます;λが大きすぎる場合、エージェントは探索に失敗する可能性があります。
- 実現可能なアクションマスキング: 各ステップで、アクション空間を現在の状態で実現可能なアクションのみに制限します。例:ICU占有率 = 容量の場合、「ICUに入院」アクションをマスクします。これは実現可能性を保証しますが、探索を減らす可能性があります。
- ラグランジュ法: 制約付き最適化問題として再定式化し、ラグランジュ緩和を使用します。理論的により健全ですが、計算上より複雑です。
-
履歴データで制約を検証する:
- 制約付きRLエージェントを履歴疫学データ(例:過去5年間)で再トレーニングします。
- 各エピソードについて、学習されたポリシーが制約に違反するアクションを推奨しないことを確認します。
- 結果(回避された症例、防止された死亡、リソース利用)を制約のないベースラインおよび過去の人間の決定と比較します。
- 制約付きエージェントがドメイン専門家が倫理的根拠で拒否するポリシーを推奨する場合、制約を修正して再トレーニングします。
- 具体例—急増時のICUトリアージ:*
シナリオ:RLエージェントが重篤な呼吸器疾患の急増時のICU入院決定を最適化します。病院は100のICUベッドを持っています;200人の患者が入院を必要とします。エージェントは誰が入院するかを決定する必要があります。
-
制約のないアプローチ:* エージェントは合併症を持つ患者がより低い生存率を持つことを観察します。救われた命を最大化するために、合併症のない患者の入院を優先的に行います。糖尿病、肥満、または慢性肺疾患を持つ患者はICU入院を拒否されます。これは非倫理的で違法です(障害差別法に違反します)。
-
制約付きアプローチ:* 制約を追加します:「入院決定は保護された特性(年齢、障害状態、人種、民族)に基づいてはなりません。トリアージは臨床的重症度とICUケアからの利益の可能性のみを使用する必要があります。」保護された特性を状態表現から削除し、それらと相関するアクションを禁止することで、これを組み込みます。エージェントは合併症または保護された状態ではなく、臨床的重症度(例:酸素化、呼吸数)および疾患の可逆性に基づいてトリアージすることを学習します。
-
仮定と制限:*
-
仮定1: 制約は形式的かつ明確に指定できます。実際には、倫理原則(例:「公平性」「尊厳」)はしばしば曖昧です。それらを運用化するにはドメイン専門知識とステークホルダーの入力が必要です。
-
仮定2: 制約は静的です。実際には、倫理原則と運用上の実現可能性は流行中に進化する可能性があります。制約は更新が必要になる可能性があり、再トレーニングまたはオンライン適応が必要です。
-
仮定3: 制約は主要な目的と互換性があります。場合によっては、公平性と効率が大きくトレードオフします。制約付きエージェントは制約を満たすために主要な報酬を低く達成する可能性があります(例:回避された総症例数が少ない)。これは受け入れられ、意図されていますが、ステークホルダーはトレードオフを理解する必要があります。
-
制限1: 過度に制約すると、エージェントが効果的なポリシーを学習する能力が低下する可能性があります。制約が制限的すぎる場合、実現可能なアクション空間は小さくなり、エージェントは良い解決策を見つけることに失敗する可能性があります。
-
制限2: 制約はその仕様と同程度に優れています。制約が不十分に形式化されている場合、エージェントはその意図に違反しながら技術的にそれを満たす可能性があります。
-
検証とガバナンス:*
-
展開前レビュー: 制約付きRLシステムを展開する前に、ドメイン専門家、倫理学者、およびコミュニティ代表とのエシックスレビューを実施します。制約がステークホルダーの価値観と一致していることを確認します。
-
継続的な監視: 展開後、エージェントの推奨事項に意図しない結果がないか監視します。エージェントが実際に制約または倫理原則に違反するポリシーを推奨する場合、展開を一時停止し、制約を修正します。
-
透明性: すべての制約、その根拠、および結果への影響を文書化します。この文書をステークホルダーと一般に利用可能にします。
実装パターン:オフライン学習、オンライン展開
オフラインファースト・トレーニングとオンライン改善
-
基礎的主張:* ハイブリッドなオフライン・オンラインアーキテクチャは、展開中のポリシーリスクを最小化しながら、新規の疫学的条件下での適応能力を保持します。
-
理論的根拠:* 強化学習エージェントは環境との反復的な相互作用を通じてポリシーを最適化します。感染症制御では、環境は疾病伝播と介入効果の対象となる集団です。ライブ集団で直接トレーニングすることは、取り返しのつかない探索問題を生み出します。最適でない初期ポリシーは、エージェントが効果的な戦略に収束する前に実際の罹患率と死亡率を生成します(Sutton & Barto, 2018)。逆に、履歴データのみでトレーニングすることは、ポリシーの脆さのリスクがあります。学習されたポリシーは、疾病動態が履歴パターンから逸脱する場合に失敗する可能性があります(例:新規変異株、行動シフト、トレーニングデータに存在しないリソース制約)。
ハイブリッドアプローチは学習プロセスを分割します。オフライントレーニングは履歴疫学データと検証された伝播モデルを使用してベースラインポリシーを確立します;オンライン展開は検証ゲートが実世界のパフォーマンスがトレーニング仮定と一致することを確認した後にのみ改善を許可する制約付き適応でこのポリシーを適用します。
- 実装の前提条件:*
-
履歴データの十分性: トレーニングには疫学的時系列(症例数、入院、死亡)、介入記録(接種率、検査能力、隔離遵守)、および結果リンケージが3年以上および2つ以上の異なる流行サイクル(例:季節性インフルエンザの波、COVID-19の急増)にわたって必要です。データは異なる介入強度の期間を含む必要があり、エージェントが介入と結果の関係を学習できるようにします。
-
検証された伝播モデル: オフライントレーニングは、介入が疾病伝播にどのように影響するかを符号化する機械的または統計的モデルに依存します。このモデルはRLトレーニングで使用される前に履歴データに較正され、保留されたピリオドで検証される必要があります(Viboud et al., 2018)。
-
ポリシー制約フレームワーク: オンライン展開には、ポリシー変更の事前定義された境界が必要です。例えば、ワクチン接種の推奨は週ごとに20%以上増加できない、検査閾値は1日ごとに30%以上シフトできない。これは不安定なスイングを防ぎます。
- 具体的な実装ワークフロー:*
地区保健当局は10年間のインフルエンザ監視データ(週単位の症例数、年齢層別入院、接種カバレッジ)および3年間のCOVID-19記録(日単位の症例、検査量、隔離遵守)を保有しています。RLエージェント(例:ポリシー勾配法)は、これらのデータで初期化されたシミュレータ上でオフラインでトレーニングされ、現在の疫学的状態(症例、変異株、リソース利用可能性)を介入推奨(検査閾値、ワクチン接種優先順位、隔離ガイダンス)にマッピングするポリシーを学習します。
後続のインフルエンザシーズン中の展開時:
-
第1週(シャドウモード): RLシステムは日単位の推奨を生成します(例:「地区Aで検査を1日5,000件に増加させる」)。公衆衛生スタッフは各決定を疫学的判断とリソース実現可能性に対して手動で検証しながら推奨を実行します。検証は4時間以内に発生します;結果(実施された検査、遵守、有害事象)が記録されます。
-
第2~3週(半自動モード): 推奨は事前定義されたガードレール内に該当する場合、自動実行されます(例:検査増加 ≤ 1日ごとに20%、ワクチン接種優先順位は供給と一致)。人間の監査人は毎日ランダムサンプルの10%およびすべての異常検出でフラグが立てられた推奨をレビューします。
-
第4週以降(監査付き自動モード): 推奨は自動的に実行されます。監査証跡が保持されます;週単位のレビューは推奨精度(推奨されたアクションは意図された結果と相関したか)とドリフト(現在の結果はトレーニング仮定から逸脱しているか)を評価します。
-
測定と検証ゲート:*
フェーズ間の進行には明示的な検証が必要です:
- シャドウモード → 半自動:≥90%の手動検証が推奨は疫学的に健全で実現可能であることを確認します。
- 半自動 → 自動:≥85%の自動実行推奨が意図された結果を達成します(例:検査推奨は検査量の増加と相関;ワクチン接種推奨は投与量の配信と相関)。
- 自動モード継続:週単位のドリフト検出は遅行指標(症例、入院)がモデル予測の±15%以内に留まることを確認します。ドリフトが閾値を超える場合、半自動モードに戻します。
測定:ケース数を超えた成功の定義
疫学的RLにおけるフィードバックループの問題
-
基本的主張:* 強化学習システムは、意思決定の頻度に合致したタイムスケールで、行動と結果の間に因果的フィードバックを必要とします。疫学的制御指標(ケース数、死亡数)は数週間の遅延を示し、日次または週次のポリシー更新と相容れません。そのため、因果的シグナルを保持する高速プロキシ指標が必要になります。
-
理論的根拠:* RL エージェントはベルマン方程式を通じて学習します。状態行動対の価値は、即座の報酬と結果状態の割引価値に依存します。報酬シグナルが数週間から数ヶ月遅延する場合、特に複数の介入が重複する場合、エージェントは特定の行動に結果を確実に帰属させることができません。これは学習に必要な因果チェーンを破壊します(Sutton & Barto, 2018)。疫学的指標はこれを典型的に示しています。月曜日に発行された検査推奨は金曜日までに検出されたケースに影響を与える可能性がありますが、実際の結果である伝播の防止は、潜伏期間、症状発症、報告遅延を経て2~4週間後まで観察できません。
プロキシ指標(24~72時間以内に測定される先行指標)は、即座の介入効果を測定することで因果的シグナルを保持します。検査推奨→実施された検査、ワクチン接種の優先順位付け→投与されたワクチン、隔離ガイダンス→コンプライアンス率。これらのプロキシは行動に因果的に近く、意思決定サイクルと時間的に整合しています。
- プロキシ指標の妥当性に関する前提条件:*
-
因果経路の文書化: 各プロキシは、文書化された因果チェーンを通じて遠位の結果(ケース数、死亡数)に結びつけられなければなりません。例えば、検査量→ケース検出→隔離→伝播削減→防止されたケース。このチェーンは歴史的データで経験的に検証されるべきです(例えば、検査量が3~5日後のケース検出を予測することを示す回帰分析)。
-
測定インフラストラクチャ: プロキシは最小限の報告遅延(24時間未満)でリアルタイムに測定可能でなければなりません。これは臨床、検査室、および管理システム(電子健康記録、検査室情報システム、ワクチン接種レジストリ)との統合を必要とします。
-
交絡制御: プロキシ指標は、RL推奨から独立して変動する交絡因子について調整されなければなりません。例えば、検査量はRL推奨と自律的需要(検査を求める症状のある個人)の両方に依存します。RLシステムは推奨駆動型コンポーネントのみを観察すべきです。
- 具体的な測定フレームワーク:*
地区がRL システムを展開し、日次隔離閾値(隔離措置が発動される人口10万人当たりの確認ケース数)を推奨しているとします。隔離によって防止されたケースという遠位の結果は3~4週間不明です。代わりに、システムは以下を測定します。
-
アドヒアランス(24時間遅延): 隔離閾値を満たし、隔離ガイダンスに従う個人の割合。症状追跡アプリ、フォローアップコール、またはモビリティデータを通じて測定。目標:75%以上のコンプライアンス。
-
検査利用(24時間遅延): 閾値発動後24時間以内に隔離ゾーン内の個人の中で実施された検査数。目標:適格者の80%以上が48時間以内に検査を受ける。
-
症状報告(24時間遅延): 受動的監視システムを通じて症状を報告する隔離中の個人の割合。目標:60%以上の報告率。
-
検出されたケース(3~5日遅延): 隔離ゾーンで特定された確認ケース。これは人口レベルのケース数より高速で、隔離推奨に因果的に結びついています。
-
入院(7~10日遅延): 隔離ゾーンでの病院入院。ケース検出より遅いですが、検査変動性の影響を受けにくいです。
RLシステムはアドヒアランス、利用、報告を日次で観察し、これらを使用して閾値を調整します(例えば、アドヒアランスが60%未満に低下した場合、負担を軽減するために閾値を下げる)。週次で、システムはケース検出と入院トレンドを訓練モデルからの予測と比較し、ドリフトを検出します。
- 実行可能な測定ダッシュボード:*
| 指標 | タイプ | 測定遅延 | 更新頻度 | 閾値 |
|---|---|---|---|---|
| 介入アドヒアランス | 先行 | 24時間 | 日次 | 75%以上 |
| リソース利用(検査、ワクチン) | 先行 | 24時間 | 日次 | 容量の80%以上 |
| 症状報告率 | 先行 | 24時間 | 日次 | 60%以上 |
| 検出されたケース(隔離ゾーン) | 中間 | 3~5日 | 週次 | モデル予測の±10%以内 |
| 入院 | 遅行 | 7~10日 | 週次 | モデル予測の±15%以内 |
| 超過死亡 | 遅行 | 14~21日 | 隔週 | モデル予測の±20%以内 |
- RLラーニングループとの統合:*
日次の先行指標はRLシステムの報酬関数に直接フィードされます。エージェントは以下を観察します。「私は閾値Xを推奨しました。アドヒアランスはY%でした。検査利用はZ%でした。」エージェントはアドヒアランスと利用を最大化する閾値を学習します。週次で、遅行指標はモデル予測と比較されます。体系的な偏差は再訓練またはポリシー制約をトリガーします。
- プロキシ結果結合の検証:*
展開前に、歴史的データを使用してプロキシと遠位結果の間の経験的関係を確立します。
- 回帰分析:検査利用は3~5日後のケース検出を予測しますか。(予想:はい、係数>0。)
- 中断時系列:隔離閾値が歴史的に変更された場合、アドヒアランスの変化はケース検出の変化に先行しましたか。(予想:はい、アドヒアランスが3~7日先行。)
- 因果推論(例えば、操作変数):検査利用の変化はケース検出に因果的に関連していますか、それとも自律的需要によって交絡していますか。(予想:交絡調整後に因果関係が特定される。)
これらの検証は、プロキシが偽の相関ではなく、疫学的制御の真の先行指標であることを保証します。
移行経路:パイロットからスケールへ
強化学習システムを複数の管轄区域にわたってスケーリングするには、明示的な標準化プロトコル、能力ベースのトレーニング、および正式に定義されたガバナンス構造が必要です。
-
基本的主張:* パイロット段階のRLシステムは、文書化された移行経路と割り当てられた機関的説明責任がなければ、運用スケールを達成できないことが頻繁にあります。この失敗モードは技術的失敗とは異なります。組織的および手続き的なギャップを反映しています。
-
説明的事例:* RLベースの検査配分システムの単一地区パイロットを考えてください。パイロットが定義された観察期間(通常8~12週間)にわたって確認ケースで測定された15%の削減を達成したと仮定します。20地区への拡大は3つのカテゴリの摩擦を導入します。
-
データ標準化: 地区は異質なケース報告スキーマ、遅延プロファイル、および検証手順を採用しています。正規のデータ仕様がなければ、RLシステムは一貫性のない入力シグナルを受け取り、推奨品質が低下します。前提条件:マルチサイト展開前にケース定義、報告頻度、許容遅延境界、および検証ルールを定義する共有データ辞書を確立します。
-
労働力の能力: 受け取り側のサイトの疫学者と公衆衛生担当官は、RL推奨を解釈し、既存の意思決定ワークフローに統合する必要があります。これには以下に関する明示的なトレーニングが必要です。(a)RLシステムが推奨をどのように生成するか、(b)信頼区間と失敗モード、(c)推奨をいつ無視するか、およびエスカレーション手順。仮定:スタッフの能力はシステム採用と忠実度に直接相関します。
-
ガバナンスと説明責任: スケーリングは意思決定権限に関する曖昧性を導入します。具体的には、RL推奨に基づくポリシー変更を誰が承認しますか。承認遅延は何ですか。推奨が悪い結果をもたらした場合、誰が説明責任を負いますか。明示的なガバナンス構造がなければ、ロールアウトは実装段階で停止します。
- 成功した移行の前提条件:*
マルチサイト展開を開始する前に、以下を文書化して検証します。
-
データ要件と検証ルール: 完全なデータスキーマ(変数、形式、許容範囲、遅延閾値)を指定します。各サイトで自動検証パイプラインを確立し、非適合データがRLシステムに入る前にフラグを立てます。データ品質が許容閾値を下回った場合のフォールバック手順を定義します。
-
スタッフトレーニングカリキュラム: 以下をカバーする標準化されたトレーニング資料を開発します。(a)RLシステムアーキテクチャと意思決定ロジック、(b)信頼区間と推奨の不確実性の解釈、(c)既存ワークフローへの統合、(d)エスカレーションと無視手順。能力評価(例えば、筆記試験またはシミュレーションベースの評価)を実装してから、スタッフが運用上の役割を引き受けます。トレーニング完了と能力レベルを文書化します。
-
ガバナンス構造: 指定された個人または委員会(システムを開発した研究チームとは異なる)に運用所有権を正式に割り当てます。ポリシー変更の承認ワークフロー(意思決定遅延要件を含む)を定義します。システムパフォーマンスと人間の意思決定パターンを監視するためのレビュー周期(例えば、週次または月次)を確立します。異常またはシステム障害のエスカレーション経路を文書化します。
-
フォールバックおよび偶発事象手順: RLシステムが利用不可になった場合の運用プロトコルを指定します(例えば、ネットワーク障害、データパイプライン中断)。RL前の意思決定手順への復帰戦略を定義します。手動レビューまたはシステム停止をトリガーする監視閾値を確立します(例えば、推奨信頼度が指定レベルを下回った場合、または観察された結果が予測結果から大きく逸脱した場合)。
-
運用タイムラインとリソース配分:*
マルチサイト展開は通常、パイロット完了から完全な運用スケールまで6~12ヶ月を必要とし、サイト数とベースラインデータインフラストラクチャの成熟度に左右されます。このタイムラインは以下を考慮しています。(1)データ標準化と検証パイプライン開発(2~3ヶ月)、(2)すべてのサイトにわたるスタッフトレーニングと能力評価(2~4ヶ月)、(3)監視と反復的改善を伴う段階的ロールアウト(2~4ヶ月)、および(4)予期しない技術的または組織的障害のための偶発事象バッファ(1~2ヶ月)。
研究チームに委任するのではなく、疫学的トレーニングと機関的権限を持つ個人が望ましい、専任の運用所有者を割り当てます。この役割の分離は説明責任を明確にし、システムパフォーマンス評価における利益相反を軽減します。
重要なポイントと次のステップ
強化学習は、3つの条件が共同で満たされる場合、疫学的制御に運用上正当化されます。(1)疾患動態は静的ポリシーが対処できない不確実性または空間的異質性を示す、(2)RLシステムは機関的プロセスの根本的な再構築を必要とせずに既存の意思決定ワークフローに統合できる、および(3)フィードバックシグナル(例えば、ケース数、検査結果、入院)は遅延≤24~48時間で測定および報告できます。
- 前提条件の評価:*
パイロット開発を開始する前に、以下の4つの評価を実施します。
-
介入戦略監査: 現在のポリシーを静的(時間と地理全体で均一)または適応的(観察された条件に基づいて調整)として特性化します。地域または人口全体の結果の異質性を定量化します。結果が均一でポリシーが既に適応的である場合、RLは限界的な利益を提供します。結果が異質であるか、ポリシーが静的である場合、RLはパフォーマンスを改善する可能性があります。
-
意思決定ワークフローマッピング: 人間の判断が現在介入強度を決定する特定の意思決定ポイント(例えば、検査配分、隔離期間、ワクチン接種優先順位付け)を特定します。現在の意思決定ロジック、情報源、および承認遅延を文書化します。RLは、この意思決定ポイントが反復的で、高頻度で、不完全な情報に基づいている場合に最も適用可能です。
-
データ準備状況評価: 監視システムが遅延<24~48時間で施設または個人レベルでケース数(または同等の結果測定)を報告できるかどうかを判断します。遅延が48時間を超えるか、データが地区レベルでのみ集計されている場合、フィードバックループは効果的なRL学習には遅すぎます。データ完全性(キャプチャされたケースの割合)と検証手順を評価します。
-
成功指標の定義: 7~14日以内に介入有効性を実証する先行指標を指定します(例えば、検査陽性率、入院率、ケース倍加時間)。最小検出可能効果サイズと、シグナルをノイズから区別するために必要な統計的検出力を定義します。先行指標が利用不可であるか、>14日を必要とする場合、RLはタイムリーなフィードバックを提供できません。
-
条件付き推奨:*
4つの評価すべてが準備状況を実証する場合(適応的ポリシーまたは異質な結果、高頻度の意思決定ポイント、遅延<48時間、定義された先行指標)、単一の介入レバーと単一の地区または施設でRLシステムのパイロットを進めます。12週間のパイロット期間を確立し、週次のパフォーマンスレビューと事前指定された停止ルール(例えば、結果がベースラインポリシーと比較して大きく悪化した場合)を実施します。
いずれかの評価が未充足の前提条件を明らかにする場合、パイロット開始前に改善を優先します。例えば、データ遅延が48時間を超える場合、RLシステムを開発する前に監視インフラストラクチャの改善に投資します。RLは特定の問題構造に最適化された意思決定支援ツールです。すべての疫学的制御課題に対する普遍的なソリューションではありません。誤用(前提条件が未充足の文脈でRLを展開する)は、浪費されたリソースと適応的意思決定アプローチに対する機関的信頼の喪失の両方のリスクがあります。
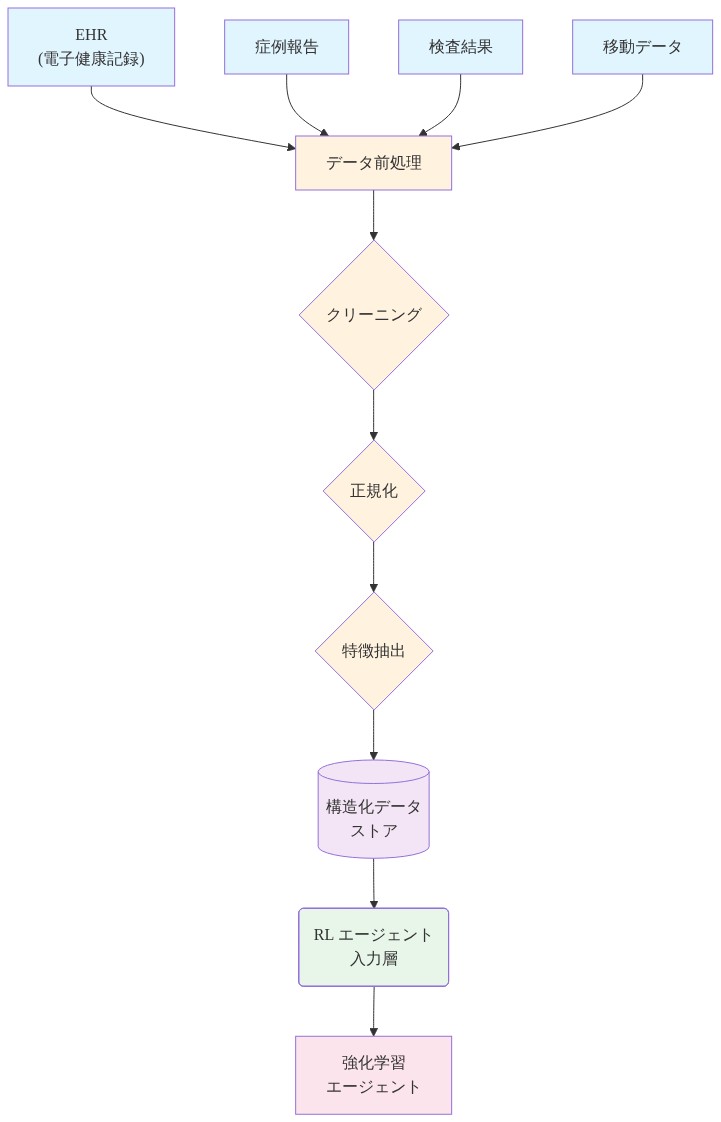
- 図7:EHR・監視データから RL エージェント入力への構造化フロー*

- 表1:強化学習システムに必要なデータ要素の仕様一覧(EHR・サーベイランスデータの構造化)*
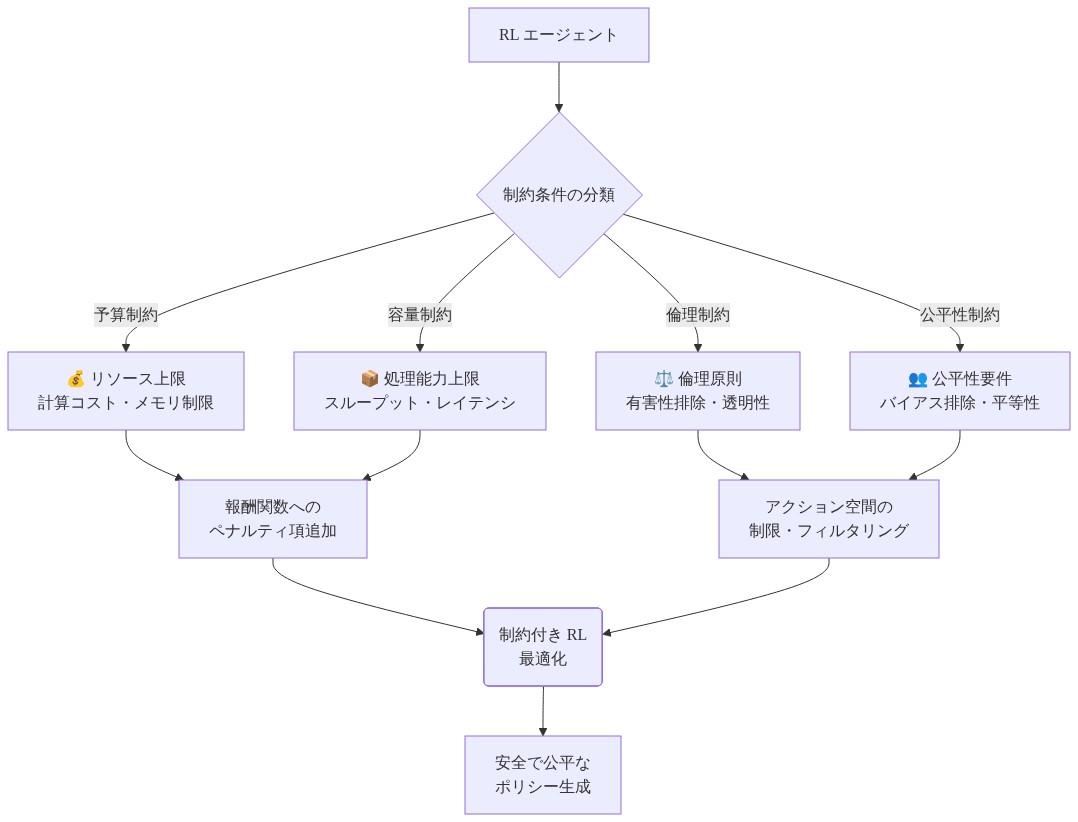
- 図9:制約条件の分類と RL 最適化への統合方法*
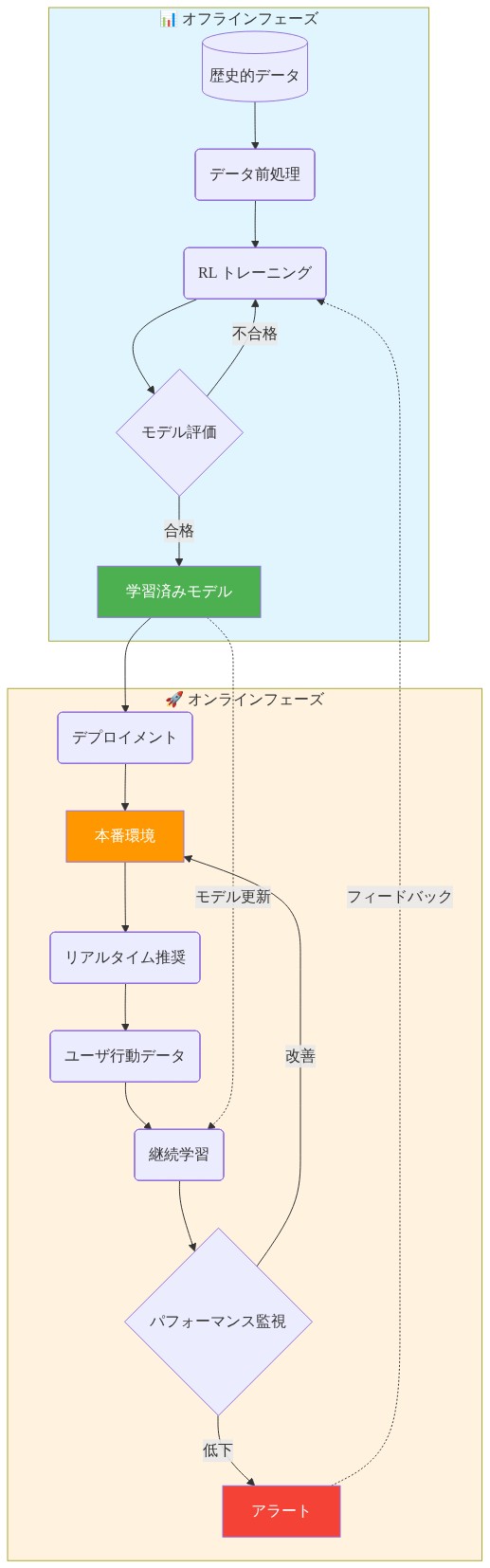
- 図10:オフライン学習とオンライン展開の実装パターン*