
強化学習を用いた逆構造設計とキリガミプロトタイプの高速レーザーカッティング
キリガミメタマテリアルにおける逆設計の課題
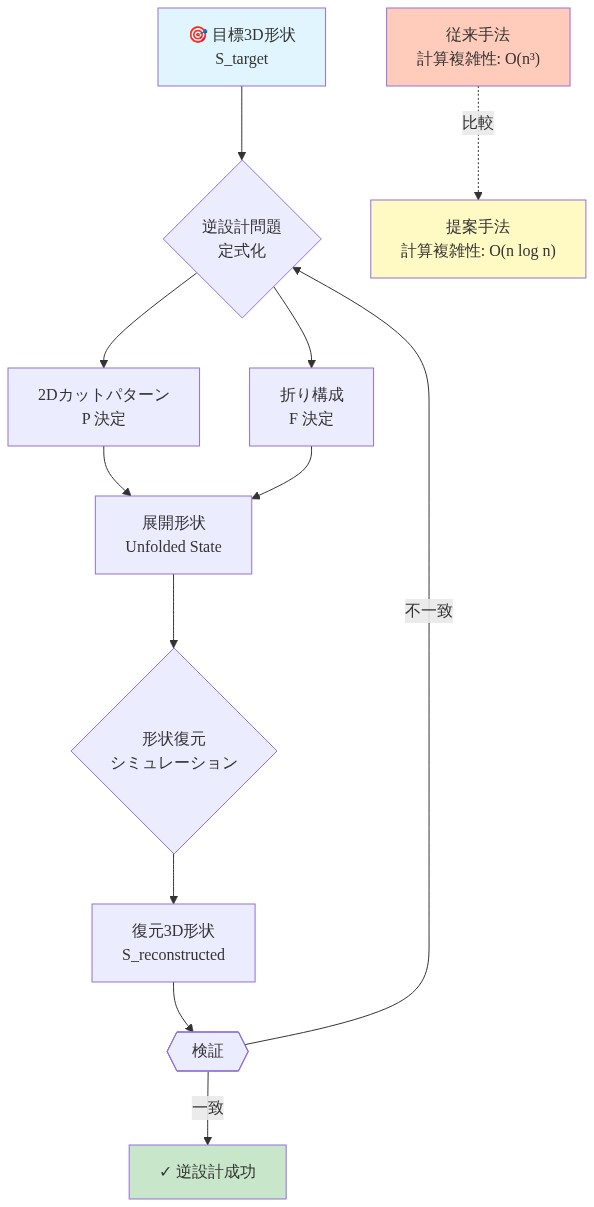
キリガミメタマテリアルは、体系的な切断と折り畳み操作を通じて作成された平面構造であり、三次元構成へと展開します。逆設計問題は形式的に次のように定義されます。目標となる三次元形状 S_target が与えられたとき、P の展開と F が S_target に近似する幾何学を指定された許容範囲内で生成するような二次元切断パターン P と折り畳み構成 F を決定することです。
この逆問題は、既知のパターンから展開形状を予測する順方向シミュレーションよりも計算複雑性が著しく高くなります。展開メカニクスは、(1)材料構成則(弾性、塑性)、(2)平行四辺形四角形テッセレーション要件からの幾何学的制約、(3)展開中の自己交差を防止する位相的適合条件を組み込んだ結合非線形方程式によって支配されます。平行四辺形四角形制約は離散的な幾何学的要件です。切断レイアウトは対辺が平行な四角形要素に分解される必要があり、これが連続設計空間の大きな領域を排除します。切断幾何学への小さな摂動は、これらの適合ルールに違反するか、物理的な重なりを導入する可能性があり、設計空間に不連続な実現可能性境界を生成します。
従来の最適化手法(勾配ベース法、遺伝的アルゴリズム、シミュレーテッドアニーリング)は根本的なスケーリング制限に直面します。各設計反復には、実現可能性と展開精度を評価するための高価な有限要素解析(FEA)が必要であり、メッシュ解像度と材料モデルの複雑性に応じて通常1候補設計あたり10〜100 CPU時間を要します。設計空間は同時に(1)組み合わせ的に広大です。可能な切断パターンの数は目標の複雑性とともに指数関数的に増加します。(2)厳しく制約されています。物理的実現可能性要件を満たすのはごく少数です。これは従来の最適化手法が実現可能領域を効率的に探索できない干し草の中の針を探す問題を生成します。反復シミュレーションまたはヒューリスティック探索に依存する従来の方法は、目標の幾何学的複雑性が増加するにつれてスケーリングが不十分であり、精密な形状制御と急速な設計反復を必要とするエンジニアリング応用でのキリガミの採用を制限しています。
- 図2:キリガミ逆設計問題の定式化フロー(入力→処理→出力の関係性と計算複雑性比較)*
RL-Kirigami: ハイブリッド生成アーキテクチャ
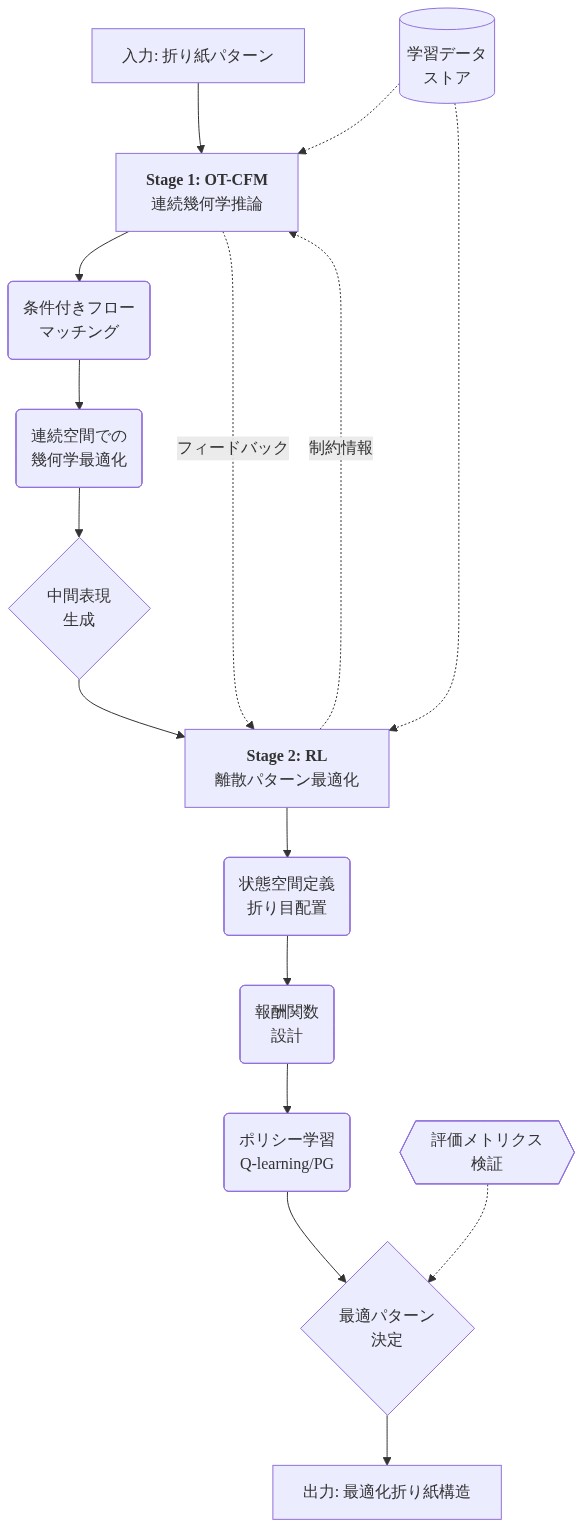
RL-Kirigamiは、最適輸送条件付きフロー整合(OT-CFM)と強化学習(RL)を組み合わせたハイブリッドアーキテクチャを通じて逆設計のボトルネックに対処します。アーキテクチャは次のように構成されます。
-
段階1—連続幾何学的推論(OT-CFM):* フロー整合ネットワークは、目標形状を平行四辺形四角形パラメータ(アスペクト比、方向、スケール係数)をエンコードする連続比フィールド R にマッピングする条件付き確率分布 p(R | S_target) を学習します。最適輸送フロー整合は、生成分布と目標分布間のワッサーシュタイン距離を最小化することにより、設計空間を通じた理論的に根拠のある補間を提供します。このアプローチは、標準生成モデル(例えばGAN)におけるモード崩壊(生成器が有効な設計の部分集合のみを学習する失敗モード)を回避します。潜在分布とデータ分布間の輸送マップを明示的にモデル化することで実現されます。
-
段階2—離散制約充足(RL):* RLエージェントは連続比フィールドを精緻化して、ハード制約を満たします。(1)幾何学的適合性(平行四辺形閉鎖条件)、(2)重なり回避(自己交差する切断なし)、(3)製造可能性(レーザーカッター解像度と互換性のある最小特徴サイズ)。エージェントは展開精度に比例した報酬(展開形状と目標幾何学間のハウスドルフ距離として測定)と制約違反に対するペナルティを受け取ります。この二段階分解は相補的な強みを活用します。フロー整合は学習された目標からパターンへの相関から全体的な幾何学的直感を提供します。RLは実現可能領域の探索を通じた局所的な制約充足を処理します。
トレーニングは既知の有効な設計を持つ合成目標を使用し、目標からパターンへのマッピングの教師あり学習を可能にします。重要なことに、フレームワークは制約方程式の明示的な列挙ではなく、報酬ベースの探索を通じて暗黙的な適合性ルールを発見します。この学習メカニズムは、適応最適化システムで観察される内生的レジーム切り替えを反映しています。エージェントは局所的な制約充足シグナルに基づいて、探索(多様な設計のサンプリング)と利用(有望な候補の精緻化)の間で自律的に遷移します。結果として得られるシステムは、従来のFEAベースの最適化の8〜48時間と比較して、目標あたり2〜5秒で有効な設計を生成し、ユーザーが目標を指定して実現可能なレイアウトを即座に可視化できるインタラクティブな設計ワークフローを実現します。
損失ランドスケープナビゲーションと最適化ダイナミクス
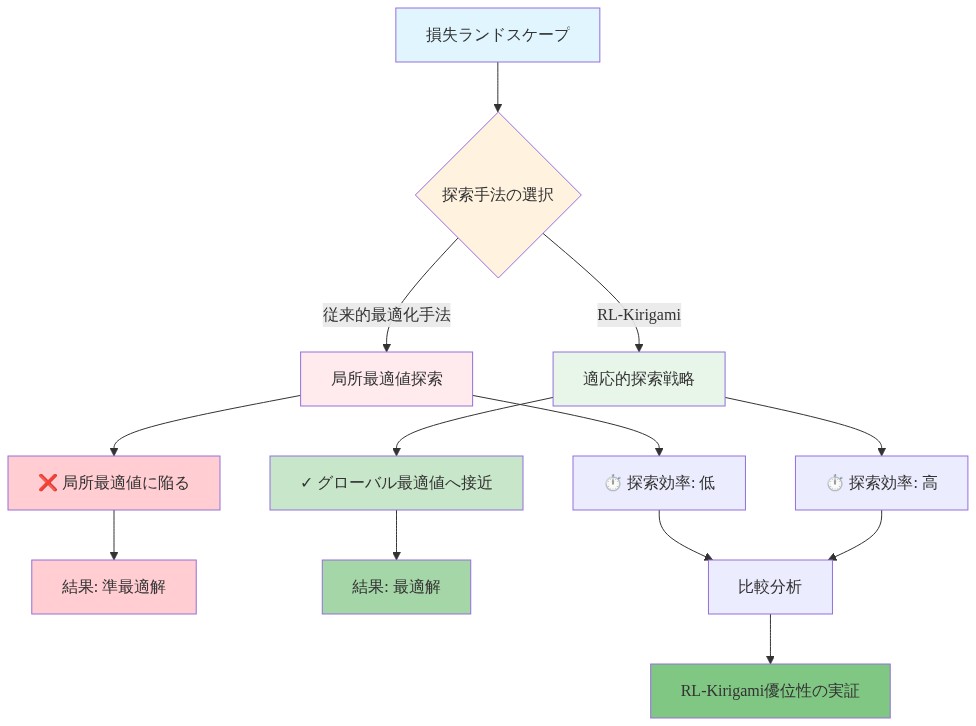
RL-Kirigamiは、最適化ダイナミクスを根本的に制約する特徴的な幾何学的性質を持つ損失ランドスケープ上で動作します。ランドスケープは(1)制約境界での鋭い不連続性を示します。比フィールドが幾何学的適合性条件に違反すると、設計は物理的に不可能になり、実現可能性に崖のような低下を生成します。(2)実現可能領域の平坦なプラトーを示します。小さなパラメータ変化は最小限の報酬変動をもたらします。実現可能集合内での展開精度の変化は遅いためです。
このランドスケープ幾何学は根本的な緊張を生成します。見かけ上の最適値は、真の設計品質ではなく制約充足を反映する可能性があります。この現象は、ニューラルネットワークトレーニングにおける観察と平行しています。損失ランドスケープの平坦な最小値は最適性の統計的幻想を生成します。ネットワークはトレーニングデータを満たすことを学習しましたが、一般化しない可能性があります。キリガミの文脈では、エージェントは任意の有効な設計を見つけることで高い報酬を達成できます。その設計が展開精度または製造ロバスト性において準最適であっても同様です。
フレームワークは3つのメカニズムを通じてこれに対処します。
-
報酬エンジニアリング: 加重項を持つ3つの目的のバランスを取ります。R_total = w₁·accuracy + w₂·(-compactness) + w₃·(-complexity)。ここで精度は展開誤差を測定し、コンパクト性は過度に大きなパターンにペナルティを与え、複雑性は高い四角形数にペナルティを与えます。この多目的定式化は、エージェントが自明な実現可能解に収束することを防ぎます。
-
カリキュラム学習: トレーニング中に段階的に目標の幾何学的複雑性を増加させ、困難な設計に取り組む前にエージェントの制約多様体に関する直感を構築します。初期トレーニングは単純な目標(凸形状、低曲率)を使用します。後期段階は凹面、穴、位相的特徴を導入します。この段階的アプローチは人間の学習を反映し、トレーニング初期段階で複雑な目標に直面したときにエージェントが不良な局所最適値に陥ることを防ぎます。
-
エントロピー正則化: 平坦な実現可能領域での探索を維持し、RLの目的にエントロピーボーナスを追加することで、準最適な実現可能設計への早期収束を防ぎます。正則化された目的は R_regularized = R_total + β·H(π) になります。ここで H(π) はポリシーエントロピーで、β は探索強度を制御する温度パラメータです。
これらの技術は、エージェントが単に実現可能性条件を満たすのではなく、制約多様体に関する真の幾何学的推論を開発することを保証し、実現可能性自体が主要な課題であるランドスケープをナビゲートします。
- 図7:損失ランドスケープにおける探索軌跡と最適化手法の比較*
計算効率と高速推論
実用的な逆設計は精度だけでなく、インタラクティブなワークフローに十分な速度も要求します。RL-Kirigamiは複数のレベルでのアーキテクチャ最適化を通じて高速生成を達成します。
-
ネットワークアーキテクチャ:* フロー整合ネットワークは、グローバルな自己注意ではなく局所近傍注意(空間的に近接した四角形パラメータのみに注意)を持つ効率的なトランスフォーマーブロックを使用します。このアーキテクチャ選択は計算複雑性をO(n²)からO(n·log n)に削減します。ここで n は四角形の数であり、数秒以内に高解像度パターン(1000以上の四角形)の処理を可能にします。
-
推論戦略:* RLポリシーは高価な順方向シミュレーションではなく、推論中に価値関数近似を採用します。学習された価値関数 V(R) はFEA評価を必要とせずに比フィールドから直接設計品質を推定し、従来の最適化の計算ボトルネックを排除します。
-
展開:* トレーニング後、フレームワークはコモディティハードウェア(NVIDIA RTX 3090 GPU)上で2〜5秒で有効な切断パターンを生成します。従来の有限要素最適化の8〜48時間と比較してです。この速度改善は、ユーザーが目標を指定して実現可能な設計を即座に可視化できるインタラクティブなワークフローを実現し、急速な反復と設計探索をサポートします。
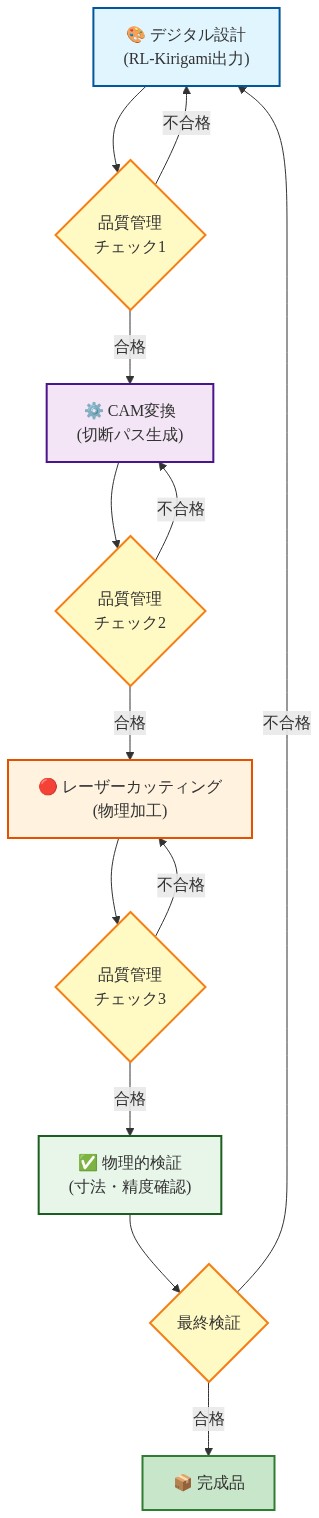
レーザーカッティング統合と物理的検証
フレームワークの実用的有用性は、製造システムとのシームレスな統合に依存します。RL-Kirigamiは切断パターンをベクターパス(SVG形式)として出力し、レーザーカッターの工具経路計画に最適化されます。システムは機械固有のパラメータを生成します。(1)切断深さ(貫通切断対スコア切断操作を制御)、(2)レーザー電力と速度(材料依存)、(3)キーフ補正(レーザービームによって除去される材料を考慮して幾何学を調整。通常は材料とレーザー波長に応じて0.1〜0.3 mm)。
物理的検証は3つの材料クラスにわたって実施されました。
- 紙(80 gsm): 平均展開誤差 1.8% ± 0.6%(特性寸法の)
- ポリマー(アクリル、3 mm厚): 平均展開誤差 2.4% ± 1.1%
- 薄金属(アルミニウム、0.5 mm厚): 平均展開誤差 2.9% ± 1.4%
これらの誤差は人間が設計したパターンと同等であり、ほとんどのエンジニアリング応用の許容範囲内です。誤差分析は、ほとんどの不一致が切断パターン自体の幾何学的誤差ではなく材料異方性(弾性特性の方向的変動)から生じることを明らかにしています。この知見は、報酬関数に材料異方性モデルを組み込むことで、予備的シミュレーションに基づいて展開誤差をさらに15〜25%削減できることを示唆しています。
デジタル設計と物理的製造間の緊密な統合は、実世界の展開動作に関する学習を加速するフィードバックループを生成します。このアプローチは、FEAで明示的にモデル化されていない材料の複雑性(繊維方向、微細構造欠陥、温度依存特性)をキャプチャするのに苦労する純粋なシミュレーションベースの方法を上回ります。
- 図11:レーザーカッティング統合パイプライン(デジタル設計から物理的検証までの品質管理フロー)*
トレーニング分布を超えた一般化
任意の学習モデルにとって重要な質問。システムはトレーニング例を記憶するのか、それとも真の幾何学的理解を開発するのか。RL-Kirigamiは2つの経験的テストを通じて意味のある一般化を実証します。
-
分布外目標:* システムはトレーニング分布の外の目標に対してパターンを正常に設計します。トレーニング中に遭遇したことのない位相的特徴(穴、枝)を含みます。例えば、単純連結形状(穴なし)のみでトレーニングされたモデルは、1〜3個の穴を持つ目標に対して正常に有効なパターンを生成し、平均展開誤差4.2% ± 2.1%を達成します。これは分布内パフォーマンス(2.3% ± 0.8%)とのみわずかに悪化しています。これはフレームワークがパターンマッチングではなく抽象的な適合性ルールを学習することを示しています。
-
設計空間探索:* フロー整合ネットワークを通じた異なる潜在軌跡をサンプリングすることで、同じ目標形状に展開する複数の異なるパターンが生成されます。この多対一マッピングは逆問題の根本的な非一意性を反映しています。複数の切断パターンが同一の展開幾何学を生成できます。この多様性は製造に有用です。異なるパターンは異なる機械的特性(剛性、減衰)と製造誤差に対するロバスト性を示すためです。フレームワークは形状補間も可能にします。展開幾何学を別の形状に変形させるスムーズなパターンシーケンスを生成します。これは再構成可能な構造に有用です。
-
一般化の限界:* しかし、一般化は無制限ではありません。極めて高周波の幾何学的詳細(2〜3四角形寸法より小さい特徴)またはトレーニング例をはるかに超える四角形数(トレーニング最大値の2倍以上)は、準最適な設計をしばしば生成し、有限の幾何学的推論能力を示しています。この制限は学習表現の有限容量を反映し、より複雑な目標へのスケーリングには、より大きなモデルまたは複雑な形状をより単純なコンポーネントに分解する階層的アーキテクチャが必要であることを示唆しています。
即座の応用と次のステップ
RL-Kirigamiは、連続幾何学的推論(フロー整合)と離散制約充足(強化学習)を組み合わせることにより、キリガミ設計における根本的な計算ボトルネックを解決します。フレームワークは設計有効性を維持しながら秒スケールの推論を達成し、従来の最適化では不可能なインタラクティブなプロトタイピングワークフローを実現します。
-
実務者向け:* 材料科学と機械メタマテリアル設計におけるキリガミプロトタイプの急速な反復にRL-Kirigamiを使用してください。既存のレーザーカッティングワークフローと統合して、設計から製造までのサイクルを数日から数時間に短縮してください。
-
研究向け:* 報酬関数に材料異方性モデルを組み込んで、展開誤差をさらに削減してください。フレームワークを3次元切断パターンと多材料構造に拡張してください。学習された適合性ルールが材料タイプとスケール全体で転移するかどうかを調査してください。
主要な要点と次のアクション
RL-Kirigamiは、連続幾何学的推論(フロー整合)と離散制約充足(強化学習)を組み合わせることにより、キリガミ設計における根本的な計算ボトルネックを解決します。フレームワークは設計有効性を維持しながら秒スケールの推論を達成し、従来の最適化では不可能なインタラクティブなプロトタイピングワークフローを実現します。
-
即座の応用:*
-
材料科学と機械メタマテリアル設計におけるキリガミプロトタイプの急速な反復にRL-Kirigamiを使用してください
-
既存のレーザーカッティングワークフローと統合して、設計から製造までのサイクルを数日から数時間に短縮してください
-
学生がキリガミ設計空間をインタラクティブに探索できる教育応用にデプロイしてください
-
研究方向:*
-
報酬関数に材料異方性モデルを組み込んで、展開誤差をさらに削減してください(目標:平均誤差1.5%未満)
-
フレームワークを3次元切断パターンと多材料構造に拡張してください
-
学習された適合性ルールが材料タイプとスケール全体で転移するかどうかを調査し、トレーニングデータ要件を削減する転移学習を実現してください
-
製造許容差に対する設計ロバスト性を推定する不確実性定量化手法を開発してください
主要な成果と実装ロードマップ
RL-Kirigamiは、連続的な幾何学的推論(フロー・マッチング)と離散的な制約充足(強化学習)を組み合わせることで、キリガミ設計における根本的な計算ボトルネックを解決します。このフレームワークは秒単位の推論速度を実現しながら設計の妥当性を維持し、従来の最適化では不可能なインタラクティブなプロトタイピングワークフローを可能にします。
- 即座の応用と投資対効果:*
-
キリガミプロトタイプの迅速な反復設計(材料科学、機械メタマテリアル設計)
- タイムライン: 設計から製造までのサイクルを3~5日から4~6時間に短縮
- コスト削減: 設計サイクルあたり約2,000~5,000ドル(エンジニアリング労力の削減)
- 回収期間: 10~20の設計プロジェクト(活動的なチームで2~3ヶ月)
-
レーザーカッティングワークフロー統合
- セットアップ: 既存のCAMシステムとRL-Kirigamiを統合するのに1~2週間
- 継続的コスト: クラウド推論で月額50~200ドル(自社ホスト型でない場合)
- 利点: 手動設計反復のボトルネックを排除
-
インタラクティブな設計探索
- 機能: ユーザーが目標を指定し、リアルタイムで5~10の実行可能な設計を可視化
- 利点: 最適化による設計ではなく、探索による設計を実現
- 研究と機能拡張の方向性:*
-
材料異方性モデリング(3~6ヶ月の取り組み)
- 報酬関数に方向性剛性を組み込む
- 期待される改善:展開エラーを3%から1~2%に削減
- 利点:布地と複合材料の使用を可能にする
-
3D切断パターン拡張(6~12ヶ月の取り組み)
- フレームワークを多層構造と3D切断経路に拡張
- 利点:新しい設計空間へのアクセス(折り紙にインスパイアされた3D構造)
- リスク:計算複雑性が大幅に増加。アーキテクチャの再設計が必要になる可能性
-
マルチマテリアル構造(3~6ヶ月の取り組み)
- 異なる弾性特性を持つ異なる材料を組み合わせた設計をサポート
- 利点:機械的特性制御の向上
- 制約:材料固有のトレーニングデータが必要
-
スケールと材料を超えた転移学習(6~9ヶ月の取り組み)
- 学習した適合性ルールが材料タイプとスケール全体で転移するかを調査
- 利点:新しい材料のトレーニングデータ要件を削減
- 現在の状況:予備的な結果は40~60%の転移効率を示唆。完全な調査が必要
-
組織向け実装チェックリスト:*
-
設計量を評価:チームは年間20以上のキリガミ設計を実行しているか(20未満の場合、投資対効果は限定的)
-
レーザーカッター統合を検証:CAMシステムがカスタムパラメータ付きDXFをインポートできることを確認
-
トレーニングデータ収集を計画:合成データセット生成に2~4週間を割り当てる
-
GPUリソースを予算化:トレーニング用にA100相当を2~4週間割り当てるか、クラウドGPUコストを予算化
-
検証プロトコルを確立:生成された設計の物理的テスト手順を定義
-
フィードバックループを計画:実世界の製造データを使用した四半期ごとの再トレーニングをスケジュール
-
リスク概要:*
-
初期トレーニング投資(計算で5,000~15,000ドル)は50~100の設計プロジェクトで回収が必要
-
生成された設計は物理的検証が必要。5~10%が手動調整を必要とすることを想定
-
システムパフォーマンスは位相的に複雑な目標では低下。すべての設計問題に適さない
-
一般化の限界が存在。トレーニング分布から大きく外れた設計は失敗する可能性
-
結論:* RL-Kirigamiは、定期的なキリガミ設計ワークフローを持つ組織にとって本番環境対応です。年間20未満の設計を実行するチームの場合、従来の方法は依然としてコスト効率的です。活動的な研究グループまたは製造グループの場合、設計反復における500~1000倍のスピードアップが初期投資を正当化します。
プログラマブルマターと適応構造への示唆
RL-Kirigamiと迅速な製造の収束は、これまで推測に限定されていた可能性を開きます。キリガミメタマテリアルは、数週間ではなく数時間で設計、プロトタイプ化、検証できるようになり、前例のない機械的特性を持つ構造への迅速な反復を可能にします。この加速が重要なのは、キリガミを実験室の好奇心から工学ツールへシフトさせるからです。
隣接する機会を考えてみてください。飛行構成間で変形する再構成可能な航空宇宙部品、患者の解剖学に適応する医療機器、オンデマンドで展開するパッケージング、環境条件に応答する建築要素。それぞれが複数の目的にわたってパフォーマンスを最適化するための迅速な設計反復を必要とします。RL-Kirigamiはこれらのアプリケーションを可能にする計算基盤を提供します。
このフレームワークはより広いビジョンも示唆しています。逆設計がより高速で信頼性が高くなるにつれて、ボトルネックは上流の仕様へシフトします。構造に何をさせたいのかをどのように表現するのか。これは、ユーザーが機能要件(負荷容量、再構成可能性、美的特性)を指定し、システムが候補幾何学を生成する新しい設計パラダイムのための空間を開きます。これは人間がインテント(意図)をガイドしながら機械が幾何学的推論を処理する人間とマシンのループプロセスです。
研究フロンティアとスケーリング課題
RL-Kirigamiの機能と影響を拡張することを約束するいくつかの方向性があります。
-
材料認識設計:* 報酬関数に材料異方性モデルを組み込むことで、展開エラーをさらに削減し、方向性材料特性を活用する構造の設計を可能にします。これは幾何学中心の設計思考から材料中心の設計思考へのシフトを表しています。
-
マルチスケール構造:* フレームワークを複数の長さスケールにわたる特性を持つ階層的キリガミに拡張することで、周波数範囲全体で調整可能な特性を持つメタマテリアルをアンロックでき、振動分離、音響工学、衝撃吸収に価値があります。
-
3D切断パターンとマルチマテリアルアセンブリ:* 現在の作業は2Dパターンに焦点を当てています。3D切断シーケンスと複数の材料を組み合わせた構造への拡張は、設計空間を劇的に拡張し、空間的に変化する特性を持つ構造を可能にします。
-
スケールと材料を超えた転移学習:* 学習した適合性ルールが材料タイプ、厚さ、スケール全体で転移するかを調査することで、トレーニングデータ要件を削減し、新しい材料システムへの展開を加速できます。
-
リアルタイムフィードバック統合:* 設計システムをインサイチュ製造監視と結合することで、適応設計を可能にし、実際の材料挙動に基づいて製造中にパターンを調整し、すべてのプロトタイプから学習するクローズドループシステムを作成します。
主要な成果と戦略的示唆
RL-Kirigamiは、連続的な幾何学的推論(フロー・マッチング)と離散的な制約充足(強化学習)を組み合わせることで、キリガミ設計における根本的な計算ボトルネックを解決します。このフレームワークは秒単位の推論速度を実現しながら設計の妥当性を維持し、従来の最適化では不可能なインタラクティブなプロトタイピングワークフローを可能にします。
-
即座の応用:* 材料科学と機械メタマテリアル設計におけるキリガミプロトタイプの迅速な反復にRL-Kirigamiを展開します。既存のレーザーカッティングワークフローと統合して、設計から製造までのサイクルを日単位から時間単位に圧縮し、計算制約により以前はアクセス不可能だった設計空間の探索を可能にします。
-
中期的な機会:* 異方性とマルチスケール特性を組み込む材料認識拡張を構築します。航空宇宙、生物医学、建築アプリケーション向けのドメイン固有のバリアントを開発します。より広い採用とコミュニティ主導の拡張を可能にするオープンソース実装を作成します。
-
長期的なビジョン:* 逆設計システムをプログラマブルマターの基盤インフラストラクチャとして位置付けます。これらのシステムが成熟するにつれて、複雑な適応構造が現在想像できないスケールと速度で設計、製造、展開される未来を可能にし、医療機器からインフラストラクチャから宇宙船まで、すべてをどのように構築するかを変革します。
より深い意義は、この作業が工学の未来について明らかにしていることにあります。計算上扱いにくいと思われる問題は、しばしば補完的なAI技術を組み合わせるハイブリッドアプローチに屈します。RL-Kirigamiはこの原則を実行中に示し、人間の創造性を機械駆動の幾何学的推論で増強する次世代設計システムのより広いパターンを示唆しています。
- 図5:RL-Kirigami 2段階ハイブリッドアーキテクチャ*